Comments 80
Мне, как быдлокодеру, было очень интересно и познавательно, спасибо!
Спасибо! Давно хотел почитать что-нибудь из алгоритмов по эвристическому анализу.
Но ведь некоторые эвристики могут дать неверный результат — как быть в таком случае?
Но ведь некоторые эвристики могут дать неверный результат — как быть в таком случае?
В этом и есть суть эвристик. Они почти никогда не дают глобально-оптимальный результат. Решение найденное с помощью эвристических алгоритмов гарантированно не худшее и с очень большой долей вероятности его можно назвать хорошим. Главный плюс этих алгоритмов в том, что они работают быстро и могут дать хоть какой-то результат в приемлемое время.
А мне казалось, что суть эвристки сводиться к оценке положения (и выбора направления) в поиске. %username%, эвристика и алгоритмы поиска — вещи немного разные. Алгоритмы могут и не использовать эвристику. Допусим у вас задача пройти по карте. Можно сделать это разными алгоритмами: перебором в ширину BFS или в глубину DFS, может быть какой-нибудь жадный вариант (обычно это BFS), если допустим стоимость (например время) перехода от клетки к клетке. Все эти варианты имеют плюсы и минусы. При определённых условиях ( цикличности, наличии непроходимых участков, большой размер карты) может возникнуть куча проблем с производительностью. Да и алгоритмы эти в сущности просто перебирают все варианты пока не находят тот, который отвечает стоп условию.
А вот с помощью эвристики мы можем попытаться оценить соседние клетки и помочь алгоритму отсеять заранее не перспективные пути. Взяв на вооружение простую функцию расстояния, можно без поиска узнать будем ли ближе к цели или нет. Таким образом тот же BFS с эвристикой будет выбирать в начале более привлекательные квадраты, а при отсутствии лидеров (все близлежащие участки оказались одинаково полезными) переходить на следующий уровень согласно поиску в ширину. Понятно, что оценка расстояния по прямой даст хороший результат, если на пути нет препятствий.
Эвристика сложная штука, так как надо найти функцию, которая приемлемо могла бы оценить ситуацию и не была обременительна по времени и производительности. Вся соль в том, что более точная аналитика может помешать вам просчитать ходы в глубину. Допустим при решении игры в крести-нолики 6х6, если вы ограничены секундой на ход, то скорее всего стоит просто посчитать количество не закрытых линий противника и углубиться на несколько ходов вперёд, чем более детально анализировать текущую позицию, а через два хода попасть впросак, так как у противника будет сразу две почти законченные линии и одним ходом их уже не закроешь.
А вот с помощью эвристики мы можем попытаться оценить соседние клетки и помочь алгоритму отсеять заранее не перспективные пути. Взяв на вооружение простую функцию расстояния, можно без поиска узнать будем ли ближе к цели или нет. Таким образом тот же BFS с эвристикой будет выбирать в начале более привлекательные квадраты, а при отсутствии лидеров (все близлежащие участки оказались одинаково полезными) переходить на следующий уровень согласно поиску в ширину. Понятно, что оценка расстояния по прямой даст хороший результат, если на пути нет препятствий.
Эвристика сложная штука, так как надо найти функцию, которая приемлемо могла бы оценить ситуацию и не была обременительна по времени и производительности. Вся соль в том, что более точная аналитика может помешать вам просчитать ходы в глубину. Допустим при решении игры в крести-нолики 6х6, если вы ограничены секундой на ход, то скорее всего стоит просто посчитать количество не закрытых линий противника и углубиться на несколько ходов вперёд, чем более детально анализировать текущую позицию, а через два хода попасть впросак, так как у противника будет сразу две почти законченные линии и одним ходом их уже не закроешь.
Что за детский сад? 2 млн лет на 65 булевых переменных в задаче оптимизации? Вы смеетесь?
Кроме того, у вас в разных «методах» просто разные критерии, и это Вы еще не учитываете вероятностные особенности инвестиций, их взаимосвязи и прочее.
Открою Вам страшную тайну, метод ветвей и границ решает Вашу задачу за секунды, если не за доли секунды, по крайней мере в той постановке, в которой вы написали. Вперед за учебник по оптимизации.
Кроме того, у вас в разных «методах» просто разные критерии, и это Вы еще не учитываете вероятностные особенности инвестиций, их взаимосвязи и прочее.
