Comments 111
первый пример пример переноса тематического топика в профильный блог(изначально был в Веб-разработке)
Ооох, я тоже только заметил первоапрельскую ППА )
У автора только значок «Переводчик», этого недостаточно для ППА.
Веб-разработка — тоже профильный.
Все эти evented сервера и гринлеты хороши до первой блокировки. Или до первой библиотеки которая не thread safe. Или до момента когда код приложения становится немного сложнее банального чатика. Так что если руки тянутся к node.js или tornado/twisted/gevent/em, то лучше сразу взять Erlang.
Ничего сложного в них нет, поверьте. Намного проще чем threads с их локами.
Более того, оверхед например на питоне от тредов ужасный.
Давно спорил перед заказчиком с другим разработчиком, человек доказывал что эвент модель в питоне медленней чем нитевая… Человек не был знаком с GIL. Но говорил красивее, в итоге проект до сих пор пишут эти «разработчики», а в это время мой готовый gevent проект работает у них же — написанный буквально за пару дней (большая часть времени ушла на настройку межсетевых-внутренних сообщений по UDP).
Более того, оверхед например на питоне от тредов ужасный.
Давно спорил перед заказчиком с другим разработчиком, человек доказывал что эвент модель в питоне медленней чем нитевая… Человек не был знаком с GIL. Но говорил красивее, в итоге проект до сих пор пишут эти «разработчики», а в это время мой готовый gevent проект работает у них же — написанный буквально за пару дней (большая часть времени ушла на настройку межсетевых-внутренних сообщений по UDP).
>Ничего сложного в них нет, поверьте. Намного проще чем threads с их локами.
Не верим :) Никогда не буду нагромождать треды на обработку соединений, но для обработки риквестов предпочту что-нибудь поудобнее чем голая евентовая модель.
В случае если риквесты — это куча обращений к базам данных итп, предпочту что-нибудь вроде декларативного описаниявсех задачек(либо иммедиэйт проталкивания задач в планировщик как это сделано в «new App Engine datastore API»), типа:
взять сессию из бд
взять данные пользователя (зависимости: сессия)
взять контент для странички
отрендерить ответ(зависимости: пользователь и контент)
и планировщик уже оптимальным образом будет решать эту проблему.
Не верим :) Никогда не буду нагромождать треды на обработку соединений, но для обработки риквестов предпочту что-нибудь поудобнее чем голая евентовая модель.
В случае если риквесты — это куча обращений к базам данных итп, предпочту что-нибудь вроде декларативного описаниявсех задачек(либо иммедиэйт проталкивания задач в планировщик как это сделано в «new App Engine datastore API»), типа:
взять сессию из бд
взять данные пользователя (зависимости: сессия)
взять контент для странички
отрендерить ответ(зависимости: пользователь и контент)
и планировщик уже оптимальным образом будет решать эту проблему.
Начните изучать Erlang. После этого ваши Пайтоны и Руби рука не поднимется применять для хайлоада и асинхронности.
Кстати, столкнувшись с проблемой нагрузки для чата на php, начал изучать Erlang (на хабре посоветовали). Чатик по туториалу сделал — вроде класс. А вот как дошло до того, чтобы в веб его повесить, чтоб html отдавал или, на худой конец, json, анализируя http-запросы, столько рутины — фактически веб-сервер писать нужно, который http запросы будет транслировать в erlang сообщения. Поставил phpdaemon — работает, нагрузку держит с большим запасом.
> А вот как дошло до того, чтобы в веб его повесить, чтоб html отдавал или, на худой конец, json, анализируя http-запросы, столько рутины — фактически веб-сервер писать нужно, который http запросы будет транслировать в erlang сообщения.
Erlang in Practice screencasts, можно найти на рутрэкере. Отличное видео, в котором как раз делается чат с вебом/json'ом итд.
Erlang in Practice screencasts, можно найти на рутрэкере. Отличное видео, в котором как раз делается чат с вебом/json'ом итд.
Эмм… Вы же не на голых сокетах писали? Использовали хотябы Mochiweb?
А, ещё… Zotonic / Atatonic, например, — годный фреймворк-CMS. В нагрузку к предыдущей ссылке.
Эх, надо было webmachine хотя бы посмотреть.
Если честно, то за 20+ лет программирования начинал использовать сторонние решения — кроме собственно ЯП и их стандартных или фактически стандартных (а-ля TurboVision, MFC или PECL) библиотек/фреймворков — только случайно наткнувшись на решение заведомо лучшее моего велосипеда. Когда-то для этого были объективные причины — всё что было в распоряжении это ЯП (+ иногда IDE), скопированные на дискетах (а сначала на магнитофонных кассетах и даже hex-дампы с журналов — килобайт 100 точно набил, позже диски с «развалов») встроенные хелпы, вводные статьи с жунлов, книги в читальных залах провинциальных библиотек. Последние лет 10, а особенно 5 возможностей появилось качественно больше, но вот привычки остались. В последнее время мечусь между разными «ньюскул» ЯП, но не могу себя заставить писать с удовольствием пользуясь прослойками между мной и ЯП, как чёрным ящиком. Надо — могу заставить себя писать под RoR, Django или PyQt (последней сейчас себе на жизнь зарабатываю), но для своего проекта выберу PHP(для веб) или C++ (для десктопа), их стандартные или почти стандартные библиотеки+«серые ящики»(библиотеки/фреймворки, которые оказались лучше моих велосипедов.
В общем, я не забиваю гвозди микроскопом, но если беру в руки универсальный инструмент, а не молоток, то не использую не собственноручно сделанные насадки, пока где-то в магазине не наткнусь на заводской набор насадок, делающих, в том числе, то же, что и мои, но лучше.
Знаю, это большой недостаток для современного программиста, но не знаю как с ним бороться — есть задача, я вижу как я её могу сам решить (пускай это займёт годы) и в голову просто не приходит мысль искать готовое решение (в разумных пределах, писать на асме или изобретать свой ЯП точно не буду). Причём не только к программированию это относится, в быту почти тоже самое. Я знаю, как наклеить обои и в голову не приходит кого-то об этом просить или нанимать. Случайно узнал, как ставят гипрок (попросили помочь) — себе его сам потом поставил и т. д., и т. п.
