
Первый раз я запустил Eclipse еще весной, почитал книжки на английском, поставил SDK, немного поигрался и забросил. В начале зимы я купил себе первый смартфон на базе Android, но вновь вернутся к разработке меня подтолкнул недавний пост, в котором говорилось, что можно обойтись и знанием C#, с которым в отличии от Java я знаком. Мне было достаточно одного вечера, чтобы понять, что за связку Visual Studio и Monodroid я больше не сяду, позже я прочитал этот пост, где полностью согласился с автором.
После небольшого вступления перейду к теме топика. Довольно большое количество приложений под мобильные устройства взаимодействуют с сайтами и не секрет, что порой нужно получить какую-то информацию со страницы — это может быть курс валют или что-нибудь другое, и нет никакого желания делать это посредством браузера.
Большинство разработчиков, получают html код страницы и перегоняют его в xml, что является неправильным подходом, так как html является «правильным» xml не всегда, вроде на хабре писали, что для браузера не обязателен тег html (современный браузер и без него должен отобразить страницу) или просто будут ошибки, тогда на помощь приходят библиотеки. Из них я выбрал HtmlCleaner.
Под катом я расскажу, как подключить эту библиотеку, а также напишем простой парсер stackoverflow.com.
Рассказывать как установить Android SDK, Eclipse и ADT Plugin я не буду, если эти слова Вам ничего не говорят, то посетите эти две ссылки:
Installing the SDK
ADT Plugin for Eclipse
Главная страница stackoverflow.com выглядит следующим образом:

Парсить я буду информацию, выделенную красными прямоугольниками.
Всё рассчитано на новичков, поэтому будет много картинок. На данном этапе у Вас должен быть полностью настроенный Eclipse, для создания проекта нажимаем File -> New -> Project… и выбираем Android Project, после чего заполним форму:
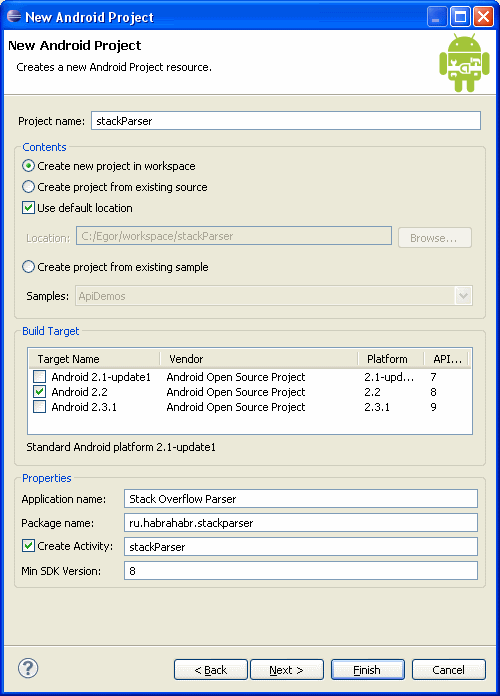
Пишу для своего устройства, поэтому выбрал версию 2.2, второй важный параметр — это package name, который должен быть уникальным, принято, что это имя сайта наоборот, плюс название приложения. Тесты создавать не будет, поэтому смело нажимаем Finish. Создался проект, рекомендую Вам изучить какие файлы и где лежат, но по своему опыту скажу, что сразу я малость испугался, того количества файлов, которое появилось при первом запуске Eclipse.
Приступим к редактированию файла res\layout\main.xml, тут я удалю TextView и добавлю два элемента управления: Button и ListView, изменю идентификаторы, для кнопки установлю android:layout_width=«fill_parent» и android:text=«Получить данные». Готовый результат выглядит таким образом:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:orientation="vertical"
android:layout_width="fill_parent"
android:layout_height="fill_parent">
<Button android:id="@+id/parse"
android:layout_height="wrap_content"
android:layout_width="fill_parent"
android:text="Получить данные">
</Button>
<ListView android:id="@+id/listViewData"
android:layout_height="wrap_content"
android:layout_width="match_parent">
</ListView>
</LinearLayout>
* This source code was highlighted with Source Code Highlighter.Это простейший интерфейс, в случае, если Вы сделаете приложение и решите опубликовать его в маркете, то обязательно его нужно изменить, поставить тот же фон через android:background="@drawable/Имя_файла_без_расширения" и т.д.
Для парсинга нам понадобиться скачать библиотеку htmlcleaner-2.2.jar, далее её следует подключить добавив в Build Paths. Хороший мануал как это сделать можно найти тут, если у Вас появились какие-то трудности.
