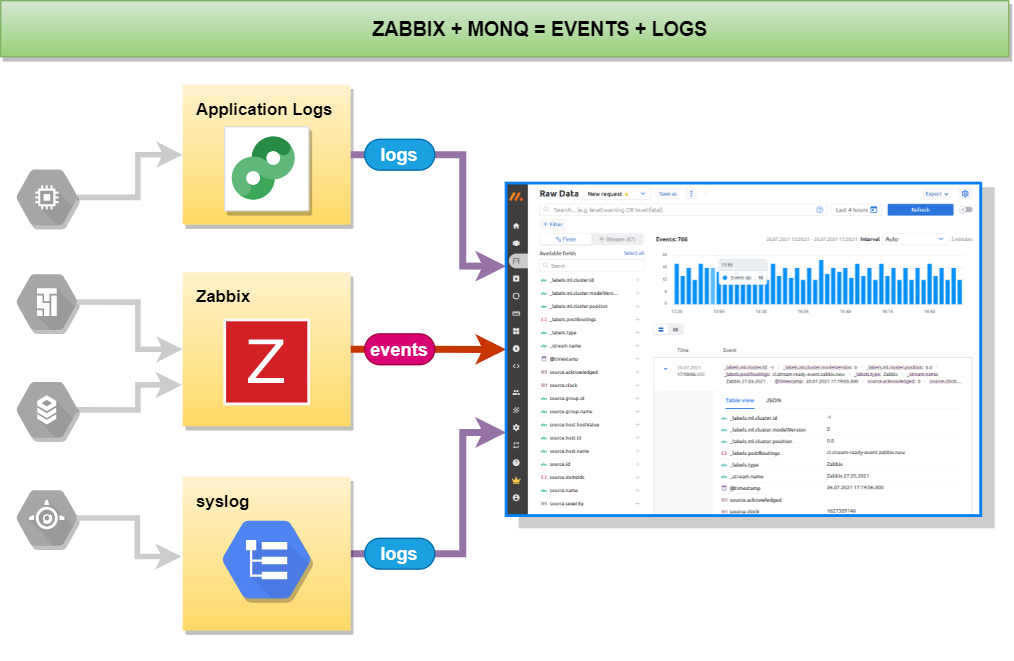
The meetup on January 14 at Hacker Dojo in Mountain View, California, went well, although not as planned - we spent almost all the time talking instead of doing hands-on exercises. The room we booked can fit 30 people and approximately 30 people did show up. The quality of participants was high: approximately half were familiar with hardware description languages and another half came from various software topics. 12 people filled out the questionnaire despite the fact that I forgot to bring 30 pens.
The discussion during and after the presentation was focused and very meaningful: microarchitecture and education, EDA infrastructure / build scripts, open-source ASIC design tools, the economics of ASIC design and manufacturing, high-level synthesis, transaction-level modeling, ASIC prototyping using FPGA boards, FPGA embedded in ASIC (Menta), new FPGA manufacturers (Gowin) and new design languages - Chisel and SpinalHDL.
Four persons came to me after the meeting to discuss their participation in working on open-source portable SystemVerilog examples, and another seven expressed this intention in the questionnaire. So we are meeting again in Hacker Dojo on Sunday, January 21, at 2 PM, this time not in the classroom area, but in the common shared area.
Generally, I am thinking of having regular meetings, probably on a weekly basis for a small team of developers of the educational materials and on a monthly basis for a wider audience, discussing various design and verification topics.
There were two correspondents of Slavic Sacramento who recorded the video of the presentation. They are going to make it available soon.











 -bit counter allows to take into account no more than
-bit counter allows to take into account no more than  events.
events.