Может это потому, что мне не платят за решение и, тем более, за скорость его разработки, а спрашивают сколько времени займёт и сколько мой час стоит и мне банально выгоднее писать самому, а не искать готовые решения. О выдаче (де-факто, взял 320 часов на разработку CMS — поставил Drupal или WordPress, настроил его за пару часов и остальные 318 работал над другими проектами или просто балду пинал, де-юре условия лицензий не нурушая) чужого кода за свой даже думать не хочется. Тоже и в быту — из доступных мне ресурсов сложнее всего конвертировать в нужные мне ресурсы моё свободное время.
В общем, я не забиваю гвозди микроскопом, но если беру в руки универсальный инструмент, а не молоток, то не использую не собственноручно сделанные насадки, пока где-то в магазине не наткнусь на заводской набор насадок, делающих, в том числе, то же, что и мои, но лучше.
Знаю, это большой недостаток для современного программиста, но не знаю как с ним бороться — есть задача, я вижу как я её могу сам решить (пускай это займёт годы) и в голову просто не приходит мысль искать готовое решение (в разумных пределах, писать на асме или изобретать свой ЯП точно не буду). Причём не только к программированию это относится, в быту почти тоже самое. Я знаю, как наклеить обои и в голову не приходит кого-то об этом просить или нанимать. Случайно узнал, как ставят гипрок (попросили помочь) — себе его сам потом поставил и т. д., и т. п.
Может это потому, что мне не платят за решение и, тем более, за скорость его разработки, а спрашивают сколько времени займёт и сколько мой час стоит и мне банально выгоднее писать самому, а не искать готовые решения. О выдаче (де-факто, взял 320 часов на разработку CMS — поставил Drupal или WordPress, настроил его за пару часов и остальные 318 работал над другими проектами или просто балду пинал, де-юре условия лицензий не нурушая) чужого кода за свой даже думать не хочется. Тоже и в быту — из доступных мне ресурсов сложнее всего конвертировать в нужные мне ресурсы моё свободное время.
покажите реальные нагруженные проекты на ерланге, кроче ejabberd и с натяжкой ерливидео.
echo, couchdb, eddie
Любой проект можно написать хоть на похапе. Но вот какие усилия потребуются на создание и развитие — другой вопрос.
Любой проект можно написать хоть на похапе. Но вот какие усилия потребуются на создание и развитие — другой вопрос.
я же проекты просил, а не инструменты. В смысле — коммерческие и работающие. и массовые.
couchdb — это инструмент.
membase кстати тоже туда же.
echo — даже гугл не знает о таком, так что не считается.
eddie — если это eddie.sourceforge.net/, то также инструмент.
couchdb — это инструмент.
membase кстати тоже туда же.
echo — даже гугл не знает о таком, так что не считается.
eddie — если это eddie.sourceforge.net/, то также инструмент.
www.aboutecho.com/
Вам не приходило в голову, что серьезные проекты пишутся модульно? Гуй — любой фреймворк, который умеет удобно рендерить хтмл и дергать сервисы. Управление узлами кластера — инструменты, предназначенные для этого, в том числе, и в первую очередь, OTP. Обработка данных — быстрые сервисы на статических компилируемых языках. Бла бла бла…
Вам не приходило в голову, что серьезные проекты пишутся модульно? Гуй — любой фреймворк, который умеет удобно рендерить хтмл и дергать сервисы. Управление узлами кластера — инструменты, предназначенные для этого, в том числе, и в первую очередь, OTP. Обработка данных — быстрые сервисы на статических компилируемых языках. Бла бла бла…
Mochimedia
Я даже представить не могу, во сколько строк кода это выльется в эрланге.
Там суть в том, что 80 порт обрабатывает и сокетные соединения по собственному протоколу и стандартный http post/get.
Ну и к тому же проект держит 5000 без проблем онлайна, сколько запросов сказать трудно, т.к. а) упирается в бекенд которые генерит результат (это уже не я писал, там много проблем) б) запросы внутри собственных-протокольных коннектов не учитываются. В общем при профилировании того что написал я, вышло, что если бы бекенд был приличный тысяч 50 бы держало онлайн (это легко проверяется time.time() вызовами перед и после отправки данных бекенда).
Там суть в том, что 80 порт обрабатывает и сокетные соединения по собственному протоколу и стандартный http post/get.
Ну и к тому же проект держит 5000 без проблем онлайна, сколько запросов сказать трудно, т.к. а) упирается в бекенд которые генерит результат (это уже не я писал, там много проблем) б) запросы внутри собственных-протокольных коннектов не учитываются. В общем при профилировании того что написал я, вышло, что если бы бекенд был приличный тысяч 50 бы держало онлайн (это легко проверяется time.time() вызовами перед и после отправки данных бекенда).
Хотя добавлю, пришлось полазить по С коду geventmysql, ибо он не поддерживал 64 битные сообщения. Но зато после патча все заработало.
Сразу видно, что у вас был большой и сложный проект — целых 2 дня писали.
Да проект не достаточно большой, но легкость питона помогает облегчить его еще сильнее. К тому же наработки были до этого, частично скопипастил из своего рабочего кода, частично переписал.
Не вижу ничего сложного в написании http демонов на питоне, тем более на gevent модели, где не надо морочиться с асинккором (который ужасен).
Не вижу ничего сложного в написании http демонов на питоне, тем более на gevent модели, где не надо морочиться с асинккором (который ужасен).
Именно по этому под статику обычно берут evented серваки (nginx, лайти, и.т.д.)
1. Тема весьма интересная и подход вроде серьезный. Но не хватает строгости в изложении и форматирование бы получше.
2. Я не понял, откуда взялась магическая константа 1000?
2. Я не понял, откуда взялась магическая константа 1000?
> Существует два способа обрабатывать параллельные запросы к серверу…
Строго говоря есть еще fsm и продолжения, и возможно даже что-то еще…
Строго говоря есть еще fsm и продолжения, и возможно даже что-то еще…
Вчера, 1 апреля, на киевском iForum в одной из презентаций, посвященной высоконагруженным приложениям на примере чата между фейсбуковцами, докладчик заявил, что морочить себе голову Erlang'ом не стоит, ибо в рунете на нем реально работает только один человек, и даже назвал его фамилию:). Интересно, какова была в этом доля шутки?
На одном отечественном фриланс сайте поиск по erlang дал 15 человек. Фамилии разные. А позиция докладчика — мерять применимость языка/технологии по количеству профессионалов — как минимум странная.
Ничего странного. Если бы язык был популярным (потому что легче в изучении, много литературы, понятен и доступен начинающим, большая база знаний и было наличие различных фреймворков), то аудитория программистов была бы гораздо больше.
Если язык не универсальный, а для определенного круга задач, у него может не быть ничего из вышеперечисленного, но при этом он будет подходить к задаче лучше любого универсального.
И почитателей у него будет ровно столько, сколько и специфических задач. Так что все верно. Более узкая специализация — меньше аудитория. Больше специализация — больше почитателей.
Ну и как соотносится охват аудитории с применимостью языка к конкретной задаче?
Странный подход. Вам задачу решить или найти дешёвых индусско-бурятских программистов?
Тот же Эрланг не сильно сложнее Лиспа, разве что OTP требует чуть-чуть понимания, да либы не для всего есть. Зато пишутся на мах и с удовольствием.
Тот же Эрланг не сильно сложнее Лиспа, разве что OTP требует чуть-чуть понимания, да либы не для всего есть. Зато пишутся на мах и с удовольствием.
Та нет, все-таки странно. Хороший программист мало того что без особых проблем вникнет в новый язык/фреймворк, так еще и полюбит его, если он действительно больше/легче применим к задаче. Разве что останется проблема с дальнейшей поддержкой, программист нынче ленивый и нелюбопытный пошел…
Это позиция реалиста. Никому в реальном мире не нужен язык, с котором вы полгода будете собирать команду разработчиков. Рынок решает.
Найти специалиста, владеющего языком/фреймворком/либой X, который сможет грамотно решить поставленую задачу так же сложно, как найти ерланг разработчика.
А вот если кинуть неподготовленного, но смышлёного программиста в ерланг, то он быстро освоится и выдаст решение, которое будет гораздо качественее чем то что будут выдавать средненькие кодеры, которых можно легко найти.
А вот если кинуть неподготовленного, но смышлёного программиста в ерланг, то он быстро освоится и выдаст решение, которое будет гораздо качественее чем то что будут выдавать средненькие кодеры, которых можно легко найти.
Ваш подход справедлив для вчерашних школьников или студентов, которым интересно изучать новое.
Но в крупных проектах средний возраст разработчиков — около 28-32 лет. Они уже наработали себе опыт и определённый консерватизм, у них есть семья, маленькие дети, пожилые родители. Они не заинтересованы, да и просто не смогут «быстро осваиваться и что-то там выдавать». Им нужна стабильная работа в сфере комфорта на привычных технологиях.
Я не против ерланга, как и любого другого «нетипичного» языка программирования. Но когда бюджет проекта измеряется миллионами (хотя бы рублей), вам их под «быстро осваивающегося студента» никто не даст.
Но в крупных проектах средний возраст разработчиков — около 28-32 лет. Они уже наработали себе опыт и определённый консерватизм, у них есть семья, маленькие дети, пожилые родители. Они не заинтересованы, да и просто не смогут «быстро осваиваться и что-то там выдавать». Им нужна стабильная работа в сфере комфорта на привычных технологиях.
Я не против ерланга, как и любого другого «нетипичного» языка программирования. Но когда бюджет проекта измеряется миллионами (хотя бы рублей), вам их под «быстро осваивающегося студента» никто не даст.
>Им нужна стабильная работа в сфере комфорта на привычных технологиях.
Да, есть специалисты, которые уже 10 лет на каких-нибудь Сях или Жаве могут делать то что может делать студентик на ерланге, но найти такого специалиста будет так же сложно, как найти ерланг программиста.
А программисты, которые останавили своё развитие на каком-нибудь инструменте специализированом для рисования формочек, и находясь в своей зоне комфорта, но пытаясь делать масштабируемые и надёжные сервера — будут годами делать то что будет постоянно ломаться. Но для них то главное, что они будут делать эти заплатки на убогенький продукт и получать свою зп.
Такие программисты точно никогда не пойдут в геймдев, вебдев итд — эти области требует постоянного развития, тк технологии не стоят на месте. Эти программисты рисуют формочки, мы сейчас не о них.
Да, есть специалисты, которые уже 10 лет на каких-нибудь Сях или Жаве могут делать то что может делать студентик на ерланге, но найти такого специалиста будет так же сложно, как найти ерланг программиста.
А программисты, которые останавили своё развитие на каком-нибудь инструменте специализированом для рисования формочек, и находясь в своей зоне комфорта, но пытаясь делать масштабируемые и надёжные сервера — будут годами делать то что будет постоянно ломаться. Но для них то главное, что они будут делать эти заплатки на убогенький продукт и получать свою зп.
Такие программисты точно никогда не пойдут в геймдев, вебдев итд — эти области требует постоянного развития, тк технологии не стоят на месте. Эти программисты рисуют формочки, мы сейчас не о них.
Аж обидно стало. В вебдеве конкретные инструменты тоже не стоят на месте. Взять тот же PHP (шаблонизатор для рисования веб-формочек :D): то, с чего я начинал (PHP3+иногда чужой переделанный код, выбирал фактически между C/C++, PHP3 и Perl) и то, что сейчас (PHP5.3+почти всегда фреймворки и библиотеки с вкраплениями своего кода) — небо и земля.
И да, один проект (мой второй в вебе по счёту) веду уже скоро 10 лет, постоянно его «латая» — сначала от плоского спагетти перешёл к тому, что называют MVC (причём в процедурном стиле), потом перешёл на ООП (его очень не хватало после C++), потом другие паттерны (правда тогда я этого слова не знал, задним числом понял что я их использовал), фреймворки и т. п. NoSQL, memcache, даже сабж — асинхронное программирование (phpdaemon) — в этом продукте сейчас используется. Да, проект убогенький, но масштабируемый (два сервера с распределением нагрузки, отключение любого почти прозрачно для локальных пользователей, F5 только нажать, если отключился во время выполнения запроса), а, главное, пользователи радуются (и платят) когда я делаю очередной «мажорный» релиз. Пробовал и другие инструменты (Java/Spring, C#/ASP .NET, Python/Django, Ruby/RoR, Erlang/Nitrogen, аначинался достался мне проект вообще в виде Clipper-приложения и ~3 года я его делал как VB+MS SQL), но нашёл (может плохо искал, не спорю), что барьер слишком высок — ни за моё вхождение «в тему» (пускай и интересную для меня), ни, тем более, за переписывание приложения пользователи платить не будут.
Вы считаете, что я за 10 лет не развился ни капли? O_o
И да, один проект (мой второй в вебе по счёту) веду уже скоро 10 лет, постоянно его «латая» — сначала от плоского спагетти перешёл к тому, что называют MVC (причём в процедурном стиле), потом перешёл на ООП (его очень не хватало после C++), потом другие паттерны (правда тогда я этого слова не знал, задним числом понял что я их использовал), фреймворки и т. п. NoSQL, memcache, даже сабж — асинхронное программирование (phpdaemon) — в этом продукте сейчас используется. Да, проект убогенький, но масштабируемый (два сервера с распределением нагрузки, отключение любого почти прозрачно для локальных пользователей, F5 только нажать, если отключился во время выполнения запроса), а, главное, пользователи радуются (и платят) когда я делаю очередной «мажорный» релиз. Пробовал и другие инструменты (Java/Spring, C#/ASP .NET, Python/Django, Ruby/RoR, Erlang/Nitrogen, а
Вы считаете, что я за 10 лет не развился ни капли? O_o
>В вебдеве конкретные инструменты тоже не стоят на месте
«Такие программисты точно никогда не пойдут в геймдев, вебдев итд — эти области требует постоянного развития, тк технологии не стоят на месте»
я про другие формочки :)
«Такие программисты точно никогда не пойдут в геймдев, вебдев итд — эти области требует постоянного развития, тк технологии не стоят на месте»
я про другие формочки :)
Ну, тот же VB довольно сильно эволюционировал от VB 6.0 до VB 2010 и, говорят, что переход от stand alone с Windows Forms к веб с ASP .NET при нормальной архитектуре приложения труда не составит даже для программиста, который в первый раз узнал про HTTP, чуть больше чем, что это префикс у адресов сайтов. Аналогичное слышал и про Delphi. Всё-таки основная логика приложения находится в модели (в терминах MVC и т. п.) и, как правило, она представляет собой наибольшую сложность для реализации, а, по слухам, модель можно использовать без изменений, а как принимать и обрабатывать события пользователя и как выводить пользователю реакцию на них не важно.
Но все эти технологии им уже совсем не интересны «Они уже наработали себе опыт и определённый консерватизм, у них есть семья, маленькие дети, пожилые родители.»
И так как их продуктами пользуется 1-50 человек, то там не важно VB 6.0 или VB 2010 :) Главное что он 10 лет проработал за этим станком и «когда бюджет проекта измеряется миллионами (хотя бы рублей)»… :)
В общем формочником я назвал программиста, который занимается этим делом не потомучто ему это нравится, а чтобы выживать.
И так как их продуктами пользуется 1-50 человек, то там не важно VB 6.0 или VB 2010 :) Главное что он 10 лет проработал за этим станком и «когда бюджет проекта измеряется миллионами (хотя бы рублей)»… :)
В общем формочником я назвал программиста, который занимается этим делом не потомучто ему это нравится, а чтобы выживать.
Похоже, вам не везло с разработчиками :-) Поверьте, наличие семьи, маленьких детей и пожилых родителей _никак_ не влияет на желание и умение изучать новые технологии.
А в крупных проектах ограничение на новые технологии практически всегда возникает по маркетинговым причинам: потому что новая технология — это риск. Да, она может и «выстрелить», но может и нет, а это означает впустую потраченное время и деньги. Некоторые компании могут себе позволить на пойти на такое, но большинство — нет, поэтому в крупных проектах чаще используются не технологии «переднего края», а более консервативные, _проверенные_.
Ну и ещё играет свою роль такой фактор, что _крупные_ проекты пишутся _долго_, а технологии меняются быстро. Менять же, например, язык программирования в середине разработки крупного проекта (т.е. по сути выкинуть весь старый код и начать писать его заново) компании могут себе позволить только в случае, если новый язык предоставляет _очень_ большие и _доказанные_ преимущества.
Но это что касается разработки _на_ новых языках. При этом готовые (и, повторюсь, проверенные) инструменты, написанные на этих языках, очень даже часто используются. Если говорить конкретно про Erlang, то это, например, такие вещи, как CouchDB, RabbitMQ и т.д.
А в крупных проектах ограничение на новые технологии практически всегда возникает по маркетинговым причинам: потому что новая технология — это риск. Да, она может и «выстрелить», но может и нет, а это означает впустую потраченное время и деньги. Некоторые компании могут себе позволить на пойти на такое, но большинство — нет, поэтому в крупных проектах чаще используются не технологии «переднего края», а более консервативные, _проверенные_.
Ну и ещё играет свою роль такой фактор, что _крупные_ проекты пишутся _долго_, а технологии меняются быстро. Менять же, например, язык программирования в середине разработки крупного проекта (т.е. по сути выкинуть весь старый код и начать писать его заново) компании могут себе позволить только в случае, если новый язык предоставляет _очень_ большие и _доказанные_ преимущества.
Но это что касается разработки _на_ новых языках. При этом готовые (и, повторюсь, проверенные) инструменты, написанные на этих языках, очень даже часто используются. Если говорить конкретно про Erlang, то это, например, такие вещи, как CouchDB, RabbitMQ и т.д.
Вот поэтому на рынке программирования очень много недопрограммистов с одной стороны и недопроектов с другой.
Нужно искать программиста или команду программистов, а не php-/django-/RoR-разработчика, потому что их много и они дешевле. Поставил задачу программистам и пусть сами выбирают платформу и все остальное.
Нужно искать программиста или команду программистов, а не php-/django-/RoR-разработчика, потому что их много и они дешевле. Поставил задачу программистам и пусть сами выбирают платформу и все остальное.
Ваша позиция называется «порулил и убегай».
Наивно полагать, что произвольно взятая команда вот так единогласно что-то выберет :) Программистов хлебом не корми — дай поспорить о технологиях. По себе знаю.
А в случае ухода ключевых специалистов вы окажетесь в ж… пе на несколько месяцев, пытаясь срочно найти хоть кого-то им на замену.
Группа программистов, как и любая другая группа, нуждается в разумном управлении.
Наивно полагать, что произвольно взятая команда вот так единогласно что-то выберет :) Программистов хлебом не корми — дай поспорить о технологиях. По себе знаю.
А в случае ухода ключевых специалистов вы окажетесь в ж… пе на несколько месяцев, пытаясь срочно найти хоть кого-то им на замену.
Группа программистов, как и любая другая группа, нуждается в разумном управлении.
Со стороны заказчика и со стороны разработчика, наверное, разный должен быть взгляд, не?
Почему? Задачу-то одну решают.
Это не мешает иметь разные взгляды на задачу и искать компромисс )
В школе вы, решая задачи по математике, тоже искали компромисс с учебником/учителем? ;) Задачу формулирует заказчик, исполнителю нужно решить её оптимально по важным для заказчика критериям. Другое дело, когда исполнителю кажется, что задача и/или критерии сформулированы неправильно, неточно (в обе стороны: и слишком широко, и слишком узко), неоптимально и т. п. — тогда святое дело проявить инициативу и предложить другую формулировку задачи/критериев.
То есть на конференции по разработке надо обсуждать не какие технологии в каких случаях применять, а как выбрать технологию, чтобы работодателю было удобно тебя заменить?
Выбор технологии диктуется не только технической эффективностью, иначе все бы писали, грубо говоря, на ассемблере, но и сложностью/временем/стоимостью разработки/поддержки/развития. Плюс ещё куча критериев, например, исключительные права заказчика на код, что исключает использование многих сторонних решений, кроме равзе что аутсорса на таких же условиях.
Выбирать можно в рамках заданных заказчиком условий. Если кажется, что условия неразумны, то можно попытаться предложить другие условия.
Выбирать можно в рамках заданных заказчиком условий. Если кажется, что условия неразумны, то можно попытаться предложить другие условия.
Я с этим и не спорил. В первом сообщении ветки я писал про оценку применимости технологии/ЯП, то есть насколько эффективно данный инструмент решает данную задачу. Разумеется, есть множество других факторов. Но говорить, что Erlang не стоит применять только из-за малого количества профессионалов, это перебор. Как можно мерять эффективность инструмента по количеству людей, которые его используют? Топор используют чаще, чем, я не знаю, надфиль, что теперь, все топором делать?
Эффективность, имхо, включает все факторы. В одних условиях одни факторы важнее, в иных — другие. Но уж применять Erlang или другие непопулярные ЯП/платформы/технологии/…, не предупредив заказчика, что специалистов, кроме вас, на поддержку/развитие проекта ему будет найти непросто/недешево, имхо, называется «подсаживание на иглу».
Эффективность, имхо, включает все факторы.
ну как хотите, это вопрос терминологии.
Но уж применять Erlang или другие непопулярные ЯП/платформы/технологии/…, не предупредив заказчика, что специалистов, кроме вас, на поддержку/развитие проекта ему будет найти непросто/недешево, имхо, называется «подсаживание на иглу».
Я разве такое говорил?
А позиция докладчика — мерять применимость языка/технологии по количеству профессионалов — как минимум странная.
Если их один, да пускай даже 15, на 1/6 земного шара, то вполне обоснованная. Банально эти 15 профессионалов физически не успеют применить технологию везде, где она применима по другим критериям.
Ну и? Предупреждайте, пожалуйста. Заказчик и сам спросит, если не знает, о примерах применения, базе готовых решений и доступности специалистов. Это его зона ответственности, а не разработчика. Как вы будете учитывать факторы, которыми не занимаетесь? Может он уверен, что будет работать именно с вами и малое количество специалистов для него малозначащий фактор? В конце концов, кто-то же все-таки делает проекты на Erlang? Мне по-крайней мере предлагали )
Если задание «сделать сайт», то, по идее, я и не должен сообщать заказчику о деталях (выбор платформы, например :) ) реализации, но это именно моя зона ответственности. Если я на автомате посчитаю, что крутится проект будет на *nix c root-доступом для разворачивания, а окажется, что у заказчика виртуальный хостинг под windows, то переписывать придётся за свой счёт или вообще отказаться от проекта без компенсации потерянного времени, ни раз убеждался.
И почему вы смешиваете постановку задачи и способ ее решения? Я уж не говорю, что не заказчик должен выбирать технологию реализации, в жизни по-всякому бывает.
Я смешиваю? Вы, по-моему, смешиваете. Заказчик формулирует задачу: «Написать сайт с такой-то функциональностью на PHP как можно быстрей», а вы предлагаете писать его на Erlang, пускай даже Erlang для этой функциональности лучше подходит?
А «на PHP» это что-ли не способ?
Перепишу ваш пример:
заказчик формулирует задачу: «Написать сайт с такой-то функциональностью как можно быстрей». Вы ему говорите: могу написать на Erlang или на PHP, выкладываете плюсы/минусы обоих решений, он рассматривает ваши плюсы и минусы, добавляет свои и принимает решение, какой вариант для него более выгоден.
Разве не компромисс? А в вашем случае, от вас никаких решений и не требуется, все решено за вас и ваше мнение можете оставить при себе. Ну или поделиться для справки.
заказчик формулирует задачу: «Написать сайт с такой-то функциональностью как можно быстрей». Вы ему говорите: могу написать на Erlang или на PHP, выкладываете плюсы/минусы обоих решений, он рассматривает ваши плюсы и минусы, добавляет свои и принимает решение, какой вариант для него более выгоден.
