Эта статья об алгоритме распознавания авторства, реализованном в проекте «Текстовый анализатор». В продолжении статьи мы рассмотрим конечный автомат для разбиения текста на уровни. (Начало и окончание).
Структура статьи:
Дополнительные материалы:
Нужно:
Выводы:
КА — конечный автомат ([1], [2], [3]). Одно из его применений заключается в том, что он распознаёт в цепочке поступающих символов те или иные конструкции: слова, составные знаки препинания, функции, структуры, целые классы с их методами и полями. Так действуют спеллчекеры, анализаторы исходного кода, компиляторы, инструменты для подсветки синтаксиса, так действует ваш компьютер, и прочее, и прочее. Применимость у КА огромная. Например, своим студентам я задавал сделать генерацию сказки с помощью недетерминированных КА, — и такое возможно. Здесь применяется КА на стратегиях ([1]), написанный Сергеем Сацким ([1]) аж в 2003 году.
Конечный автомат Сацкого ([h]) реализован на паттерне «Стратегия». (Strategy, [1], [2], [3]). В качестве стратегий приходят типы SState, SEvent (событие, состояние), SFunctor (функтор перехода от одного состояния к другому) и SUnknownEventStrategy (поведение КА, если событие не распознано). Вот как выглядит функция, распознающая событие и переводящая КА в новое состояние:
Пусть где-то во внешней среде мы перебираем текст посимвольно. Мы берём очередной символ и передаем его в функцию ProcessEvent(). Конечный автомат по этому символу выбирает ячейку в таблице переходов, основываясь так же на текущем состоянии. В ячейке сказано, какое состояние должно наступить, и что делать дальше. Я слегка изменил КА, чтобы он понимал «символ» как событие. Так же я переопределил стратегию «Состояние», подсунув свой класс состояния. Таким образом, таблица переходов состояла из мною определенных событий и состояний.
И ее было очень трудно разрабатывать. Она росла как на дрожжах. Если состояние было «Пусто», и приходила буква «А», то мы должны начать распознавание слова, предложения и абзаца, перейдя в соответствующее состояние. Если приходила точка, то мы должны перейти в специальное состояние и подождать, а не является ли это составным знаком препинания. Могли прийти «Б», «В», «б», «в», "!", «1», «2»… Все буквы алфавита, все знаки препинания, вообще все знаки таблицы ASCII. И на них ведь нужно как-то реагировать! Представьте себе таблицу, в которой ~ 255 строк (одна строка — одно событие, один символ) и около 20 столбцов, состояний КА. Это же убиться веником, сколько ячеек с командами перехода заполнять! 20*255=5100 ячеек. Я нашёл более простой подход. Все однотипные символы помещаются в наборы символов ([CCharsSet.h]; [UConstants.h]), и событием уже считается весь набор символов, если пришёл его символ. Разумеется, наборы могут пересекаться. Например, буква «Б» является элементов следующих наборов: «Все символы», «Буква», «Прописная буква», «Русская буква», «Русская прописная буква». Знак «точка» входит в наборы «Все символы», «Знак препинания», «Знак конца абзаца». И так далее. Наборов вышло порядочно, однако, это меньше, чем всех символов. Таблица переходов ([xls]) сократилась в десятки раз. Ещё одно важное преимущество в том, что наборы можно изменять, не влияя на таблицу переходов. Ну, забыли мы букву «Ё», ну вставили в соответствующие наборы, и делов-то!..
Как это вообще работает? Ведь пропуская текст через конечный автомат, мы должны строить дерево уровней. Если на словах, то конечный автомат, выполняя инструкцию при наступлении события, вызывает связанную с событием функцию. Таких функций несколько ([UParSentWordFSM.h]), и все они строят общее дерево, получая на вход указатель на него. Давайте поближе взглянем на то, как описывается конфигурация КА.
Класс TState, как следует из его названия, является состоянием КА. Внутри него лежит указатель на функцию для построения дерева, и указатель на само дерево. Функция вызывается, когда у TState запрашивается метод OnEnter(). Класс, который это дерево представляет (TCFCustomUnitDivisionTreeItem), довольно таки сложен: это доопределение какого-то более абстрактного шаблонного класса ([h]). Мы сейчас не будем заострять на нём внимание. Посмотрим дальше, на функции построения дерева.
