Введение
Здравствуй, уважаемый хабраюзер.Я хотел бы тебе представить материал о практическом создании компилятора, который будет транслировать код, написанный на языке Cool, в код виртуальной машины CIL (Common Intermediate Language) под платформу .NET.Данный материал я решил разбить на две части
В первой части будет описан процесс написания грамматики с учетом приоритетов операторов в среде ANTLR, а также генерации лексера и парсера под язык C#. Также в ней будут рассмотрены подводные камни, которые встретились у меня на пути. Таким образом я постараюсь хоть кому-нибудь сэкономить время (может быть для себя в будущем).
Во второй же части будет описан процесс построения семантического анализатора кода, генерации кода и самопальной
Предупреждение: перед разработкой данного компилятора я практически не изучал никакой тематической литературы. Всё обошлось чтением нескольких интересующих меня статей, просмотром видеоуроков по ANTLR на официально сайте и разговорами с «шарящими» одногруппниками. Так что разработанное ПО является
Чтобы читатель лучше понимал меня, я дам в начале сначала некоторые определения (из Википедии):
- Токен — последовательности символов в лексическом анализе в информатике, соответствующий лексеме.
- Лексер — модуль для аналитического разбора входной последовательности символов (например, такой как исходный код на одном из языков программирования) с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в слова).
- Парсер — модуль для сопоставления линейной последовательности лексем (слов, токенов) языка с его формальной грамматикой. Результатом является дерево разбора или синтаксическое дерево.
Итак, для разработки компилятора были использованы следующие программы и библиотеки:
- ANTLRWorks — IDE для написания грамматик и генерации кода лексеров и парсеров под различные языки (C, C#, Java, JavaScript, Objective-C, Perl, Python, Ruby и др.). Основана на LL(*) парсинге.
- ANTLR C# runtime distribution (Antlr3.Runtime.dll) используется в сгенерированном лексере и парсере.
- Visual Studio 2010 В следующей статье будет рассмотрен компонент под WPF, расширенный текстовый редактор для подсветки синтаксиса и автодополнения кода AvalonEdit).
- Java Runtime Environment (так как ANTLRWorks написана на Java).
- IL Disassembler будет использоваться во второй части для того, чтобы понимать, как компилятор, например языка C#, генерирует CIL код и как он должен выглядеть.
Описание языка Cool
Cool — Classroom Object-Oriented Language является, как мы видим из названия, учебным
Все поля являются видимыми внутри базового и производного классов. Все функции являются видимыми отовсюду (public).
Данный язык построен на выражениях (expression). Все функции в качестве аргументов могут принимать выражения и телами всех функций являются выражения, который возвращают какой-либо результат. Даже такие функции, как вывод строки, возвращают результат, а именно экземпляр класса, из которого они вызваны.
Cool содержит также и статические классы String, Int, Bool, от которых нельзя наследоваться и которые не могут принимать значения null (здесь это называется void). Объекты данных классов передаются по значению, а не по ссылке.
Ключевые слова данного языка: class, else, false, fi, if, in, inherits, isvoid, let, loop, pool, then, while,case, esac, new, of, not, true
Хочу обратить внимание, что некоторые операторы заканчивается не фигурной скобкой (как в С-подобных) или словом end; (как в
Как вы думаете, если каждый оператор возвращает какой-то результат, то что же должен возвращать if? Ведь он может возвратить вариант из двух альтернатив. Правильный ответ: наиболее близкий общий предок (в учебнике написано про это как-то сложно, там еще специальный оператор используется). Привожу для наглядности картинку:
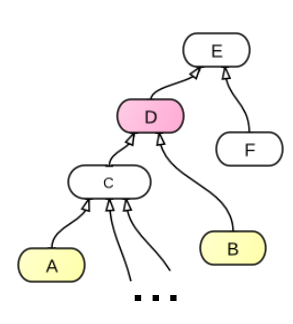
Рисунок 1.
Здесь у классов A и B наиболее близким общим предком является класс D.
Оператор case подобен оператору if, примененному несколько раз.
В конструкции while всегда возвращается void (если конечно цикл не зацикливается).
Такая конструкция { <expr1>;… <exprn>; } возвращает объект выражения exprn, т.е. последнего выражения.
Функции здесь могут вызываться не только у класса и его предка (виртуальные функции), но и вообще у любых предков данного класса. Это можно осуществить, использовав оператор '@'. В качестве примера рассмотрим иерархию классов на рисунке 1. Пусть класс E имеет функцию func(), все остальные потомки переопределяют ее по своему. Тогда, если мы имеет экземпляр объекта A и хотим вызывать функцию func из класса D, нужно использовать следующий синтаксис:
result <- (new A)@D.func()Ключевое слово SELF_TYPE используется как синоним класса, в котором описывается определенная функция. Идентификатор self же является указатель на текущий класс (т.е. this в других языка).
Локальных переменные вводятся в языке Cool с помощью оператора let и они могут использоваться только в рамках данного блока let.
void — аналог null, признак того, что объект не создан.