Разве не компромисс? А в вашем случае, от вас никаких решений и не требуется, все решено за вас и ваше мнение можете оставить при себе. Ну или поделиться для справки.
Не способ решения задачи, а условие её решения.
Способов, различающихся сложностью/временем/стоимостью разработки/поддержки/развития, написать сайт на PHP — множество. Если попадают под условие — выбирайте любой на ваше усмотрение, критерии выбора — зона вашей ответственности. Считаете, что условие лишнее или даже вредное — ищите, если хотите, компромисс по изменению условий. Сможете доказать заказчику, что его условие мешает оптимальному по каким-то критериям решению задачи и что эти критерии более важны для него, чем условие «на PHP» — будете писать на том, что обсуждали на коференциях. А если условие «на PHP» обязательное, то или будете писать на PHP, или не будете решать эту задачу вовсе, другие, я думаю, найдутся :)
Способов, различающихся сложностью/временем/стоимостью разработки/поддержки/развития, написать сайт на PHP — множество. Если попадают под условие — выбирайте любой на ваше усмотрение, критерии выбора — зона вашей ответственности. Считаете, что условие лишнее или даже вредное — ищите, если хотите, компромисс по изменению условий. Сможете доказать заказчику, что его условие мешает оптимальному по каким-то критериям решению задачи и что эти критерии более важны для него, чем условие «на PHP» — будете писать на том, что обсуждали на коференциях. А если условие «на PHP» обязательное, то или будете писать на PHP, или не будете решать эту задачу вовсе, другие, я думаю, найдутся :)
Ну вот опять. «На PHP» это способ решения задачи. Он просто уже выбран заказчиком с максимальным приоритетом. Так понятнее? Разумеется, в таких условиях вам выбирать нечего.
Ну, вот опять вы путаете способ и условия. Почему «сайт» вы считаете задачей, а «PHP» условием? Может заказчику действительно нужно (и будет выгоднее по всем критериям, кроме ваших предпочтений) консольное приложение на ассемблере или, вообще, реклама на аргентинском ТВ в прайм-тайм, а он почему-то решил, что нужен сайт на PHP? А вы предложите сайт на Erlang…
Я как минимум двух знаю :)
erlang@conference.jabber.ru от 20 до 50 человек онлайн, постоянно что-то обсуждается. Уверен, там не все Erlang разработчики сидят.
groups.google.ru/group/erlang-russian последнее сообщение — вчера.
Жив Erlang в России, жив.
groups.google.ru/group/erlang-russian последнее сообщение — вчера.
Жив Erlang в России, жив.
И почему я об этом узнал, когда в Erlang'е, как в платформе для малобюджетных проектов, разочаровался :(
Не всё ещё потеряно :)
Ну, переписывать уже принятый проект как-то не комильфо, а задача была для меня специфичная, под которую я сразу подумал, что нужен Erlang, но не осилил.
>Существует два способа обрабатывать параллельные запросы к серверу. Потоковые (threaded, синхронные) серверы используют множество одновременно выполняющихся потоков, каждый из которых обрабатывает один запрос. В это время событийные (evented, асинхронные) серверы выполняют единственной цикл событий, который обрабатывает все запросы.
— больше чем два
— parallelism != concurrency
— потоки/евенты — одна фигня, разница лишь в том где хранится стэйт.
дальше идёт ещё больший маразм. Автор явно не понимает проблем при создании масштабируемых(!=производительных) серверов.
— больше чем два
— parallelism != concurrency
— потоки/евенты — одна фигня, разница лишь в том где хранится стэйт.
дальше идёт ещё больший маразм. Автор явно не понимает проблем при создании масштабируемых(!=производительных) серверов.
невнимателен. Там же про запросы, а не про сервера «параллельные запросы к сервер» :)
>Проблему количества поддерживаемых потоков можно решить с помощью специализированных средств, например гринлетов
из-за оверхеда памяти на стэк — это никак не решает проблему
хотя сейчас в gcc4.6 добавили интересную штуку Split Stacks
ещё можно посмотреть в сторону Stackless threads
ну а для питонистов можно посмотреть что-нибудь вроде A new App Engine datastore API, здесь больше решается проблема с лэйтэнси, тк пока обрабатывается один запрос к базе, можно одновременно пытаться запрашивать данные никак не связаные с предыдущим запросом.
>или Erlang-процессов
а вот эрланг проессы как раз отлично подходят для решении проблемы с обработкой кучи риквестов, и при ошибках в этих процессах они не будут вешать весь сервер как это умеет node.js :)
Справедливости ради нужно заметить, что современные асинхронные решения также используют многопоточную модель работы. Делается это ради эффективного использования многоядерных процессоров и многопроцессорных систем. В таких решениях запросы, для которых блокирующая операция выполнилилась помещаются в очередь, откуда выбираются одним из рабочих потоков для выполнения неблокирующей операции. Если для нескольких запросов блокирующая операция завершилась одновременно, то они будут выбраны из очереди и неблокирующая часть каждого запроса будет выполнена в отдельном потоке. Таким образом снижается время обслуживания каждого запроса. В таких решениях кол-во потоков относительно небольшое и равно(или кратно) числу ядер. Одним из примеров такого решения является библиотека Boost.Asio. В документации к библиотеке хорошо описан паттерн асинхронной обработки Proactor.
В большинстве случаев конечно подойдёт.
Но бывают ситуации(хттп риквесты) когда лучше привязывать риквест к определённому треду, чтобы небыло оверхеда на мьютексы/итп, а плюсом от многопоточности служит например общий кэш, разделяемый между всеми риквестами. Ну и балансировка после привязки не особо нужна, тк время жизни риквестов обычно не больше нескольких секунд.
Всё очень сильно зависит от задачи, и внутри одного приложения могут спокойно сосуществовать треды/евенты/и что угодно.
Но бывают ситуации(хттп риквесты) когда лучше привязывать риквест к определённому треду, чтобы небыло оверхеда на мьютексы/итп, а плюсом от многопоточности служит например общий кэш, разделяемый между всеми риквестами. Ну и балансировка после привязки не особо нужна, тк время жизни риквестов обычно не больше нескольких секунд.
