
Месяц назад компания Splunk на своей 8-ой ежегодной конференции Splunk Conf 2017 презентовала выпуск нового мажорного релиза Splunk 7.0. В этой статье мы расскажем об основных нововведениях и улучшениях платформы, а также покажем пару примеров.
Метрики
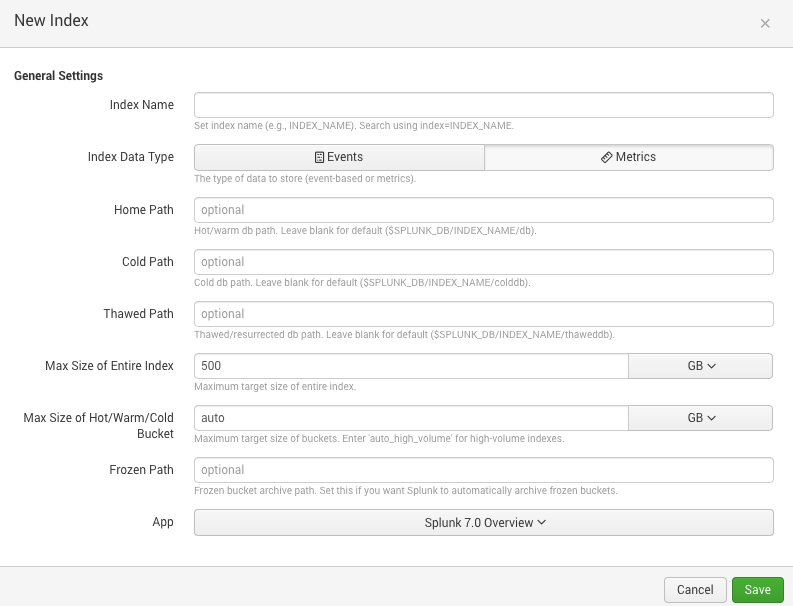
В новом релизе Splunk вводит отдельный тип данных для индексации — метрики. Это в большинстве своем технологические данные, описывающие конкретный процесс или систему, а точнее их состояние. Это всем известные показатели, такие как: величина загрузки процессора, объем свободной оперативной памяти или места на диске, показатели AWS (Amazon Web Service), IoT и многое другое. Полный список доступен здесь. Стоит сказать лишь одно, чтобы загрузить метрики в Splunk у них должно быть три обязательных поля: время, название метрики и значение, остальное опционально, см. картинку ниже.

Также, при создании нового индекса, теперь нужно указывать, что это данные с метриками а не просто логи. Из коробки доступны забор таких sourcetype, как StatsD и collectD, для остального нужно будет конфигурировать transforms.conf и props.conf, но это не сложно.
Новые SPL команды для метрик
Для работы с метриками Splunk сделал новые команды mstats и mcatalog. Правда mcatalog пока официально не поддержиается, поэтому мы покажем только примеры запросов с mstats, которая как вы уже поняли сильно похожа на stats, глбальным отличием от stats является то, что поиск начинается сразу с pipe line |, а не с фильтрации.
Посчитаем среднюю скорость:
| mstats avg(_value) WHERE metric_name="car.speed" AND driver_id="*" span=1m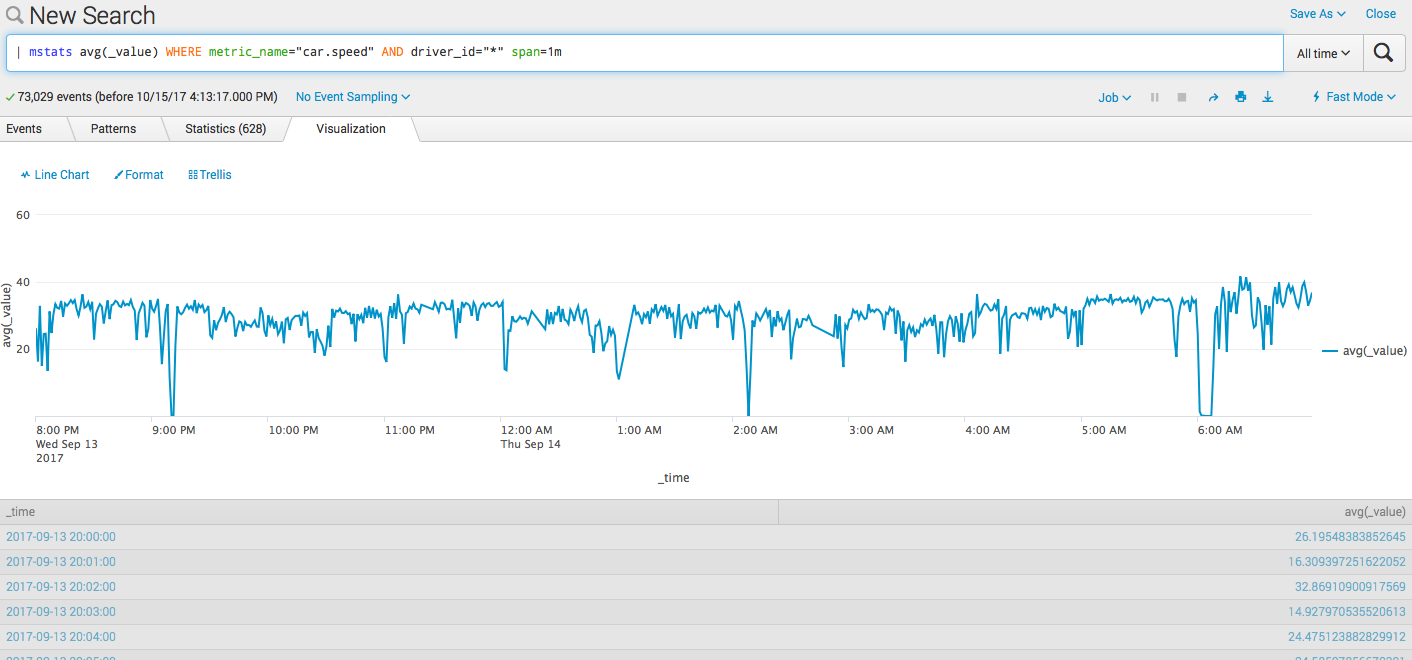
Добавим разделение по car_ip, для этого используем дополнительно timechart:
| mstats avg(_value) prestats=t WHERE metric_name="car.speed" AND driver_id="*" span=1m BY car_ip
| timechart avg(_value) AS speed span=30m BY car_ip
Зачем все это нужно?
