Не так давно мне пришлось делать приложение для Windows Phone работающее с xml-файлами. Всё было неплохо, но когда в файле стало ~100.000 записей, чтение их занимало ну уж очень много времени. И я решил сравненить производительность различных способов чтения данных из xml возможных на платформе .Net.
Подробности под катом.
Для лучшего понимания показателей проведенных тестов стоить рассказать на чём они были проведены. Тесты из разряда «Desktop» я выполял на домашнем компьютере:
Тесты на Windows Phone были выполнены на HTC 7 Mozart.
Для тестирования использовался простой xml-файл. ID для каждого элемента генерировались рандомно, а количество записей различалось в зависимости от теста и составляло: 1, 10, 100, 1 000, 100 000 штук соответственно. Итоговый файл выглядел примерно следующим образом:
Для уменьшение погрешностей каждый тест был выполен 100 раз и полученные данные усреднены. А для имитации некоторых действий над записью вызывался пустой метод ProcessId(id).
На мой взгляд реализация чтения данных этим способом наиболее простая и понятная. Но, как мы увидим в конце, достигается это уж очень большой ценой (в конце статьи приведена реализация этого способа без использования XPath, но результаты, лично у меня, не сильно отличаются). Код метода следующий:
Использование Linq-to-XML также оставляет реализацию метода довольно простой и понятной.
Ну и наконец последний способ чтения данных из XML — использование XmlTextReader. Стоит сказать, что этот метод самый сложный для понимания. В процессе чтения xml-файла вы двигаетесь по нему сверху вниз (без возможности движения в обратном направлении), и вам каждый раз необходимо проверять, те ли данные вам нужно извлечь? Соответственно, код метода выглядит так:
* Для упрощения, в методах были опущены проверки.
Ниже представлены результаты тестирования. Для запуска каждого теста время измерялось отедельно и затем усреднялось. Время в таблице в миллисекундах.
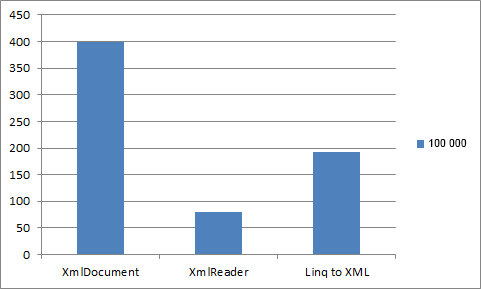
Как видно из таблицы, XmlReader при чтении больших xml файлов, выигрывает в производительности Linq To XML в 2,42 раза, а XmlDocument в более чем 5 раз!
Теперь настало время провести тесты на телефоне. Стоит заметить, что на Windows Phone установлена более старая версия .Net Framework'а, поэтому метод с использованием XmlDocument.Load не работает, а код для XmlReader пришлось немного переписать:
Предсказуемо, что и на телефоне быстрее оказался XmlReader. Но в отличии от настольного компьютера, разница в производительности на больших файлах у них различна. На телефоне XmlReader быстрее LINQ to XML в 1,91 раз, а на десктопе в 2,42 раза.
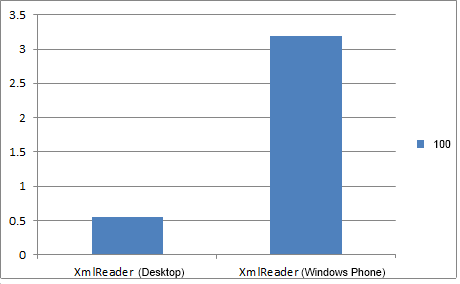
Разница в скорости чтения 100 элементов из файла на Desktop и Windows Phone.
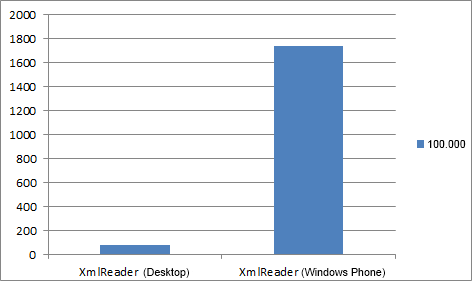
Разница в скорости чтения 100 000 элементов из файла на Desktop и Windows Phone.
Как можно видеть, скорость чтения данных на телефоне и настольном компьютере, в зависимости от объема данных, изменяется нелинейно. Интересно узнать почему это так?
