
Мне понадобилось для своих сайтов запускать еженедельную проверку битых и несуществующих ссылок. Потратив пол часа на интернет-серфинг, я нашел несколько достойных консольных приложений (так как сервера у меня на Windows, то хотел использовать для этой задачи TaskSheduler). Все они оказались платные. А так как я мог выделить себе немного свободного времени, и задача на первый взгляд показалась не сложной, решил написать свое.
Отталкиваться решил вот от этой реализации: WebSpider, но, как оно обычно бывает в конечном итоге, почти все переписал, как мне нравится.
Составил себе небольшой список, того, что мне требуется и понемногу вычеркиваю из него таски:
| Задача | Описание | Статус |
| Рекурсивно собрать все ссылки | Пробежаться по всем страницам в рамках одного сайта и собрать все ссылки | Сделано |
| Проверить N ссылок | В основном для отладочных целей, остановиться после проверки N ссылок | Сделано |
| Сохранить результат в файл | Сохранение в TXT | Сделано |
| Сохранить результат используя html template | Для удобства чтения + прикрутить плагин jquery data table для фильтрации и сортировки | Сделано |
| Показывать только ошибки | В файл репорте показывать только битые ссылки | Сделано |
| Опция архивирования файла репорта | Добавить поддержку 7zip | Не сделано |
| Посылать результат по почте | Добавить поддержку консольного мейлера | Не сделано |
| Показывать в репорте редиректы | Правильно обрабатывать все редиректы и выводить информацию о них в репорте | Не сделано |
| Добавить логирование | Добавить библиотек Log4Net | Не сделано |
| Общая информация о процессе в html темплейте | Показывать когда начался процесс обработки, когда закончился, и другую общую информацию в html темплейте | Не сделано |
| Проверить и настроить правильную обработку редиректов | Не сделано | |
| app.config конфигурация по умолчанию | Так как стало слишком много параметров для утилиты, решил, что надо сделать конфигурацию по умолчанию из app.config | Не сделано |
Программа простая до безобразия:
1. На вход подается URI, для которого скачивается контент и в контенте ищутся ссылки при помощи регулярного выражения:
public const string UrlExtractor = @"(?: href\s*=)(?:[\s""']*)(?!#|mailto|location.|javascript|.*css|.*this\.)(?<url>.*?)(?:[\s>""'])";2. Все найденные ссылки, если они относятся к данному сайту, помещаются в хештейбл, где ключ — это абсолютное URI, чтобы не было дублирования.
3. Для каждой ссылки из таблицы хешей мы создаем Request и пытаемся получить Response, и читаем возвращаемый статус:
public bool Process(WebPageState state)
{
state.ProcessSuccessfull = false;
HttpWebRequest request = (HttpWebRequest) WebRequest.Create(state.Uri);
request.Method = "GET";
WebResponse response = null;
try
{
response = request.GetResponse();
if (response is HttpWebResponse)
state.StatusCode = ((HttpWebResponse) response).StatusCode;
else if (response is FileWebResponse)
state.StatusCode = HttpStatusCode.OK;
if (state.StatusCode.Equals(HttpStatusCode.OK))
{
var sr = new StreamReader(response.GetResponseStream());
state.Content = sr.ReadToEnd();
if (ContentHandler != null)
ContentHandler(state);
state.ProcessSuccessfull = true;
}
}
catch (Exception ex)
{
// обработка ошибок todo: сделать отдельные catch блоки
}
finally
{
if (response != null)
{
response.Close();
}
}
return state.ProcessSuccessfull;
}
Все остальное это красивости и энтропия.
Из интересного: использовал для удобного парсинга консольных параметров вот этот пакет https://nuget.org/packages/ManyConsole.
