Эта статья нацелена на читателей, которые начинают или только хотят начать заниматься программированием модулей ядра Linux и сетевых приложений. А также может помочь разобраться с прозрачным проксированием HTTPS трафика.
Небольшое оглавление, чтобы Вы могли оценить, стоит ли читать дальше:
P.S. Для тех, кому только хочется посмотреть на прозрачный прокси-сервер для HTTP и HTTPS, достаточно настроить прозрачный прокси-сервер для HTTP, например, Squid с transparent портом 3128, и скачать архив с исходниками Shifter. Скомпилировать (make) и, после удачной компиляции, выполнить ./Start с правами root. При необходимости можно поправить настройки в shifter.h до компиляции.
Как и все начинающие в области IT захотелось покопаться немножко в ядре. Тут и область для экспериментов появилась сама собой. Если заглянуть в гугл, то можно заметить, что, если с прозрачным прокси-сервером для HTTP проблем ни у кого не возникает, то в случае с HTTPS некоторые уверены в том, что прозрачного прокси для протокола HTTPS нет. И его никогда не будет. Все это и послужило появлению этой статьи.
Для начала рассмотрим некоторые аспекты работы прокси-сервера, которые нам понадобятся. Когда браузер напрямую обращается к HTTP серверу, то он создает следующий типовой запрос:
Когда в настройках браузера указываем прокси сервер, то браузер начинает соединяться с прокси-сервером, и отсылает ему запрос с полным адресом:
Если прокси сервер получит запрос с неполным адресом, как в первом случае, то он может не знать, кому предназначен этот запрос и возвратит ошибку.
Скажу в двух словах про HTTPS. Браузер устанавливает tcp соединение и, используя протокол SSL: обменивается сертификатами и передает зашифрованный трафик HTTP. Так как протокол SSL как раз направлен на то, чтобы никто не смог посередине прочитать передаваемые данные, то прокси-сервер не может, как в случае HTTP, выяснить с кем следует установить соединение. Для передачи данных по HTTPS через прокси-сервер браузер должен сообщить прокси-серверу с кем он хочет соединиться, используя HTTP метод CONNECT:
На что прокси-сервер должен ответить, что соединение успешно установлено:
В результате браузер получает как бы прямое tcp соединение через прокси-сервер, в котором он может передавать абсолютно любые данные. А прокси-сервер занимается только точной перекладкой данных из tcp соединения, установленного с браузером, в tcp соединение, установленное с указанным хостом в методе CONNECT, и, соответственно, обратной перекладкой.
Когда используется прозрачное проксирование, т.е. браузер даже не подозревает о существование прокси-сервера, то соответственно браузер и не будет так красиво подготавливать свои данные. И прокси-серверу придется самому подумать об этом.
Схематично взглянем на прозрачный прокси для HTTP:

Здесь конечно есть неточности, например, прокси, получая пакет на свой порт 3128, не передает его дальше гуглу, а создает новое соединение с гуглом, но, в общем, схема взаимодействий примерно такова. В данной схеме видно, что NAT начинает направлять пакеты прокси-серверу, которые предназначены не для него, и ему требуется узнать кому их все-таки отсылать. В случае с HTTP трафиком некоторые прокси-сервера неправомерно начинают пользоваться информацией из поля HOST заголовка HTTP запроса, нарушая спецификацию. Чаще всего конечно в HOST содержится именно то имя хоста, которому и адресован запрос, но, в общем случае, HOST может содержать что угодно. Для HTTPS такое решение и вовсе не подходит. Чтобы узнать, кому адресован пакет, сразу напрашивается решение, в котором прокси-сервер заглянул бы в NAT и посмотрел, кому все-таки были предназначены данные и тогда проблем бы ни каких не было. Вот собственно, чем и займемся.
В сам iptables, к сожалению, не полезем, но все равно будут хорошо понятны основные принципы его работы. Схематично это будет выглядеть следующим образом:
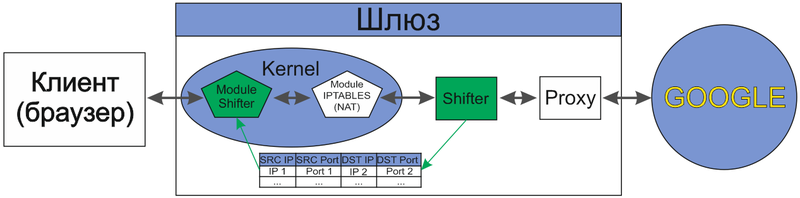
Для намеченных целей, будет достаточно написать крохотный модуль ядра (Module Shifter) и реализовать небольшую программную прослойку (Shifter) в пользовательском пространстве для взаимодействия с нашим модулем, которая и будет подготавливать данные для прокси-сервера.
Напишем маленькое клиент-серверное приложение, которое я назвал Shifter. Shifter будет висеть на своем порту и, когда кто-нибудь установит tcp соединение с ним, то он создаст tcp соединение с прокси-сервером и пошлет ему метод CONNECT (HTTP), а далее будет заниматься только точной передачей данных между этими двумя соединениями. В случае если клиент или прокси закроет соединение с ним, то он закроет эту пару сокетов.
Для отправки метода CONNECT нужен ip адрес удаленного узла, с которым на самом деле хотел установить соединение клиент. Чтобы получить эту информацию Shifter будет связываться с модулем ядра (Module Shifter) используя библиотеку Netlink. Об этом будет рассказано в последней части этой статьи.
Данным приложением мы подготовим прокси-сервер к приему данных (HTTPS) от клиента, который ничего не знает о прокси-сервере. Так как имеется много ресурсов, где подробно написано про сокеты, здесь лишь приведу ссылку на часть исходного кода Shifter'а с подробными комментариями.