Как мы вяснили, самым произоводительным способом чтения данных из xml является использование XmlReader'a вне зависимости от платформы. Но неудобство его использования заключается в довольно сложном способое выборки данных — нам каждый раз приходиться проверять на каком элементе стоит указатель.
Если же для вас производительность не является краеугольным камнем, а главное — ясность и простота сопровождаемости кода, то наиболее подходящим является использование LINQ to XML. Также необходимо стараться избегать использования XmlDocument.Load в рабочих проектах из-за его низкой производительности.
P.S. Стоит упомянуть, что на написание всего этого меня вдохновила эта статья.
Update: по предложению alex_rusсделал тест для XmlDocument без использования XPath. Результыты получились лучше, но все равно этот способ остался самым медленным.
Таблица № 3. Сравнение производительности XmlDocument с и без использования XPath.
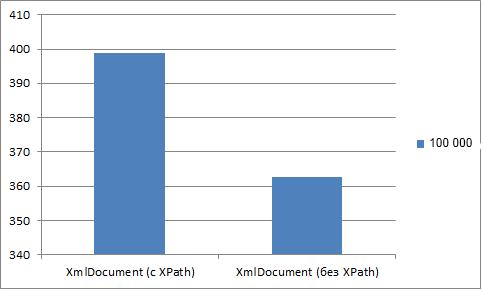
Как видно из таблицы (и рисунка) производительность увеличилась только на 10%. Хотя были предположения, что это значение будет гораздо выше.
Собственно, код для XmlDocument без XPath ниже. Надеюсь, знающие люди покажут где у меня ошибки, в результате которых скорость обработки увеличилась всего лишь на 10%, а не «в разы».
Подробности под катом.
Оборудование
Для лучшего понимания показателей проведенных тестов стоить рассказать на чём они были проведены. Тесты из разряда «Desktop» я выполял на домашнем компьютере:
- Процессор: Pentium Dual-Core T4300 2100 Mhz
- RAM: DDR2 2048Mb
Тесты на Windows Phone были выполнены на HTC 7 Mozart.
Подготовка к тестированию
Для тестирования использовался простой xml-файл. ID для каждого элемента генерировались рандомно, а количество записей различалось в зависимости от теста и составляло: 1, 10, 100, 1 000, 100 000 штук соответственно. Итоговый файл выглядел примерно следующим образом:
<?xml version="1.0"?>
<items>
<item id="433382426" />
<item id="1215581841" />
<item id="2085749980" />
........
<item id="363608924" />
</items>
* This source code was highlighted with Source Code Highlighter.Для уменьшение погрешностей каждый тест был выполен 100 раз и полученные данные усреднены. А для имитации некоторых действий над записью вызывался пустой метод ProcessId(id).
XmlDocument.Load
На мой взгляд реализация чтения данных этим способом наиболее простая и понятная. Но, как мы увидим в конце, достигается это уж очень большой ценой (в конце статьи приведена реализация этого способа без использования XPath, но результаты, лично у меня, не сильно отличаются). Код метода следующий:
private static void XmlDocumentReader(string filename)
{
var doc = new XmlDocument();
doc.Load(filename);
XmlNodeList nodes = doc.SelectNodes("//item");
if (nodes == null)
throw new ApplicationException("invalid data");
foreach (XmlNode node in nodes)
{
string id = node.Attributes["id"].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter.LINQ to XML
Использование Linq-to-XML также оставляет реализацию метода довольно простой и понятной.
private static void XDocumentReader(string filename)
{
XDocument doc = XDocument.Load(filename);
if (doc == null || doc.Root == null)
throw new ApplicationException("invalid data");
foreach (XElement child in doc.Root.Elements("item"))
{
XAttribute attr = child.Attribute("id");
if (attr == null)
throw new ApplicationException("invalid data");
string id = attr.Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter.XmlReader
Ну и наконец последний способ чтения данных из XML — использование XmlTextReader. Стоит сказать, что этот метод самый сложный для понимания. В процессе чтения xml-файла вы двигаетесь по нему сверху вниз (без возможности движения в обратном направлении), и вам каждый раз необходимо проверять, те ли данные вам нужно извлечь? Соответственно, код метода выглядит так:
private static void XmlReaderReader(string filename)
{
using (var reader = new XmlTextReader(filename))
{
while (reader.Read())
{
if (reader.NodeType == XmlNodeType.Element)
{
if (reader.Name == "item")
{
reader.MoveToAttribute("id");
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter.* Для упрощения, в методах были опущены проверки.
