Я продолжаю цикл статей, посвященных некоторым простым правилам разработки под Unix «по версии Эрика Реймонда», которые, по моему глубочайшему убеждению, могут быть распространены на любые другие операционные системы. Я уже рассказывал в первых трех частях о правилах модульности, ясности, композиции, разделения, простоты и кодоэкономии. Сегодня дело дошло до седьмого правила —
Правило прозрачности: проектируйте ПО сразу с учетом отладочных инструментов
Смысл этого правила можно представить двумя постулатами:
Или — типичныйWindows-FTP-клиент . Вещь, вроде, уже давно вошедшая в арсенал обычного пользователя. Ну ладно, продвинутого пользователя, но по-всякому уже давно не обязательно программиста, понимающего в тонкостях протоколов. Ставишь себе программу, в которую встроен FTP-клиент , чуть ли не ради него ее выбрал, а он — не коннектится к серверу. Почему — не определишь. Никак он себя не выдает. Ошибка — и все!..
Хорошо, спустимся еще ниже. Вот есть скайп и аська под Windows. У них обоих есть настройки напрокси-серверы . И каждый раз, когда проблемы с соединением, не знаешь, почему они-то ли что-то с прокси-сервером , то ли это «у них» проблема, то ли — у меня.
Таких примеров, когда необходимо вести журнал действий — море. И это мы смотрим на крупные промышленные решения, у которых потеря одного пользователя — капля в море. А если вы имеете дело с системой с высокими требованиями к доступности? Когда каждая секунда на счету?
В юниксовом мире есть очень хорошая практика включать отладочный режим в стандартные консольные приложения, работающие как «вещь в себе» и/или вести журнал, т.н. «логи». Вы выставляете уровень отладки и видите, как работает приложение. Вот оно открыло соединение, вот бросило туда команду, вот получило ответ, вот ответ оказался неожиданным и программа сообщила об ошибке. Кроме того, что часть «продвинутых» пользователей начинает самостоятельно справляться с проблемами, вы еще экономите таким образом свое же время на поиск и устранение проблем.
Ведение логов удобно тем, что программа оставляет следы, которые могут быть полезны лишь спустя довольно продолжительное время. Например, можно анализировать журнал на предмет ошибок, особо не заметных пользователю. Вдруг они появляются регулярно? Из логов можно забирать данные о производительности и строить по ним графики и анализировать тренды. Отключить журналирование никогда не поздно, но если его не включили в программу, то потом это сделать уже сложнее.
Например, в ArtPublishing отладочная консоль выглядела следующим образом. Иерархия вызововфункций-шаблонов . Для одного из шаблонов форума, который я приводил в прошлой статье, разработчик мог изучить, как работает ПО внутри, добавив в URL отладочный флаг:
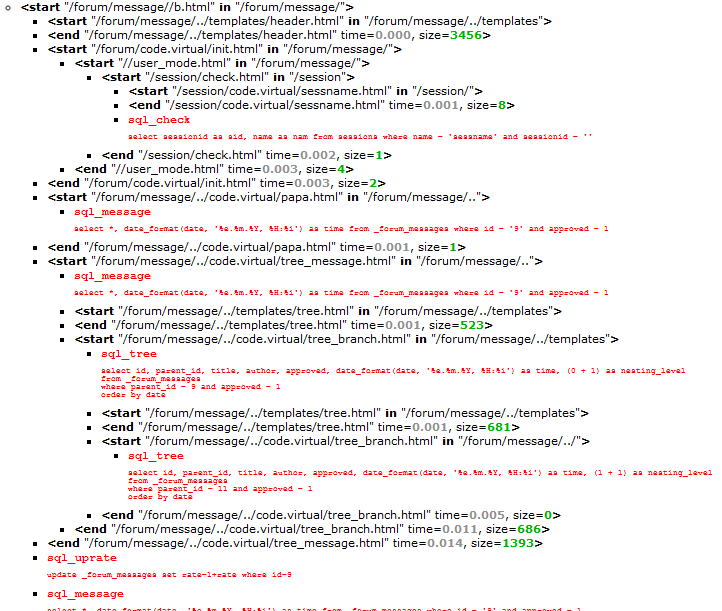
Приведенный пример может быть использован как положительный, так и как отрицательный. В частности, в нем удобным является то, что журнал представляется в форме структуры. Минус в том, что собирать и обрабатывать численные данные из такого журнала довольно непросто, непросто, например, зафиксировать изчезновение из структурыкакого-нибудь обязательного блока. Он похож на XML, но совершенно не «валидный».
Важно, что качественные «логи» — это как авторский почерк, по которому судят по программисту его коллеги. Это не менее важно, чем комментарии в исходных текстах или правильные названия для функций, файлов, папок и переменных. Как правило, записи в логи разделяют на четыре главных типа: ошибка, предупреждение, уведомление и отладочное сообщение, снабжают временной меткой и не забывают о том, что при трансляции в лог данных нужно не забывать о максимальной длине, кодировке, переводе строк (в текстовых логах), а в целом — о ротации логов (архивации и/или удаления старых логов).
Когда есть журналирование, обычно несложно сделать мониторинг работы сразу нескольких запущенных на разных рабочих станциях или серверах приложений — достаточно получить доступ к хранилищу этих логов и анализировать их «на лету».