У них у всех один тип. Мы можем замещать эти функции в классе TState друг другом, — таким образом, имеем здесь перегрузку и полиморфизм функций ([1], [2]).
Но это всё определения и подготовка к главному. Мы же должны получить конкретный объект, содержащий настройки для КА, так? Вот как выглядит функция, возвращающая такой объект:
Очень хорошо видно, как в таблицу КА вносятся события и состояния, но саму таблицу в этих знаках "<<" увидеть трудно. Просто поверьте, здесь она записана вся.
Можно было бы ещё заглянуть в класс TEvent, который, на самом деле, TCharsSetEvent ([cpp], [h]). Любопытным — добро пожаловать, а мы перейдём к менеджеру КА — TFiniteStateMachineManager ([h]). Задача этого класса следующая: пользуясь унифицированными интерфейсами, провести анализ с помощью абстрактного КА над абстрактным источником событий. Так же в менеджер можно передать функцию, которая будет где-то отображать прогресс распознавания. Код этого класса весьма богат, и я приведу только самые интересные участки.
Опять имеем дело с шаблонами. Если быть точным, то здесь также представлен паттерн «Стратегия». Мало того, что у нас сам конечный автомат на стратегиях, так ещё и какой-то менеджер! Не утаю, скажу, что этот же менеджер используется для создания карты благозвучия, только работает он с другим конечным автоматом, специальным. Ему, по сути, вообще всё равно, что за КА подсунут, лишь бы был интерфейс одинаков. Менеджер берёт этот «подсунутый» КА, и перенаправляет всю работу ему. Один КА обрабатывает правила звучания, другой — разбивает текст на уровни. В этом и есть суть паттерна «Стратегия»: мы конфигурируем наш класс объектами-стратегиями, которые и делают реальную работу. Например, если бы мне было нужно, что при наступлении события вызывался какой-нибудь фильтр, я бы мог заменить событие EventType, передав в качестве стратегии другой класс, реализующий фильтры.

В функции Process() всё просто. Создается объект конечного автомата _Machine, настраивается описателем (таблица переходов, начальное состояние), и запускается процесс распознавания в цикле. «Итератор», переданный в качестве второго параметра в класс EventType, обозначает индекс символа в тексте. Если событие вызвало, например, состояние «Начать слово», то индекс запишется в RangeItem как BeginIndex. И наоборот: если событие — это конец слова (предложения, абзаца), то индекс станет конечным для данного диапазона. Так мы и получаем список из RangeItem, соотнесенных с текстом.
Почему слово «итератор» я взял в кавычки? Потому что это не настоящий итератор, а всего лишь целочисленная переменная. Но если бы нужно было сделать по-настоящему универсальный менеджер, то пришлось бы абстрагироваться от объектов-событий. Менеджер вообще не должно волновать, в каких списках, таблицах или массивах там хранятся данные, откуда берутся, сколько элементов, и в каком они порядке. А чтобы обеспечить проход по ним, можно было бы использовать паттерн «Итератор» (Iterator, [1], [2]). Великих изменений не потребовалось бы, чтобы заставить цикл работать с итераторами:

Результатом работы этого КА будут деревья разбиения текстов. Далее нужно из этих разбиений выбрать участки для сравнения. Алгоритм довольно прост.
— Для каждого текста участки сортируются по возрастанию длины.
— Составляется шаблон минимального соответствия. В нем прописывается, сколько участков одинаковой длины можно взять из всех текстов. Если у всех текстов есть 10 абзацев длиной 1000, а у одного текста таких абзацев всего 8, то минимальное соответствие — 8 участков. Так — для каждой длины.
— В соответствии с шаблоном выбираются участки из текстов.
— В алгоритме поочерёдно участвуют все уровни: абзацев, предложений и слов.
Теперь у нас есть образцы, и можно приступить к сбору характеристик.
