Введение, или зачем нужны синтаксические анализаторы
Добрый день.
Не так давно появилась у меня задача синтаксического анализа одной грамматики. Существующие решения мне увы не подходили, поэтому встала проблема написания собственного генератора парсеров. Несмотря на то, что тема довольно популярная и существует не так уж и мало статей и книг по данному сабжу, я всё-таки решил еще раз описать данный процесс, причём начать с самых базовых понятий.
Эта часть посвящена базису, общей теории computer science. Возможно, что это даже преподаётся в школах/вузах России. Самая мякота пойдет со второй части.
Итак, зачем же кому-то может понадобиться писать парсер и что вообще это такое? Парсер — это код, который наделяет входящий набор символов семантическим смыслом. То есть, происходит анализ этих символов, и на основе этого анализа программа понимает как интерпретировать эти буквы и цифры. Простой пример — «1+2», после или во время процесса парсинга знак "+" это не просто символ плюса, но обозначение бинарноого оператора сложения, а в "+3" это унарный оператор знака числа. Большинству людей это очевидно, машине — нет.
Парсеры используются всюду — в Word'e для анализа приложений, словоформ, формул, etc; практически на любом сайте при валидации входных данных: email'а, телефонного номера, номера кредитки; конфигурационные файлы; сериализованные данные (например, в xml); во многих играх — скриптовые ролики, скрипты ИИ, консоль. В общем, это неотъемлемая часть computer science.
Два вида парсеров
Ок, после осознания важности данной технологии, необходимо поднять вопрос о стандартах написания данного класса программ.
Условно говоря, можно парсеры разделить на два типа: на использующих формальное описания языка и на внедряемых напрямую в код без абстрактной схемы данных.
Первый подход означает разделение анализатора на две части — описание формата/схемы входной информации и логики, которая оперирует уже не чистым потоком данных, а структурированным в соответствии со схемой. Пример:
scheme:
DIGIT = '0'..'9'
ADD = DIGIT '+' DIGIT
SIGN = ('+' | '-') DIGIT
EXPR = ADD | SIGN
code:
long result = 0;
ParseNode & expr = Parse(input);
ParseNode & oper = expr.child()
switch (oper.type)
{
// 0: DIGIT, 1: '+', 2: DIGIT
case ADD:
result = oper.child(0) + oper.child(2);
break;
// 0: '+' or '-', 1: DIGIT
case SIGN:
result = oper.child(0) == '-' ? - oper.child(1) : oper.child(1);
break;
}
Второй подход проще показать, чем объяснить:
char c = '';
long result = 0;
input >> c;
// we have three variants of first symbol
switch (c)
{
case '+':
// next symbol is digit
input >> c;
if (c < '0' || c > '9')
return SyntaxError;
result = c - '0';
break;
case '-':
// next symbol is digit
input >> c;
if (c < '0' || c > '9')
return SyntaxError;
result = c - '0';
break;
default:
if (c < '0' || c > '9')
return SyntaxError;
result = c - '0';
input >> c;
if (c != '+')
return SyntaxError;
input >> c;
if (c < '0' || c > '9')
return SyntaxError;
result += (c - '0');
break;
}
В принципе из данного примера уже можно делать выводы о том, какой путь лучше, но я всё же постараюсь собрать плюсы каждого типа. В данном случае, плюс для одного равнозначен минусу другого.
Преимущества описания грамматики:
- Прежде всего, это легкая поддержка языка. То есть модификации, даже самые кардинальные, накладываются очень просто.
- Так как синтаксические конструкции собраны в одном месте и компактно, то очень просто обозреть структуру языка в целом. В альтернативе можно просто-напросто погрязнуть среди тысяч и десятков тысяч строк вперемешку с логикой. Кроме того обеспечивается прозрачность языка, очевидно прослеживается эволюция конструкций. То есть в нашем примере видно как DIGIT превращается в ADD, а затем в EXPR, собственно позволяя наметить точки для внедрения семантической логики.
- Легкое отслеживание ошибок. Причём сразу двух категорий — синтаксических ошибок входных данных и ошибок составления самого кода. При ручном написании, код может содержать противоречивости, мертвые участки, и прочие логические радости и при этом компилироваться. С заданной схемой такое невозможно. Противоречия выявляются сразу на этапе генерации.
- Введение дополнительной абстракции упрощает исходный код и позволяет отлаживать и тестировать более высокоуровневые сущности, которые по определению являются менее многочисленными и более конкретными чем простой поток символов.
Несмотря на всё это, и у программирования «наживую» есть ряд своих плюсов:
- Порог входа значительно ниже. То есть практически любому программисту можно сказать — «сиди пиши код», и парсер будет запрограммирован в предложенном стиле. Для составления формальной грамматики нужно обладать пусть и небольшим, но всё же важным, объёмом теории — азы математической логики, разбираться в построении грамматики, владеть инструментом генерации кода.
- Несмотря на то, что грамматикой можно описать практически всё, есть и исключения. Кроме того к ним добавляется ограниченность инструментария. Прямое написания кода обладает наивысшей гибкостью.
- Есть еще совсем крохотный плюс — всё в одном месте. То есть при нормальной организации программы, можно выделять ключевые фрагменты логики и сразу понимать их суть. В первом варианте у нас фактически два нужных экрана — экран схемы + экран кода. Иногда нужно переключаться между ними для уточнения нюансов. Это не совсем удобно. Но повторюсь, это крайне небольшое преимущество, особенно если учесть второй плюс раздельного кодирования.
Структура парсера
Само собой я, как и большинство нормальных программистов, почти всегда выбираю первый подход. Опять же, для реализации второго не нужно никаких знаний, и дополнительной теории для него у меня нет. Поэтому дальше рассказываю о структуре парсера, основанном на формальной грамматике.

Это весьма условная схема, анализатор может состоять из всех трех частей, или иметь объединение первых или последних двух, и даже быть цельным куском без разделения на компоненты. Здесь уже почти нет best practises в организации. Но лично я предпочитаю отделять мух от котлет. Не буду разводить холивар, а просто опишу возможные варианты.
Прежде всего стоит разобраться, что же это за составляющие. Лексический анализатор получает на вход поток символов заданного алфавита (буквы, цифры, используемые символы, etc). Дальше он разбивает этот поток на более комплексные примитивы (такой вот оксюморон, да), так называемые токены или терминалы. К примеру вместо последовательности цифр какой-то длины синтаксический анализатор получает «Число» с атрибутом равным значению этого числа. Зачем он нужен объясню ниже. Дальше синтаксический анализатор на основе токенов и правил составления символов второго иерархического порядка (первый — токены), так называемых нетерминалов, собирает дерево вывода. Данная АТД однозначно представляет структуру распознанных данных. И наконец, последний этап — это семантический анализ полученного дерева и выполнение бизнес-логики. Как раз этот этап представлен на первом листинге.
Зачем же нужен лексический анализатор, если он фактически может быть интегрирован в синтаксическую часть? Ведь какая разница какой алфавит получать — исходный или новый синтетический. Ответ достаточно очевиден — во-первых, это как правило сужение алфавита, то есть упрощение семантики; во-вторых, мы убираем один или даже несколько нижних уровней дерева при полном сохранении его свойств. Понятное дело что лексический анализатор не должен брать на себя роль синтаксического, а тем более семантического, поэтому на «1+2» он не должен возвращать 3, но простейшие действия, такие как формирование чисел вполне подходит. Немного усложним пример, и посмотрим на дерево вывода в двух случаях. Заодно и покажу что это за дерево такое тем, кто не совсем понял краткого объяснения.
DIGIT = '0'..'9'
NUMBER = NUMBER? DIGIT
ADD = NUMBER '+' NUMBER
SIGN = ('+' | '-') NUMBER
EXPR = ADD | SIGN
Разбор идёт выражения 12+34
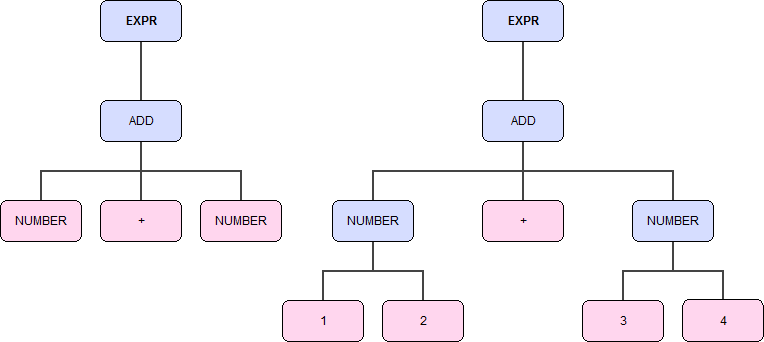
Даже на таком простом примере видно что удобнее разделять анализ как минимум на 2 этапа. Кроме того специализация лексического анализатора позволяет использовать более эффективные, отличные от разбора грамматик, алгоритмы. Основное различие, кроме вышепредставленного эмпирического, лексера от синтаксического анализатора — это отсутствие правил вывода, точнее их неявно можно представить, но справа будут стоять только знаки алфавита, и в правилах никогда нет связи с остальными нетерминалами лексера. То есть они самодостаточны и описывают только ожидаемый поток символов.
