Приветствуем, уважаемые Хабравчане. Последнее время на Хабре стало мелькать название компании Teradata в тех или иных вопросах. И, увидев возможный интерес, мы решили рассказать немного о том, что же такое СУБД Teradata, от первого лица. Мы планируем подготовить небольшую серию статей о самых интересных, на наш взгляд, технических особенностях СУБД и работы с ней. Если у вас есть опыт работы с Teradata или в вашей компании используется наша платформа и у вас есть вопросы – подкидывайте их, и мы либо ответим на них в комментариях, либо подготовим соответствующую полноценную статью. А начнем с небольшого обзора. Для знакомства, так сказать.
СУБД Teradata была создана в 1976 году и многие концепции, заложенные в ее фундамент, актуальны и по сей день. Teradata реализовала дизайн, отличный от главенствующей на тот момент архитектуры мэйнфреймов. Это была идея объединения в сеть вычислительных модулей, работающих параллельно. Приятным дополением к такой архитектуре стало значительное удешевление систем.
Идея параллельной обработки дала Teradata возможность линейно масштабировать производительность, объемы обрабатываемых данных и количество пользователей. Что же такое «параллельная обработка»?
Двое друзей в 10 часов вечера в субботу ужинали и пили пиво, когда один из них сказал, что у него есть дело и он должен уйти. На вопрос друга, что это за дело, он ответил: «Стирка». Друг негодовал по этому поводу: «Как это можно… вечером уйти… чтобы стирать?..» На что получил объяснение: «Если я пойду стирать завтра, то мне повезет, если будет свободна одна из 10 машин в прачечной самообслуживания. Мне нужно постирать белья на 10 загрузок, и на это уйдет весь день. Если же я пойду сейчас, когда все отдыхают, я смогу использовать все стиральные машины и закончу стирку за полтора часа».
Эта история описывает то, что называется параллельной обработкой. Teradata выполняет загрузку, архивирование и обработку данных параллельно. В зависимости от конфигурации Teradata позволяет выполнять сотни, тысячи операций одновременно.
Руководитель хора готовился к концерту. Внезапно он остановился и обратился к хору со словами «Говорил ли я вам, что несколько лет назад я руководил другим хором, мы работали над этим же произведением и они сделали ту же ошибку, которую делаете сейчас вы? Знаете ли вы, что это за ошибка?» Голос из хора ответил: «Один и тот же руководитель!»
Многие проекты построения хранилища реализованы на архитектурах, которые не предназначены для этого. Многие компании часто удивляются провалам таких проектов, хотя они изначально не имели шанса на успех. Руководству компаний необходимо понимание, которое позволит выбрать те технологии поддержки принятия решений, которые будут соответствовать масштабу бизнеса.
Приведенная ниже диаграмма представляет собой логическую архитектуру Teradata.
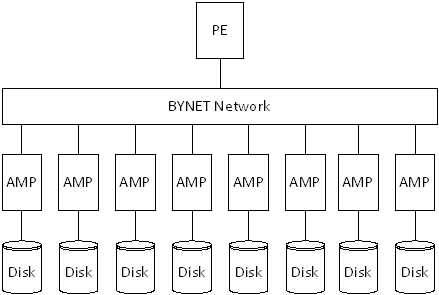
Основное назначение компонентов, представленных на диаграмме:
PE – Parsing Engine, отвечает за контроль сессии и обработку запросов пользователя;
AMP – Access Module Processor, отвечает за извлечение данных с ассоциированного с ним диска;
BYNET – Среда обмена сообщениями между компонентами системы.
Teradata относится к классу систем, называемых MPP (англ. Massively parallel processing), и имеет архитектуру Shared nothing, в рамках которой отдельные узлы системы не имеют общих ресурсов. А сама СУБД является реляционной.
На верхнем уровне процесс выполнения запроса в Teradata выглядит следующим образом:
PE и AMP объединяются термином VPROC, или виртуальный процессор.
Для того чтобы запросы обрабатывались максимально эффективно, данные должны быть распределены между AMP'ами максимально равномерно. Есть исключения, но о них мы расскажем в одной из следующих статей. Данные распределяются на основании собственного hash-алгоритма обработки полей, входящих в Primary index таблицы. Причем алгоритм хэширования реализован так, что на основании значения хэша можно понять номер AMP’а, на котором находится строка. Помимо основной цели, это также очень ускоряет поиски по значению.
Таким образом, AMP’ы – это рабочие лошадки, которые отвечают за свой кусок данных. Но часто бывают задачи, когда для выполнения запроса требуется перераспределение данных. Пример – join двух таблиц, которые распределены по разным ключам. Тогда в дело вступает BYNET. BYNET отвечает за коммуникацию между компонентами системы, и в том числе за передачу данных между AMP’ами. Он может с умопомрачительной скоростью передавать массивы данных между узлами. Не трудно догадаться, какая нагрузка ложится на BYNET. Поэтому отцы-основатели технологии заложили в нее хороший потенциал и сделали своим ноу-хау. В платформах Warehouse Appliance этот компонент может быть реализован софтверно поверх Ethernet. В более серьезных платформах Active Enterprise Data Warehouse это отдельный аппаратный модуль, ибо с такими объемами Ethernet уже не эффективен.
Лицом к клиентам стоит PE – parsing engine. Это компонент (а точнее, набор компонентов), в функции которого входит первоначальная обработка поступающих запросов, контроль выполнения и отправка ответов. В его состав входят 3 модуля: парсер, оптимизатор, диспетчер.
Как нетрудно догадаться, парсер отвечает за парсинг запроса, проверку прав доступа и прочий семантический контроль. Оптимизатор оценивает возможные варианты выполнения запроса и выбирает наиболее эффективный. Ходят слухи, что код оптимизатора занимает более 1 млн строк, а где-то в районе Rancho Bernardo сидит группа людей, которая не занимается ничем, кроме совершенствования логики оптимизатора от версии к версии. И да, нельзя не сказать – в Терадате нет хинтов. Поэтому если разработчик считает, что его план лучше, чем тот, что определил оптимизатор, то это еще придется доказать, а не просто приставить к порту «пистолет» и сказать: «+use_hash». И, как показывает практика, оптимизатор оказывается прав.
А диспетчер отвечает за разбитие выбранного плана на шаги и контроль последовательности/параллельности их выполнения, отдавая указания на AMP’ы через BYNET.
Так что если вкратце, то логически работа системы выглядит примерно таким образом. В следующих постах мы думали рассказать об особенностях работы со статистикой в СУБД, может, коснуться вопросов физического моделирования и поговорить об инструментах автоматической балансировки нагрузки. А вы что скажете о возможных интересных темах?
Параллелизм
СУБД Teradata была создана в 1976 году и многие концепции, заложенные в ее фундамент, актуальны и по сей день. Teradata реализовала дизайн, отличный от главенствующей на тот момент архитектуры мэйнфреймов. Это была идея объединения в сеть вычислительных модулей, работающих параллельно. Приятным дополением к такой архитектуре стало значительное удешевление систем.
Идея параллельной обработки дала Teradata возможность линейно масштабировать производительность, объемы обрабатываемых данных и количество пользователей. Что же такое «параллельная обработка»?
Двое друзей в 10 часов вечера в субботу ужинали и пили пиво, когда один из них сказал, что у него есть дело и он должен уйти. На вопрос друга, что это за дело, он ответил: «Стирка». Друг негодовал по этому поводу: «Как это можно… вечером уйти… чтобы стирать?..» На что получил объяснение: «Если я пойду стирать завтра, то мне повезет, если будет свободна одна из 10 машин в прачечной самообслуживания. Мне нужно постирать белья на 10 загрузок, и на это уйдет весь день. Если же я пойду сейчас, когда все отдыхают, я смогу использовать все стиральные машины и закончу стирку за полтора часа».
Эта история описывает то, что называется параллельной обработкой. Teradata выполняет загрузку, архивирование и обработку данных параллельно. В зависимости от конфигурации Teradata позволяет выполнять сотни, тысячи операций одновременно.
Логическое представление архитектуры Teradata
Руководитель хора готовился к концерту. Внезапно он остановился и обратился к хору со словами «Говорил ли я вам, что несколько лет назад я руководил другим хором, мы работали над этим же произведением и они сделали ту же ошибку, которую делаете сейчас вы? Знаете ли вы, что это за ошибка?» Голос из хора ответил: «Один и тот же руководитель!»
Многие проекты построения хранилища реализованы на архитектурах, которые не предназначены для этого. Многие компании часто удивляются провалам таких проектов, хотя они изначально не имели шанса на успех. Руководству компаний необходимо понимание, которое позволит выбрать те технологии поддержки принятия решений, которые будут соответствовать масштабу бизнеса.
Приведенная ниже диаграмма представляет собой логическую архитектуру Teradata.