Хороший вопрос, ведь раньше все тоже самое можно было делать с помощью обычной индексации, timechart и stats, и все работало. На самом деле ответ очевиден — это скорость. Для метрик, скорость обработки поисковых запросов, по заявлению разработчиков, возрастает в 20 раз и при этом уменьшается общая нагрузка на систему. Впечатляет, не правда ли?
Улучшение визуализации
Теперь на графики можно добавлять аннотации, Splunk так и назвал эту фичу Event Annotation. Правда стоит сразу отметить, что она работает только с line charts, column charts, и area charts.
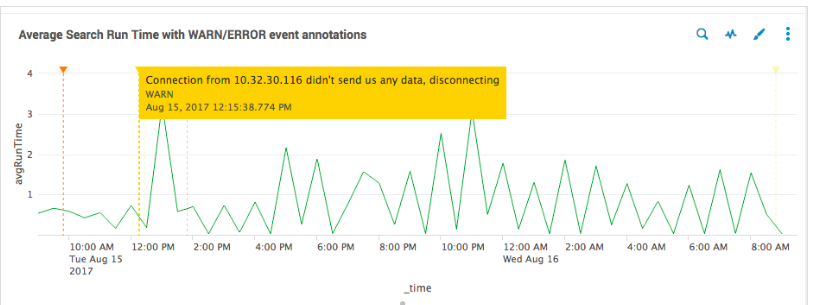
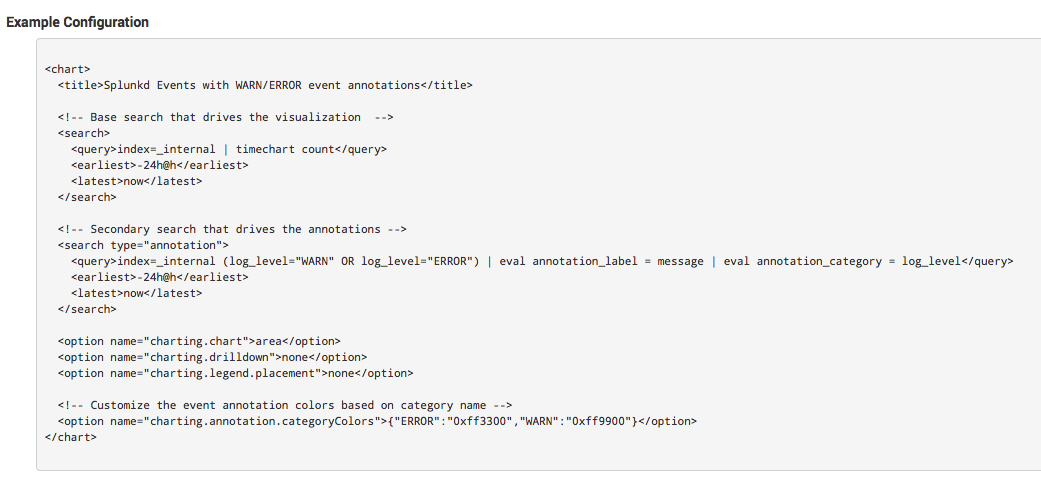
Цвет можно выбирать, сообщение в аннотации может быть как статичным, так и формироваться из конкретного поля события, ну и понятно, что аннотация — это отдельный запрос в том же временном интервале что и главный запрос. Все это делается очень просто, стоит только дописать пару строчек в исходный xml дашборда. Ниже пример, ну а подробно об этом здесь.
Обновленный Machine Learning Toolkit
Основным обновлением ML Toolkit является добавление в него нового алгоритма — ARIMA, что очень сильно приближает его к реальному Machine Learning. Помимо этого была расширена ролевая модель, теперь каждый пользователь может сохранить свои наработки отдельно, а также расширен API, о нем подробно здесь.

Итого
Понятно, что в данном релизе есть еще масса различных фич, таких как: обновленная Monitoring Console, Chart Enhancements, Report Action Enhancements, общая оптимизация работы платформы и ускорение поиска и многое другое, но мы старались рассказть про наиболее важные и интересные нововведения.
Дополнительно
Для наиболее глубокого изучения вопроса стоит установить приложение Splunk Enterprise 7.0 Overview, а также посмотреть официальное видео релиза.
Также, не забывайте, что по любым вопросом относительно Splunk: его внедрения, разработки на нем приложений, добавления новых, сложноиндексируемых событий и всего прочего вы можете обращаться за помощью к нам через наш сайт.
