Семьдесят лет назад, в 1941 году, был создан первый программируемый компьютер. С тех пор утекло немало воды, и сейчас компьютеры окружают нас повсюду. Многие аспекты устройства компьютеров сильно эволюционировали, многие, напротив, ничуть не изменились по сути. В частности, не изменился и, вероятно, никогда не изменится сам принцип работы центральных процессоров — алгоритмическая модель. Хорошо понятны физические ограничения этой модели, и соответственно, отчётливо виден предел развития центральных процессоров в смысле их быстродействия. Технологически до этого потолка ещё довольно далеко: несколько десятилетий развития и несколько порядков быстродействия. Но это не должно помешать нам всерьёз подумать, какими же будут процессоры на пороге предела их скоростного развития.
Делать прогнозы в этой области позволяет именно то, что возможные пути развития жёстко диктуются фундаментальными физическими ограничениями: конечностью скорости света, законами термодинамики и ограничением на минимальный размерэлементов — они не могут быть меньше молекулы.
устройствах — от микроволновок до роботизированных производственных линий и от мобильных телефонов до космических кораблей. В частности, именно управляющую роль он играет в ноутбуках, настольных рабочих станциях и игровых приставках — устройствах, называемых бытовыми компьютерами.
Существует несколько существенно различных моделей вычислений, так что АВМ будущего, возможно, будут устроены совершенно непредвиденным образом. Однако компьютер как управляющее устройство в любом случае должен содержать исполнительный блок (центральный процессор), и устройство этого блока жёстко зафиксировано его функциями: он должен уметь
– выдавать последовательные инструкции другим устройствам и
– совершать выбор дальнейшей программы действий в зависимости от сложившихся условий.
Эти два требования автоматически предполагают модель устройства, называемую «relaxed sequential execution» по-английски или «алгоритмической моделью» в русскоязычной традиции. Эта модель, в отличие от многих других, не имеет квантового аналога, так как квантовые вычисления принципиально обратимы, а совершение выбора принципиально необратимо. Именно об этой модели пойдёт речь в следующих двух частях статьи.
Для полноты рассказа приведём список всех известных на данных момент масштабируемых аппаратных моделей вычислений:
– алгоритмическая модель, то есть, (условно-)пошаговое выполнение инструкций («условно» означает, что допускается параллельное выполнение независимых инструкций);
– потоковые векторные вычисления и их естественноеобобщение — квантовые конвейеры;
– клеточные/сетевые автоматы и их естественноеобобщение — квантовые автоматы.
На данный момент на практике за исключением модели последовательного выполнения используются лишь потоковые векторные вычисления: на бытовых компьютерах в специализированных сопроцессорах для трёхмерной графики (GPU), а также в их аналогах повышенной мощности (GPGPU) на вычислительных станциях для численных симуляций и обработки больших массивов данных. Центральный процессор делегирует некоторые специфические задачи потоковому процессору, однако управляющие функции в полной мере выполняет только он сам. С развитием квантовых вычислений это положение вещей вряд ли изменится: квантовые конвейеры и автоматы будут лишь дополнениями центрального процессора, но не его заменой.
В окружающей нас цифровой электронике в качестве переключателей используются транзисторы, а дорожки делаются из проводников.
§ 2.1. Передача сигнала
 В двоичной цифровой электронике для кодирования сигнала используются напряжение. Дорожка несёт сигнал «ноль», если на неё подан потенциал
В двоичной цифровой электронике для кодирования сигнала используются напряжение. Дорожка несёт сигнал «ноль», если на неё подан потенциал (U0 ± ε) , а если на неё подан потенциал (U1 ± ε) , то она несёт сигнал «единица». Базовые уровни U0 и U1 выбираются так, чтобы (U0 + ε) < (U1 — ε), где ε — неизбежная по техническим причинам погрешность. Переход из одного состояния в другое — это остановка или, наоборот, разгон огромного количества электронов в проводнике. Оба эти процесса занимают довольно много времени и неизбежно связаны с большими энергетическими потерями.
Существуют альтернативы цифровой электронике, лишённые этого недостатка: по дорожкам можно пускать постоянный поток электронов (т.н. спинтроника) или фотонов (т.н. фотонная логика), а сигнал кодировать при помощи поляризации этого потока. Как электроны, так и фотоны, движущиеся по одномерному волноводу, могут пребывать ровно в двух ортогональных состояниях поляризации, одно из которых объявляется нулём, а другое единицей. Что лучше — фотонная логика или спинтроника, пока непонятно:
– в обоих случаях поток частиц течёт с неизбежными тепловыми потерями, однако эти потери могут быть сколь угодно малы;
– в обоих случаях скорость потока ниже скорости света, однако может быть сколь угодно близка к ней;
– в обоих случаях требуются сложные технические приёмы, чтобы наводки, тепловой шум и фоновое излучение (пролетающие мимо случайные частицы) не искажали сигнал.
Иными словами, известные физические ограничения обеих технологий одинаковы. По всей видимости, наилучшие результаты будут давать комбинированные технологии: транспортировка фотонов выигрывает на длинных дистанциях и проигрывает на коротких; при этом уже разработаны рабочие прототипы переходников (в обе стороны) между поляризацией фотонного и электронного потока. Идеальным материалом для спинтронных дорожек является графен: он обеспечивает превосходную скорость при очень низких тепловых потерях. Кроме того, уже существуют рабочие прототипы следующих элементов:
– дорожек, надёжно сохраняющих поляризацию тока на коротких и средних дистанциях;
– ячеек памяти, способных сохранить поляризацию и затем формировать поток сохранённой поляризации.
Информация по графеновым дорожкам:
2010-06: Mass fabrication of graphene nanowires. Georgia Institute of Technology.
2011-01: Researchers managed to generate a spin current in Graphene. City University of Hong Kong.
2011-02: Creating a pure spin current in graphene. City University of Hong Kong.
2011-02: Mass production-ready bottom-up synthesis of soluble defect-free graphene nanoribbons. Max Planck Institute for Polymer Research in Mainz.