Результаты для Desktop
Ниже представлены результаты тестирования. Для запуска каждого теста время измерялось отедельно и затем усреднялось. Время в таблице в миллисекундах.
| 1 | 10 | 100 | 1 000 | 10 000 | 100 000 | |
| XmlDocument | 0,59 мс | 0,5 мс | 0,67 мс | 2,49 мс | 21,73 мс | 398,91 мс |
| XmlReader | 0,51 мс | 0,47 мс | 0,55 мс | 1,31 мс | 8,62 мс | 79,65 мс |
| Linq to XML | 0,57 мс | 0,59 мс | 0,64 мс | 2,09 мс | 15,6 мс | 192,66 мс |
Как видно из таблицы, XmlReader при чтении больших xml файлов, выигрывает в производительности Linq To XML в 2,42 раза, а XmlDocument в более чем 5 раз!
Тестирование на Windows Phone
Теперь настало время провести тесты на телефоне. Стоит заметить, что на Windows Phone установлена более старая версия .Net Framework'а, поэтому метод с использованием XmlDocument.Load не работает, а код для XmlReader пришлось немного переписать:
private static void XmlReaderReader(string filename)
{
using (var reader = XmlReader.Create(filename)) {
while (reader.Read()) {
if (reader.NodeType == XmlNodeType.Element) {
if (reader.Name == "item") {
reader.MoveToAttribute("id");
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter.Результаты для Windows Phone
Предсказуемо, что и на телефоне быстрее оказался XmlReader. Но в отличии от настольного компьютера, разница в производительности на больших файлах у них различна. На телефоне XmlReader быстрее LINQ to XML в 1,91 раз, а на десктопе в 2,42 раза.
| 1 | 10 | 100 | 1 000 | 10 000 | 100 000 | |
| XmlReader | 1,67 мс | 1,74 мс | 3,19 мс | 19,5 мс | 173,84 мс | 1736,18 мс |
| Linq to XML | 1,73 мс | 2,21 мс | 4,75 мс | 31,39 мс | 314,39 мс | 3315,13 мс |
Разница в скорости чтения 100 элементов из файла на Desktop и Windows Phone.
Разница в скорости чтения 100 000 элементов из файла на Desktop и Windows Phone.
Как можно видеть, скорость чтения данных на телефоне и настольном компьютере, в зависимости от объема данных, изменяется нелинейно. Интересно узнать почему это так?
Заключение
Как мы вяснили, самым произоводительным способом чтения данных из xml является использование XmlReader'a вне зависимости от платформы. Но неудобство его использования заключается в довольно сложном способое выборки данных — нам каждый раз приходиться проверять на каком элементе стоит указатель.
Если же для вас производительность не является краеугольным камнем, а главное — ясность и простота сопровождаемости кода, то наиболее подходящим является использование LINQ to XML. Также необходимо стараться избегать использования XmlDocument.Load в рабочих проектах из-за его низкой производительности.
P.S. Стоит упомянуть, что на написание всего этого меня вдохновила эта статья.
Update: по предложению alex_rusсделал тест для XmlDocument без использования XPath. Результыты получились лучше, но все равно этот способ остался самым медленным.
Таблица № 3. Сравнение производительности XmlDocument с и без использования XPath.
| 1 | 10 | 100 | 1 000 | 10 000 | 100 000 | |
| XmlDocument (c XPath) | 0,59 мс | 0,5 мс | 0,67 мс | 2,49 мс | 21,73 мс | 398,91 мс |
| XmlDocument (без XPath) | 0,56 мс | 0,5 мс | 0,65 мс | 2,24 мс | 19,47 мс | 362,75 мс |
Как видно из таблицы (и рисунка) производительность увеличилась только на 10%. Хотя были предположения, что это значение будет гораздо выше.
Собственно, код для XmlDocument без XPath ниже. Надеюсь, знающие люди покажут где у меня ошибки, в результате которых скорость обработки увеличилась всего лишь на 10%, а не «в разы».
private static void XmlDocumentReader2(string filename)
{
var doc = new XmlDocument();
doc.Load(filename);
XmlElement root = doc.DocumentElement;
foreach (XmlElement el in root.ChildNodes)
{
if (el.Name != "item") continue;
string id = el.Attributes["id"].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter.