Нейронные сети врываются в медицину
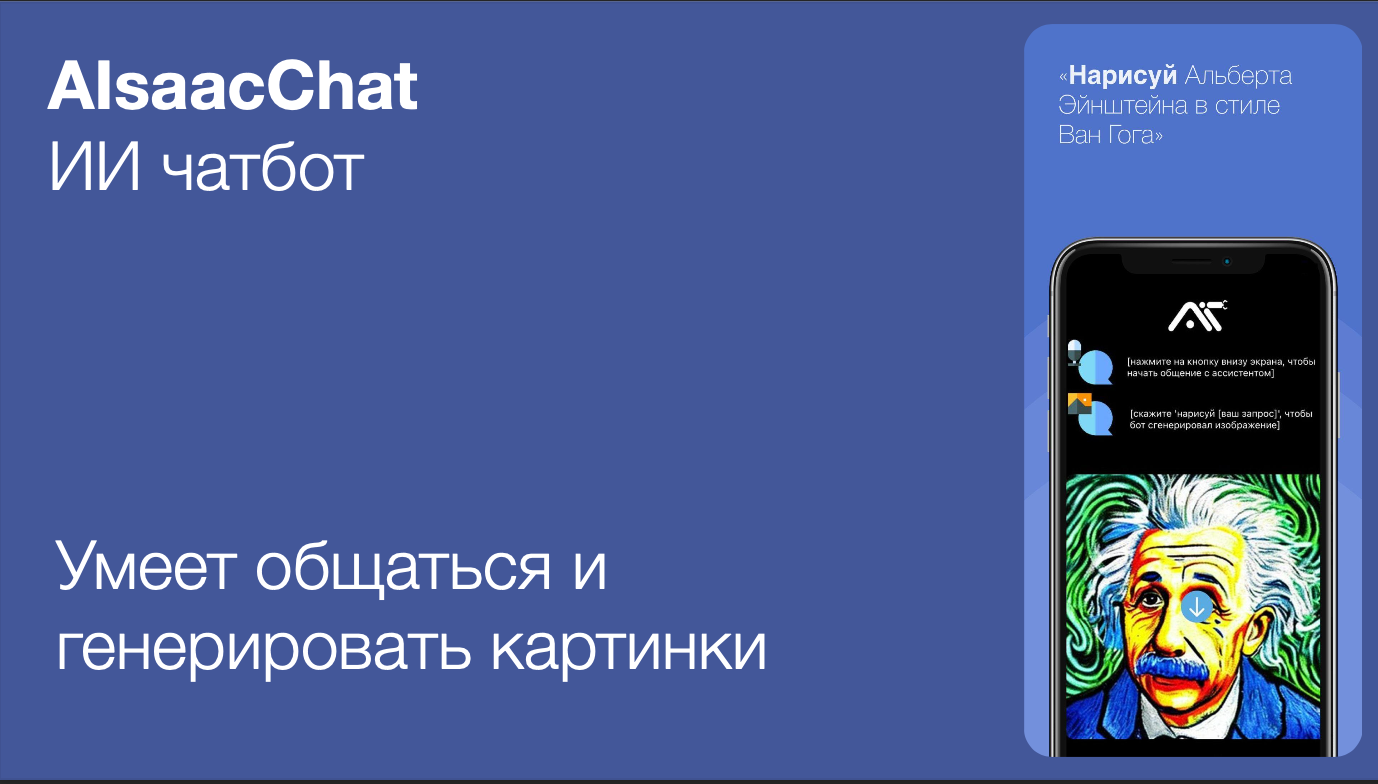
Доброго времени суток habr, на связи Николай Иванов, студент-магистр 1 курса Сколтеха факультета Data Science. С почином, так как это моя первая, и, надеюсь, не последняя статья на habr. С того момента как я познакомился с областью Deep Learning прошло уже около двух лет. С самого начала мне была интересна область обработки естественного языка (Natural Laguage Processing, NLP), о некоторых задачах которой и результатах я попробую рассказать в этой статье. В мае 2023 года начался мой путь в Sber AI Lab в замечательном центре медицины. Мой рассказ будет в какой-то степени сравнением того что было сделано до меня и того, какие идеи мы развили, что получилось, а что не получилось. Хочу сослаться на замечательную статью Даниила (https://habr.com/ru/articles/711700/), который использовал модель RuBioBERTa для задач из MedBench. Я же буду использовать другое решение, посмотрим, чем оно лучше, чем хуже и вообще насколько подходит для NLP-задач в медицине.
Немного оффтопа
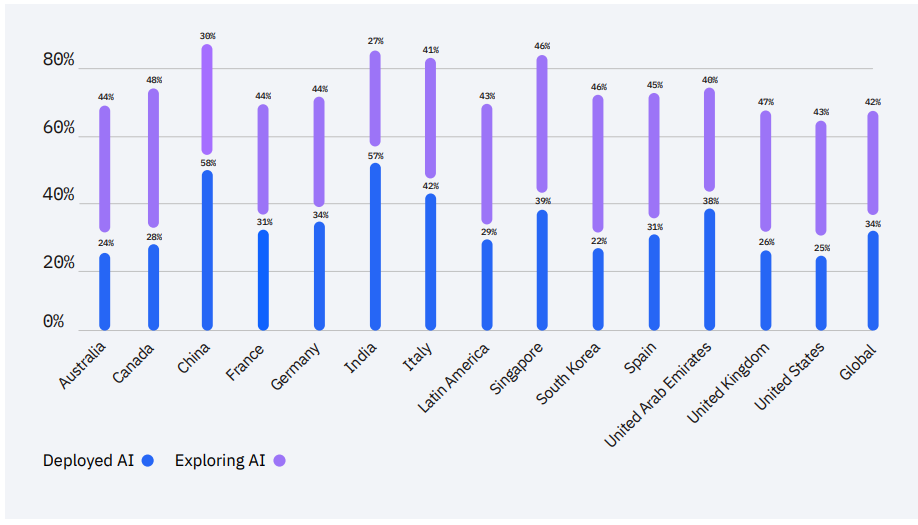
Я очень рад, что каждый месяц появляются новые, более сложные и интересные архитектуры, реализующие смелые идеи, которые двигают вперёд области Deep Learning, NLP и Computer Vision (CV), но сколько из них реально используются в прикладных задачах? Вот оценка внедрения AI решений по странам (на основании отчёта IBM Global AI Adoption Index 2022):