§ 2.2. Переключатели
 Применяемый в цифровой электронике транзистор представляет собой устройство с тремя контактами, работающее следующим образом:
Применяемый в цифровой электронике транзистор представляет собой устройство с тремя контактами, работающее следующим образом:
– если на средний контакт подаётся высокий потенциал, то крайние контакты соединены, переключатель находится в положении «проводник»;
– если на средний подаётся низкий потенциал, то крайние контакты разомкнуты, переключатель находится в положении «изолятор».
На данный момент успешно созданы и протестированы транзисторы, состоящие из одной молекулы. Их скорость работы и компактность практически достигают теоретического предела, однако пока не существует технологий, которые бы позволяли их массово производить и использовать. Вся современная цифровая электроника изготавливается на основе металл-оксидных полевых транзисторов (MOSFET). Уже несколько десятилетий производители микросхем лишь уменьшают линейные размеры и энергопотребление таких транзисторов, однако уже были проведены промышленные испытания некоторых типов многостоковых и беспереходных транзисторов (BDT, JNT). Такие транзисторы смогут обеспечить повышение производительности в4–6 раз. Этот переход не потребует сильных изменений технологического процесса и ожидается в ближайшие 5–10 лет.
По фундаментальным термодинамическим причинам переключатели транзисторного типа не могут работать эффективно: эффективный должен быть консервативным и обратимым как логический элемент. Этим условиям удовлетворяет симметрический переключатель, называемый также вентилем Фредкина.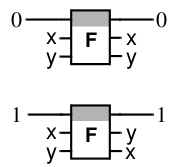 Это устройство с двумя входами In1, In2, двумя выходами Out1, Out2 и сквозной дорожкой
Это устройство с двумя входами In1, In2, двумя выходами Out1, Out2 и сквозной дорожкой С (Сontrol) . Если C находится в положении «0», входы и выходы соединены прямо: In1 с Out1, In2 с Out2; если С находится в положении «1», входы и выходы соединены крест-накрест: In1 с Out2, In2 с Out1. Скорее всего, и спиновые симметрические переключатели удастся реализовать в одномолекулярном варианте, сочетающем максимальные компактность, скорость работы и эффективность.
Как из транзисторов, так и из симметрических переключателей можно изготовить логические схемы любой сложности, однако симметрические переключатели гораздо более экономны. Например, для клонирования сигнала и логических операций «не», «и», «или», «и не» и «следует» требуется всего один симметрический переключатель, «исключающее или», «не или» и «не и» требуют двух переключателей. Для реализации этих операций на транзисторах требуется от 4 до 6 транзисторов:
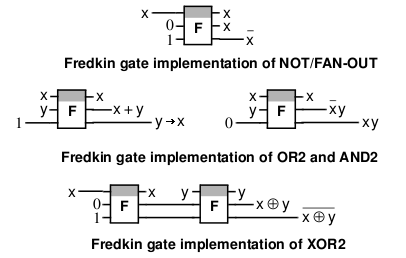
 Быстрый одноразрядный сумматор (half adder) использует четыре симметрических переключателя (вместо 12 транзисторов) и обеспечивает в идеале существенно большую скорость работы, чем транзисторный аналог: время его работы составляет всего 2τ, где τ — время прохождения сигналом одного переключателя и одной дорожки. На более сложных схемах компактность и выигрыш в скорости симметрических переключателей проявляются ещё более явно. Звено многоразрядного сумматора (full adder) состоит из десятков транзисторов, в то время как реализация на симметрических переключателях требует от 4 (самый компактный вариант) до 7 (самый быстрый вариант) переключателей:
Быстрый одноразрядный сумматор (half adder) использует четыре симметрических переключателя (вместо 12 транзисторов) и обеспечивает в идеале существенно большую скорость работы, чем транзисторный аналог: время его работы составляет всего 2τ, где τ — время прохождения сигналом одного переключателя и одной дорожки. На более сложных схемах компактность и выигрыш в скорости симметрических переключателей проявляются ещё более явно. Звено многоразрядного сумматора (full adder) состоит из десятков транзисторов, в то время как реализация на симметрических переключателях требует от 4 (самый компактный вариант) до 7 (самый быстрый вариант) переключателей:
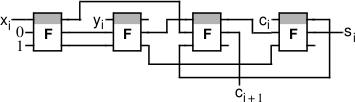
Уникальная особенность симметрических переключателей заключается в том, что с их помощью достигается максимальная компактность и скорость работы мультиплексоров и демультиплексоров, являющихся очень распространёнными составными элементами процессоров. К сожалению, симметрические переключатели становятся привлекательными лишь при использовании спинтроники или фотонной логики. Электроника обречена использовать обычные транзисторы.
* В параграфе использованы материалы и изображения из статей Bruce, Thornton et al., “Efficient Adder Circuits Based on a Conservative Reversible Logic” (Mississippi State University, Proc. IEEE Symposium on VLSI, 2002); Rentergem, de Vos, “Optimal Design of A Reversible Full Adder” (Universiteit Gent, International Journal of Unconventional Computing, 2005), а также материалы частной переписки. Изображение одномолекулярного транзистора взято из соответствующего пресс-релиза на сайте Йельского университета.
§ 2.3. Заключение
Итак, в пределе центральный процессор будущего, скорее всего, будет представлять из себя огромную паутину, где нити сделаны из графеновой ленты, проводящей поляризованный поток электронов, а в узлах находятся миниатюрные симметрические переключатели. На длинных дистанциях сигнал будет перекодироваться в свет, доставляться фотонами и перекодироваться обратно на месте назначения. Ряд специальных задач (в частности, поиск и сортировка) будут выполняться квантовыми конвейерами и автоматами.
– процессор содержит содержит определённое количество (например, 16) нумерованных ячеек памяти (например, по 64 бита каждая), которые называются операционными регистрами;
– работа процессора состоит в том, чтобы перерабатывать содержимое регистров в соответствии с программой;
– программа представляет из себя последовательность инструкций, например:
– взять значения из регистров № 2 и № 5 и записать их сумму в регистр № 8;
– считать в регистр № 4 значение из ячейки внешней памяти с адресом из регистра № 6;
– отослать число из регистра № 12 внешнему устройству NNN;
– данные и сами программы хранятся в оперативной памяти, при этом инструкции программ кодируются числами и записываются в последовательные ячейки памяти;
– номер ячейки, инструкция из которой выполняется в данный момент, хранится в специальном регистре, называемом Instruction Pointer, который по окончании выполнения передвигается на следующую ячейку памяти.