Для того чтобы узнать, что такое модуль ядра можно прочитать, например, Работаем с модулями ядра в Linux. Приступим к написанию модуля. Для начала нужно выполнить инициализацию модуля, которая будет происходить один раз, когда модуль будет подгружаться в ядро. А также следует выполнить корректное завершение работы модуля, чтобы не оставлять всякие ненужные следы прошлого присутствия, когда модуль выгрузят из ядра. Для этих целей в библиотеке <linux/module.h>:<linux/init.h> есть два макроса module_init и module_exit, которые в качестве параметра принимают имя функции для этих целей. Также имеются макросы MODULE_AUTHOR, MODULE_DESCRIPTION, MODULE_LICENSE, чтобы увековечить свое имя :) Еще есть очень полезная функция вывода int printk(const char *fmt, ...) в библиотеке <linux\kernel.h>:<linux\printk.h>. Она мало чем отличается от обычного printf(..). Так как модуль находится в ядре, а не запущен в консоли, то сообщения соответственно выводятся в логи (для просмотра можно использовать команду dmesg). Сообщения можно выводить различных типов:
Теперь у нас имеется вся информация, чтобы написать каркас своего первого модуля:
Расскажу еще немного о том, как это все скомпилировать и запустить. Скажу сразу, что у меня установлена Ubuntu 11.10 (x86) Kernel 3.0.
В системе имеется каталог /lib/modules/[версия ядра]/ в нем находятся модули для соответствующей версии ядра. Также там имеется build – это символическая ссылка на заголовки библиотек ядра (kernel-headers), которые находятся в каталоге /usr/src/linux-headers-[версия ядра]/. Если у вас еще нет kernel-headers, то их нужно скачать (sudo apt-get install linux-headers-[версия ядра]). Чтобы узнать версию текущего ядра, в котором Вы работаете, можно выполнить команду uname –r. Если будете использовать библиотеку с версией отличной от версии текущего ядра, то такой скомпилированный модуль может замечательно работать, а может в лучшем случае не запуститься. Это все зависит от того, какие произошли изменения в ядре, и какие Вы используете в модуле функции.
Для компиляции модуля напишем Makefile. Создадим две цели: all (сборка модуля) и clean (очистка проекта), для их написания воспользуемся уже написанными для нас целями: modules и clean в Makefile из kernel-headers.
Теперь можем легко скомпилировать модуль с помощью команды make и очистить проект make clean. В результате получим готовый модуль module_test.ko, который можно сразу загрузить в ядро, используя команду insmod ./module_test.ko. Есть еще один вариант загрузки модуля в ядро — командой modprobe module_test. Для этого нужно положить модуль module_test.ko в каталог /lib/modules/[текущая версия ядра]/[любой каталог]/ и не забыть выполнить depmod, т.к. эта команда создает список зависимостей модулей в /lib/modules/. Даже если у модуля нет зависимостей, modprobe не увидит добавленный модуль без depmod. Основные различия между insmod и modprobe в следующем: modprobe при загрузке модуля автоматически загружает все модули, от которых он зависит, зато insmod может подгружать модуль из любого каталога. Удалить модуль из ядра: rmmod module_test. Посмотреть информацию о модуле: modinfo module_test или modinfo ./module_test.ko.
И так вернемся к прокси для HTTPS. Наша задача — сделать так, чтобы модуль просматривал сетевые пакеты до того, как их обработает DNAT (iptables). Для этого нам поможет библиотека Netfilter. (Для более детального понимания рекомендую дополнительно прочитать о Netfilter в других источниках, хотя бы в Википедии) Рассмотрим, как выглядит путь сетевого пакета в ядре:

Более подробно можно посмотреть вот здесь.
Netfilter <linux/netfilter.h> предоставляет 5 hook функций, которые дают доступ к сетевому пакету в 5 различных местах:
Модуль ядра может зарегистрировать свою функцию в любом из этих 5 мест. При регистрации модуль должен указать приоритет своей функции в этом месте. В библиотеке <linux/netfilter_ipv4.h> можно найти приоритет для различных стандартных задач:
Из списка видно, что DNAT имеет приоритет -100, поэтому для нашей цели подойдет любой приоритет < -100. Если же приоритет у функции будет > -100, то она будет получать пакеты с уже измененным IP адресом назначения (получателя).
Каждая зарегистрированная функция в любой из 5 точек должна возвращать одно из следующих значений, которое определяет дальнейшую судьбу переданного ей пакета:
В моем вольном переводе это будет звучать так:В данном случае под итерацией понимается переход пакета от функции к функции, т.к. в одной точке может быть зарегистрировано много функций, которые в свою очередь могут быть разделены по приоритетам.
С теорией разобрались, теперь продолжим писать модуль. При загрузке модуля в ядро нужно зарегистрировать функцию, назовем ее Hook_Func, которая будет просматривать все входящие пакеты, а при завершении эту функцию надо разрегистрировать, иначе ядро будет пытаться вызывать несуществующую функцию.
Теперь все что нам осталось — это написать саму функцию Hook_Func. Она должна иметь следующий прототип:
Рассмотрим ее параметры:
Теперь подробнее об указателе на пакет struct sk_buff *skb.
При работе с tcp можно воспользоваться еще двумя структурами — это struct iphdr и struct tcphdr.
Как видно из названия, эти структуры предназначены для работы с IP заголовком и, соответственно, с TCP заголовком. Чтобы получить указатели на эти структуры из skb_buff можно воспользоваться двумя функциями:
В этом месте я хотел бы обратиться к читателю. Мне осталось не совсем понятным, кто именно должен устанавливать указатель transport_header в структуре sk_buff, т.к. в точках NF_INET_PRE_ROUTING и NF_INET_LOCAL_IN (с любыми приоритетами) мне не удалось с помощью skb_transport_header получить структуру на tcp заголовок, хотя в остальных точках это работало прекрасно. Пришлось вручную указывать смещение для transport_header от указателя sk_buff->data, воспользовавшись void skb_set_transport_header(skb, offset).
Упомянутый указатель sk_buff->data — это указатель на содержимое пакета, т.е. указывает на область памяти после Ethernet протокола, например, сразу на структуру IP заголовка, а после нее может следовать структура TCP заголовка или Ваш собственный протокол.
Так как везде используются указатели на данные в самом пакете, то можно не только читать различные поля, но и изменять их. Однако нужно помнить, что при изменении, например, IP адреса отправителя или получателя следует еще пересчитать контрольную сумму в заголовке IP пакета.