Структура статьи:
- Анализ авторства
- Знакомство с кодом
- Внутренности TAuthoringAnalyser и хранение текстов
- Разбиение на уровни конечным автоматом на стратегиях
- Сбор частотных характеристик
- Нейросеть Хэмминга и анализ авторства
Дополнительные материалы:
- Исходники проекта «Текстовый анализатор» (Borland C++ Builder 6.0)
- Тестирование нейросистемы Хэмминга в Excel'е ([xls])
- Таблица переходов для КА, разбивающего текст на уровни ([xls])
- Расчет благозвучия отдельных букв ([xls])
- Презентация дипломного проекта «Текстовый анализатор» ([ppt])
- Презентация проекта «Карта благозвучия» ([ppt])
- Все эти материалы в сжатом виде ([zip], [7z], [rar])
4. Разбиение на уровни конечным автоматом на стратегиях
Нужно:
- Разбить текст на слова, предложения и абзацы.
- Обращаться к этим уровням единообразно, ничего не зная о внутренней реализации.
- Не хранить эти уровни в натуральном виде, иначе тексты бы копировались огромное количество раз.
Выводы:
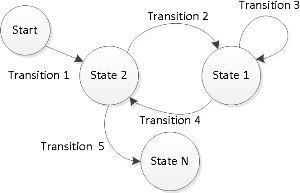
- Уровни будут храниться в виде списков с индексами. Логичным образом сюда вписывается концепция диапазонов (Range, [1], [2], [3]); и хотя в то время я еще ничего не знал ни про Range, ни про Александреску ([1]), примитивные диапазоны у меня получились. У диапазонов есть начальный индекс и конечный индекс: RangeItem(BeginIndex, EndIndex), либо начальный индекс и количество (смещение): Range(BeginIndex, Count). Индексы в точности соответствуют позициям символов в тексте. Если мы хотим обозначить весь текст, то это будет RangeItem(1, Length(Text)). Если нам нужен какой-то абзац посередине, то мы получим RangeItem(312031, 312355). Список диапазонов будет представлять собой куски текста без их прямого копирования.
- Диапазоны надо скрыть за абстракцией. Так, обращаясь к списку диапазонов, представляющих собой первый и последний абзацы, мы должны лишь видеть текст, который в них скрывается. Нам должно быть всё равно, сколько там этих Range и куда они указывают. Пусть мы будем обращаться к более высокому уровню, а он нам предоставит то, что мы хотим.
- Определить слова — не проблема. Знай себе отделяй все буквы между другими знаками… Абзацы тоже выявляются легко. Если, конечно, забыть, что в разных ОС конец абзаца обозначается по-разному ([1]). А вот предложения… Сколько, вы бы думали, у нас есть «легальных» знаков, завершающих предложение? Три?! Точка, вопрос и восклицание?.. Куда там!.. Они же еще могут сочетаться!!! ([1]). Но даже это еще и не всё; я встречал конструкции, где в одном предложении фактически находится два и больше. И если считать неправильно, то вместо семи предыдущих предложений можно насчитать более пятнадцати. Вывод, в принципе, очевиден: нужен конечный автомат.
КА — конечный автомат ([1], [2], [3]). Одно из его применений заключается в том, что он распознаёт в цепочке поступающих символов те или иные конструкции: слова, составные знаки препинания, функции, структуры, целые классы с их методами и полями. Так действуют спеллчекеры, анализаторы исходного кода, компиляторы, инструменты для подсветки синтаксиса, так действует ваш компьютер, и прочее, и прочее. Применимость у КА огромная. Например, своим студентам я задавал сделать генерацию сказки с помощью недетерминированных КА, — и такое возможно. Здесь применяется КА на стратегиях ([1]), написанный Сергеем Сацким ([1]) аж в 2003 году.