Думаю все остальные операторы в пояснениях не нуждаются, а если не понятно, то вы можете изучить мануал по данному диалекту языка Cool по ссылке, указанной в конце статьи.
Написание грамматики языка Cool в ANTLRWorks
Итак, исходная грамматика задана в следующей форме:
program ::= [[class; ]]+
class ::= class TYPE [inherits TYPE] { [[feature; ]]*}
feature ::= ID( [ formal [[, formal]]*] ) : TYPE { expr } | ID : TYPE [ <- expr ]
formal ::= ID : TYPE
expr ::=
ID <- expr
| expr[@TYPE].ID( [ expr [[, expr]]*] )
| ID( [ expr [[, expr]]*] )
| if expr then expr else expr fi
| while expr loop expr pool
| { [[expr; ]] +}
| let ID : TYPE [ <- expr ] [[, ID : TYPE [ <- expr ]]]* in expr
| case expr of [[ID : TYPE => expr; ]]+ esac
| new TYPE
| isvoid expr
| expr + expr
| expr ? expr
| expr ? expr
| expr / expr
| ~expr
| expr < expr
| expr <= expr
| expr = expr
| not expr
| (expr)
| ID
| integer
| string
| true
| falseОбозначения:[[]]* — итерация; [[]]+ — положительная итерация;Итак, что нужно сделать, увидев такую грамматику?
- Существование левой рекурсии. Конечно, ANTLRWorks, основанная на методе рекурсивного спуска, это сразу определит и выдаст ошибку такого рода:[fatal] rule compilation_unit has non-LL(*) decision due to recursive rule invocations reachable from alts… Resolve by left-factoring or using syntactic predicates or using backtrack=true option… И, конечно же, в ANTLR есть опция backtrack=true, которая позволяет преодолеть данное ограничение. Но применив ее, придется смириться с еще одним узлом в сгенерированном КА для выражения с левой рекурсией. Так что все-таки хорошо бы от нее избавиться. К тому же, как видно из этой статьи, данная опция замедляет работу парсера и автор рекомендует по возможности отказываться от нее.
- Но главное, что в этой форме грамматики не учтен приоритет операторов. Если левая рекурсия влияет только на эффективность парсера, то игнорирование данной проблемы приведет к неправильной генерации кода уже потом (например 2 + 2 * 2 будет равно 8, а не 6)
- .
- @
- ~
- isvoid
- * /
- + -
- <= < =
- not
- <-
expr:
(ID ASSIGN^)* not;
not:
(NOT^)* relation;
relation:
addition ((LE^ | LT^ | GE^ | GT^ | EQUAL^) addition)*;
addition:
multiplication ((PLUS^ | MINUS^) multiplication)*;
multiplication:
isvoid ((MULT^ | DIV^) isvoid)*;
isvoid:
(ISVOID^)* neg;
neg:
(NEG^)* dot;
dot:
term ((ATSIGN typeName)? DOT ID LPAREN invokeExprs? RPAREN)? ->
^(Term term ID? typeName? invokeExprs?);
Терм в данном случае включает в себя все оставшиеся выражения, которые не были рассмотрены, т.е. выражения с одинаковым приоритетом.
Комментарии в языке по сути являются последовательностью символов, которую нужно проигнорировать при лексическом разборе. Для этого в ANTLR используется конструкция
{$channel = Hidden;};COMMENT : '--' .* ('\n'|'\r') {$channel = Hidden;};Операторы ANTLR
Далее я опишу используемые операторы ANTLR:
- ! — нужен для того, чтобы лишние токены языка не мешали при разборе. Например, скобки и другие операторы, которые нужны только для парсера (например те же окончания синтаксических конструкций fi, esac). Данные оператор нужен для того, чтобы строилось именно синтаксическое дерево из потока токенов, а не дерева разбора).
- -> — нужен для того, чтобы преобразовывать последовательность токенов, стоящих в левой части, в последовательность токенов, стоящих в правой части, которую было бы удобно обрабатывать при генерации кода.Вместе с этим оператором используется также и оператор ^.
- ^ используется для того, чтобы в генерируемом синтаксическом дереве создавался новый узел из токена, помеченного этим оператором, и его потомков. Существует две формы у этого оператора:
- Постфиксная. Например для такого правила:
в синтаксическое дерево вставится узел с одним из операторов, указанных в скобках, и детьми addition, который слева от оператора и addition, который справа от оператора.relation: addition ((LE^ | LT^ | GE^ | GT^ | EQUAL^) addition)*; - Префиксная. Например для такого правила:
в синтаксическое дерево вставится узел-родитель Class с потомками typeName featureList typeName?CLASS typeName (INHERITS typeName)? LCURLY featureList RCURLY -> ^(Class typeName featureList typeName?)
- Постфиксная. Например для такого правила:
Все остальные используемые операторы ANTLR в комментариях не нуждаются (для человека, изучавшего дискретную математику), а если и нуждаются, то в небольших:
- * — Итерация.
- + — Положительная итерация.