И так, наша функция будет сохранять IP адрес назначения только тогда, когда она увидит IP-TCP пакет, идущий на порт 443 (HTTPS) и содержащий флаг SYN, который говорит, что клиент хочет установить TCP соединение для протокола HTTPS. И удалять, когда появляются пакеты содержащие флаги FIN или RST, которые сообщают что tcp соединение разорвано и больше этот IP адрес нам не нужен.
Здесь есть две функции AddTable и DelTable, которые должны сохранять и удалять IP адрес получателя из памяти, для каждого IP и порта отправителя. Это нужно для того, чтобы клиент-сервер Shifter смог связаться с модулем Shifter и воспользовавшись функцией ReadTable, узнать по IP и порту клиента с каким IP адресом на самом деле хотел он связаться. Я не стал сильно раздумывать над типом данных для сохранения IP и воспользовался обычным статическим массивом с использованием элементарной хэш-функции. Хэш-функция (KeyHash) получает на входе ip и порт отправителя и возвращает индекс массива, где хранится ip адрес назначения. Она написана с учетом того, что клиент находится за натом и имеет подсеть с маской 255.255.255.0, поэтому я использую только последний байт ip отправителя, и еще этот байт накладывается 3 битами на два байта порта. В результате мне удалось сжать массив до размера 0x1FFFFF (~8 Мб). Конечно, нужно учитывать, что теперь после загрузки в ядро этот модуль будет занимать не меньше 8 Мб памяти, а это может оказаться слишком много для каких-нибудь встраиваемых систем. И еще не забываем про коллизию :) Но для моего демонстрационного примера все это окупается простотой и, вдобавок, DelTable вообще осталась пустой.
На этом эта длинная часть статьи закончена и осталось только связать клиент-сервер Shifter c модулем ядра Shifter.
Теперь наша цель создать по одному сокету в Shifter и в модуле Shifter и соединить их между собой. Протокол обмена между модулем и сервером Shifter будет простым. Shifter будет отсылать 4 байта IP клиента и 2 байта Порт клиента, а модуль будет отвечать 4 байтами IP назначением, взятым из своей таблицы. Для этого воспользуемся библиотекой Netlink.
Хочу обратить внимание, что заголовок <linux/netlink.h> для пользовательских приложений /usr/include/linux/netlink.h и для модулей ядра /usr/src/linux-headers-[версия ядра]/include/linux/netlink.h имеет множество различий.
Что касается netlink со стороны пользовательского пространства в сети много информации, например вот:
RFC 3549 — Linux Netlink как протокол для служб IP
Работа с NetLink в Linux. Часть 1
Простой монитор сетевых интерфейсов Linux, с помощью netlink
Поэтому здесь я расскажу только то, что нам понадобится, чтобы обеспечить обмен информацией между модулем ядра и программами пользовательского пространства.
Netlink сокет создается привычной функцией: int socket(PF_NETLINK, socket_type, netlink_family);
Где в качестве socket_type могут использоваться как SOCK_RAW, так и SOCK_DGRAM; несмотря на это, протокол netlink не проводит границы между датаграммными и raw-сокетами. А netlink_family выбирает модуль ядра или группу netlink для связи. В <linux/netlink.h> можно посмотреть полный список семейств.
Сообщения netlink представляют собой поток байтов с одним или несколькими заголовками nlmsghdr (netlink message header). Для доступа к байтовым потокам следует использовать только макросы NLMSG_*. Хочу еще обратить внимание, что протокол netlink не обеспечивает гарантированной доставки сообщений. При нехватке памяти или возникновении иных ошибок протокол может отбрасывать пакеты.
Рассмотрим структуры sockaddr_nl, nlmsghdr (<linux/netlink.h>), iovec и msghdr (<sys/socket.h>), с которыми будем работать:

struct sockaddr_nl — описывает адреса netlink для пользовательских программ и модулей ядра. Структура используется для описания отправителя или получателя данных.
struct nlmsghdr – заголовок сообщения netlink и сразу за структурой в памяти расположены отправляемые/принимаемые данные, для доступа к ним используйте NLMSG_DATA(struct nlmsghdr *) макрос.
struct iovec — находится в msghdr, в ней будет содержаться указатель на структуру nlmsghdr.
struct msghdr – содержит указатель на адрес (sockaddr_nl) и данные (iovec)
Рассмотрим некоторые макросы Netlink:
Часть исходного кода сервера Shifter с Netlink.
При использовании библиотеки netlink в модулях ядра есть некоторые отличия, например, структура nlmsghdr из <linux/netlink.h> остается той же, но уже заворачивается в хорошо знакомую нам структуру sk_buff. И вместо привычных функций для работы с сокетами будем использовать новый набор функций. Рассмотрим некоторые из них.
В модуле сокет представляется не типом int, а структурой sock из <net/sock.h>. struct sock – очень большая я не буду ее описывать, к тому же ее описание и не понадобиться.
Для создания netlink сокета в <linux/netlink.h> имеется функция netlink_kernel_create. Она не только создает netlink сокет, но и регистрирует функцию, которая будет вызываться всякий раз, когда поступят данные.
Чтобы закрыть netlink сокет и удалить «регистрацию функции» воспользуйтесь:
Еще нам понадобятся функции из <net/netlink.h>, там вы можете найти функции с изумительным описанием.
Я просто сделаю перевод некоторых нужных функций:
Осталось дописать Module Shifter.
В заключение скажу, чтобы перенаправить пакеты на прокси-сервер, достаточно на шлюзе добавить правило в iptables:
Скачать архив с исходниками Shifter
NetFilter.org
Linux, Kernel, Firewall
Kernel Korner — Why and How to Use Netlink Socket
RFC 3549 — Linux Netlink как протокол для служб IP
Работа с NetLink в Linux. Часть 1
Протокол netlink в Linux
Небольшое оглавление, чтобы Вы могли оценить, стоит ли читать дальше:
- Как работает прокси сервер. Постановка задачи.
- Клиент – серверное приложение с использованием неблокирующих сокетов.
- Написание модуля ядра с использованием библиотеки Netfilter.
- Взаимодействие с модулем ядра из пользовательского пространства (Netlink)
P.S. Для тех, кому только хочется посмотреть на прозрачный прокси-сервер для HTTP и HTTPS, достаточно настроить прозрачный прокси-сервер для HTTP, например, Squid с transparent портом 3128, и скачать архив с исходниками Shifter. Скомпилировать (make) и, после удачной компиляции, выполнить ./Start с правами root. При необходимости можно поправить настройки в shifter.h до компиляции.
Постановка задачи
Как и все начинающие в области IT захотелось покопаться немножко в ядре. Тут и область для экспериментов появилась сама собой. Если заглянуть в гугл, то можно заметить, что, если с прозрачным прокси-сервером для HTTP проблем ни у кого не возникает, то в случае с HTTPS некоторые уверены в том, что прозрачного прокси для протокола HTTPS нет. И его никогда не будет. Все это и послужило появлению этой статьи.
Для начала рассмотрим некоторые аспекты работы прокси-сервера, которые нам понадобятся. Когда браузер напрямую обращается к HTTP серверу, то он создает следующий типовой запрос:
GET / HTTP/1.1
Host: www.google.ru
…
Когда в настройках браузера указываем прокси сервер, то браузер начинает соединяться с прокси-сервером, и отсылает ему запрос с полным адресом:
GET http://www.google.ru/ HTTP/1.1
Host: www.google.ru
…
Если прокси сервер получит запрос с неполным адресом, как в первом случае, то он может не знать, кому предназначен этот запрос и возвратит ошибку.
Скажу в двух словах про HTTPS. Браузер устанавливает tcp соединение и, используя протокол SSL: обменивается сертификатами и передает зашифрованный трафик HTTP. Так как протокол SSL как раз направлен на то, чтобы никто не смог посередине прочитать передаваемые данные, то прокси-сервер не может, как в случае HTTP, выяснить с кем следует установить соединение. Для передачи данных по HTTPS через прокси-сервер браузер должен сообщить прокси-серверу с кем он хочет соединиться, используя HTTP метод CONNECT:
CONNECT mail.google.com:443 HTTP/1.1
Host: mail.google.com
…
На что прокси-сервер должен ответить, что соединение успешно установлено:
HTTP/1.0 200 Connection established
В результате браузер получает как бы прямое tcp соединение через прокси-сервер, в котором он может передавать абсолютно любые данные. А прокси-сервер занимается только точной перекладкой данных из tcp соединения, установленного с браузером, в tcp соединение, установленное с указанным хостом в методе CONNECT, и, соответственно, обратной перекладкой.
Когда используется прозрачное проксирование, т.е. браузер даже не подозревает о существование прокси-сервера, то соответственно браузер и не будет так красиво подготавливать свои данные. И прокси-серверу придется самому подумать об этом.
Схематично взглянем на прозрачный прокси для HTTP:
Здесь конечно есть неточности, например, прокси, получая пакет на свой порт 3128, не передает его дальше гуглу, а создает новое соединение с гуглом, но, в общем, схема взаимодействий примерно такова. В данной схеме видно, что NAT начинает направлять пакеты прокси-серверу, которые предназначены не для него, и ему требуется узнать кому их все-таки отсылать. В случае с HTTP трафиком некоторые прокси-сервера неправомерно начинают пользоваться информацией из поля HOST заголовка HTTP запроса, нарушая спецификацию. Чаще всего конечно в HOST содержится именно то имя хоста, которому и адресован запрос, но, в общем случае, HOST может содержать что угодно. Для HTTPS такое решение и вовсе не подходит. Чтобы узнать, кому адресован пакет, сразу напрашивается решение, в котором прокси-сервер заглянул бы в NAT и посмотрел, кому все-таки были предназначены данные и тогда проблем бы ни каких не было. Вот собственно, чем и займемся.
В сам iptables, к сожалению, не полезем, но все равно будут хорошо понятны основные принципы его работы. Схематично это будет выглядеть следующим образом:
Для намеченных целей, будет достаточно написать крохотный модуль ядра (Module Shifter) и реализовать небольшую программную прослойку (Shifter) в пользовательском пространстве для взаимодействия с нашим модулем, которая и будет подготавливать данные для прокси-сервера.
Клиент – серверное приложение (Shifter)
Напишем маленькое клиент-серверное приложение, которое я назвал Shifter. Shifter будет висеть на своем порту и, когда кто-нибудь установит tcp соединение с ним, то он создаст tcp соединение с прокси-сервером и пошлет ему метод CONNECT (HTTP), а далее будет заниматься только точной передачей данных между этими двумя соединениями. В случае если клиент или прокси закроет соединение с ним, то он закроет эту пару сокетов.
Для отправки метода CONNECT нужен ip адрес удаленного узла, с которым на самом деле хотел установить соединение клиент. Чтобы получить эту информацию Shifter будет связываться с модулем ядра (Module Shifter) используя библиотеку Netlink. Об этом будет рассказано в последней части этой статьи.
Данным приложением мы подготовим прокси-сервер к приему данных (HTTPS) от клиента, который ничего не знает о прокси-сервере. Так как имеется много ресурсов, где подробно написано про сокеты, здесь лишь приведу ссылку на часть исходного кода Shifter'а с подробными комментариями.
Kernel module Shifter
Для того чтобы узнать, что такое модуль ядра можно прочитать, например, Работаем с модулями ядра в Linux. Приступим к написанию модуля. Для начала нужно выполнить инициализацию модуля, которая будет происходить один раз, когда модуль будет подгружаться в ядро. А также следует выполнить корректное завершение работы модуля, чтобы не оставлять всякие ненужные следы прошлого присутствия, когда модуль выгрузят из ядра. Для этих целей в библиотеке <linux/module.h>:<linux/init.h> есть два макроса module_init и module_exit, которые в качестве параметра принимают имя функции для этих целей. Также имеются макросы MODULE_AUTHOR, MODULE_DESCRIPTION, MODULE_LICENSE, чтобы увековечить свое имя :) Еще есть очень полезная функция вывода int printk(const char *fmt, ...) в библиотеке <linux\kernel.h>:<linux\printk.h>. Она мало чем отличается от обычного printf(..). Так как модуль находится в ядре, а не запущен в консоли, то сообщения соответственно выводятся в логи (для просмотра можно использовать команду dmesg). Сообщения можно выводить различных типов:
#define KERN_EMERG "<0>" /* system is unusable */
#define KERN_ALERT "<1>" /* action must be taken immediately */
#define KERN_CRIT "<2>" /* critical conditions */
#define KERN_ERR "<3>" /* error conditions */
#define KERN_WARNING "<4>" /* warning conditions */
#define KERN_NOTICE "<5>" /* normal but significant condition */
#define KERN_INFO "<6>" /* informational */
#define KERN_DEBUG "<7>" /* debug-level messages */
#define KERN_DEFAULT "<d>" /* Use the default kernel loglevel */
Теперь у нас имеется вся информация, чтобы написать каркас своего первого модуля:
#include <linux/module.h>
#include <linux/kernel.h>
MODULE_AUTHOR("Denis Dolgikh <sindo@sibmail.com>");
MODULE_DESCRIPTION("Module for the demonstration");
MODULE_LICENSE("GPL");
int Init(void)
{
printk(KERN_INFO "Init my module\n");
printk("Hello, World!\n");
return 0;
}
void Exit(void)
{
printk(KERN_INFO "Exit my module\n");
}
module_init(Init);
module_exit(Exit);
Расскажу еще немного о том, как это все скомпилировать и запустить. Скажу сразу, что у меня установлена Ubuntu 11.10 (x86) Kernel 3.0.
В системе имеется каталог /lib/modules/[версия ядра]/ в нем находятся модули для соответствующей версии ядра. Также там имеется build – это символическая ссылка на заголовки библиотек ядра (kernel-headers), которые находятся в каталоге /usr/src/linux-headers-[версия ядра]/. Если у вас еще нет kernel-headers, то их нужно скачать (sudo apt-get install linux-headers-[версия ядра]). Чтобы узнать версию текущего ядра, в котором Вы работаете, можно выполнить команду uname –r. Если будете использовать библиотеку с версией отличной от версии текущего ядра, то такой скомпилированный модуль может замечательно работать, а может в лучшем случае не запуститься. Это все зависит от того, какие произошли изменения в ядре, и какие Вы используете в модуле функции.
Для компиляции модуля напишем Makefile. Создадим две цели: all (сборка модуля) и clean (очистка проекта), для их написания воспользуемся уже написанными для нас целями: modules и clean в Makefile из kernel-headers.
# Добавляем модуль к списку модулей для компилирования
# module_test.o – означает, что модуль нужно собрать автоматически из module_test.с
obj-m += module_test.o
# Подключаем Makefile из kernel-headers с помошью -С,
# который лежит в каталоге /lib/modules/[версия ядра]/build
# используем из него цель modules для сборки модулей в списке obj-m
# M=$(PWD) передаем текущий каталог, где лежат исходники нашего модуля
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
Теперь можем легко скомпилировать модуль с помощью команды make и очистить проект make clean. В результате получим готовый модуль module_test.ko, который можно сразу загрузить в ядро, используя команду insmod ./module_test.ko. Есть еще один вариант загрузки модуля в ядро — командой modprobe module_test. Для этого нужно положить модуль module_test.ko в каталог /lib/modules/[текущая версия ядра]/[любой каталог]/ и не забыть выполнить depmod, т.к. эта команда создает список зависимостей модулей в /lib/modules/. Даже если у модуля нет зависимостей, modprobe не увидит добавленный модуль без depmod. Основные различия между insmod и modprobe в следующем: modprobe при загрузке модуля автоматически загружает все модули, от которых он зависит, зато insmod может подгружать модуль из любого каталога. Удалить модуль из ядра: rmmod module_test. Посмотреть информацию о модуле: modinfo module_test или modinfo ./module_test.ko.
Библиотека Netfilter
И так вернемся к прокси для HTTPS. Наша задача — сделать так, чтобы модуль просматривал сетевые пакеты до того, как их обработает DNAT (iptables). Для этого нам поможет библиотека Netfilter. (Для более детального понимания рекомендую дополнительно прочитать о Netfilter в других источниках, хотя бы в Википедии) Рассмотрим, как выглядит путь сетевого пакета в ядре:
Более подробно можно посмотреть вот здесь.
Netfilter <linux/netfilter.h> предоставляет 5 hook функций, которые дают доступ к сетевому пакету в 5 различных местах:
- NF_INET_PRE_ROUTING – функция ловит абсолютно все входные пакеты, до этого пакеты уже прошли простые проверки (пакеты не потеряны, IP checksum в порядке и т.д.);
Далее пакет проходит через маршрутизацию, которая решает, предназначен ли пакет для другого интерфейса или локального процесса. Маршрутизация может отбрасывать пакет, если он не поддается маршрутизации. - NF_INET_LOCAL_IN – вызывается, если пакет предназначен для локального процесса, перед передачей пакета ему;
- NF_INET_FORWARD – когда пакет маршрутизируется с одного интерфейса на другой;
- NF_INET_LOCAL_OUT – ловушка для пакетов которые создают локальные процессы;
- NF_INET_POST_ROUTING – заключительная точка прежде, чем послать пакет драйверу сетевой карты.
Модуль ядра может зарегистрировать свою функцию в любом из этих 5 мест. При регистрации модуль должен указать приоритет своей функции в этом месте. В библиотеке <linux/netfilter_ipv4.h> можно найти приоритет для различных стандартных задач:
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
Из списка видно, что DNAT имеет приоритет -100, поэтому для нашей цели подойдет любой приоритет < -100. Если же приоритет у функции будет > -100, то она будет получать пакеты с уже измененным IP адресом назначения (получателя).
Каждая зарегистрированная функция в любой из 5 точек должна возвращать одно из следующих значений, которое определяет дальнейшую судьбу переданного ей пакета:
#define NF_DROP 0 /* discarded the packet */
#define NF_ACCEPT 1 /* the packet passes, continue iterations */
#define NF_STOLEN 2 /* gone away */
#define NF_QUEUE 3 /* inject the packet into a different queue (the target queue number is in the high 16 bits of the verdict) */
#define NF_REPEAT 4 /* iterate the same cycle once more */
#define NF_STOP 5 /* accept, but don't continue iterations */
В моем вольном переводе это будет звучать так:
- NF_DROP – удалить этот пакет
- NF_ACCEPT – пакет проходит дальше, продолжаются итерации
- NF_STOLEN – бросить этот пакет (ядро его больше не будет обрабатывать, модуль должен сам освободить память выделенную под этот пакет)
- NF_QUEUE – поставить пакет в очередь (обычно для обработки пакета в пользовательском пространстве)
- NF_REPEAT – повторить итерацию (повторный вызов функции с этим же пакетом)
- NF_STOP – пропускать пакет дальше, но итерации не продолжать
С теорией разобрались, теперь продолжим писать модуль. При загрузке модуля в ядро нужно зарегистрировать функцию, назовем ее Hook_Func, которая будет просматривать все входящие пакеты, а при завершении эту функцию надо разрегистрировать, иначе ядро будет пытаться вызывать несуществующую функцию.
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
/* Структура для регистрации функции перехватчика входящих ip пакетов */
struct nf_hook_ops bundle;
int Init(void)
{
printk(KERN_INFO "Start module Shifter\n");
/* Заполняем структуру для регистрации hook функции */
/* Указываем имя функции, которая будет обрабатывать пакеты */
bundle.hook = Hook_Func;
/* Устанавливаем указатель на модуль, создавший hook */
bundle.owner = THIS_MODULE;
/* Указываем семейство протоколов */
bundle.pf = PF_INET;
/* Указываем, в каком месте будет срабатывать функция */
bundle.hooknum = NF_INET_PRE_ROUTING;
/* Выставляем самый высокий приоритет для функции */
bundle.priority = NF_IP_PRI_FIRST;
/* Регистрируем */
nf_register_hook(&bundle);
return 0;
}
void Exit(void)
{
/* Удаляем из цепочки hook функцию */
nf_unregister_hook(&bundle);
printk(KERN_INFO "End module Shifter\n");
}
module_init(Init);
module_exit(Exit);
Теперь все что нам осталось — это написать саму функцию Hook_Func. Она должна иметь следующий прототип:
unsigned int Hook_Func(uint hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *) )
{
/* Получаем очень надежный firewall */
/* который будет удалять (блокировать) абсолютно все входящие пакеты :) */
return NF_DROP;
}
Рассмотрим ее параметры:
- uint hooknum содержит одно из следующих значений: {NF_INET_PRE_ROUTING = 0, NF_INET_LOCAL_IN = 1, NF_INET_FORWARD = 2, NF_INET_LOCAL_OUT = 3, NF_INET_POST_ROUTING = 4}. Этот параметр нужен, чтобы узнать из какого места вызвали функцию, т.к. можно зарегистрировать одну и ту же функцию в нескольких местах.
- struct sk_buff *skb указатель на структуру пакета.
- const struct net_device *in информация о входном интерфейсе. Если это исходящий пакет, тогда параметр равен NULL.
- const struct net_device *out информация о выходном интерфейсе. Если это входящий пакет, тогда параметр равен NULL.
- int (*okfn)(struct sk_buff *) — callback функция, которая вызывается с пакетом, когда все итерации вернут положительный ответ.
Теперь подробнее об указателе на пакет struct sk_buff *skb.
sk_buff – это буфер для работы с пакетами. Как только приходит пакет или появляется необходимость его отправить, создается sk_buff, куда и помещается пакет, а также сопутствующая информация, откуда, куда, для чего… На протяжении всего путешествия пакета в сетевом стеке используется sk_buff. Как только пакет отправлен, или данные переданы пользователю, структура уничтожается, тем самым освобождая память.Cтруктура sk_buff описывается в <linux/skbuff.h>, там же описаны еще различные функции для приятной работы с ней.
При работе с tcp можно воспользоваться еще двумя структурами — это struct iphdr и struct tcphdr.
Как видно из названия, эти структуры предназначены для работы с IP заголовком и, соответственно, с TCP заголовком. Чтобы получить указатели на эти структуры из skb_buff можно воспользоваться двумя функциями:
static inline unsigned char *skb_network_header(const struct sk_buff *skb);
static inline unsigned char *skb_transport_header(const struct sk_buff *skb);
В этом месте я хотел бы обратиться к читателю. Мне осталось не совсем понятным, кто именно должен устанавливать указатель transport_header в структуре sk_buff, т.к. в точках NF_INET_PRE_ROUTING и NF_INET_LOCAL_IN (с любыми приоритетами) мне не удалось с помощью skb_transport_header получить структуру на tcp заголовок, хотя в остальных точках это работало прекрасно. Пришлось вручную указывать смещение для transport_header от указателя sk_buff->data, воспользовавшись void skb_set_transport_header(skb, offset).
Упомянутый указатель sk_buff->data — это указатель на содержимое пакета, т.е. указывает на область памяти после Ethernet протокола, например, сразу на структуру IP заголовка, а после нее может следовать структура TCP заголовка или Ваш собственный протокол.
Так как везде используются указатели на данные в самом пакете, то можно не только читать различные поля, но и изменять их. Однако нужно помнить, что при изменении, например, IP адреса отправителя или получателя следует еще пересчитать контрольную сумму в заголовке IP пакета.
И так, наша функция будет сохранять IP адрес назначения только тогда, когда она увидит IP-TCP пакет, идущий на порт 443 (HTTPS) и содержащий флаг SYN, который говорит, что клиент хочет установить TCP соединение для протокола HTTPS. И удалять, когда появляются пакеты содержащие флаги FIN или RST, которые сообщают что tcp соединение разорвано и больше этот IP адрес нам не нужен.