Copy Source | Copy HTML
- template <class SState, class SEvent, class SFunctor = SEmptyFunctor<SState,SEvent>, class SUnknownEventStrategy = SThrowStrategy<SEvent> >
- class SFiniteStateMachine
- {
- public:
- typedef SState StateType;
- typedef SEvent EventType;
-
- private:
- StateType _CurrentState; // Current machine state
- std::vector<StateType> _States; // A list of the registered states
- std::vector<EventType> _Events; // A list of the registered events
- std::vector< std::vector<StateType> > _Transitions; // A table of transitions between states
- SFunctor _Functor; // Transition function
- SUnknownEventStrategy _UnknownEventStrategy; // Unknown event strategy
- std::deque<EventType> _EventsQueue; // Internal events queue to support events
- // that were generated in the transition functions
- bool _InProcess; // To be sure that we are in the process of events
- int _CurrentStateIndex; // Index of column in a transition table (0 - based)
- StateType _InitialState; // Start machine state
- // ......
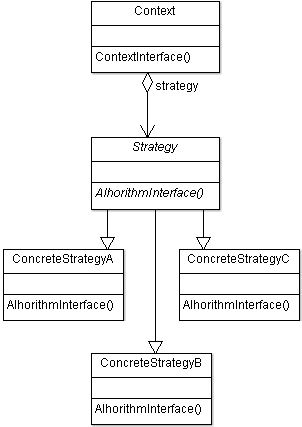
Конечный автомат Сацкого ([h]) реализован на паттерне «Стратегия». (Strategy, [1], [2], [3]). В качестве стратегий приходят типы SState, SEvent (событие, состояние), SFunctor (функтор перехода от одного состояния к другому) и SUnknownEventStrategy (поведение КА, если событие не распознано). Вот как выглядит функция, распознающая событие и переводящая КА в новое состояние:
Copy Source | Copy HTML
- inline void ProcessEvent(const EventType & tEvent)
- {
- int EventIndex(GetEventIndex(tEvent));
- if (EventIndex == -1) return;
-
- StateType OldState(_CurrentState); // Сохраняем старое состояние.
-
- _CurrentState = (_Transitions[EventIndex])[_CurrentStateIndex]; //Определяем новое состояние.
- _CurrentStateIndex = GetStateIndex(_CurrentState);
-
- _Functor(OldState, tEvent, _CurrentState); // Выполняем действие, связанное с новым состоянием.
- }
Пусть где-то во внешней среде мы перебираем текст посимвольно. Мы берём очередной символ и передаем его в функцию ProcessEvent(). Конечный автомат по этому символу выбирает ячейку в таблице переходов, основываясь так же на текущем состоянии. В ячейке сказано, какое состояние должно наступить, и что делать дальше. Я слегка изменил КА, чтобы он понимал «символ» как событие. Так же я переопределил стратегию «Состояние», подсунув свой класс состояния. Таким образом, таблица переходов состояла из мною определенных событий и состояний.
И ее было очень трудно разрабатывать. Она росла как на дрожжах. Если состояние было «Пусто», и приходила буква «А», то мы должны начать распознавание слова, предложения и абзаца, перейдя в соответствующее состояние. Если приходила точка, то мы должны перейти в специальное состояние и подождать, а не является ли это составным знаком препинания. Могли прийти «Б», «В», «б», «в», "!", «1», «2»… Все буквы алфавита, все знаки препинания, вообще все знаки таблицы ASCII. И на них ведь нужно как-то реагировать! Представьте себе таблицу, в которой ~ 255 строк (одна строка — одно событие, один символ) и около 20 столбцов, состояний КА. Это же убиться веником, сколько ячеек с командами перехода заполнять! 20*255=5100 ячеек. Я нашёл более простой подход. Все однотипные символы помещаются в наборы символов ([CCharsSet.h]; [UConstants.h]), и событием уже считается весь набор символов, если пришёл его символ. Разумеется, наборы могут пересекаться. Например, буква «Б» является элементов следующих наборов: «Все символы», «Буква», «Прописная буква», «Русская буква», «Русская прописная буква». Знак «точка» входит в наборы «Все символы», «Знак препинания», «Знак конца абзаца». И так далее. Наборов вышло порядочно, однако, это меньше, чем всех символов. Таблица переходов ([xls]) сократилась в десятки раз. Ещё одно важное преимущество в том, что наборы можно изменять, не влияя на таблицу переходов. Ну, забыли мы букву «Ё», ну вставили в соответствующие наборы, и делов-то!..
