Ноды кластера очень сильно зависят от их физического соединения. Как показывает практика, большинство случаев отработки failove-миграций ресурсов происходит по вине именно сетевых соединений. Поэтому от того, как у вас осуществляется соединение между нодами и настроены размещения ресурсов, зависит очень многое.
Для примера, я буду рассматривать кластер состоящий из двух нод. Одна нода будет в состоянии Active, а другая в состоянии Hot Spare. Наш кластер будет обслуживать внутреннюю приватную сеть и содержать следующие ресурсы кластера: Mysql сервер и Mysql VIP. На двух нодах Mysql сервер будет запущен c репликацией Master-Master. Однако вся работа будет производиться только с одним экземпляром через виртуальный ip адрес. Такая схема позволяет получить максимально быстрый failover. Опустим выбор именно данной конфигурации её плюсы и минусы — нас сейчас интересует доступность этих ресурсов в случае падения сетевых линков.
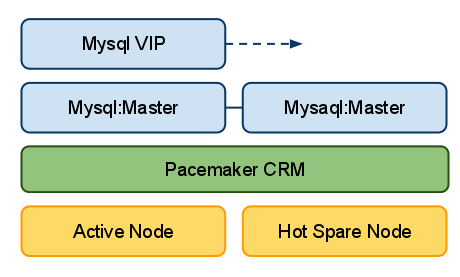
рис. 1 Схема класстера
Главное на что следует обратить внимание при проектировании любого кластера это избыточность сетевого соединения между нодами кластера. Другими словами должны быть как минимум два крос-соединения между нашими нодами. Их можно объединить посредствам бондинга в один интерфейс либо просто использовать два разных интерфейса в конфигурации heartbeat или corosynс. При проектировании нового кластера я бы рекомендовал использовать corosync, не только потому что разработка heartbeat потихоньку сворачивается в сторону pacemaker и corosync, а потому, что он обладает более гибкими настройками для работы с несколькими интерфейсами и может использовать их параллельно или в режиме “действующий и запасной”.
Не следование правилам резервирования или выделения отдельных сетевых интерфейсов может привести к ситуации расщепления разума (split brain). Что в принципе не сулит ничего хорошего. Также удостоверьтесь что используете разные сетевые карты, а то будет не много толку при аппаратном сбое.
Т.к. у нас кластер состоит из двух нод — то мы имеем проблемы с кворум. А точнее его полное отсутствие, что опять же намекает на необходимость резервния соединения между нодами.
На этом хватит теории переходим к практике.
Выставляем поведение нод в случае отсутсвия кворума:
Так же для кластера из двух нод я рекомендую делать кластер не симметричным. Это позволит более точно провести его настройку и отловить странное поведение:
Несимметричный кластер не будет запускать ресурсы если у них явно не указаны значения стоимости их запуска на каждой из нод. К примеру, вот так мы можем задать значение 100 для некого ресурса P_RESOURCE для ноды first.local и значиение 10 — для ноды second.local.
Данная конфигурация говорит нам, что ресурс запустится на ноде first.local — т.к. у него суммарная стоимость на этой ноде оказалась больше чем на ноде second.local.
Я умышленно опускаю первичные настройки нод, настройку бондига (по желанию), установку pacemaker и corosync, настройку Master-Master реплиацию и т.д. Этого и так достаточно в интернетах и легко находится. В свою очередь я покажу как нужно правильно настраивать ресурсы кластера с учётом сетевой специфики.
Условимся, что у нас приватная сеть: 192.168.56.0/24, Mysql VIP — 192.168.56.133 и две ноды в сети, которые мы будем использовать для оценки адекватности сетевого соединения: 192.168.56.1 и 192.168.56.100.
Небольшое отступление: для правильной работы Mysql в связке с pacemaker нужно отключить его автоматический старт:
Т.к. Муsql сервер используется только в приватной сети — падение приватного коннекта на активной ноде должно приводить к миграции ресурса на другую ноду, где коннект присутсвует. Добьёмся такого поведения.
Мы должны проверять состояния хостов в приватной сети. Для этого мы будем использовать ресурс кластера ping. В данный момент существуют следующие ресурсы, которые позволяют производить мониторинг состояния сети:
Два из которых являются устаревшими.
На основе этих ресурсов мы можем управлять размещением ресурсов на нодах. Делается это при помощи параметра location.
Для примера, сначала, опишем конфигурацию pacemaker кластера показанную на рисунке (рис. 1):
Данная конфигурация описывает кластер из двух нод с двумя Mysql мастерами (клонированными). Работа с базой ведётся через VIP адрес.
Для случае несемметричного кластера нам необходимо явно задать значения для location:
Данная запись говорит нам о том, что ресурc типа “clone” стоит запускать на двух нодах кластера.
Теперь тоже самое для VIP:
Здесь мы отдаём предпочтение на запуск VIP на ноде first.local
И завершаем настройку:
Если теперь проверить как работает failover — то при запуске VIP стартует на first.local при её падении (kill -9 corosync) — он переезжает на second.local. Однако при возвращении ноды first.local — он возвращается обратно. Это связано с тем, что значение score для first.local болше чем на secon.local (100 > 10). Чтобы предотвратить такие переезды на высоконагруженном кластере, которые могут привести к нежелательным простоям, мы должны задать параметр “липкости” (resource-stickiness):
Теперь повторяя ту же операцию мы имеем значение score: 110+10=120 против 100, что предотвращает переезд.