За более чем полвека с момента появления этой архитектуры были предложены десятки альтернативных арихетектур организации последовательного выполнения, однако все из них уступают ей в потолке производительности. Потолок производительности определяется (из-за конечности скорости света) линейными размерами критической части конструкции, и именно классическая регистровая архитектура обеспечивает максимальную локальность вычисления из всех предложенных на данный момент архитектур последовательного выполнения. Соответственно, именно такая архитектура сохранится, по всей видимости, и вдальнейшем — по крайней мере ещё несколько десятилетий.
§ 3.1. Функционально-логические единицы
 Описанные в первой части переключатели и дорожки являются «сырьём» для изготовления функционально-логических единиц, таких как сумматор, умножитель, мультиплексор и демультиплексор. Мультиплексоры и демультиплексоры представляют из себя устройства, похожие на сортировочные станции на железной дороге (см. иллюстрацию справа). На вход мультиплексора поступают n чисел (a1..an) и управляющее число m. На выход подаётся число am, то есть
Описанные в первой части переключатели и дорожки являются «сырьём» для изготовления функционально-логических единиц, таких как сумматор, умножитель, мультиплексор и демультиплексор. Мультиплексоры и демультиплексоры представляют из себя устройства, похожие на сортировочные станции на железной дороге (см. иллюстрацию справа). На вход мультиплексора поступают n чисел (a1..an) и управляющее число m. На выход подаётся число am, то есть m-тое из n входящих чисел. Демультиплексор — зеркальный аналог мультиплексора: передаёт входящий сигнал на m-тый из n выходов.

Задача сумматора в том, чтобы складывать подаваемые на него числа. На входn-битного сумматора поступает два числа a и b по n бит плюс однобитное число c (0 или 1). Сумматор складывает входящие числа и выдаёт результат (a + b + с) . Это (n + 1)-битное число.

Функционально-логические единицы реагируют на изменения аргументов не сразу: нужно, чтобы сигнал успел пройти весь путь от начала схемы до её конца, учитывая задержки, вызываемые прохождением через переключатели, и возможные циклы в схеме. Для каждой функционально-логической единицы при проектировании рассчитывается время работы. Разработана обширная теория проектирования функционально-логических единиц с минимальным временем работы. Так, простейший многоразрядный сумматор, выполняющий сложение по образу и подобию сложения в столбик на бумаге, требует для работы время, растущее линейно с разрядностью. В 60-е годы были разработаны схемы ускоренного переноса, уменьшающие рост до логарифмического. Использующий их сумматор на симметрических переключателях гарантированно подсчитывает результат за ⌈3 + log2(разрядность)⌉·τ, что является теоретическим пределом скорости. В случае 64-битного сумматора достигается 15-кратное ускорение о сравнению с наивной реализацией. А хитроумная оптимизация умножения, деления, вычисления тригонометрических функций позволяет подчас достичь ускорения в сотни раз.
§ 3.2. Операционные блоки
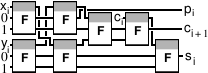
Операционныйблок — это устройство, умеющее выполнять инструкции какого-то одного типа — например, сложение и вычитание. Базовый элемент операционного блока — ячейка памяти (т.н. регистр инструкции), в которую записывают инструкцию, подлежащую выполнению. По исполнении инструкции блок очищает эту ячейку. В остальном операционный блок состоит из набора связанных между собой и с регистром инструкции функционально-логических единиц. Для примера рассмотрим операционный блок, способный выполнять инструкции вида «сложить значения из регистров № 2 и № 5 и записать сумму в регистр № 8 ».
Нам потребуется:
– регистр инструкции, в котором хранится код операции суммирования и номера регистров-операндов (2, 5 и 8 в вышеуказанной команде);
– сумматор;
– два мультиплексора, подключенные к блоку регистров с одной стороны и входам сумматора с другой: они выбирают из регистров те два, чьи номера сохранении в регистре инструкции (№ 2 и № 5 ) и подают содержимое на входы сумматора;
– один демультиплексор, подающий вывод сумматора на входы регистра, в котором его следует сохранить.
В современных процессорах операционные блоки способны производить более чем одно действие. Например, блок может содержать кроме сумматора ещё и умножитель. Для технической реализации достаточно в параллель с сумматором поставить умножитель, обрамлённые демультиплексором и мультиплексором, которые выбирают, проводить сигнал через сумматор или умножитель в зависимости от кода операции, сохранённого в регистре инструкции.
§ 3.2.1. Организация операционного цикла: синхронизация, суперскалярность, pipelining
Работа процессора представляет из себя повторение следующего цикла, в ходе которого информация проходит по кругу «регистры → операционные блоки → регистры»:
– загрузить подлежащие выполнению инструкции в операционные блоки;
– подождать результатов;
– сохранить результаты в регистры.
Существует два подхода к организации процессорного цикла: синхронный и асинхронный. В синхронных процессорах имеется сигнал-дирижёр. При его изменении («дирижёр взмахивает палочкой») значения, выдаваемые операционными блоками сохраняются в регистры, а в операционные блоки подаётся следующая инструкция. В асинхронных процессорах общего сигнала-дирижёра нет, а о готовности результата сообщают сами операционные блоки. С момента готовности задания и операндов блок начинает отслеживать готовность результата. По окончании вычисления блок даёт отмашку на сохранение результата и запрашивает следующее задание.
Синхронные процессоры имеют фиксированную тактовуючастоту — количество «взмахов дирижёрской палочки» в секунду. Время между «взмахами» приходится выбирать, исходя из самого пессимистичного сценария. Однако на практике в подавляющем большинстве случаев для выполнения операции требуется в несколько раз меньше времени. На скорость выполнения влияют три фактора:
– исходное состояние операционного блока: если инструкция или часть аргументов загружены заранее, часть блока заранее приходит в нужное состояние;
– значения операндов: так, умножение коротких чисел занимает много меньше времени, чем умножение длинных;
– уровень фоновых шумов: при температуре процессора20 °C все операции протекают гораздо быстрее, чем при температуре 90 °C .
