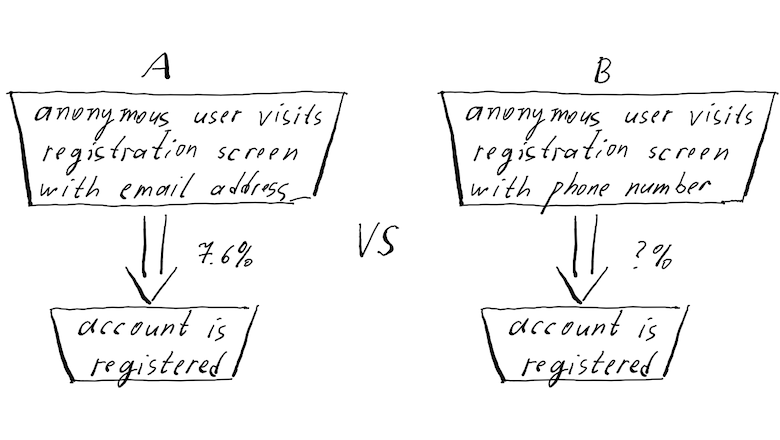
2. Information Theory + ML. Mutual Information

In Part 1, we became familiar with the concept of entropy.
In this part, we will delve into the concept of Mutual Information, which opens doors to error-resistant coding, compression algorithms, and offers a fresh perspective on regression and Machine Learning tasks.
It is an essential component that will pave the way, in the next section, for tackling Machine Learning problems as tasks of extracting mutual information between features and the predicted variable.
Here, there will be three interesting and crucial visualizations.
The first one will visualize entropy for two random variables and their mutual information.
The second one will shed light on the very concept of dependency between two random variables, emphasizing that zero correlation does not imply independence.
The third one will demonstrate that the bandwidth of an information channel has a straightforward geometric interpretation through the convexity measure of the entropy function.
In the meantime, we will prove a simplified version of the Shannon-Hartley theorem regarding the maximum bandwidth of a noisy channel. Let's dive in!