Введение
Долгое время считалось, что динамический анализ программ является слишком тяжеловесным подходом к обнаружению программных дефектов, и полученные результаты не оправдывают затраченных усилий и ресурсов. Однако, две важные тенденции развития современной индустрии производства программного обеспечения позволяют по-новому взглянуть на эту проблему. С одной стороны, при постоянном увеличении объема и сложности ПО любые автоматические средства обнаружения ошибок и контроля качества могут оказаться полезными и востребованными. С другой – непрерывный рост производительности современных вычислительных систем позволяет эффективно решать все более сложные вычислительные задачи. Последние исследовательские работы в области динамического анализа такие, как SAGE, KLEE и Avalanche, демонстрируют, что несмотря на присущую этому подходу сложность, его использование оправдано, по крайней мере, для некоторого класса программ.
Динамический vs Статический анализ
В качестве более эффективной альтернативы динамическому анализу часто рассматривают статический анализ. В случае статического анализа поиск возможных ошибок осуществляется без запуска исследуемой программы, например, по исходному коду приложения. Обычно при этом строится абстрактная модель программы, которая, собственно, и является объектом анализа.
При этом следует подчеркнуть следующие характерные особенности статического анализа:
- Возможен раздельный анализ отдельно взятых фрагментов программы (обычно отдельных функций или процедур), что дает достаточно эффективный способ борьбы с нелинейным ростом сложности анализа.
- Возможны ложные срабатывания, обусловленные либо тем, что при построении абстрактной модели некоторые детали игнорируются, либо тем, что анализ модели не является исчерпывающим.
- При обнаружении дефекта возникают, во-первых, проблема проверки истинности обнаруженного дефекта (false positive) и, во-вторых, проблема воспроизведения найденного дефекта при запуске программы на определенных входных данных.
В отличие от статического анализа, динамический анализ осуществляется во время работы программы. При этом:
- Для запуска программы требуются некоторые входные данные.
- Динамический анализ обнаруживает дефекты только на трассе, определяемой конкретными входными данными; дефекты, находящиеся в других частях программы, не будут обнаружены.
- В большинстве реализаций появление ложных срабатываний исключено, так как обнаружение ошибки происходит в момент ее возникновения в программе; таким образом, обнаруженная ошибка является не предсказанием, сделанным на основе анализа модели программы, а констатацией факта ее возникновения.
Применение
Автоматическое тестирование в первую очередь предназначено для программ, для которых работоспособность и безопасность при любых входных данных являются наиважнейшими приоритетами: веб-сервер, клиент/сервер SSH, sandboxing, сетевые протоколы.
Fuzz testing (фаззинг)
Фаззинг – методика тестирования, при которой на вход программы подаются невалидные, непредусмотренные или случайные данные.
Основная идея такого подхода состоит в том, чтобы случайным образом “мутировать”, т.е. изменять ожидаемые программой входные данные в произвольных местах. Все фаззеры работают примерно одинаковым образом, позволяя задавать некоторые ограничения на мутирование входных данных определенными байтами или последовательностью байтов. В качестве примера можно упомянуть:zzuf (linux), minifuzz (Windows), filefuzz (Windows). Фаззеры протоколов: PROTOS(WAP, HTTP-reply, LDAP, SNMP, SIP) (Java), SPIKE (linux) . Фреймворки фаззеров: Sulley (фреймворк для создания сложных структур данных).
Fuzz testing – предтеча автоматического тестирования, метод “грубой силы”. Из преимуществ данного подхода выделяется только его простота. Очевидным же недостатком является то, что фаззер ничего не знает о внутреннем устройстве программы и, в конечном итоге, для полного покрытия кода вынужден перебирать астрономическое количество вариантов (как нетрудно догадаться, полный перебор растет экспоненциально от размера входных данных O(c^n),c>1).
Фаззеры нового поколения (обзор)
Логическим, но не таким простым продолжением идеи автоматического тестирования стало появление подходов и программ, позволяющих накладывать ограничения на мутируемые входные данные с учетом специфики исследуемой программы.
Отслеживание помеченных данных в программе
Вводится понятие символических или помеченных (tainted) данных – данных, полученных программой из внешнего источника (стандартный поток ввода, файлы, переменные окружения и т. д.). Распространенным решением этой задачи является перехват набора системных вызовов: open, close, read, write, lseek (Avalanche,KLEE).
Инструментация кода
Код исследуемой программы приводится к виду, удобному для анализа. Например, используется внутреннее независимое от аппаратной платформы представление valgrind (Avalanche) или анализируется удобный для разбора сам по себе llvm-байткод программы(KLEE).
Инструментированный код позволяет легко находить потенциально опасные инструкции (например, деление на ноль или разыменование нулевого указателя) и их операнды, а также инструкции ветвления, зависящие от помеченных данных. Анализируя инструкции, инструмент составляет логические условия на помеченные данные и передает запрос на выполнимость “решателю” булевских формул (SAT Solver).