Открою Вам страшную тайну, метод ветвей и границ решает Вашу задачу за секунды, если не за доли секунды, по крайней мере в той постановке, в которой вы написали. Вперед за учебник по оптимизации.
Не люблю заниматься арифметикой, но вы неправы:

Строго говоря, я тоже загнул насчёт миллионов лет, но 1100 лет это совсем не те доли секунд, о которых Вы говорите.

Строго говоря, я тоже загнул насчёт миллионов лет, но 1100 лет это совсем не те доли секунд, о которых Вы говорите.
а я не люблю отвечать на бред, но не правы Вы. Метод ветвей и границ не предполагает расчет всех узлов вообще, иначе он не интереснее перебора. У Вас одни ветви, а границы где потеряли?)
Вторая строка сверху. Мы предполагаем, что МВиГ исследует только один процент узлов, но я так понимаю, спорить с Вами бесполезно.
Послушайте, Вам самому не смешно? Вы решаете элементарную задачу с детской размерностью и говорите, что нужна эвристика. Я писал прогу, которая решает задачу из нескольких десятков тысяч переменных, около тысячи из которых были целочисленными, и время расчета не превышало нескольких минут. А Вы тут травите.
Насчет всех узлов, я согласен, не заметил про один процент. Но во-первых, откуда этот процент? Почему процент? Во вторых, почему такая скорость расчета?
Насчет всех узлов, я согласен, не заметил про один процент. Но во-первых, откуда этот процент? Почему процент? Во вторых, почему такая скорость расчета?
Просмотр одного процента узлов — это ожидаемая эффективность метода ветвей и границ.
А скорость расчёта… Давайте пойдём от обратного. Предположим, что эта задача и правда решается за секунду. Это значит, что в секунду будет перебрано 3*10^16 узлов. Предположим также, что просмотр узла занимает один такт процессора. Получается, что Ваш компьютер работает на частоте 10 пета(!)герц? P.S. И нет, мне не смешно.
А скорость расчёта… Давайте пойдём от обратного. Предположим, что эта задача и правда решается за секунду. Это значит, что в секунду будет перебрано 3*10^16 узлов. Предположим также, что просмотр узла занимает один такт процессора. Получается, что Ваш компьютер работает на частоте 10 пета(!)герц? P.S. И нет, мне не смешно.
Очень жаль, что Вам не смешно. А хотите эксперимент? Попросите какую-нибудь мат. пакет, типа матлаба, хуже мепла (он все же символьный, да и он пойдет) Решить Вашу задачу, без всяких эвристик — время решения Вас удивит. Вообще говоря, меня удивляет, что Вы так никогда не поступали, иначе очевидно не написали бы этой статьи.
Если хотите, дайте мне Ваши исходные данные, я сам напишу, у меня правда, кроме мэпла старенького нет ничего на данный момент, но и это сойдет))
А насчет эффективности в 1% — может я чего не знаю, а откуда эта цифра взялась?
Если хотите, дайте мне Ваши исходные данные, я сам напишу, у меня правда, кроме мэпла старенького нет ничего на данный момент, но и это сойдет))
А насчет эффективности в 1% — может я чего не знаю, а откуда эта цифра взялась?
Эксперимент — это очень интересно, но
1. где гарантии, что Maple решает МВиГ, а не динамическим программированием?
2. Было бы гораздо проще, если вы укажите на ошибку в моих рассуждениях. Тогда я с радостью признаю Вашу правоту.
1. где гарантии, что Maple решает МВиГ, а не динамическим программированием?
2. Было бы гораздо проще, если вы укажите на ошибку в моих рассуждениях. Тогда я с радостью признаю Вашу правоту.
Мэплу, если мне не изменяет память, можно указать метод решения, или матлабу, я сейчас не вспомню.
Насчет ошибки в рассуждениях — я не понимаю откуда взялась цифра в 1%, может это я просто не догоняю. Это к вопросу о моем заявлении о методе ветвей и границ, которое мы хотим проверить.
Но отбросим его, если меплу не получится указать точно метод решения. В любой ситуации, уверяю Вас, задача оптимизации с 65 булевыми переменными, линейным критерием и одним(!) ограничением решается очень быстро (положим, что я ошибся даже с ветвями и границами), а посему никакие эвристики не нужны просто.
Насчет ошибки в рассуждениях — я не понимаю откуда взялась цифра в 1%, может это я просто не догоняю. Это к вопросу о моем заявлении о методе ветвей и границ, которое мы хотим проверить.
Но отбросим его, если меплу не получится указать точно метод решения. В любой ситуации, уверяю Вас, задача оптимизации с 65 булевыми переменными, линейным критерием и одним(!) ограничением решается очень быстро (положим, что я ошибся даже с ветвями и границами), а посему никакие эвристики не нужны просто.
Зашёл в пост, чтобы написать этот комментарий.
А как насчет того, чтобы открыть учебник по линейной оптимизации и посмотреть как описать задачу системой линейных уравнений, которая решаются вообще парой преобразований матрицы?
С огромным интересом послушаю ваш вариант решения этой задачи. (Уверяю Вас, с теорией оптимизации я знаком)
OK, задача называется binary integer programming.
www.mpi-inf.mpg.de/~behle/publications/behle_thesis.pdf
Почитав, я выяснил, что если решения дожны быть бинарными, то все как-то усложняется. Так что там для аналитического вычислительно-несложного решения пока однозначного решения вроде нет. Понятен тогда интерес топикстартера к эвристическому методу.
www.mpi-inf.mpg.de/~behle/publications/behle_thesis.pdf
Почитав, я выяснил, что если решения дожны быть бинарными, то все как-то усложняется. Так что там для аналитического вычислительно-несложного решения пока однозначного решения вроде нет. Понятен тогда интерес топикстартера к эвристическому методу.
мы на банковском в универе на предмете «Инвестиционный анализ» в прошлом году точно такую же задачу решили в тетрадке в клеточку на одном листике. Конспекты не нашёл, но если взять формулы из эконом теории, то задача решается очень просто и быстро.
Согласен, задача классическая из области линейного программирования www.optimization-online.org/DB_FILE/2002/10/549.pdf
Есть в примерах к Microsoft Solver Foundation
Есть в примерах к Microsoft Solver Foundation
Господа решившие NP-трудную задачу двумя преобразованиями матрицы или на тетрадке в клеточку — 10 декабря, в городе Стокгольме, вас лично примет король Швеции для вручения премии имени какого-то малоизвестного шведского подрывника.
Просто топикстартеру нужно было назвать задачу как следует, а то за килобайтом текста сущности сразу не легко было уловить. А так вы правы, в общем случае это NP проблема. Вот еще надо подумать, а общий ли это случай.
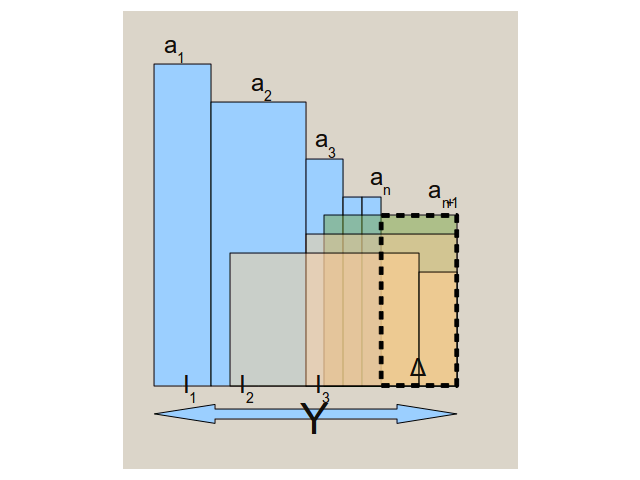
Вот я тут прикинул, почему вообще не поступить так: отсортировать инвестиции по прибыли на доллар «a» — назовем ее отдачей. Потом брать инвестиции (синий цвет на картинке) с максимальной отдачей по убывающей, пока следующая уже не влезет в бюджет Y. Тогда у нас возможно останется дельта денег, как на картинке
Мы возьмем следующие инвестиции, которые по объему больше дельты и протестируем их на превосходство по абсолютной прибыли по отношению к предпоследним инвестициям в пакете (зеленый цвет). Если таковая найдется, то мы ее вставим и все (первую попавшуюся из упорядоченного списка). Если нет — то тоже все.
Где я промахнулся?
Мы возьмем следующие инвестиции, которые по объему больше дельты и протестируем их на превосходство по абсолютной прибыли по отношению к предпоследним инвестициям в пакете (зеленый цвет). Если таковая найдется, то мы ее вставим и все (первую попавшуюся из упорядоченного списка). Если нет — то тоже все.
Где я промахнулся?