Всё очень сильно зависит от задачи, и внутри одного приложения могут спокойно сосуществовать треды/евенты/и что угодно.
Не правда ваша. откуда взялась цифра 1000 переключенйи контекста? В многопоточной версии после окончания обработки потоком задания он, либо получит следующее задание, либо уснёт в его ожидании. Если поток усыпает, то планировщик выполнит «внеочередное» переключние контекста на готовый к исполнению поток. Т.о. при правильной организации рабочих потоков (с использование средств межпотоковой синхронизации, а не простое зацикливание) процессор будет выполнять столько переключений контекста в секунду, сколько нужно. Да, будут налкадные расходны на переключение контеста. Но для современные процессоров 10'000 переключений считается нормой (посмотрите статистику у десктопоной машины), а обращать внимание накладные расходны нужно при достижении примерно от 50'000 до 100'000 переключений контекста. На практичке, такое количество запросов ещё найти нужно — это по 100 запросов в секунду от 1000 пользователей. При этом напоминаю — если есть не пустая очередь задач для потоков, то при правильном построение взаимодействия «внеочередных» переключений контекста не будет вообще — поток просто будет брать очередное задание из очереди. Переключение же контекста убдут
Продолжение:
Переключения же контекста будут только по таймеру планировщика — что неизбежно.
И ещё один момент. Событийная система, как правило, всё равно использует несколько потоков (не всегда, но если). В этом случае обработка очереди событиый также может быть свзяана с накладными расходами и даже переключние контекста.
Остюда мораль — при правильных руках программиста и понимании просходящего бутлочное горлышко многопоточной обработки отодвигается до уровня ~50'000 событий для обработки в секунду. На самом деле существует совсем не много задач, где есть такой темп поступление данных. В плюсе же имеем простоту и понятность программы.
Переключения же контекста будут только по таймеру планировщика — что неизбежно.
И ещё один момент. Событийная система, как правило, всё равно использует несколько потоков (не всегда, но если). В этом случае обработка очереди событиый также может быть свзяана с накладными расходами и даже переключние контекста.
Остюда мораль — при правильных руках программиста и понимании просходящего бутлочное горлышко многопоточной обработки отодвигается до уровня ~50'000 событий для обработки в секунду. На самом деле существует совсем не много задач, где есть такой темп поступление данных. В плюсе же имеем простоту и понятность программы.
Так это же древняя проблема — высокая производительность и масштабируемость. Есть гибридный паттерн, предназначенный как раз для решения этой проблемы — многопоточно-событийный, ака асинхронный ввод-вывод. Суть в том, что 1 поток инициирует операции чтения/записи из/в источник данных, само чтение или запись выполняется в фоновом потоке из пула потоков, а по завершении вызывается каллбек, в том же фоновом потоке. Каллбек может устанавливать какое-нибудь событие. Именно этот паттерн используют все вменяемо написанные серверные приложения. Он даёт максимальную производительность и масштабируемость за счет использования пула потоков с очередью пользовательских запросов. Проблема нехватки производительности решается выделением дополнительных процессоров под серверный процесс.
В Windows эта функциональность встроена — называется Overlapped I/O. Как там с Java я уж не знаю.
В Windows эта функциональность встроена — называется Overlapped I/O. Как там с Java я уж не знаю.
в Java наверное NIO, который поверх бежит систем-специфик (ИМХО)
>Именно этот паттерн используют все вменяемо написанные серверные приложения
нужно преаллокэйтить буфферы для чтения == плохо масштабируется
используйте линукс/фрибсд/итд и неблокирующий I/O :)
нужно преаллокэйтить буфферы для чтения == плохо масштабируется
используйте линукс/фрибсд/итд и неблокирующий I/O :)
Так асинхронный это и есть неблокирующий. А как не выделять буферы? Откуда они иначе возьмутся? Куда-то данные из ядра в пользовательское адресное пространство должны попасть в любом случае. Обычно выделяют буфер в несколько килобайт и в него читают. Выделяют 1 раз, не при каждой операции. И никто не мешает его динамически перевыделять, если окажется что порции данных в него часто не влезают.
К тому же если говорить про сети, клиентское приложение отправляющее данные по протоколу TCP/IP, в праве отправлять данные запроса пакетами хоть по 1 байту данных. Маршрутизаторы могут творить с пакетами что захотят. На сервере не возможно гарантировать, что в 1 пакете придет 1 сообщение в терминах протокола представительного уровня (HTTP, FTP и т.д.), нужна логика склеивания сообщений из кусочков прочитанных данных. Оттуда ползут всякие техники байт-стаффинга. Т.е. тут размер буфера чтения ничего не решает.
К тому же если говорить про сети, клиентское приложение отправляющее данные по протоколу TCP/IP, в праве отправлять данные запроса пакетами хоть по 1 байту данных. Маршрутизаторы могут творить с пакетами что захотят. На сервере не возможно гарантировать, что в 1 пакете придет 1 сообщение в терминах протокола представительного уровня (HTTP, FTP и т.д.), нужна логика склеивания сообщений из кусочков прочитанных данных. Оттуда ползут всякие техники байт-стаффинга. Т.е. тут размер буфера чтения ничего не решает.
>Так асинхронный это и есть неблокирующий.
асинхронным обычно называют proactor pattern, а неблокурующим reactor pattern.
>Куда-то данные из ядра в пользовательское адресное пространство должны попасть в любом случае.
Когда у нас 100тыс соединений, которые проявляют оч мало активности, то зачем нам преаллокэйтить 100тыс буфферов для чтения?
Когда будет какая-то активность, ядро начнёт выделять память под буфферы и уведомит нас о том что поступили какие-то данные на этом соединении, а мы уже потом на стороне приложения сделаем readv в большой вектор страничек и под наше соединение заберём только те странички, что используются.
асинхронным обычно называют proactor pattern, а неблокурующим reactor pattern.
>Куда-то данные из ядра в пользовательское адресное пространство должны попасть в любом случае.
Когда у нас 100тыс соединений, которые проявляют оч мало активности, то зачем нам преаллокэйтить 100тыс буфферов для чтения?