Мониторинг работы модуля или приложения — дело несколько иное. Если логи показывают то, что происходит внутри программы, то мониторинг отражает в удобном для восприятия виде некоторые важные для контроля показатели. В случае выхода закакие-нибудь установленные граничные значения система мониторинга должна уведомлять администратора, пассивно (записывая в журнал) или активно (е-майл , sms). Например, сообщения о фатальных ошибках программ, отправляемые в компанию-разработчика по е-майл — тот же мониторинг, только внутренний, а не внешний.
Нерегулярный мониторинг строится на системе автоматизированного тестирования. Для того, чтобы построение такой системы было в принципе возможно, в архитектуре ПО должна быть учтена возможность «пакетной» работы. На вход подается набор готовых тестов, на выходе — готовые результаты. Такой мониторинг можно проводить после каждого изменения логики ПО.
Недавно занимались системой расчета сроков доставки. Там довольно хитрый алгоритм, учитывающий особенности логистики. Понять правильность расчета сходу невозможно, нужно вооружаться калькулятором и таблицами. Поэтому для того, чтобы быстро отвечать на вопросы, правильно ли работает механизм, нужно было добавить для него «прозрачности»: при отработке в журнале должна отражаться вся логика расчета срока, понятная неспециалисту. Отражать ее на сайте, конечно, не нужно было, но зато отвечать на вопрос вида «как это так получилось, что доставка занимает целых 15 дней!» стало отвечать очень просто — понятный для человека ответ буквально дает сама система. Также была разработана система автоматизированного тестирования, рассчитывающая сроки сразу для десятков ситуаций и сравнивающих результаты с рассчитанными вручную.
Правило прозрачности: проектируйте ПО сразу с учетом отладочных инструментов
Смысл этого правила можно представить двумя постулатами:
- приложение должно не просто работать хорошо, но и показывать, что она работает хорошо;
- должна быть предусмотрена возможность «высокоуровневой отладки» приложения;
Или — типичный
Хорошо, спустимся еще ниже. Вот есть скайп и аська под Windows. У них обоих есть настройки на
Таких примеров, когда необходимо вести журнал действий — море. И это мы смотрим на крупные промышленные решения, у которых потеря одного пользователя — капля в море. А если вы имеете дело с системой с высокими требованиями к доступности? Когда каждая секунда на счету?
В юниксовом мире есть очень хорошая практика включать отладочный режим в стандартные консольные приложения, работающие как «вещь в себе» и/или вести журнал, т.н. «логи». Вы выставляете уровень отладки и видите, как работает приложение. Вот оно открыло соединение, вот бросило туда команду, вот получило ответ, вот ответ оказался неожиданным и программа сообщила об ошибке. Кроме того, что часть «продвинутых» пользователей начинает самостоятельно справляться с проблемами, вы еще экономите таким образом свое же время на поиск и устранение проблем.
Ведение логов удобно тем, что программа оставляет следы, которые могут быть полезны лишь спустя довольно продолжительное время. Например, можно анализировать журнал на предмет ошибок, особо не заметных пользователю. Вдруг они появляются регулярно? Из логов можно забирать данные о производительности и строить по ним графики и анализировать тренды. Отключить журналирование никогда не поздно, но если его не включили в программу, то потом это сделать уже сложнее.
Например, в ArtPublishing отладочная консоль выглядела следующим образом. Иерархия вызовов
Приведенный пример может быть использован как положительный, так и как отрицательный. В частности, в нем удобным является то, что журнал представляется в форме структуры. Минус в том, что собирать и обрабатывать численные данные из такого журнала довольно непросто, непросто, например, зафиксировать изчезновение из структуры
Важно, что качественные «логи» — это как авторский почерк, по которому судят по программисту его коллеги. Это не менее важно, чем комментарии в исходных текстах или правильные названия для функций, файлов, папок и переменных. Как правило, записи в логи разделяют на четыре главных типа: ошибка, предупреждение, уведомление и отладочное сообщение, снабжают временной меткой и не забывают о том, что при трансляции в лог данных нужно не забывать о максимальной длине, кодировке, переводе строк (в текстовых логах), а в целом — о ротации логов (архивации и/или удаления старых логов).
Когда есть журналирование, обычно несложно сделать мониторинг работы сразу нескольких запущенных на разных рабочих станциях или серверах приложений — достаточно получить доступ к хранилищу этих логов и анализировать их «на лету».
Мониторинг работы модуля или приложения — дело несколько иное. Если логи показывают то, что происходит внутри программы, то мониторинг отражает в удобном для восприятия виде некоторые важные для контроля показатели. В случае выхода за
Нерегулярный мониторинг строится на системе автоматизированного тестирования. Для того, чтобы построение такой системы было в принципе возможно, в архитектуре ПО должна быть учтена возможность «пакетной» работы. На вход подается набор готовых тестов, на выходе — готовые результаты. Такой мониторинг можно проводить после каждого изменения логики ПО.
Недавно занимались системой расчета сроков доставки. Там довольно хитрый алгоритм, учитывающий особенности логистики. Понять правильность расчета сходу невозможно, нужно вооружаться калькулятором и таблицами. Поэтому для того, чтобы быстро отвечать на вопросы, правильно ли работает механизм, нужно было добавить для него «прозрачности»: при отработке в журнале должна отражаться вся логика расчета срока, понятная неспециалисту. Отражать ее на сайте, конечно, не нужно было, но зато отвечать на вопрос вида «как это так получилось, что доставка занимает целых 15 дней!» стало отвечать очень просто — понятный для человека ответ буквально дает сама система. Также была разработана система автоматизированного тестирования, рассчитывающая сроки сразу для десятков ситуаций и сравнивающих результаты с рассчитанными вручную.
| « Ранее: правило кодоэкономии |