картинка с хабраstorage что-то не вставляется.
habrastorage.org/storage/f09c6809/b6b538e1/cd886647/f97f24fa.png
habrastorage.org/storage/f09c6809/b6b538e1/cd886647/f97f24fa.png
{kind=link}
Вы перебираете лишь последние добавленные элементы, тогда как оптимальное решение может потребовать замены любого из добавленных элементов, что разрушит всю структуру.
Максимально, что можно выйграть, добавляя n+1 элемент и выкидывая предпоследний (или предыдущие в любых комбинациях) это a(n+1)*delta. Если в элементах а1 до аn не находится того, что по площади (т.е. абсолютной прибыли) меньше a(n+1)*delta, и по ширине (т.е. объему инвестиций) >= (I(n+1) — delta), то больше и нечего искать. Т.е. I(n+1) пропускаем и идем дальше по цепочке. Все остальные элементы шире дельты будут не интересны, более узкие мы добавляем и сводим задачу к предыдущей.
Жалко, что картинку не видно, но вы можете ее открыть в соседнем окошке, чтобы было понятны обозначения.
Жалко, что картинку не видно, но вы можете ее открыть в соседнем окошке, чтобы было понятны обозначения.
не, не вручат. по математике по крайней мере. придется впихивать ее в какое нить физическое или химическое научное достижение. Ну или на Абелевскую надеяться.
UshkurKayuf — да
А вообще данные методы с фиксированной одновременной предсказуемой прибылью без учета влияния на рынок применимы в очень ограниченном круге задач, например расчет депозита или управления облигационным портфелем (с предварительным учетом веса рисков).
А вообще данные методы с фиксированной одновременной предсказуемой прибылью без учета влияния на рынок применимы в очень ограниченном круге задач, например расчет депозита или управления облигационным портфелем (с предварительным учетом веса рисков).
не вижу «эвристик», вижу простейший жадный алгоритм.
описанная вами задача называется «задача о рюкзаке», и с применением динамического программирования она решается за O (число возможных инвестиций * максимальная сумма портфеля) по памяти и по времени (то есть 8гб памяти и 2 часа времени). естественно, мы можем немножечко схитрить и стереть последние 3 нолика в суммах (ну, плюс-минус тысяча в рельной жизни погоды не сделают), сократив таким образом в тысячу раз перебор.
Никто не спорит, но
1. расход памяти
2. сложность по времени всё равно больше, чем у эвристик.
Хотя, соглашусь с Вами, динамическое программирование — очень и очень мощный аппарат.
1. расход памяти
2. сложность по времени всё равно больше, чем у эвристик.
Хотя, соглашусь с Вами, динамическое программирование — очень и очень мощный аппарат.
вот только решение походу от задачи комивояжера.
а ещё, если вначале воспользоваться вашими эвристиками, а потом запустить полный перебор с отсечением по найденной эвристики, то проверять мы будем не каждый сотый вариант и даже не каждый тысячный, а гораздо реже. и имеем, вообще говоря, неплохие шансы наш перебор за обозримое время закончить.
а разве порядок приобретения инвестиций имеет значение? Если нет, то зачем вообще обходить граф?
Задача в данной постановке является аналогичной задаче об упаковке ранца, которая, в свою очередь являясь NP-полной, решается за псевдо-полиномиальное время методом динамического программирования.
Построенная с помощью жадного алгоритма аппроксимация решения задачи об упаковке ранца с неограниченными числом изделий(unbounded problem) гарантированно составляет не менее 1/2 оптимального решения. В случае ограниченности числа изделий(bounded problem) полученная аппроксимация может быть далека от оптимума.
Поэтому патетика в духе:
мне кажется совершенно неуместной.
Построенная с помощью жадного алгоритма аппроксимация решения задачи об упаковке ранца с неограниченными числом изделий(unbounded problem) гарантированно составляет не менее 1/2 оптимального решения. В случае ограниченности числа изделий(bounded problem) полученная аппроксимация может быть далека от оптимума.
Поэтому патетика в духе:
Конечно, невозможно гарантировать, что это решение будет наилучшем, но оно точно будет достаточно хорошим.
мне кажется совершенно неуместной.
Эта-же задача существует в формулировке «задача о раскрое» или «задача о рюкзаке». Эффективно решается с использованием генетического алгоритма.
эффективно? с помощью генетики??? Вы ничего не путаете?
Уверяю вас!!!