Когда будет какая-то активность, ядро начнёт выделять память под буфферы и уведомит нас о том что поступили какие-то данные на этом соединении, а мы уже потом на стороне приложения сделаем readv в большой вектор страничек и под наше соединение заберём только те странички, что используются.
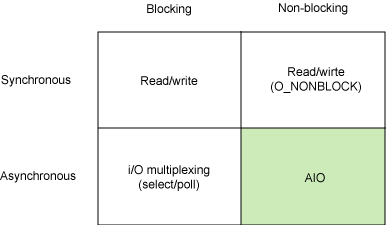
И ещё дополнение. Большинство мифов (именно мифов) о меньшем быстродействии многопоточный обработчиков ростут из кривых рук программистов и разных подходов к работе с сокетами (вот тут собака и зарыта). Большиство приложений, связанных с обработкой большого числа событий, работают с сетью. А сокеты себя ведут очень по разному при блокирующих операциях и работе по собтиям. И снова на сцену выходят руки программистов с неправильным радиусом изгиба — рождаются, то крайности с сотнями/тысячами потоков, то не поддающиеся пониманию и отладке монстирические полностью синхронные событийные моснтры. Ну, или какие-то экотические языки. А в подавляющием большистве задач оптимум бедет между ними — не нужно путать получение/передачу данных и их обработку. Никто не мешает сделать гибрид с событийным приёмом/передачей и пулом потоков для их обработки. Получится прозрачность многопоточной модели с быстродействием событийной.
Как только однопоточной программе, обслуживающей в цикле десять тысяч клиентов, приходится ради одного из них задержаться, например, на секунду, эту секунду ждут все остальные
1) событийные программы не однопоточны: обычно используется пул потоков.
2) для длительных подзапросов используются отдельные пулы потоков на каждую подсистему (БД, диски, сеть), в т.ч. с добавлением потоков по требованию. Во многих случаях API к таким пулам предоставляются ОСью.
С учетом 1 и 2, единственным недостатком событийной модели остается относительная сложность программирования если в инструменте нет поддержки co-routines.
Недавно появилась задача сделать свой велосипед сервер на С++, который бы выдавал некие динамические данные в nginx. Поскольку не являюсь большим специалистом в серверных технологиях, долго думал и пробовал, что бы было лучше использовать.
Остановился на такой модели: есть evented-серверный класс, есть расширяемый пул готовых потоков. Серверный класс принимает запрос и тут же, без задержек, передаёт его в один из ожидающих потоков. Как только поток выполнил запрос (а надо отметить что запрос не чисто вычислительный, так что процессор занимает мало), он снова готов к работе. Если свободных потоков не осталось, я расширяю пул сразу на некоторое число потоков.
Мощное тестирование — впереди. Пока протестированы отдельно серверный класс и работа пула потоков. Надеюсь на лучшее.
Остановился на такой модели: есть evented-серверный класс, есть расширяемый пул готовых потоков. Серверный класс принимает запрос и тут же, без задержек, передаёт его в один из ожидающих потоков. Как только поток выполнил запрос (а надо отметить что запрос не чисто вычислительный, так что процессор занимает мало), он снова готов к работе. Если свободных потоков не осталось, я расширяю пул сразу на некоторое число потоков.
Мощное тестирование — впереди. Пока протестированы отдельно серверный класс и работа пула потоков. Надеюсь на лучшее.
Насчет поточных событий, сильно использующих CPU — ведь можно запустить несколько процессов, по количеству ядер, и использовать CPU на 100%, а любители тредов пусть сами мучаются с тормозами, блокировками, забытыми блокировками и сегфалтами. Естественно, для этого, надо чтобы данные можно было разнести в несколько процессов, но мы веждь умненькие и изначально проектируем систему с учетом этого, да?
Хотя, мысль насчет долгих вычислений, тормозящих все остальные соединения, верная. Но ведь и имногопоточное приложение будет в таком случае тупить, да и не факт что ОС нормально справиттся с шедулингом сотен потоков, да и накладных расходов будет много: расходы на блокировки (при 200 потоках их будет много), расходы на постоянные переключения контекста и шедулинг, постоянные системные вызовы.
Хотя, мысль насчет долгих вычислений, тормозящих все остальные соединения, верная. Но ведь и имногопоточное приложение будет в таком случае тупить, да и не факт что ОС нормально справиттся с шедулингом сотен потоков, да и накладных расходов будет много: расходы на блокировки (при 200 потоках их будет много), расходы на постоянные переключения контекста и шедулинг, постоянные системные вызовы.
Приведенные формулы в статье неправильные. Рассмотрим пример: сервер может обрабатывать только один поток, время CPU и ожидания одинаковы, т.е.:
t=1
c=w
Тогда очевидно, что сервер при использовании потоков сможет обработать только:
1000/(c+w) = 1000/2c
т.е. в 2 раза меньше, чем значение, указанное в статье. Более того, в реальности производительный софт использует следующий подход:
1. Проакторная модель: события асинхронные, по окончании события зовется callback.
2. События распрараллеливаются в t потоках.
3. Запросы могут включать в себя «легкую» логику (можно быстро вернуть ответ) и «тяжелую» (например, нужно обратиться к базе данных). «Легкая» логика обрабатывается тут же, «тяжелая» использует другой пул потоков. Для этого пула количество потоков уже, как правило, превышает t.
Таким образом в реальности продвинутые высоконагруженные сервера используют гибридную модель.
t=1
c=w
Тогда очевидно, что сервер при использовании потоков сможет обработать только:
1000/(c+w) = 1000/2c
т.е. в 2 раза меньше, чем значение, указанное в статье. Более того, в реальности производительный софт использует следующий подход:
1. Проакторная модель: события асинхронные, по окончании события зовется callback.
2. События распрараллеливаются в t потоках.
3. Запросы могут включать в себя «легкую» логику (можно быстро вернуть ответ) и «тяжелую» (например, нужно обратиться к базе данных). «Легкая» логика обрабатывается тут же, «тяжелая» использует другой пул потоков. Для этого пула количество потоков уже, как правило, превышает t.
Таким образом в реальности продвинутые высоконагруженные сервера используют гибридную модель.
Sign up to leave a comment.
Потоки или события