В итоге для обработки параметра, все что от меня требуется это создать вот такой вот класс:
public class GetTime : ConsoleCommand
{
public GetTime()
{
Command = "get-text";
OneLineDescription = "Returns the current system time.";
}
public override int Run()
{
Console.WriteLine(DateTime.UtcNow);
return 0;
}
}
P.S. И В заключении, так как проект пишу для себя и все еще в процессе, то добавил его на github https://github.com/alexsuslin/LinkInspector
Ах, да… кому все-таки интерсно визуально посмотреть что получается в итоге, вот это в консоле:
D:\WORK\Projects\Own\LinkInspector\LinkInspector\bin\Debug>LinkInspector.exe -u www.google.com -n=10 -ff=html -e
Executing -u (Specify the Url to inspect for broken links.):
======================================================================================================
Proccess URI: www.google.com
Start At : 2011-12-21 04:56:09
------------------------------------------------------------------------------------------------------
0/1 : [ 2.98s] [200] : www.google.com
1/7 : [ 0.47s] [200] : accounts.google.com/ServiceLogin?hl=be&continue=http://www.google.by/
2/6 : [ 0.22s] [200] : www.google.com/preferences?hl=be
3/5 : [ 0.27s] [200] : www.google.com/advanced_search?hl=be
4/7 : [ 0.55s] [200] : www.google.com/language_tools?hl=be
5/341 : [ 0.21s] [200] : www.google.by/setprefs?sig=0_OmYw86q6Bd9tjRx1su-C4ZbrJUU=&hl=ru
6/340 : [ 0.09s] [200] : www.google.com/intl/be/about.html
7/361 : [ 0.30s] [200] : www.google.com/ncr
8/361 : [ 0.21s] [200] : accounts.google.com/ServiceLogin?hl=be&continue=http://www.google.com/advanced_search?hl=be
9/360 : [ 0.13s] [200] : www.google.com/webhp?hl=be
------------------------------------------------------------------------------------------------------
Pages Processed: 10
Pages Pending : 0
End At : 2011-12-21 04:56:14
Elasped Time : 0h 0m 5s 456ms
======================================================================================================
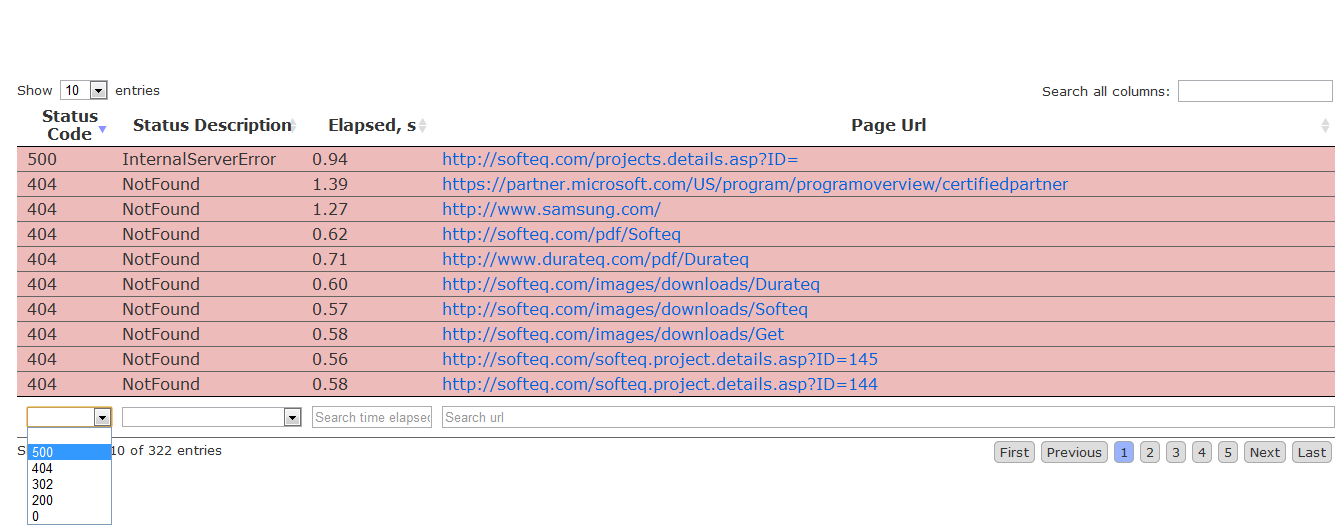
или вот это вот скриншот репорта в html темплейте
P.P.S. Попросили скомпилированные бинарники, вот пожалуйста: скачать Link Inspector 0.1 alpha