- ? — Левостоящий токен или группа токенов может как присутствовать, так и отсутствовать.
STRING: '"'
{ StringBuilder b = new StringBuilder(); }
( '"' '"' { b.Append('"');}
| c=~('"'|'\r'|'\n') { b.Append((char)c);}
)*
'"'
{ Text = b.ToString(); }
;
Здесь используется StringBuilder для того, чтобы обработка строк была эффективной.В принципе, для оптимизации лексера допустимы и другие вкрапления такого кода, но не для всех правил.Для того, чтобы в C# коде лексера и парсера указать пространства имен (например System.Text для StringBuilder), используются следующие конструкции (здесь также отключаются некоторые «ненужные» предупреждения):
@lexer::header {#pragma warning disable 3021
using System;
using System.Text;
}
@parser::header {#pragma warning disable 3021
using System.Text;}
После того, как мы составили грамматику в ANTLRWorks, нужно сгенерировать C# код лексера и парсера (спасибо, кэп).
ANTLRWorks с заданными настройками генерирует 3 файла:
- CoolGrammar.tokens
- CoolGrammarLexer.cs
- CoolGrammarParser.cs
Использование сгенерированного лексера в C# коде
Получение списка всех токенов в сгенерированном C# коде выглядит не очень тривиально (хоть это и не всегда нужно):
var stream = new ANTLRStringStream(Source); // Source - исходный код.
lexer = new CoolGrammarLexer(stream, new RecognizerSharedState() { errorRecovery = true });
IToken token;
token = lexer.NextToken();
while (token.Type != CoolGrammarLexer.EOF)
{
// Здесь обрабатываем каждый токен.
// Имя токена: CoolTokens.Dictionary[token.Type] (Например для '(' это LPAREN,
// используется дополнительный заранее подготовленный словарь, сопоставляющий имя токена и его значение)
// Текст токена: token.Text (Например для '(' это просто "(")
// Номер линии токена в коде: token.Line
// Позиция токена в коде от начала строки: token.Column
token = lexer.NextToken(); // Читаем следующий токен, то тех пор, пока не дойдем до конца файла.
}
// Далее перегружаем поток токенов и устанавливаем позицию в коде в 0,
// чтобы использовать этот же поток токенов потом (читай в парсере).
lexer.Reset();
CoolTokens.Dictionary должен генерироваться следующим образом:
var Lines = File.ReadAllLines(fileName);
Dictionary = new Dictionary<int, string>(Lines.Length);
foreach (var line in Lines)
{
var parts = line.Split('=');
if (!Dictionary.ContainsKey(int.Parse(parts[1])))
Dictionary.Add(int.Parse(parts[1]), parts[0]);
}Использование сгенерированного парсера в C# коде
var tokenStream = new CommonTokenStream(lexer); // как получить lexer, было описано ранее.
parser = new CoolGrammarParser(tokenStream);
Tree = parser.program(); // Самый верхний узел, отвечающий за аксиому грамматики (т.е. program в нашем случае).- treeNode.ChildCount — количество детей у узла treeNode
- treeNode.GetChild(i) — получение ребенка у узла treeNode под номером i
- treeNode.Type — токен данного узла. Имеет тип int и должен сравниваться с константами, объявленными в классе лексера. Например:treeNode.Type == CoolGrammarLexer.EQUAL (является ли данный токен знаком '=').Хочу обратить внимание, что при обходе дерева нужно использовать именно свойство Type, а не Text, поскольку сранивание чисел быстрее, чем сравнивание строк, к тому же вероятность ошибки уменьшается, поскольку все константы генерируются автоматически.
- treeNode.Line — номер линии токена в коде
- treeNode.CharPositionInLine — позиция токена в коде от начала строки
Заключение
В этой статье было рассказано, как описать грамматику в среде ANTLRWorks, которая затем используется для генерации кода лексеров и парсеров на языке C#, а также как использовать лексер и парсер. В следующей статье будет рассказано про обработку семантики языка (т.е. проверке типов, обработке семантических ошибок), как обходить каждый узел синтаксического дерева и генерировать CIL код для соответствующей синтаксической конструкции с объяснением CIL инструкций, объяснением работы стека виртуальной машины и использование встроенной в .NET библиотеки System.Reflection.Emit для облегчении генерации кода. Разумеется, я опишу и подводные камни, которые встретились у меня на пути (В частности, создание иерархии классов с помощью System.Reflection.Emit). Также там будет описано, как сделать
Напоследок я бы хотел задать один вопрос хабрасообществу, ответ на который мне найти не удалось:
Для C# лексера у меня всегда генерируется такой код для исключения NoViableAltException, причем этот throw невозможно никак перехватить:
catch (NoViableAltException nvae) {
DebugRecognitionException(nvae);
throw;
}Было бы приятно, если кто-нибудь разобрался с этой проблемой и написал ответ в комментариях.
Рекомендуемая к прочтению литература
- Definite ANTLR Reference, Terence Parr, 2007.
- Компиляторы. Принципы, технологии и инструментарий, 2008, Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман
