 Доброго времени суток!
Доброго времени суток! Как известно, одной из важных задач, решаемых обработкой изображений (помимо сброса пары кг и укрывания дефектов кожи на аватарках), является поиск и распознавание нужных нам объектов на сцене. Но этот процесс весьма сложный и ресурсоемкий, что делает его неприменимым в системах реального времени. Сегодня мы и поговорим, нельзя ли каким-то образом решить эту проблему и ускорить процесс поиска нужного объекта на сцене, с минимальными потерями в точности (а может, и без них вовсе). И вообще, причем тут папоротники?
PS
Традиционно много картинок.
Вводная
Итак, начнем. Классический метод распознавания чего-либо состоит из следующих этапов:
- Предобработка изображения (выравнивание ярокости, выделение контуров, подгон размеров и много чего еще);
- Выделение локальных особенностей (в англоязычной литературе local descriptors/features, keypoints);
- Обучаем классификатор.
После этого начинается, собственно, рабочий процесс:
- Предобработка текущего изображения;
- Извлечение ключевых точек;
- Отдаем их классификатору на распознавание;
- Используем полученные результаты («розовый слон в верхнем углу», «человек по правому борту»...) в решении насущной задачи.
У такого подхода есть вполне очевидная проблема — выделение локальных особенностей. Это довольно-таки медленный процесс (особенно для больших изображений). Давайте посмотрим, нельзя ли от него избавиться (или, скорее, заменить чем-то более быстрым). Стоит отметить, что если скорость распознавания не принципиальна, то это отличный метод. Например, юный фотограф может распихать тысячи своих творений по папкам в автоматическом режиме («море», «универ», «работа», «спрятать от родителей»). Не без ошибок, конечно, но тем не менее. Но об этом подходе поговорим в другой раз.
Уголок математика
Подойдем формально к нашей задаче.
Предположим, у нас есть небольшая окрестность вокруг некоей точки (в англ. литературе image patch). Нам нужно знать, к какому классу из известных нам она относится (картинка рядом).

Очевидно, нам нужен классификатор, который на вход принимает множество patch'ей, на выходе выдает предполагаемый класс изображения. Patch'и мы можем выбирать разными способами — можно самому мышкой натыкать, можно брать пиксели со случайными координатами. Но разум подсказывает, что проще всего выбирать их при помощи локальных особенностей.

Что если взять за основу одну из самых простых операций — сравнение, которое выдает нам 0 или 1 в зависимости от выполненности условия?
Сформулируем так:
 — собственно, наш примитивный тест (например, будем сравнивать яркость двух пикселей, хотя принципиального значения это не имеет — во многом выбор условия определяется решаемой задачей);
— собственно, наш примитивный тест (например, будем сравнивать яркость двух пикселей, хотя принципиального значения это не имеет — во многом выбор условия определяется решаемой задачей);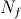 — число тестов в классификаторе;
— число тестов в классификаторе;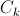 — индекс определенного класса изображений.
— индекс определенного класса изображений.
С таким взглядом на вещи нашу задачу можно описать так:
для заданных
 выбрать такой класс
выбрать такой класс  , что
, что . Так же учтем, что вероятность выбора определенного класса равномерно распределена.
. Так же учтем, что вероятность выбора определенного класса равномерно распределена.Работать с кучей условий как-то неочень удобно. Поэтому объединим их в небольшие группы, которые назовем fern'ами (таки да, папоротники). Причем результаты работы одного fern'а никак не влияет на работу других. Запишем это все формально:
 — собственно, fern. Представляет собой набор условий, или, в виде формулы,
— собственно, fern. Представляет собой набор условий, или, в виде формулы, 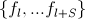 ;
;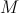 — число fern'ов, да такое, что
— число fern'ов, да такое, что 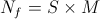
Важно отметить, что число fern'ов и тестов несет в себе любопытное свойство — фактически, оно определяет тип классификатора:
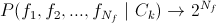 — так называемый оптимальный классификатор. Неприменим из-за огромного числа тестов;
— так называемый оптимальный классификатор. Неприменим из-за огромного числа тестов; — по сути, наивный байесовкий классификатор (тык). Неплохое решение, но не учитывает связей между параметрами, что бывает весьма важным;
— по сути, наивный байесовкий классификатор (тык). Неплохое решение, но не учитывает связей между параметрами, что бывает весьма важным;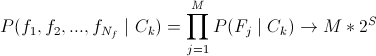 — как Вы догадались, выбор редакции. Semi-naive (полунаивный? В отечественной литературе ничего похожего не увидел, кто знает — подскажите) байесовский классификатор. Как раз учитывает связи между параметрами, что и делает его весьма интересным в рамках поставленной задачи.
— как Вы догадались, выбор редакции. Semi-naive (полунаивный? В отечественной литературе ничего похожего не увидел, кто знает — подскажите) байесовский классификатор. Как раз учитывает связи между параметрами, что и делает его весьма интересным в рамках поставленной задачи.
Практика
Фух, математику осилили, перейдем к самому интересному — картинкам!
Что у нас есть на данный момент:
- Простейший тест на сравнение яркостей 2 пикселей, возвращающий 0 и 1 по результатам проверки
- Набор таких тестов fern. Когда пройдут все проверки, получим двоичное число (10100011101...)