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#define uchar unsigned char
#define ushort unsigned short
#define uint unsigned int
/* Hook_Func - функция, которая будет просматривать все входящие пакеты */
/* Запоминает IP адрес получателя, если пакет: */
/* - является tcp пакетом */
/* - идет на 443 порт (HTTPS) */
/* - содержит флаг SYN (установка tcp соединения) */
uint Hook_Func(uint hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *) )
{
/* Указатель на структуру заголовка протокола ip в пакете */
struct iphdr *ip;
/* Указатель на структуру заголовка протокола tcp в пакете */
struct tcphdr *tcp;
/* Проверяем что это IP пакет */
if (skb->protocol == htons(ETH_P_IP))
{
/* Сохраняем указатель на структуру заголовка IP */
ip = (struct iphdr *)skb_network_header(skb);
/* Проверяем что это IP версии 4 и внутри TCP пакет */
if (ip->version == 4 && ip->protocol == IPPROTO_TCP)
{
/* Задаем смещение в байтах для указателя на TCP заголовок */
/* ip->ihl - длина IP заголовка в 32-битных словах */
skb_set_transport_header(skb, ip->ihl * 4);
/* Сохраняем указатель на структуру заголовка TCP */
tcp = (struct tcphdr *)skb_transport_header(skb);
/* Если пакет идет на 443 порт (HTTPS) */
if (tcp->dest == htons(443))
{
/* Если выставлен флаг SYN, то сохраняем IP адрес назначения */
if (tcp->syn)
AddTable((uint)ip->saddr, (ushort)tcp->source, (uint)ip->daddr);
/* Если имеется флаг FIN или RST, то можно удалить IP адрес назначения */
if (tcp->fin || tcp->rst)
DelTable((uint)ip->saddr, (ushort)tcp->source, (uint)ip->daddr);
}
}
}
/* Пропускаем дальше все пакеты */
return NF_ACCEPT;
}
Здесь есть две функции AddTable и DelTable, которые должны сохранять и удалять IP адрес получателя из памяти, для каждого IP и порта отправителя. Это нужно для того, чтобы клиент-сервер Shifter смог связаться с модулем Shifter и воспользовавшись функцией ReadTable, узнать по IP и порту клиента с каким IP адресом на самом деле хотел он связаться. Я не стал сильно раздумывать над типом данных для сохранения IP и воспользовался обычным статическим массивом с использованием элементарной хэш-функции. Хэш-функция (KeyHash) получает на входе ip и порт отправителя и возвращает индекс массива, где хранится ip адрес назначения. Она написана с учетом того, что клиент находится за натом и имеет подсеть с маской 255.255.255.0, поэтому я использую только последний байт ip отправителя, и еще этот байт накладывается 3 битами на два байта порта. В результате мне удалось сжать массив до размера 0x1FFFFF (~8 Мб). Конечно, нужно учитывать, что теперь после загрузки в ядро этот модуль будет занимать не меньше 8 Мб памяти, а это может оказаться слишком много для каких-нибудь встраиваемых систем. И еще не забываем про коллизию :) Но для моего демонстрационного примера все это окупается простотой и, вдобавок, DelTable вообще осталась пустой.
/* Статический массив для хранения IP адреса получателя */
#define MaxTable 0x1FFFFF
uint Table[MaxTable];
/* KeyHash - возвращает индекс в массиве */
/* который соответсвует заданным IP и Порту отправителя */
uint KeyHash(uint src_IP, ushort src_Port)
{
return (uint)(((src_IP & 0xFF000000) >> 11) ^ (uint)src_Port) % MaxTable;
}
/* AddTable - добавляет IP адрес получателя в таблицу */
/* который будет соответствовать заданным IP и Порту отправителя */
void AddTable(uint src_IP, ushort src_Port, uint dst_IP)
{
Table[KeyHash(src_IP, src_Port)] = dst_IP;
}
void DelTable(uint src_IP, ushort src_Port, uint dst_IP)
{
/* Если вы используете динамически выделяемую память для хранения IP получателя */
/* то здесь можно ее удалять */
}
/* ReadTable - возвращает IP адрес получателя */
/* который соответствует заданным IP и Порту отправителя */
uint ReadTable(uint src_IP, ushort src_Port)
{
return Table[KeyHash(src_IP, src_Port)];
}
На этом эта длинная часть статьи закончена и осталось только связать клиент-сервер Shifter c модулем ядра Shifter.
Взаимодействие с модулем ядра из пользовательского пространства (Netlink)
Теперь наша цель создать по одному сокету в Shifter и в модуле Shifter и соединить их между собой. Протокол обмена между модулем и сервером Shifter будет простым. Shifter будет отсылать 4 байта IP клиента и 2 байта Порт клиента, а модуль будет отвечать 4 байтами IP назначением, взятым из своей таблицы. Для этого воспользуемся библиотекой Netlink.
Хочу обратить внимание, что заголовок <linux/netlink.h> для пользовательских приложений /usr/include/linux/netlink.h и для модулей ядра /usr/src/linux-headers-[версия ядра]/include/linux/netlink.h имеет множество различий.
Netlink in user space
Что касается netlink со стороны пользовательского пространства в сети много информации, например вот:
RFC 3549 — Linux Netlink как протокол для служб IP
Работа с NetLink в Linux. Часть 1
Простой монитор сетевых интерфейсов Linux, с помощью netlink
Поэтому здесь я расскажу только то, что нам понадобится, чтобы обеспечить обмен информацией между модулем ядра и программами пользовательского пространства.
Netlink сокет создается привычной функцией: int socket(PF_NETLINK, socket_type, netlink_family);
Где в качестве socket_type могут использоваться как SOCK_RAW, так и SOCK_DGRAM; несмотря на это, протокол netlink не проводит границы между датаграммными и raw-сокетами. А netlink_family выбирает модуль ядра или группу netlink для связи. В <linux/netlink.h> можно посмотреть полный список семейств.
Сообщения netlink представляют собой поток байтов с одним или несколькими заголовками nlmsghdr (netlink message header). Для доступа к байтовым потокам следует использовать только макросы NLMSG_*. Хочу еще обратить внимание, что протокол netlink не обеспечивает гарантированной доставки сообщений. При нехватке памяти или возникновении иных ошибок протокол может отбрасывать пакеты.
Рассмотрим структуры sockaddr_nl, nlmsghdr (<linux/netlink.h>), iovec и msghdr (<sys/socket.h>), с которыми будем работать:
struct sockaddr_nl — описывает адреса netlink для пользовательских программ и модулей ядра. Структура используется для описания отправителя или получателя данных.
struct sockaddr_nl
{
sa_family_t nl_family; /* семейство протоколов AF_NETLINK */
unsigned short nl_pad; /* заполнение нулями */
__u32 nl_pid; /* содержит идентификатор процесса или 0, если сообщение адресовано ядру, либо отправитель является ядром */
__u32 nl_groups; /* netlink имеет 32 multicast-группы. nl_groups содержит битовую маску групп, которым следует слышать сообщение по умолчанию установлено нулевое значение, которое отключает групповую передачу сообщений */
};
struct nlmsghdr – заголовок сообщения netlink и сразу за структурой в памяти расположены отправляемые/принимаемые данные, для доступа к ним используйте NLMSG_DATA(struct nlmsghdr *) макрос.
struct nlmsghdr
{
__u32 nlmsg_len; /* размер сообщения с учетом заголовка */
__u16 nlmsg_type; /* тип сообщения (содержимое) */
__u16 nlmsg_flags; /* стандартные и дополнительные флаги */
__u32 nlmsg_seq; /* порядковый номер (сообщение может быть разбито на несколько структур) */
__u32 nlmsg_pid; /* идентификатор процесса (PID), открывшего сокет */
};
struct iovec — находится в msghdr, в ней будет содержаться указатель на структуру nlmsghdr.
struct iovec
{
void * iov_base; /* указатель на данные (указатель на nlmsghdr) */
size_t iov_len; /* длина (размер) данных */
};
struct msghdr – содержит указатель на адрес (sockaddr_nl) и данные (iovec)
struct msghdr
{
void * msg_name; /* адрес отправителя или получателя */
socklen_t msg_namelen; /* длина адреса */
struct iovec * msg_iov; /* указатель на данные */
size_t msg_iovlen; /* длинна данных */
void * msg_control; /* буфер для разнообразных вспомогательных данных */
size_t msg_controllen; /* длина буфера вспомогательных данных */
int msg_flags; /* флаги принятого сообщения */
};
Рассмотрим некоторые макросы Netlink:
int NLMSG_ALIGN(size_t len);int NLMSG_LENGTH(size_t len);int NLMSG_SPACE(size_t len);void *NLMSG_DATA(struct nlmsghdr *nlh);struct nlmsghdr *NLMSG_NEXT(struct nlmsghdr *nlh, int len);int NLMSG_OK(struct nlmsghdr *nlh, int len);int NLMSG_PAYLOAD(struct nlmsghdr *nlh, int len);Часть исходного кода сервера Shifter с Netlink.
Netlink Kernel Space
При использовании библиотеки netlink в модулях ядра есть некоторые отличия, например, структура nlmsghdr из <linux/netlink.h> остается той же, но уже заворачивается в хорошо знакомую нам структуру sk_buff. И вместо привычных функций для работы с сокетами будем использовать новый набор функций. Рассмотрим некоторые из них.
В модуле сокет представляется не типом int, а структурой sock из <net/sock.h>. struct sock – очень большая я не буду ее описывать, к тому же ее описание и не понадобиться.
Для создания netlink сокета в <linux/netlink.h> имеется функция netlink_kernel_create. Она не только создает netlink сокет, но и регистрирует функцию, которая будет вызываться всякий раз, когда поступят данные.
struct sock *netlink_kernel_create(
struct net *net,
int unit,
unsigned int groups,
void (*input)(struct sk_buff *skb),
struct mutex *cb_mutex,
struct module *module);
Чтобы закрыть netlink сокет и удалить «регистрацию функции» воспользуйтесь:
void netlink_kernel_release(struct sock *sk);
Еще нам понадобятся функции из <net/netlink.h>, там вы можете найти функции с изумительным описанием.
Я просто сделаю перевод некоторых нужных функций:
/**
* nlmsg_new – выделяет память для нового netlink сообщения
* @payload: размер данных сообщения
* @flags: тип памяти для выделения
*
* Используйте NLMSG_DEFAULT_SIZE, если размер данных не известен
*/
static inline struct sk_buff *nlmsg_new(size_t payload, gfp_t flags)
{
return alloc_skb(nlmsg_total_size(payload), flags);
}
/**
* nlmsg_put - Добавляет новое сообщение NetLink в skb пакет
* @skb: буфер сетевого пакета для netlink сообщения
* @pid: идентификатор процесса
* @seq: порядковый номер сообщения
* @type: тип сообщения
* @payload: длина передаваемых данных (полезных данных)
* @flags: флаги сообщений
*
* Возвращает NULL, если для skb пакета выделено меньше памяти,
* чем необходимо для размещения заголовка и данных netlink сообщения,
* иначе указатель на netlink сообщение
*/
static inline struct nlmsghdr *nlmsg_put(struct sk_buff *skb, u32 pid, u32 seq,
int type, int payload, int flags)
/**
* nlmsg_unicast – передает индивидуальное netlink сообщение
* @sk: netlink сокет
* @skb: сетевой пакет с netlink сообщением
* @pid: netlink идентификатор сокета назначения
*/
static inline int nlmsg_unicast(struct sock *sk, struct sk_buff *skb, u32 pid)
/**
* nlmsg_data – возвращает указатель на полезные данные
* @nlh: заголовок netlink сообщение
*/
static inline void *nlmsg_data(const struct nlmsghdr *nlh)
{
return (unsigned char *) nlh + NLMSG_HDRLEN;
}
Осталось дописать Module Shifter.
Заключение
В заключение скажу, чтобы перенаправить пакеты на прокси-сервер, достаточно на шлюзе добавить правило в iptables:
# для таблицы nat добавить правило (-A) в точку PREROUTING
# для протокола tcp и порта назначения 443 сделать редирект на 443 порт
iptables -t nat -A PREROUTING -p tcp --dport 443 -j REDIRECT --to-port 443
Скачать архив с исходниками Shifter
Конец.
Используемая и полезная литература
NetFilter.org
Linux, Kernel, Firewall
Kernel Korner — Why and How to Use Netlink Socket
RFC 3549 — Linux Netlink как протокол для служб IP
Работа с NetLink в Linux. Часть 1
Протокол netlink в Linux

{kind=link}