Синхронный подход не может учитывать всех этих факторов; кроме того, зависимость уровня шумов от температуры определяется концентрацией кристаллическихдефектов — величиной, которая варьируется от экземпляра к экземпляру и увеличивается по мере старения процессора. При расчёте тактовой частоты процессора следует исходить из худшего, то есть из изношенного посредственного экземпляра, работающего при температуре 85–90 °C . Именно этим фактом пользуются люди, выполняющие так называемый «разгон» процессора («overclocking»): удачные экземпляры при достаточном охлаждении продолжают стабильно работать при существенном превышении заложенной производителем тактовой частоты.
Асинхронные процессоры начинают следующую операцию, как только результаты предыдущей готовы. У них нет такого понятия как тактовая частота, и их скорость работы всегда максимальна для данных условий: если на асинхронный процессор поставить горячий кофе, он замедлится, если полить жидкимазотом — ускорится. Однако асинхронная схемотехника из-за её сложности используется на сегодняшний день лишь в небольшом количестве экспериментальных асинхронных процессоров (начиная с ILLIAC I в 1951 году и заканчивая GA144 в 2010 году). В будущем она, вероятно, будет применяться всё шире, так как других областей оптимизации не остаётся.
Уже больше десятилетия в процессорах устанавливают несколько операционных блоков каждого типа. Такие процессоры называют суперскалярными. Они могут параллельно производить независимыедействия — например, параллельно выполнять инструкции «c = a + b» и «d = a · b» . Ещё одной широко применяемой техникой оптимизации является так называемый «pipelining»: инструкцию-задание записывают в операционные блоки ещё до того, как операнды готовы, при этом мультиплексоры и демультиплексоры успевают заранее прийти в нужное состояние, и время выполнения операции разительно сокращается. Однако максимальную выгоду от использования пайплайнинга можно получить лишь на асинхронном процессоре, так как синхронные процессоры дают на выполнение каждой инструкции заранее фиксированное количество «взмахов дирижёрской палочки», а при этом выигрыш от упреждающей загрузки инструкций в блоки относительно невелик. Если же вдобавок отдельно следить за готовностью каждого операнда, на асинхронном процессоре можно получать выигрыш во времени не только за счёт предварительной загрузки инструкции, но и за счёт более ранней готовности одного из операндов. Иногда инструкция может сработать вообще до того, как готовы все операнды — например, при равенстве одного из операндов нулю умножение выдаст ноль, не дожидаясь готовности второго операнда.
Единственный эффективный способ раздельного контроля готовностиоперандов — одноразовое использование регистров. Под этим термином подразумевается, что в ходе работы каждой подпрограммы запись в каждый регистр производится только один раз (значения никогда не перезаписываются). По окончании процедуры все использованные регистры сбрасываются назад в пустое состояние. Тем самым обеспечивается простота проверки готовности операндов: операнд готов, как только содержащий его регистр непуст. Прямолинейная реализация раздельного контроля готовности требует огромного числа регистров, однако на практике этого не требуется: можно эмулировать большое число логических регистров, на деле обходясь небольшим числом аппаратных регистров.
§ 3.3. Управляющие блоки и блок прерываний
Распределением заданий по операционным блокам в соответствии с записанной в оперативной памяти программой занимается управляющий блок. Он загружает из оперативной памяти команды программы, декодирует их и в декодированном виде рассылает по регистрам инструкций свободных операционных блоков. Кроме того, он выполняет инструкции перехода и ветвления, то есть выбирает одну из ветвей программы в зависимости от значения какого-либо операционного регистра. Управляющих блоков в процессоре может быть несколько, что позволяет исполнять несколько программ параллельно.
Центральные процессоры не только выполняют программы, но и реагируют на аппаратные запросы. Аппаратныйзапрос — это сигнал, подаваемый внешними устройствами на специально выделенные для этого входы процессора. Например, при нажатии на кнопку мыши процессору подаётся запрос на обработку этого события. Обработкой аппаратных запросов занимается блок прерываний. При поступлении запроса блок прерываний ищет свободный управляющий блок и посылает приказ о выполнении программы-обработчика. Если свободных блоков нет, он выбирает один из блоков и временно прерывает выполняющуюся в нём программу, перенаправляя блок на обработку аппаратного запроса. По окончании обработки выполнение прерванной программы возобновляется. Блок прерываний обязан своим названием тому, что большая часть его работы состоит именно в прерывании и возобновлении выполнения программ.
§ 3.3.1. Управляющие инструкции: переходы, вызовы, ветвление и циклы
Программа представляет собой набор закодированных числами инструкций, расположенных в последовательных ячейках памяти. Если же по тем или иным причинам невозможно расположить последовательные инструкции в последовательных ячейках, обычно используется инструкция перехода. Считывая такую инструкцию, управляющий блок записывает в Instruction Pointer адрес, указанный в инструкции. В традиционных архитектурах состояние остальных регистров при переходе не изменяется.
Исторически основным применением инструкций перехода является вызов подпрограмм, однако сейчас для этого используются отдельные инструкции вызова и возврата. Инструкция вызова маскирует или очищает все регистры (сбрасывая их значения в специально выделенное хранилище) за исключением диапазона регистров, в которых находятся аргументы, чтобы вызываемая подпрограмма работала «с чистого листа». (Маскировка работает быстрее перемещения значений в хранилище, но может быть реализована лишь на процессорах, использующих динамическое переименование регистров.) Подпрограммы заканчивают своё выполнение инструкцией возврата, которая очищает использованные подпрограммой регистры и демаскирует либо восстанавливает убранные при вызове регистры за исключением диапазона, в котором сохранены результаты выполнения подпрограммы.