Как это вообще работает? Ведь пропуская текст через конечный автомат, мы должны строить дерево уровней. Если на словах, то конечный автомат, выполняя инструкцию при наступлении события, вызывает связанную с событием функцию. Таких функций несколько ([UParSentWordFSM.h]), и все они строят общее дерево, получая на вход указатель на него. Давайте поближе взглянем на то, как описывается конфигурация КА.
Copy Source | Copy HTML
- class TState;
- typedef TCharsSetEvent TEvent;
-
- typedef TCFDivisionTreeItem<TCFLevelDataType, TUnitType> TCFCustomUnitDivisionTreeItem;
- typedef TCFTreeLevel<TCFLevelDataType, TUnitType> TCFCustomUnitTreeLevel;
-
- typedef void (*TFuncPtr)(TCFCustomUnitDivisionTreeItem *, const TEvent &);
- typedef TStateMachineDescriptor<TState, TEvent> TParSenWordDescriptor;
-
- /*Класс используемого состояния.*/
-
- class TState : public TFunctionalState<TEvent, TTextString>
- {
- private:
- TFuncPtr _Function;
- TCFCustomUnitDivisionTreeItem *_TargetTree;
- public:
- void OnEnter(const TState & tStateFrom, const TEvent & tEvent) {
- _Function(_TargetTree, tEvent);
- };
-
- TState(const TTextString & tName, TFuncPtr tFunc, TCFCustomUnitDivisionTreeItem * tTargetTree)
- : TFunctionalState<TEvent, TTextString> (tName, sat_None), _Function(tFunc), _TargetTree(tTargetTree){};
- };
Класс TState, как следует из его названия, является состоянием КА. Внутри него лежит указатель на функцию для построения дерева, и указатель на само дерево. Функция вызывается, когда у TState запрашивается метод OnEnter(). Класс, который это дерево представляет (TCFCustomUnitDivisionTreeItem), довольно таки сложен: это доопределение какого-то более абстрактного шаблонного класса ([h]). Мы сейчас не будем заострять на нём внимание. Посмотрим дальше, на функции построения дерева.
Copy Source | Copy HTML
- void FEmpty(TCFCustomUnitDivisionTreeItem * tItem, const TEvent & tEvent)
- {
- return;
- };
-
- void FOpenParagraph(TCFCustomUnitDivisionTreeItem * tTree, const TEvent & tEvent)
- {
- TCFCustomUnitDivisionTreeItem NewItem( 0, TRangeItem(tEvent.Iterator(), tEvent.Iterator()));
- tTree->AddItem( 0, NewItem);
- };
-
- void FOpenSentence(TCFCustomUnitDivisionTreeItem * tTree, const TEvent & tEvent)
- {
- TCFCustomUnitDivisionTreeItem NewItem(1, TRangeItem(tEvent.Iterator(), tEvent.Iterator()));
- tTree->AddItem(1, NewItem);
- };
-
- // .......
-
- void FCloseAll(TCFCustomUnitDivisionTreeItem * tTree, const TEvent & tEvent)
- {
- FCloseWord(tTree, tEvent);
- FCloseSentence(tTree, tEvent);
- FCloseParagraph(tTree, tEvent);
- };
-
- // ... и еще несколько функций ...
У них у всех один тип. Мы можем замещать эти функции в классе TState друг другом, — таким образом, имеем здесь перегрузку и полиморфизм функций ([1], [2]).
Но это всё определения и подготовка к главному. Мы же должны получить конкретный объект, содержащий настройки для КА, так? Вот как выглядит функция, возвращающая такой объект:
Copy Source | Copy HTML
- TParSenWordDescriptor Descriptor(TCFCustomUnitDivisionTreeItem * tTree)
- {
- // Начальное состояние - q0, функция - FEmpty, таблица переходов называется "Параграфы, предложения, слова".
- TParSenWordDescriptor D(TState("q0", FEmpty, tTree), "Paragraphs, Sentences, Words");
-
- // Задаём состояния, причем у каждого - своё имя: q0, q1, ... q14.
- // Каждому состоянию передаем функцию (FEmpty, FOpenAll...), которая должна вызываться, если состояние наступает.
- // Так же передаем указатель на дерево, которое строим - tTree.
- D << TState("q0", FEmpty, tTree)
- << TState("q1", FOpenAll, tTree)
- << TState("q2", FOpenSentenceOpenWord, tTree)
- << TState("q3", FOpenWord, tTree)
- << TState("q4", FEmpty, tTree)
- << TState("q5", FCloseWord, tTree)
- << TState("q6", FCloseSentence, tTree)
- << TState("q7", FCloseSentenceOpenSentenceOpenWord, tTree)
- << TState("q8", FEmpty, tTree)
- << TState("q9", FEmpty, tTree)
- << TState("q10", FCloseWord, tTree)
- << TState("q11", FCloseAll, tTree)
- << TState("q12", FCloseSentenceCloseParagraph, tTree)
- << TState("q13", FCloseParagraph, tTree)
- << TState("q14", FEmpty, tTree);
-
- // Задаём события, у каждого - свое имя ("WinParagraph", "SentenceEnd"...).
- // cWinParagraph, cSentenceEnd - это наборы символов, описанные в UConstants.h.
- D << TEvent("WinParagraph", cWinParagraph)
- <<"q0"<<"q11"<<"q11"<<"q11"<<"q11"<<"q12"<<"q12"<<"q11"<<"q12"<<"q13"<<"q12"<<"q0"<<"q0"<<"q0"<<"q12";
- D << TEvent("SentenceEnd", cSentenceEnd)
- <<"q0"<<"q10"<<"q10"<<"q10"<<"q10"<<"q14"<<"q14"<<"q10"<<"q14"<<"q9"<<"q14"<<"q0"<<"q0"<<"q0"<<"q14";
- D << TEvent("Letters", cLetters + cDigits)
- <<"q1"<<"q4"<<"q4"<<"q4"<<"q4"<<"q3"<<"q2"<<"q4"<<"q3"<<"q2"<<"q7"<<"q1"<<"q1"<<"q1"<<"q7";
- D << TEvent("Space", cSpace + cTab)
- <<"q0"<<"q5"<<"q5"<<"q5"<<"q5"<<"q8"<<"q9"<<"q5"<<"q8"<<"q9"<<"q6"<<"q0"<<"q0"<<"q0"<<"q6";
- D << TEvent("PunctMarks and other symbols", TCharsSet(cPrintable) >> cWinParagraph >> cSentenceEnd >> cLetters >> cDigits >> cSpace >> cTab)
- <<"q0"<<"q5"<<"q5"<<"q5"<<"q5"<<"q8"<<"q9"<<"q5"<<"q8"<<"q9"<<"q14"<<"q0"<<"q0"<<"q0"<<"q14";
- D << TEvent("EndSign", TCharsSet(CTextStringEndSign))
- <<"q0"<<"q11"<<"q11"<<"q11"<<"q11"<<"q12"<<"q13"<<"q11"<<"q12"<<"q13"<<"q12"<<"q0"<<"q0"<<"q0"<<"q12";
-
- return D;
- };
Очень хорошо видно, как в таблицу КА вносятся события и состояния, но саму таблицу в этих знаках "<<" увидеть трудно. Просто поверьте, здесь она записана вся.
Можно было бы ещё заглянуть в класс TEvent, который, на самом деле, TCharsSetEvent ([cpp], [h]). Любопытным — добро пожаловать, а мы перейдём к менеджеру КА — TFiniteStateMachineManager ([h]). Задача этого класса следующая: пользуясь унифицированными интерфейсами, провести анализ с помощью абстрактного КА над абстрактным источником событий. Так же в менеджер можно передать функцию, которая будет где-то отображать прогресс распознавания. Код этого класса весьма богат, и я приведу только самые интересные участки.