Теперь рассмотрим второй потенциальный сплав. Это интеграция семантической логики напрямую в синтаксический анализатор, минуя стадию построения дерева. Здесь тактика проста — намечаем точки, которые имеют семантическое значение и пишем код. Пример:
DIGIT = '0'..'9' {value = child[0] - '0'}
ADD = DIGIT '+' DIGIT {value = child[0].value + child[1].value}
SIGN = ('+' | '-') DIGIT {value = child[0].value == '-' ? - child[1].value : child[1].value}
EXPR = ADD | SIGN {result = child[0].value}
Заметно то, что сложную грамматику так не описать. Да и такое смешивание нивелирует некоторые преимущества раздельного написания кода. Но для простых грамматик это довольно хороший метод написания кода, и его важность не стоит преуменьшать.
LL против LR, или слон против кита
Написание хорошего лексера это отдельная большая тема, поэтому дальше буду описывать только разработку синтаксического анализатора.
Выделяют две группы анализаторов — восходящие (LR) и нисходящие (LL).
Своё название они берут от метода построение дерева вывода. Первый строит дерево снизу вверх, второй же сверху вниз. Немного остановлюсь на этом и приведу наитупейшие алгоритмы.
LR-парсер условно имеет стек, в котором хранит последние поступившие символы (и терминалы, и нетерминалы), на каждом шаге, считывая очередной токен, парсер пытается подобрать правило, которое может применить к набору символов с вершины стека, если находит, то он сворачивает последовательность символов в один нетерминал. То есть если стек выглядит как {DIGIT, +, DIGIT}, то анализатор свернет это в {ADD}, а затем в {EXPR}. Псевдокод такого парсера будет примерно таким:
input >> term;
while (term != EOF)
{
stack.push(term);
do
{
reduced = false;
for (Rule rule : rules)
if (rule.Reduce(stack))
{
stack.pop(rule.right.length);
stack.push(rule.symbol);
reduced = true;
break;
}
} while (reduced);
input >> term;
}
LL-парсер пытается сделать наоборот — для каждого входящего символа угадать к какому правилу он относится. Самый примитив это выбор из альтернатив (например, EXPR может развернуться в ADD или в SIGN, то есть 2 альтернативы) по первому символу, и рекурсивный спуск с новым набором правил, которые продуцируют нетерминалы из выбранного пути. И так до тех пор пока не правила не разложатся до терминалов. Описание довольно сложное, в коде понять это будет куда проще:
function ExpandRule(symbol, term)
{
for (Rule rule : rules)
{
if (rule.sybmol == symbol && firstTerminal(rule) == term)
break;
}
for (s : rule)
{
if (s.type == NonTerminal)
term = ExpandRule(s, term);
else
{
if (term != s)
throw SyntaxError;
input >> term;
}
}
return term;
}
input >> term;
ExpandRule(EXPR, term);
Какой синтаксический анализатор использовать — дело вкуса. Практически по всем характеристикам они одинаковы. Гуляет байка о том, что в Советах использовали LL(x), а на Западе — LR(x), но не знаю насколько это правдиво. Лично мне идеологически приглянулся LR, более подробно о нём расскажу в следующей части.
PS: Важность правильного написания парсеров можно заметить прямо в статье, взглянув на неподсвеченный второй участок кода, который обернут в тот же самый блок source, что и первый пример.
Части статьи
- Часть 1. Базовая теория
- Часть 2. Описание LR-генераторов
- Часть 3. Особенности написания и возможные фичи LR-генераторов