Решение булевских ограничений
SAT Solvers – решают задачи выполнимости булевых формул. Отвечают на вопрос: всегда ли выполнена заданная формула, и если не всегда, то выдается набор значений, на котором она ложна. Результаты работы подобных решателей используется широким набором анализирующих программ, от theorem provers до анализаторов генетического кода в биоинформатике. Подобные программы интересны сами по себе и требуют отдельного рассмотрения. Примеры: STP, MiniSAT.
Моделирование окружения
Кроме перехвата системных вызовов, для автоматической генерации условий для “решателя” булевских формул, анализаторам необходимо формализовать задачу. Входной файл, набор регистров и адресное пространство (память) программы представляются c помощью массивов булевского “решателя”.
Перебор путей в программе
Получив ответ от “решателя”, инструмент получает условие на входные данные для инвертирования исследуемого условного перехода или выясняет, что оно всегда истинно или ложно. Каждый вариант условия создает новый независимый путь в программе, и программе приходится рассматривать каждый путь и условия для его выполнения независимо, т.е. пути “форкаются” на каждой инструкции ветвления, зависящей от входных данных. Новые входные данные могут открыть ранее не открытые базовые блоки исследуемой программы и так далее. Для исчерпывающего тестирования необходим полный перебор всех возможных путей в программе. Так как скорость роста количества путей хоть и значительно снизилась по сравнению с методом грубой силы (~O(2^n), где n – количество условных переходов, зависящих от входных данных), но все еще остается значительной. Анализаторы вынуждены использовать различные эвристики для приоритезации анализа некоторых путей. В частности, различают выбор пути, покрывающего наибольшее количество непокрытых (новых) базовых блоков (Avalanche, KLEE) и выбор случайного пути (KLEE).
Avalanche
Avalanche – инструмент обнаружения программных дефектов при помощи динамического анализа. Avalanche использует возможности динамической инструментации программы, предоставляемые Valgrind, для сбора и анализа трассы выполнения программы. Результатом такого анализа становится либо набор входных данных, на которых в программе возникает ошибка, либо набор новых тестовых данных, позволяющий обойти ранее не выполнявшиеся и, соответственно, еще не проверенные фрагменты программы. Таким образом, имея единственный набор тестовых данных, Avalanche реализует итеративный динамический анализ, при котором программа многократно выполняется на различных, автоматически генерированных тестовых данных, при этом каждый новый запуск увеличивает покрытие кода программы такими тестами.
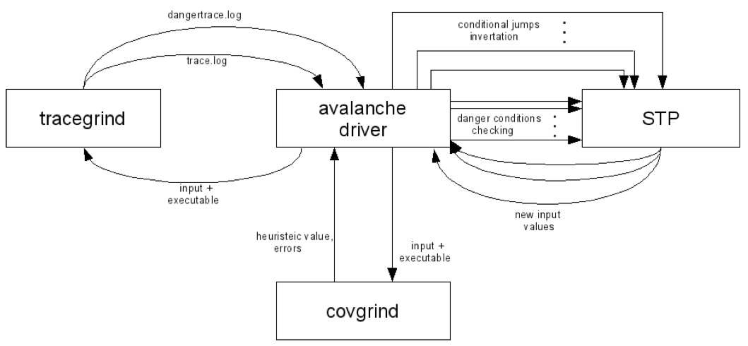
Общая схема работы
Инструмент Avalanche состоит из 4 основных компонент: двух модулей расширения (плагинов) Valgrind – Tracegrind и Covgrind, инструмента проверки выполнимости ограничений STP и управляющего модуля.
Tracegrind динамически отслеживает поток помеченных данных в анализируемой программе и собирает условия для обхода ее непройденных частей и для срабатывания опасных операций. Эти условия при помощи управляющего модуля передаются STP для исследования их выполнимости. Если какое-то из условий выполнимо, то STP определяет те значения всех входящих в условия переменных (в том числе и значения байтов входного файла), которые обращают условие в истину.
- В случае выполнимости условий для срабатывания опасных операций программа запускается управляющим модулем повторно (на этот раз без какой-либо инструментации) с соответствующим входным файлом для подтверждения найденной ошибки.
- Выполнимые условия для обхода непройденных частей программы определяют набор возможных входных файлов для новых запусков программы. Таким образом, после каждого запуска программы инструментом STP автоматически генерируется множество входных файлов для последующих запусков анализа.
- Далее встает задача выбора из этого множества наиболее “интересных” входных данных, т.е. в первую очередь должны обрабатываться входные данные, на которых наиболее вероятно возникновение ошибки. Для решения этой задачи используется эвристическая метрика – количество ранее не обойденных базовых блоков в программе (базовый блок здесь понимается в том смысле, как его определяет фреймворк Valgrind). Для измерения значения эвристики используется компонент Covgrind, в функции которого входит также фиксация возможных ошибок выполнения. Covgrind гораздо более легковесный модуль, нежели Tracegrind, поэтому возможно сравнительно быстрое измерение значения эвристики для всех полученных ранее входных файлов и выбор входного файла с ее наибольшим значением.
Ограничения
- один помеченный входной файл или сокет
- анализ ошибок ограничен разыменованием нулевого указателя и делением на ноль.
Результаты
Эффективность поиска ошибок при помощи Avalanche была исследована на большом числе проектов с открытым исходным кодом.
- qtdump (libquicktime-1.1.3). Три дефекта связаны с разыменованием нулевого указателя, один – с наличием бесконечного цикла, еще в одном случае имеет место обращение по некорректному адресу (ошибка сегментации). Часть дефектов исправлена разработчиком.
- flvdumper (gnash-0.8.6). Непосредственное возникновение дефекта связано с появлением исключительной ситуации в используемой приложением библиотеке boost (один из внутренних указателей библиотеки boost оказывается равен нулю). Поскольку само приложение не перехватывает возникшее исключение, выполнение программы завершается с сигналом SIGABRT. Дефект исправлен разработчиком.
- cjpeg (libjpeg7). Приложение читает из файла нулевое значение и без соответствующей проверки использует его в качестве делителя, что приводит к возникновению исключения плавающей точки и завершению программы с сигналом SIGFPE. Дефект исправлен разработчиком.
- swfdump (swftools-0.9.0). Возникновение обоих дефектов связано с разыменованием нулевого указателя.
KLEE
KLEE несколько отличается от Avalanche тем, что не ищет подозрительные места, а пытается покрыть как можно больше кода и провести исчерпывающий анализ путей в программе. По общей схема KLEE аналогичен Avalanche, но использует другие базовые инструменты для решения задачи, что накладывает свои ограничения и дает свои преимущества.
- Вместо инструментации valgrind'а, которую использует Avalanche, KLEE анализурует программы в llvm-байткоде. Соответственно, это позволяет анализировать программу на любом языке программирования, для которого есть llvm-бэкэнд.
- Для решения задачи булевских ограничений KLEE так же использует STP.
- KLEE так же перехватывает около 50 системных вызовов, позволяя выполняться множеству виртуальных процессов параллельно, не мешая друг другу.
- Оптимизация и кэширование запросов к STP.
KLEE представляет собой символическую виртуальную машину, где параллельно выполняются символические процессы (в рамках терминологии KLEE: states), где каждый процесс представляет собой один из путей в исследуемой программе. Эффективная реализация форков таких процессов (не средствами системы) на каждом ветвлении в программе, позволяет анализировать большое количество путей одновременно.
Для каждого уникального пройденного пути KLEE сохраняет набор входных данных, необходимых для прохождения по этому пути.
Возможности KLEE позволяют с малыми затратами (предоставляется обширный API) проверить эквивалентность любых двух функций (проверка идентичной функциональности по работающему прототипу, рефакторинг) на всем диапазоне заданных входных данных.
Следующий пример иллюстрирует данную функциональность:
unsigned mod_opt(unsigned x, unsigned y) {
if((y & −y) == y) // power of two?
return x & (y−1);
else
return x % y;
}
unsigned mod(unsigned x, unsigned y) {
return x % y;
}
int main() {
unsigned x,y;
make symbolic(&x, sizeof(x));
make symbolic(&y, sizeof(y));
assert(mod(x,y) == mod_opt(x,y));
return 0;
}
Запустив KLEE на данном примере, можно убедится в эквивалентности двух функций во всем диапазоне входных значений (y!=0). Решая задачу на невыполнение условия в ассерте, KLEE на основе перебора всех возможных путей приходит к выводу об эквивалентности двух функций на всем диапазоне значений.
Результаты
Для получения реальных результатов тестирования авторы проанализировали весь набор программ пакета coreutils 6.11. Средней процент покрытия кода составил 94%. Всего программа сгенерировала 3321 набор входных данных, позволяющих покрыть весь указанный процент кода. Так же было найдено 10 уникальных ошибок, которые были признаны разработчиками пакета как реальные дефекты в программах, что является очень хорошим достижением, так как этот набор программ разрабатывается более 20 лет и большинство ошибок было устранено.
Ограничения
- нет поддержки многопоточных приложений, символических данных с плавающей точкой (ограничение STP), ассемблерные вставки.
- тестируемое приложение должно быть собрано в llvm-байт код (так же как и его библиотеки!).
- для эффективного анализа нужно править код.
Предварительные выводы
Безусловно, динамический анализ найдет свою нишу среди инструментов помогающих отдельным программистам и командам программистов решать поставленную задачу, т.к. является эффективным способом нахождения ошибок в программах, а так же доказательством их отсутствия! В в некоторых случаях подобные инструменты просто жизненно необходимы (Mission critical software: RTOS, системы управления производством, авиационное программное обеспечение и так далее).
Заключение
Планируется продолжение тематики статьи (результаты некоторого опыта работы с avalanche и KLEE, а также сравнение KLEE и Avalanche, обзор S2E (https://s2e.epfl.ch) (Selection Symbolic Execution)) при условии положительной обратной связи с читателями Хабра.
Статья содержит фрагменты следующих работ: avalanche_article, KLEE, Применение fuzz-тестирования.