Copy Source | Copy HTML
- template <class EventType, class FiniteStateMachineType, class StateMachineDescriptorType, class SourceType>
- class TFiniteStateMachineManager
- {
- private:
-
- StateMachineDescriptorType _Descriptor;
- SourceType _Source;
-
- TUInt _Begin;
- TUInt _End;
- TUInt _Iterator;
- public:
- // <......>
- TFiniteStateMachineManager(const StateMachineDescriptorType &tDescriptor, const SourceType &tSource)
- :
- _Descriptor(tDescriptor),
- _Source(tSource),
- _ReportStep( 0),
- _ProgressFunc(NULL)
- {};
- // <......>
Опять имеем дело с шаблонами. Если быть точным, то здесь также представлен паттерн «Стратегия». Мало того, что у нас сам конечный автомат на стратегиях, так ещё и какой-то менеджер! Не утаю, скажу, что этот же менеджер используется для создания карты благозвучия, только работает он с другим конечным автоматом, специальным. Ему, по сути, вообще всё равно, что за КА подсунут, лишь бы был интерфейс одинаков. Менеджер берёт этот «подсунутый» КА, и перенаправляет всю работу ему. Один КА обрабатывает правила звучания, другой — разбивает текст на уровни. В этом и есть суть паттерна «Стратегия»: мы конфигурируем наш класс объектами-стратегиями, которые и делают реальную работу. Например, если бы мне было нужно, что при наступлении события вызывался какой-нибудь фильтр, я бы мог заменить событие EventType, передав в качестве стратегии другой класс, реализующий фильтры.
Copy Source | Copy HTML
- TFiniteStateMachineManager & Process()
- {
- _Begin = _Source.Begin();
- _End = _Source.End();
-
- FiniteStateMachineType _Machine(_Descriptor.StartState(), _Descriptor.Proxy());
-
- for (_Iterator=_Begin; _Iterator<=_End; _Iterator++)
- {
- _Machine << EventType(_Source[_Iterator], _Iterator);
- };
-
- _Machine << EventType(_Source.EndSign(), _End+1);
-
- return *this;
- };
В функции Process() всё просто. Создается объект конечного автомата _Machine, настраивается описателем (таблица переходов, начальное состояние), и запускается процесс распознавания в цикле. «Итератор», переданный в качестве второго параметра в класс EventType, обозначает индекс символа в тексте. Если событие вызвало, например, состояние «Начать слово», то индекс запишется в RangeItem как BeginIndex. И наоборот: если событие — это конец слова (предложения, абзаца), то индекс станет конечным для данного диапазона. Так мы и получаем список из RangeItem, соотнесенных с текстом.
Почему слово «итератор» я взял в кавычки? Потому что это не настоящий итератор, а всего лишь целочисленная переменная. Но если бы нужно было сделать по-настоящему универсальный менеджер, то пришлось бы абстрагироваться от объектов-событий. Менеджер вообще не должно волновать, в каких списках, таблицах или массивах там хранятся данные, откуда берутся, сколько элементов, и в каком они порядке. А чтобы обеспечить проход по ним, можно было бы использовать паттерн «Итератор» (Iterator, [1], [2]). Великих изменений не потребовалось бы, чтобы заставить цикл работать с итераторами:
Copy Source | Copy HTML
- // ......
- SourceType *_Source;
- // ......
-
- SourceType::Iterator _Iterator = _Source->Begin();
- for (; _Iterator != _Source->End(); ++_Iterator)
- {
- _Machine << EventType(*_Iterator);
- };
Результатом работы этого КА будут деревья разбиения текстов. Далее нужно из этих разбиений выбрать участки для сравнения. Алгоритм довольно прост.
— Для каждого текста участки сортируются по возрастанию длины.
— Составляется шаблон минимального соответствия. В нем прописывается, сколько участков одинаковой длины можно взять из всех текстов. Если у всех текстов есть 10 абзацев длиной 1000, а у одного текста таких абзацев всего 8, то минимальное соответствие — 8 участков. Так — для каждой длины.
— В соответствии с шаблоном выбираются участки из текстов.
— В алгоритме поочерёдно участвуют все уровни: абзацев, предложений и слов.
Теперь у нас есть образцы, и можно приступить к сбору характеристик.