Специальным случаем является так называемый хвостовой вызов, то есть ситуация, когда некая подпрограмма f заканчивается парой инструкций вида «вызвать g и вернуть результат её выполнения на уровень выше». В этом случае при вызове g не нужно сохранять или маскировать текущие регистры и точкувозврата — вместо этого можно передать вызываемой подпрограмме g, что результат нужно возвращать не в f, а сразу на уровень выше. Хвостовой вызов отличается от описанного в самом начале этого параграфа перехода только тем, что явно указывается, какие регистры следует сохранить, а какие отбросить при переходе. В будущем переход-«хвостовой вызов» заменит традиционный переход (не изменяющий значений операционных регистров), так как традиционный переход мешает асинхронному выполнению и одноразовому использованию регистров, а переход-«хвостовой вызов» нет. (На самом деле, и инструкция возврата является частным случаем перехода-«хвостового вызова», однако обсуждение этой красивой концепции выходит за рамки данного текста.)
Кроме вызовов и переходов управляющие блоки выполняют инструкции ветвления, то есть выборы ветви программы в зависимости от значения одного из операционных регистров. Традиционно ветвление осуществляется при помощи инструкций условного перехода, однако на асинхронных процессорах вместо традиционной операции перехода гораздо лучше использовать инструкции условного вызова или условного хвостового вызова. Инструкция такого рода указывает на таблицу, в которой записано, какую подпрограмму вызывать в зависимости от значения одного из операционных регистров. При помощи инструкций условного (хвостового) вызова можно эффективно реализовывать и конструкции видаif-then-else , match-case , условную рекурсию и, соответственно, все возможные виды циклов. Дополнительных операций управления выполнением не требуется.
Зачастую на подходе к точке ветвления свободных вычислительных ресурсов много и большая часть аргументов для вызываемых подпрограмм готова, однако не готово значение, определяющее, какую из подпрограмм надлежит в итоге вызвать. В этом случае можно спекулятивно начать выполнять одну или несколько наиболее вероятных процедур, избегая лишь операций, влияющих на «внешний мир»: сохранения каких-либо значений в общедоступную оперативную память, обращения к внешним устройствам и возврата из процедуры. Эта техника оптимизации во многих ситуациях способна обеспечить более чем двукратный прирост производительности.
Пример ветвления:
ветвления — бинарное ветвление if-then-else :
§ 3.4. Заключение
По всей видимости, архитектура центральных процессоров останется фон-неймановской. Увеличение производительности будет обеспечиваться за счёт лучшей параллелизации инструкций и перехода на асинхронную схемотехнику. Для обеспечения наилучшей параллелизуемости потребуется переход на более совершенные наборыинструкций — в частности, пригодные для одноразового использования регистров.
Современные процессоры используют от 1 до 16 управляющих блоков и от 4 до 64 операционных блоков. При переходе к асинхронной схемотехнике будет оправдано использование нескольких десятков управляющих блоков и нескольких сотен операционных блоков. Такой переход вместе с соответствующим увеличением числа блоков обеспечит увеличение пиковой производительности более чем на два порядка и средней производительности более чем на порядок.
сути — в те времена они были результатами необходимых инженерных компромиссов и технических ухищрений, сегодня их основным источником является требование обратной совместимости со старыми моделями. Чтобы не перегружать читателя ненужными и быстро устаревающими деталями и сохранить универсальность изложения, Кнут решил разработать собственную архитектуру компьютера, предназначенную специально для обучения. Эта архитектура получила название MIX.
В течение последующих трёх десятилетий в области компьютерных технологий произошли серьёзные изменения, и MIX во многом устарел. Чтобы «Искусство программирования» продолжало оставаться актуальным источником, автор решил разработать вместе с ведущими промышленными разработчиками процессоровMMIX — новый вымышленный компьютер, который является идеализированным и улучшенным аналогом компьютеров второй половины 1990-х годов. MMIX является глубоко продуманной архитектурой, пригодной для немедленной аппаратной реализации и заметно более развитой, чем все широко распространённые на сегодняшний день процессорные архитектуры.
Стремление сделать машину, которую можно эффективно реализовать «в железе» средствами конца 1990-х годов, помешало сделать достаточный задел набудущее — к большому сожалению, набор инструкций MMIX практически непригоден для реализации потенциала асинхронных суперскалярных процессоров. Дело в том, что организация вызовов в MMIX базируется на использовании традиционных переходов и требует перезаписи регистров. Для практического исследования перспективных техник программирования необходимо переработать этот набор инструкций в соответствии с описанными выше неизбежными тенденциями развития центральных процессоров — к счастью, это не такая уж сложная задача.
Делать прогнозы в этой области позволяет именно то, что возможные пути развития жёстко диктуются фундаментальными физическими ограничениями: конечностью скорости света, законами термодинамики и ограничением на минимальный размер
Часть 1. Принципы устройства вычислительных машин сегодня и в будущем
В первые десятилетия своего существования компьютеры использовались только для вычислений. Исходный смысл слова «компьютер» переводится на русский как «автоматизированная вычислительная машина» (АВМ). Чуть позже компьютеры стали также применять в качестве управляющих элементов других устройств, и слово «компьютер» обрело своё современное значение: «исполняющий программы аппарат общего назначения». Сегодня АВМ являются узкоспециальными (используемыми в вычислительных центрах) устройствами, а компьютер как управляющий элемент, напротив, используется практически во всех автоматизированныхСуществует несколько существенно различных моделей вычислений, так что АВМ будущего, возможно, будут устроены совершенно непредвиденным образом. Однако компьютер как управляющее устройство в любом случае должен содержать исполнительный блок (центральный процессор), и устройство этого блока жёстко зафиксировано его функциями: он должен уметь
– выдавать последовательные инструкции другим устройствам и
– совершать выбор дальнейшей программы действий в зависимости от сложившихся условий.
Эти два требования автоматически предполагают модель устройства, называемую «relaxed sequential execution» по-английски или «алгоритмической моделью» в русскоязычной традиции. Эта модель, в отличие от многих других, не имеет квантового аналога, так как квантовые вычисления принципиально обратимы, а совершение выбора принципиально необратимо. Именно об этой модели пойдёт речь в следующих двух частях статьи.
Для полноты рассказа приведём список всех известных на данных момент масштабируемых аппаратных моделей вычислений:
– алгоритмическая модель, то есть, (условно-)пошаговое выполнение инструкций («условно» означает, что допускается параллельное выполнение независимых инструкций);
– потоковые векторные вычисления и их естественное
– клеточные/сетевые автоматы и их естественное
На данный момент на практике за исключением модели последовательного выполнения используются лишь потоковые векторные вычисления: на бытовых компьютерах в специализированных сопроцессорах для трёхмерной графики (GPU), а также в их аналогах повышенной мощности (GPGPU) на вычислительных станциях для численных симуляций и обработки больших массивов данных. Центральный процессор делегирует некоторые специфические задачи потоковому процессору, однако управляющие функции в полной мере выполняет только он сам. С развитием квантовых вычислений это положение вещей вряд ли изменится: квантовые конвейеры и автоматы будут лишь дополнениями центрального процессора, но не его заменой.
Часть 2. Элементная база процессоров сегодня и в будущем
На элементарном уровне процессоры состоят из двух типов элементов: переключателей и соединяющих их дорожек. Задача дорожек в том, чтобы переносить сигнал, а задача переключателей в том, чтобы этот сигнал трансформировать. Существует много разных реализаций переключателей и дорожек.В окружающей нас цифровой электронике в качестве переключателей используются транзисторы, а дорожки делаются из проводников.
§ 2.1. Передача сигнала
В двоичной цифровой электронике для кодирования сигнала используются напряжение. Дорожка несёт сигнал «ноль», если на неё подан потенциал Существуют альтернативы цифровой электронике, лишённые этого недостатка: по дорожкам можно пускать постоянный поток электронов (т.н. спинтроника) или фотонов (т.н. фотонная логика), а сигнал кодировать при помощи поляризации этого потока. Как электроны, так и фотоны, движущиеся по одномерному волноводу, могут пребывать ровно в двух ортогональных состояниях поляризации, одно из которых объявляется нулём, а другое единицей. Что лучше — фотонная логика или спинтроника, пока непонятно:
– в обоих случаях поток частиц течёт с неизбежными тепловыми потерями, однако эти потери могут быть сколь угодно малы;
– в обоих случаях скорость потока ниже скорости света, однако может быть сколь угодно близка к ней;
– в обоих случаях требуются сложные технические приёмы, чтобы наводки, тепловой шум и фоновое излучение (пролетающие мимо случайные частицы) не искажали сигнал.
Иными словами, известные физические ограничения обеих технологий одинаковы. По всей видимости, наилучшие результаты будут давать комбинированные технологии: транспортировка фотонов выигрывает на длинных дистанциях и проигрывает на коротких; при этом уже разработаны рабочие прототипы переходников (в обе стороны) между поляризацией фотонного и электронного потока. Идеальным материалом для спинтронных дорожек является графен: он обеспечивает превосходную скорость при очень низких тепловых потерях. Кроме того, уже существуют рабочие прототипы следующих элементов:
– дорожек, надёжно сохраняющих поляризацию тока на коротких и средних дистанциях;
– ячеек памяти, способных сохранить поляризацию и затем формировать поток сохранённой поляризации.
Информация по графеновым дорожкам:
2010-06: Mass fabrication of graphene nanowires. Georgia Institute of Technology.
2011-01: Researchers managed to generate a spin current in Graphene. City University of Hong Kong.
2011-02: Creating a pure spin current in graphene. City University of Hong Kong.
2011-02: Mass production-ready bottom-up synthesis of soluble defect-free graphene nanoribbons. Max Planck Institute for Polymer Research in Mainz.
§ 2.2. Переключатели
Применяемый в цифровой электронике транзистор представляет собой устройство с тремя контактами, работающее следующим образом:– если на средний контакт подаётся высокий потенциал, то крайние контакты соединены, переключатель находится в положении «проводник»;
– если на средний подаётся низкий потенциал, то крайние контакты разомкнуты, переключатель находится в положении «изолятор».
На данный момент успешно созданы и протестированы транзисторы, состоящие из одной молекулы. Их скорость работы и компактность практически достигают теоретического предела, однако пока не существует технологий, которые бы позволяли их массово производить и использовать. Вся современная цифровая электроника изготавливается на основе металл-оксидных полевых транзисторов (MOSFET). Уже несколько десятилетий производители микросхем лишь уменьшают линейные размеры и энергопотребление таких транзисторов, однако уже были проведены промышленные испытания некоторых типов многостоковых и беспереходных транзисторов (BDT, JNT). Такие транзисторы смогут обеспечить повышение производительности в
По фундаментальным термодинамическим причинам переключатели транзисторного типа не могут работать эффективно: эффективный должен быть консервативным и обратимым как логический элемент. Этим условиям удовлетворяет симметрический переключатель, называемый также вентилем Фредкина.
Это устройство с двумя входами In1, In2, двумя выходами Out1, Out2 и сквозной дорожкой Как из транзисторов, так и из симметрических переключателей можно изготовить логические схемы любой сложности, однако симметрические переключатели гораздо более экономны. Например, для клонирования сигнала и логических операций «не», «и», «или», «и не» и «следует» требуется всего один симметрический переключатель, «исключающее или», «не или» и «не и» требуют двух переключателей. Для реализации этих операций на транзисторах требуется от 4 до 6 транзисторов:
Быстрый одноразрядный сумматор (half adder) использует четыре симметрических переключателя (вместо 12 транзисторов) и обеспечивает в идеале существенно большую скорость работы, чем транзисторный аналог: время его работы составляет всего 2τ, где τ — время прохождения сигналом одного переключателя и одной дорожки. На более сложных схемах компактность и выигрыш в скорости симметрических переключателей проявляются ещё более явно. Звено многоразрядного сумматора (full adder) состоит из десятков транзисторов, в то время как реализация на симметрических переключателях требует от 4 (самый компактный вариант) до 7 (самый быстрый вариант) переключателей: Уникальная особенность симметрических переключателей заключается в том, что с их помощью достигается максимальная компактность и скорость работы мультиплексоров и демультиплексоров, являющихся очень распространёнными составными элементами процессоров. К сожалению, симметрические переключатели становятся привлекательными лишь при использовании спинтроники или фотонной логики. Электроника обречена использовать обычные транзисторы.
* В параграфе использованы материалы и изображения из статей Bruce, Thornton et al., “Efficient Adder Circuits Based on a Conservative Reversible Logic” (Mississippi State University, Proc. IEEE Symposium on VLSI, 2002); Rentergem, de Vos, “Optimal Design of A Reversible Full Adder” (Universiteit Gent, International Journal of Unconventional Computing, 2005), а также материалы частной переписки. Изображение одномолекулярного транзистора взято из соответствующего пресс-релиза на сайте Йельского университета.
§ 2.3. Заключение
Итак, в пределе центральный процессор будущего, скорее всего, будет представлять из себя огромную паутину, где нити сделаны из графеновой ленты, проводящей поляризованный поток электронов, а в узлах находятся миниатюрные симметрические переключатели. На длинных дистанциях сигнал будет перекодироваться в свет, доставляться фотонами и перекодироваться обратно на месте назначения. Ряд специальных задач (в частности, поиск и сортировка) будут выполняться квантовыми конвейерами и автоматами.
Часть 3. Архитектура центральных процессоров сегодня и в будущем
Все распространённые сегодня центральные процессоры представляют из себя регистровые машины фон-неймановской архитектуры:– процессор содержит содержит определённое количество (например, 16) нумерованных ячеек памяти (например, по 64 бита каждая), которые называются операционными регистрами;
– работа процессора состоит в том, чтобы перерабатывать содержимое регистров в соответствии с программой;
– программа представляет из себя последовательность инструкций, например:
– взять значения из регистров № 2 и № 5 и записать их сумму в регистр № 8;
– считать в регистр № 4 значение из ячейки внешней памяти с адресом из регистра № 6;
– отослать число из регистра № 12 внешнему устройству NNN;
– данные и сами программы хранятся в оперативной памяти, при этом инструкции программ кодируются числами и записываются в последовательные ячейки памяти;
– номер ячейки, инструкция из которой выполняется в данный момент, хранится в специальном регистре, называемом Instruction Pointer, который по окончании выполнения передвигается на следующую ячейку памяти.
За более чем полвека с момента появления этой архитектуры были предложены десятки альтернативных арихетектур организации последовательного выполнения, однако все из них уступают ей в потолке производительности. Потолок производительности определяется (из-за конечности скорости света) линейными размерами критической части конструкции, и именно классическая регистровая архитектура обеспечивает максимальную локальность вычисления из всех предложенных на данный момент архитектур последовательного выполнения. Соответственно, именно такая архитектура сохранится, по всей видимости, и в
§ 3.1. Функционально-логические единицы
Описанные в первой части переключатели и дорожки являются «сырьём» для изготовления функционально-логических единиц, таких как сумматор, умножитель, мультиплексор и демультиплексор. Мультиплексоры и демультиплексоры представляют из себя устройства, похожие на сортировочные станции на железной дороге (см. иллюстрацию справа). На вход мультиплексора поступают n чисел (a1..an) и управляющее число m. На выход подаётся число am, то есть Задача сумматора в том, чтобы складывать подаваемые на него числа. На вход
Функционально-логические единицы реагируют на изменения аргументов не сразу: нужно, чтобы сигнал успел пройти весь путь от начала схемы до её конца, учитывая задержки, вызываемые прохождением через переключатели, и возможные циклы в схеме. Для каждой функционально-логической единицы при проектировании рассчитывается время работы. Разработана обширная теория проектирования функционально-логических единиц с минимальным временем работы. Так, простейший многоразрядный сумматор, выполняющий сложение по образу и подобию сложения в столбик на бумаге, требует для работы время, растущее линейно с разрядностью. В 60-е годы были разработаны схемы ускоренного переноса, уменьшающие рост до логарифмического. Использующий их сумматор на симметрических переключателях гарантированно подсчитывает результат за ⌈3 + log2(разрядность)⌉·τ, что является теоретическим пределом скорости. В случае 64-битного сумматора достигается 15-кратное ускорение о сравнению с наивной реализацией. А хитроумная оптимизация умножения, деления, вычисления тригонометрических функций позволяет подчас достичь ускорения в сотни раз.
§ 3.2. Операционные блоки
Операционный
Нам потребуется:
– регистр инструкции, в котором хранится код операции суммирования и номера регистров-операндов (2, 5 и 8 в вышеуказанной команде);
– сумматор;
– два мультиплексора, подключенные к блоку регистров с одной стороны и входам сумматора с другой: они выбирают из регистров те два, чьи номера сохранении в регистре инструкции (
– один демультиплексор, подающий вывод сумматора на входы регистра, в котором его следует сохранить.
В современных процессорах операционные блоки способны производить более чем одно действие. Например, блок может содержать кроме сумматора ещё и умножитель. Для технической реализации достаточно в параллель с сумматором поставить умножитель, обрамлённые демультиплексором и мультиплексором, которые выбирают, проводить сигнал через сумматор или умножитель в зависимости от кода операции, сохранённого в регистре инструкции.
§ 3.2.1. Организация операционного цикла: синхронизация, суперскалярность, pipelining
Работа процессора представляет из себя повторение следующего цикла, в ходе которого информация проходит по кругу «
– загрузить подлежащие выполнению инструкции в операционные блоки;
– подождать результатов;
– сохранить результаты в регистры.
Существует два подхода к организации процессорного цикла: синхронный и асинхронный. В синхронных процессорах имеется сигнал-дирижёр. При его изменении («дирижёр взмахивает палочкой») значения, выдаваемые операционными блоками сохраняются в регистры, а в операционные блоки подаётся следующая инструкция. В асинхронных процессорах общего сигнала-дирижёра нет, а о готовности результата сообщают сами операционные блоки. С момента готовности задания и операндов блок начинает отслеживать готовность результата. По окончании вычисления блок даёт отмашку на сохранение результата и запрашивает следующее задание.