Прежде всего нужно указать, что нашему приложению нужен интернет, иначе у Вас ничего не выйдет, добавим в файл AndroidManifest.xml:
<uses-permission android:name="android.permission.INTERNET"/>
Теперь создадим класс HtmlHelper, который будет делать основную работу:
public class HtmlHelper {
TagNode rootNode;
//Конструктор
public HtmlHelper(URL htmlPage) throws IOException
{
//Создаём объект HtmlCleaner
HtmlCleaner cleaner = new HtmlCleaner();
//Загружаем html код сайта
rootNode = cleaner.clean(htmlPage);
}
List<TagNode> getLinksByClass(String CSSClassname)
{
List<TagNode> linkList = new ArrayList<TagNode>();
//Выбираем все ссылки
TagNode linkElements[] = rootNode.getElementsByName("a", true);
for (int i = 0; linkElements != null && i < linkElements.length; i++)
{
//получаем атрибут по имени
String classType = linkElements[i].getAttributeByName("class");
//если атрибут есть и он эквивалентен искомому, то добавляем в список
if (classType != null && classType.equals(CSSClassname))
{
linkList.add(linkElements[i]);
}
}
return linkList;
}
}
В главном классе установим слушателя для кнопки и вызовем асинхронно парсинг с помощью AsyncTask, сразу я делал с помощью создания потока и потом через handler обновлял интерфейс, но прочитал, что это не лучшее решение и лучше для этих целей подходит AsyncTask, также, чтобы было видно, что приложение работает я вызову диалог, который будет информировать о процессе. Собственно главный класс выглядит следующим образом:
public class StackParser extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
//Находим кнопку
Button button = (Button)findViewById(R.id.parse);
//Регистрируем onClick слушателя
button.setOnClickListener(myListener);
}
//Диалог ожидания
private ProgressDialog pd;
//Слушатель OnClickListener для нашей кнопки
private OnClickListener myListener = new OnClickListener() {
public void onClick(View v) {
//Показываем диалог ожидания
pd = ProgressDialog.show(StackParser.this, "Working...", "request to server", true, false);
//Запускаем парсинг
new ParseSite().execute("http://www.stackoverflow.com");
}
};
private class ParseSite extends AsyncTask<String, Void, List<String>> {
//Фоновая операция
protected List<String> doInBackground(String... arg) {
List<String> output = new ArrayList<String>();
try
{
HtmlHelper hh = new HtmlHelper(new URL(arg[0]));
List<TagNode> links = hh.getLinksByClass("question-hyperlink");
for (Iterator<TagNode> iterator = links.iterator(); iterator.hasNext();)
{
TagNode divElement = (TagNode) iterator.next();
output.add(divElement.getText().toString());
}
}
catch(Exception e)
{
e.printStackTrace();
}
return output;
}
//Событие по окончанию парсинга
protected void onPostExecute(List<String> output) {
//Убираем диалог загрузки
pd.dismiss();
//Находим ListView
ListView listview = (ListView) findViewById(R.id.listViewData);
//Загружаем в него результат работы doInBackground
listview.setAdapter(new ArrayAdapter<String>(StackParser.this,
android.R.layout.simple_list_item_1 , output));
}
}
}
Если Вы всё делали со мной, то у Вас должна была получится, следующая иерархия файлов:
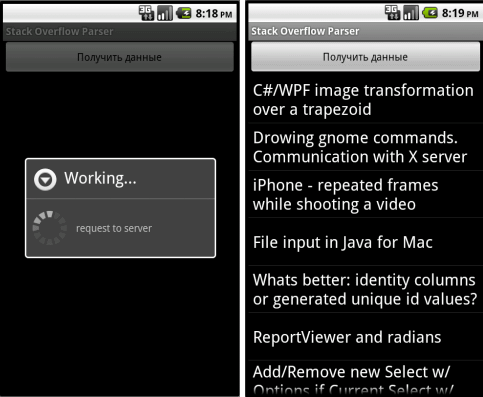
А после запуска приложение должно выглядеть следующим образом:
Ссылка на скачивание: приложение
Вывод
Мы узнали, что есть довольно много библиотек для парсинга, познакомились с одной из них, написали приложение, которое в фоне парсит сайт и при готовности показывает нам результат своей работы. В принципе, его можно развить и дальше, после чего не исключено, что оно станет популярным в определенных кругах, первое, что приходит в голову — это при клике на вопрос, открывать данный вопрос в новом окне через WebView.