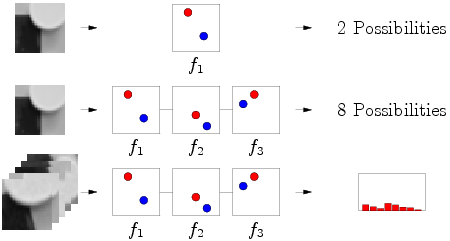 Очевидно, что для 1 тест для 1 картинки даст 2 варинта — 0 или 1. Но это неточно, да и классов может быть много. Тогда, множество тестов (fern) выдаст нам набор нулей и единиц (в диапозоне от 0 до
Очевидно, что для 1 тест для 1 картинки даст 2 варинта — 0 или 1. Но это неточно, да и классов может быть много. Тогда, множество тестов (fern) выдаст нам набор нулей и единиц (в диапозоне от 0 до 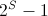 ). Если же у нас много разных картинок, относящихся к одному классу — мы получим распределение вероятностей. Да, важная деталь — проверка может быть абсолютно любой, но! Мы должны раз и навсегда, для всех изображений и fern'ов выбрать один вариант теста, например, всегда и всюду синий пиксель должен быть ярче красного. Если хотим наоборот — пожалуйста, но тогда наоборот должно быть везде.
). Если же у нас много разных картинок, относящихся к одному классу — мы получим распределение вероятностей. Да, важная деталь — проверка может быть абсолютно любой, но! Мы должны раз и навсегда, для всех изображений и fern'ов выбрать один вариант теста, например, всегда и всюду синий пиксель должен быть ярче красного. Если хотим наоборот — пожалуйста, но тогда наоборот должно быть везде.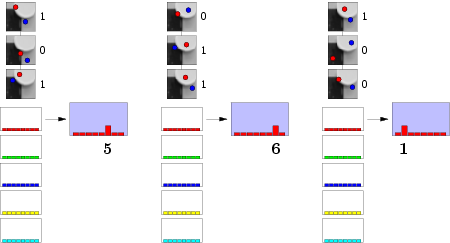 Возьмем простую ситуацию — у нас 3 теста, 3 fern'а и, например, 5 классов картинок. На стадии обучения мы скармливаем 1 образец 1 класса fern'ам и они проводят серию проверок на яркость пикселей. В результате каждый fern формирует двоичное число, в данном случае 101, 011, 100 (для ленивых — в десятичной системе исчисления 5, 6 и 1, сответственно). Данные номера позволяют нам инкрементировать соответствующий столбец в распределении. Да, кстати, чтобы никому не было обидно, инициализируем его как равномерное распределение вероятности Дирихле (тык).
Возьмем простую ситуацию — у нас 3 теста, 3 fern'а и, например, 5 классов картинок. На стадии обучения мы скармливаем 1 образец 1 класса fern'ам и они проводят серию проверок на яркость пикселей. В результате каждый fern формирует двоичное число, в данном случае 101, 011, 100 (для ленивых — в десятичной системе исчисления 5, 6 и 1, сответственно). Данные номера позволяют нам инкрементировать соответствующий столбец в распределении. Да, кстати, чтобы никому не было обидно, инициализируем его как равномерное распределение вероятности Дирихле (тык).Продолжаем в том же духе для всех классов:
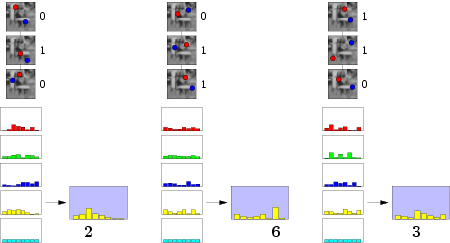
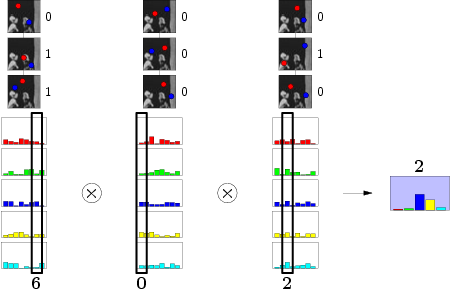
После того, как все классы будут успешно освоены, можно приступать к распознаванию. Подаем на вход любое изображение, fern'ы исправно формируют бинарный номер столбца. На этом этапе значения столбцов лучше нормализовать, а то какой-нибудь fern может все одеяло на себя утянуть. Так как где-то в начале мы постулировали независимость результатов, мы смело можем перемножить значения столбцов. И, что самое любопытное, столбец результата с наибольшим значением укажет наиболее вероятный класс. Что нам и нужно было, ведь так?:)
Результаты
Мы добились желаемого — получили быстрый и крайне простой классификатор. Основным его достоинством является скорость работы достаточно высокое качество распознавания. Независимость результатов также приводит нас к идее паралелльной обработки (по fern'у на ядро и вперед!). Минусом же является необходимость в большой обучающей выборке (очень уж мало информации используется при обучении, приходится компенсировать). Так же стоит отметить некоторое ограничение на сами fern'ы — желательно, чтобы они были небольшими, пусть лучше их будет больше.
Копирайты
- Все изображения взяты из работ V. Lepetit
- Формулы построены в онлайн интерпретаре Latex
Чтиво на ночь
- Fast Keypoint Recognition using Random Ferns M. Özuysal, M. Calonder, V. Lepetit, P. Fua
- Fast Keypoint Recognition in Ten Lines of Code M. Özuysal, P. Fua, V. Lepetit
- Полная версия вышеприведенного материала на английском