Синхронные процессоры имеют фиксированную тактовую
– исходное состояние операционного блока: если инструкция или часть аргументов загружены заранее, часть блока заранее приходит в нужное состояние;
– значения операндов: так, умножение коротких чисел занимает много меньше времени, чем умножение длинных;
– уровень фоновых шумов: при температуре процессора
Синхронный подход не может учитывать всех этих факторов; кроме того, зависимость уровня шумов от температуры определяется концентрацией кристаллических
Асинхронные процессоры начинают следующую операцию, как только результаты предыдущей готовы. У них нет такого понятия как тактовая частота, и их скорость работы всегда максимальна для данных условий: если на асинхронный процессор поставить горячий кофе, он замедлится, если полить жидким
Уже больше десятилетия в процессорах устанавливают несколько операционных блоков каждого типа. Такие процессоры называют суперскалярными. Они могут параллельно производить независимые
Единственный эффективный способ раздельного контроля готовности
§ 3.3. Управляющие блоки и блок прерываний
Распределением заданий по операционным блокам в соответствии с записанной в оперативной памяти программой занимается управляющий блок. Он загружает из оперативной памяти команды программы, декодирует их и в декодированном виде рассылает по регистрам инструкций свободных операционных блоков. Кроме того, он выполняет инструкции перехода и ветвления, то есть выбирает одну из ветвей программы в зависимости от значения какого-либо операционного регистра. Управляющих блоков в процессоре может быть несколько, что позволяет исполнять несколько программ параллельно.
Центральные процессоры не только выполняют программы, но и реагируют на аппаратные запросы. Аппаратный
§ 3.3.1. Управляющие инструкции: переходы, вызовы, ветвление и циклы
Программа представляет собой набор закодированных числами инструкций, расположенных в последовательных ячейках памяти. Если же по тем или иным причинам невозможно расположить последовательные инструкции в последовательных ячейках, обычно используется инструкция перехода. Считывая такую инструкцию, управляющий блок записывает в Instruction Pointer адрес, указанный в инструкции. В традиционных архитектурах состояние остальных регистров при переходе не изменяется.
Исторически основным применением инструкций перехода является вызов подпрограмм, однако сейчас для этого используются отдельные инструкции вызова и возврата. Инструкция вызова маскирует или очищает все регистры (сбрасывая их значения в специально выделенное хранилище) за исключением диапазона регистров, в которых находятся аргументы, чтобы вызываемая подпрограмма работала «с чистого листа». (Маскировка работает быстрее перемещения значений в хранилище, но может быть реализована лишь на процессорах, использующих динамическое переименование регистров.) Подпрограммы заканчивают своё выполнение инструкцией возврата, которая очищает использованные подпрограммой регистры и демаскирует либо восстанавливает убранные при вызове регистры за исключением диапазона, в котором сохранены результаты выполнения подпрограммы.
Специальным случаем является так называемый хвостовой вызов, то есть ситуация, когда некая подпрограмма f заканчивается парой инструкций вида «вызвать g и вернуть результат её выполнения на уровень выше». В этом случае при вызове g не нужно сохранять или маскировать текущие регистры и точку
Кроме вызовов и переходов управляющие блоки выполняют инструкции ветвления, то есть выборы ветви программы в зависимости от значения одного из операционных регистров. Традиционно ветвление осуществляется при помощи инструкций условного перехода, однако на асинхронных процессорах вместо традиционной операции перехода гораздо лучше использовать инструкции условного вызова или условного хвостового вызова. Инструкция такого рода указывает на таблицу, в которой записано, какую подпрограмму вызывать в зависимости от значения одного из операционных регистров. При помощи инструкций условного (хвостового) вызова можно эффективно реализовывать и конструкции вида
Зачастую на подходе к точке ветвления свободных вычислительных ресурсов много и большая часть аргументов для вызываемых подпрограмм готова, однако не готово значение, определяющее, какую из подпрограмм надлежит в итоге вызвать. В этом случае можно спекулятивно начать выполнять одну или несколько наиболее вероятных процедур, избегая лишь операций, влияющих на «внешний мир»: сохранения каких-либо значений в общедоступную оперативную память, обращения к внешним устройствам и возврата из процедуры. Эта техника оптимизации во многих ситуациях способна обеспечить более чем двукратный прирост производительности.
Пример ветвления:
match (a <> b) {
case 0: {
print "a and b are equal"
}
case 1: {
print "a is greater than b"
}
case -1: {
print "b is greater than a"
}
} if (condition) {
do_this
} else {
do_that
}
match (condition) {
case True: {
do_this
}
case False: {
do that
}
} def gcd(a, b) = {
if (b = 0) return a
else return gcd(b, a % b) // Хвостовая рекурсия
}
§ 3.4. Заключение
По всей видимости, архитектура центральных процессоров останется фон-неймановской. Увеличение производительности будет обеспечиваться за счёт лучшей параллелизации инструкций и перехода на асинхронную схемотехнику. Для обеспечения наилучшей параллелизуемости потребуется переход на более совершенные наборы
Современные процессоры используют от 1 до 16 управляющих блоков и от 4 до 64 операционных блоков. При переходе к асинхронной схемотехнике будет оправдано использование нескольких десятков управляющих блоков и нескольких сотен операционных блоков. Такой переход вместе с соответствующим увеличением числа блоков обеспечит увеличение пиковой производительности более чем на два порядка и средней производительности более чем на порядок.
Часть 4. ↁⅠⅩ wanted!
В 1962 году Дональд Кнут начал написание знаменитой серии книг «Искусство программирования», в которой описываются эффективные алгоритмы и анализируется их скорость. Чтобы сохранить возможность описывать низкоуровневые алгоритмы и точно оценивать время их выполнения, он принял решение не использовать высокоуровневых языков программирования, а писать на ассемблере. Однако архитектуры и ассемблеры реальных процессоров переполнены причудливыми техническими особенностями, отвлекающими отВ течение последующих трёх десятилетий в области компьютерных технологий произошли серьёзные изменения, и MIX во многом устарел. Чтобы «Искусство программирования» продолжало оставаться актуальным источником, автор решил разработать вместе с ведущими промышленными разработчиками процессоров
Стремление сделать машину, которую можно эффективно реализовать «в железе» средствами конца 1990-х годов, помешало сделать достаточный задел на