Кластер работает и позволяет в случае неполадок с железом/питанием переключаться автоматически на резервную ноду.
Теперь настроем мониторинг внутренней сети. Будем пинговать 192.168.56.1 и 192.168.56.100:
Данная конфигурация пингует два хоста. Каждый хост оценивается в 111 очков. Суммарное значение для каждой ноды хранится в переменной ping_intranet. Эти значения можно и нужно использовать при определении места расположения ресурса. Теперь укажем VIP чтобы он использовал эти очки в решении, где ему находиться:
Эти дополнительные очки сумируются с пердыдущими заданными нами. И исходя из итоговой суммы определяется положение ресурса.
Мониторинг состояния кластера с указанием значении score производиться двумя утилитами: ptest и crm_mon:

Для того, чтобы перевести кластер в исходное положение необходимо перенести ресурс на ноду first.local:
После этого ресур получает location с 1000000 очками (это INF для pacemaker) и переезжает на first.local. Очень важно дальше сделать unmove этого ресурса, который вернёт очки locatoin на место, но не поменяет расположение ресурса, т.к. у него и так будет больше очков (см. начальную ситуацию):
Можно проверять запущен ли ресурс ping’a и проверять его значение:
Данный location запрещает размещать ресурс P_RESOURCE на ноде, где пинг меньше либо равен 0 (lte — less then or equal) или не запущен ресурс пинга.
Можно также совместить это правило с именем ноды:
Говорит нам что если это нода first.local и пинг =< 0, то этот ресурс здесь не может находиться.
Для примера, я буду рассматривать кластер состоящий из двух нод. Одна нода будет в состоянии Active, а другая в состоянии Hot Spare. Наш кластер будет обслуживать внутреннюю приватную сеть и содержать следующие ресурсы кластера: Mysql сервер и Mysql VIP. На двух нодах Mysql сервер будет запущен c репликацией Master-Master. Однако вся работа будет производиться только с одним экземпляром через виртуальный ip адрес. Такая схема позволяет получить максимально быстрый failover. Опустим выбор именно данной конфигурации её плюсы и минусы — нас сейчас интересует доступность этих ресурсов в случае падения сетевых линков.
рис. 1 Схема класстера
Главное на что следует обратить внимание при проектировании любого кластера это избыточность сетевого соединения между нодами кластера. Другими словами должны быть как минимум два крос-соединения между нашими нодами. Их можно объединить посредствам бондинга в один интерфейс либо просто использовать два разных интерфейса в конфигурации heartbeat или corosynс. При проектировании нового кластера я бы рекомендовал использовать corosync, не только потому что разработка heartbeat потихоньку сворачивается в сторону pacemaker и corosync, а потому, что он обладает более гибкими настройками для работы с несколькими интерфейсами и может использовать их параллельно или в режиме “действующий и запасной”.
Не следование правилам резервирования или выделения отдельных сетевых интерфейсов может привести к ситуации расщепления разума (split brain). Что в принципе не сулит ничего хорошего. Также удостоверьтесь что используете разные сетевые карты, а то будет не много толку при аппаратном сбое.
Т.к. у нас кластер состоит из двух нод — то мы имеем проблемы с кворум. А точнее его полное отсутствие, что опять же намекает на необходимость резервния соединения между нодами.
На этом хватит теории переходим к практике.
Выставляем поведение нод в случае отсутсвия кворума:
crm configure property no-quorum-policy="ignore"
Так же для кластера из двух нод я рекомендую делать кластер не симметричным. Это позволит более точно провести его настройку и отловить странное поведение:
crm configure property symmetric-cluster="false"
Несимметричный кластер не будет запускать ресурсы если у них явно не указаны значения стоимости их запуска на каждой из нод. К примеру, вот так мы можем задать значение 100 для некого ресурса P_RESOURCE для ноды first.local и значиение 10 — для ноды second.local.
location L_RESOURCE_01 P_RESOURCE 100: first.local location L_RESOURCE_02 P_RESOURCE 10: second.local
Данная конфигурация говорит нам, что ресурс запустится на ноде first.local — т.к. у него суммарная стоимость на этой ноде оказалась больше чем на ноде second.local.
Я умышленно опускаю первичные настройки нод, настройку бондига (по желанию), установку pacemaker и corosync, настройку Master-Master реплиацию и т.д. Этого и так достаточно в интернетах и легко находится. В свою очередь я покажу как нужно правильно настраивать ресурсы кластера с учётом сетевой специфики.
Условимся, что у нас приватная сеть: 192.168.56.0/24, Mysql VIP — 192.168.56.133 и две ноды в сети, которые мы будем использовать для оценки адекватности сетевого соединения: 192.168.56.1 и 192.168.56.100.
Небольшое отступление: для правильной работы Mysql в связке с pacemaker нужно отключить его автоматический старт:
chkconfig mysql --list mysql 0:off 1:off 2:off 3:off 4:off 5:off 6:off
Т.к. Муsql сервер используется только в приватной сети — падение приватного коннекта на активной ноде должно приводить к миграции ресурса на другую ноду, где коннект присутсвует. Добьёмся такого поведения.
Мы должны проверять состояния хостов в приватной сети. Для этого мы будем использовать ресурс кластера ping. В данный момент существуют следующие ресурсы, которые позволяют производить мониторинг состояния сети:
ocf:heartbeat:pingd (Deprecated) ocf:pacemaker:pingd (Deprecated) ocf:pacemaker:ping
Два из которых являются устаревшими.
На основе этих ресурсов мы можем управлять размещением ресурсов на нодах. Делается это при помощи параметра location.
Для примера, сначала, опишем конфигурацию pacemaker кластера показанную на рисунке (рис. 1):
crm configure primitive P_MYSQL lsb:mysql primitive P_MYSQL_IP ocf:heartbeat:IPaddr2 params \ ip="192.168.56.133" nic="eth0" clone CL_MYSQL P_MYSQL clone-max="2" clone-node-max="1" \ globally-unique="false"
Данная конфигурация описывает кластер из двух нод с двумя Mysql мастерами (клонированными). Работа с базой ведётся через VIP адрес.
Для случае несемметричного кластера нам необходимо явно задать значения для location:
location L_MYSQL_01 CL_MYSQL 100: first.local location L_MYSQL_02 CL_MYSQL 100: second.local
Данная запись говорит нам о том, что ресурc типа “clone” стоит запускать на двух нодах кластера.
Теперь тоже самое для VIP:
location L_MYSQL_IP_01 P_MYSQL_IP 100: first.local location L_MYSQL_IP_02 P_MYSQL_IP 10: second.local
Здесь мы отдаём предпочтение на запуск VIP на ноде first.local
И завершаем настройку:
commit
Если теперь проверить как работает failover — то при запуске VIP стартует на first.local при её падении (kill -9 corosync) — он переезжает на second.local. Однако при возвращении ноды first.local — он возвращается обратно. Это связано с тем, что значение score для first.local болше чем на secon.local (100 > 10). Чтобы предотвратить такие переезды на высоконагруженном кластере, которые могут привести к нежелательным простоям, мы должны задать параметр “липкости” (resource-stickiness):
crm configure property rsc_defaults resource-stickiness="110"
Теперь повторяя ту же операцию мы имеем значение score: 110+10=120 против 100, что предотвращает переезд.
Кластер работает и позволяет в случае неполадок с железом/питанием переключаться автоматически на резервную ноду.
Теперь настроем мониторинг внутренней сети. Будем пинговать 192.168.56.1 и 192.168.56.100:
crm configure primitive P_INTRANET ocf:pacemaker:ping \ params host_list="192.168.56.1 192.168.56.100" \ multiplier="111" name="ping_intranet" \ op monitor interval="5s" timeout="20s" clone CL_INTRANET P_INTRANET globally-unique="false" location L_INTRANET_01 CL_INTRANET 100: first.local location L_INTRANET_02 CL_INTRANET 100: second.local commit
Данная конфигурация пингует два хоста. Каждый хост оценивается в 111 очков. Суммарное значение для каждой ноды хранится в переменной ping_intranet. Эти значения можно и нужно использовать при определении места расположения ресурса. Теперь укажем VIP чтобы он использовал эти очки в решении, где ему находиться:
crm configure location L_MYSQL_IP_PING_INTRANET P_MYSQL_IP rule \ ping_intranet: defined intranet commit
Эти дополнительные очки сумируются с пердыдущими заданными нами. И исходя из итоговой суммы определяется положение ресурса.
Мониторинг состояния кластера с указанием значении score производиться двумя утилитами: ptest и crm_mon:
- ptest -sL — показывает текущие значение размещения для кажой ноды.
- crm_mon -A — показывает состояние переменной ping_intranet для каждой из нод.
Для того, чтобы перевести кластер в исходное положение необходимо перенести ресурс на ноду first.local:
crm resource move P_MYSQL_IP first.local
После этого ресур получает location с 1000000 очками (это INF для pacemaker) и переезжает на first.local. Очень важно дальше сделать unmove этого ресурса, который вернёт очки locatoin на место, но не поменяет расположение ресурса, т.к. у него и так будет больше очков (см. начальную ситуацию):
crm resource unmove P_MYSQL_IP
Что ещё можно делать с location и ping
Можно проверять запущен ли ресурс ping’a и проверять его значение:
location L_RESOURCE P_RESOURCE rule -inf: not_defined ping_intranet or ping_intranet lte 0
Данный location запрещает размещать ресурс P_RESOURCE на ноде, где пинг меньше либо равен 0 (lte — less then or equal) или не запущен ресурс пинга.
Можно также совместить это правило с именем ноды:
location L_RESOURCE P_RESOURCE rule -inf: #host eq first.local and ping_intranet lte 0
Говорит нам что если это нода first.local и пинг =< 0, то этот ресурс здесь не может находиться.