Основное назначение компонентов, представленных на диаграмме:
PE – Parsing Engine, отвечает за контроль сессии и обработку запросов пользователя;
AMP – Access Module Processor, отвечает за извлечение данных с ассоциированного с ним диска;
BYNET – Среда обмена сообщениями между компонентами системы.
Teradata относится к классу систем, называемых MPP (англ. Massively parallel processing), и имеет архитектуру Shared nothing, в рамках которой отдельные узлы системы не имеют общих ресурсов. А сама СУБД является реляционной.
На верхнем уровне процесс выполнения запроса в Teradata выглядит следующим образом:
- Пользователь, подключаясь к системе Teradata, устанавливает соединение с Parsing Engine (PE). После того как соединение установлено, он может выполнять запросы SQL.
- PE проверяет синтаксис полученного SQL-запроса, права пользователя на доступ к информации и создает план выполнения запроса для выполнения компонентом Access Module Processor (AMP).
- PE через BYNET направляет шаги плана AMP'ам на выполнение.
- AMP’ы извлекают необходимую информацию с ассоциированных с ними дисков и возвращают ее PE через BYNET. AMP’ы выполняют свою работу параллельно.
- PE возвращает результат пользователю.
PE и AMP объединяются термином VPROC, или виртуальный процессор.
Для того чтобы запросы обрабатывались максимально эффективно, данные должны быть распределены между AMP'ами максимально равномерно. Есть исключения, но о них мы расскажем в одной из следующих статей. Данные распределяются на основании собственного hash-алгоритма обработки полей, входящих в Primary index таблицы. Причем алгоритм хэширования реализован так, что на основании значения хэша можно понять номер AMP’а, на котором находится строка. Помимо основной цели, это также очень ускоряет поиски по значению.
Технические детали по составу hash'a
В современных версиях платформ Teradata результат хэша представляет собой 32-битную последовательность. В ее рамках заложены идентификаторы AMP’a (единица параллелизма системы) и собственно строки. Допустим, нам надо обработать запись со значением 7202. Схема определения ее хэша и того, на какой AMP следует поместить строку, выглядит следующим образом.

Таким образом, AMP’ы – это рабочие лошадки, которые отвечают за свой кусок данных. Но часто бывают задачи, когда для выполнения запроса требуется перераспределение данных. Пример – join двух таблиц, которые распределены по разным ключам. Тогда в дело вступает BYNET. BYNET отвечает за коммуникацию между компонентами системы, и в том числе за передачу данных между AMP’ами. Он может с умопомрачительной скоростью передавать массивы данных между узлами. Не трудно догадаться, какая нагрузка ложится на BYNET. Поэтому отцы-основатели технологии заложили в нее хороший потенциал и сделали своим ноу-хау. В платформах Warehouse Appliance этот компонент может быть реализован софтверно поверх Ethernet. В более серьезных платформах Active Enterprise Data Warehouse это отдельный аппаратный модуль, ибо с такими объемами Ethernet уже не эффективен.
Лицом к клиентам стоит PE – parsing engine. Это компонент (а точнее, набор компонентов), в функции которого входит первоначальная обработка поступающих запросов, контроль выполнения и отправка ответов. В его состав входят 3 модуля: парсер, оптимизатор, диспетчер.
Как нетрудно догадаться, парсер отвечает за парсинг запроса, проверку прав доступа и прочий семантический контроль. Оптимизатор оценивает возможные варианты выполнения запроса и выбирает наиболее эффективный. Ходят слухи, что код оптимизатора занимает более 1 млн строк, а где-то в районе Rancho Bernardo сидит группа людей, которая не занимается ничем, кроме совершенствования логики оптимизатора от версии к версии. И да, нельзя не сказать – в Терадате нет хинтов. Поэтому если разработчик считает, что его план лучше, чем тот, что определил оптимизатор, то это еще придется доказать, а не просто приставить к порту «пистолет» и сказать: «+use_hash». И, как показывает практика, оптимизатор оказывается прав.
А диспетчер отвечает за разбитие выбранного плана на шаги и контроль последовательности/параллельности их выполнения, отдавая указания на AMP’ы через BYNET.
Так что если вкратце, то логически работа системы выглядит примерно таким образом. В следующих постах мы думали рассказать об особенностях работы со статистикой в СУБД, может, коснуться вопросов физического моделирования и поговорить об инструментах автоматической балансировки нагрузки. А вы что скажете о возможных интересных темах?