Я, честно говоря, тоже не могу поверить…
На каких основаниях вы считаете, что это неэффективно?
Сама суть генетических алгоритмов. Десятки поколений, сотни особей в каждом поколении, постоянные мутации.
И что?
Не похоже это всё на эффективный алгоритм.
cудя по тому, что конечным (? конечным ли?) продуктом такого алгоритма является человек, он доказал свою эффективность на деле
Ну, если в роли ососбей представить себе смешных человечков с усиками прыгающими внутри массивов вдоль и поперек, то, пожалуй да, не похож. Но с точки зрения математики использование BL-генетического алгоритма является одним из самых эффективных способов решения данной задачи, дающий средний коэффициент выше 92%, и с 1999 года создано множество более эффективных его модификаций.
В генетических алгоритмах есть тёмное место — выбор признака для мутации. Некоторые с особым цинизмом честно генерят псевдослучайное висло, что делает результат невоспроизводимым :)
На всякий случай — пример не имеет АБСОЛЮТНО ничего общего с инвестициями — это просто иллюстрация задачи о рюкзаке (см комментарии выше).
Причина — в условии дана прибыль от инвестиций — величина как правило неизвестная. Любые инвестиции предполагают риск НЕ получить прогнизируемую прибыль — а вот тут уже начинается самое интересное.
Просто хочу предупредить желающих заработать миллионы, написав нехитрый алгоритм оптимизации ;-)
И биржевые боты к портфельным инвестициям вааабще не имеют отношения. Трейдинг != инвестиции.
Причина — в условии дана прибыль от инвестиций — величина как правило неизвестная. Любые инвестиции предполагают риск НЕ получить прогнизируемую прибыль — а вот тут уже начинается самое интересное.
Просто хочу предупредить желающих заработать миллионы, написав нехитрый алгоритм оптимизации ;-)
И биржевые боты к портфельным инвестициям вааабще не имеют отношения. Трейдинг != инвестиции.
Механические торговые системы? Счёты и печатающая машинка что ли?
Что-то я недопонимаю… В чём отличие Вашей задачи от задачи о рюкзаке ?
Если не кратны, тогда да, в том-то и цимес NP-полноты.
Но я бы конечно решил её для кратных миллиону весов (= для небольших чисел, только вес меряется не в долларах а в миллионах), и получил бы первое приближение. Оно вообще полезно с многих точек зрения.
Но я бы конечно решил её для кратных миллиону весов (= для небольших чисел, только вес меряется не в долларах а в миллионах), и получил бы первое приближение. Оно вообще полезно с многих точек зрения.
очень интересно понять что думал человека, когда писал словосочетание «восхождение на холм» вместо «метод градиента» ЛОЛ!!!
Уважаемый автор!
Ваша статья имеет больше отношения к теории оптимизации (в части рассмотрения модификации задачи о рюкзаке), но к теории формирования портфеля имеет слабое отношение, так как ни один управляющий портфелем инвестиций не ставит своей задачей максимизацию прибыли. В статье не рассмотрен такой показатель как риск инвестиции и влияние одной инвестиции на другую. Портфель инвестиций это как минимум двухпараметрическая функция от доходности и риска. По поводу портфельной теории начните читать отсюда
Ваша статья имеет больше отношения к теории оптимизации (в части рассмотрения модификации задачи о рюкзаке), но к теории формирования портфеля имеет слабое отношение, так как ни один управляющий портфелем инвестиций не ставит своей задачей максимизацию прибыли. В статье не рассмотрен такой показатель как риск инвестиции и влияние одной инвестиции на другую. Портфель инвестиций это как минимум двухпараметрическая функция от доходности и риска. По поводу портфельной теории начните читать отсюда
Хорошая статья иллюстрирующая некоторые из дискретных методов оптимизации. Не рассмотрены правда многие другие варианты например генетические алгоритмы и поиск по табу. Под эвристиками еще часто подразумевают некие функции которые показывают куда дальше вероятно идти поиске и строятся применительно к конкретной задаче.
Как мне кажется данная задача сводится к математическому программированию, максимизация линейной суммы при ограничении на другую линейную сумму. А далее можно применить симлекс метод.
Как мне кажется данная задача сводится к математическому программированию, максимизация линейной суммы при ограничении на другую линейную сумму. А далее можно применить симлекс метод.
Sign up to leave a comment.
Эвристические алгоритмы формирования портфеля инвестиций