Всем привет. Перед вами заключительная статья из цикла «Внутреннее устройство и архитектура сервиса AtContent.com». Здесь собраны лучшие практики из нашего опыта работы с Azure Table Storage и платформой в целом. Эта статья может стать отправной точкой при построении типовых структур данных и позволит более эффективно использовать ресурсы Windows Azure.
Горизонтальное масштабирование во многом опирается на разделение данных и платформа Windows Azure не исключение. Одной из составляющих частей платформы является Azure Storage Table — NoSQL база данных с неограниченным ростом. Но многие разработчики игнорируют её в пользу привычного и знакомого SQL. При этом довольно часто задачи решаются с помощью Azure Storage Table намного эффективнее, чем с применением Azure SQL.
Здесь вы найдете практику и сценарии применения Azure Storage Tables.
Самым распространенным сценарием применения является хранение списков. Он прекрасно вписывается в архитектуру Azure Storage Tables. Списки могут быть очень разные, но самый частоупотребимый – это записи по дате.
Первое, на что стоит обратить внимание при работе –это то, как из таблицы выбираются значения. Особенностей здесь несколько:
Про выборку частями нужно помнить всегда, потому как Table Storage может вернуть любое количество записей и токен продолжения. Хотя чаще всего это происходит когда записей больше 1000. В SDK есть механизм, который позволяет обрабатывать это в автоматическом режиме, так что очень сильно беспокоиться об этом не стоит. Нужно только помнить о том, что каждый запрос – это дополнительная транзакция. Если у вас будет 2001 запись в выборке – тобудет как минимум 3 обращения к хранилищу.
Также нужно помнить про PartitionKey. Это очень важный ключ, который отвечает за разделение данных по разделам. Если в запросе вы не укажете его – то облачному хранилищу придется опрашивать все разделы и затем собирать данные в один набор. При этом разные разделы могут располагаться на различных серверах. И это не добавит производительности вашим запросам. К тому же увеличит число транзакций к хранилищу.
И наконец, наменее очевидная особенность – это выборка записей по условию. Экспериментальным путем было обнаружено, что если указывать для RowKey условие «меньше» или «меньше или равно» — то выбранные значения будут идти от минимального до того, который будет удовлетворять условию. При этом порядок возвращаемых записей будет от меньшего к большему. То есть если у вас в таблице 10 000 записей, которые удовлетворяют условию, а вам нужны только первые 100, у которых RowKey меньше определенного значения – то хранилище выберет вам 100 записей начиная от минимального значения RowKey.
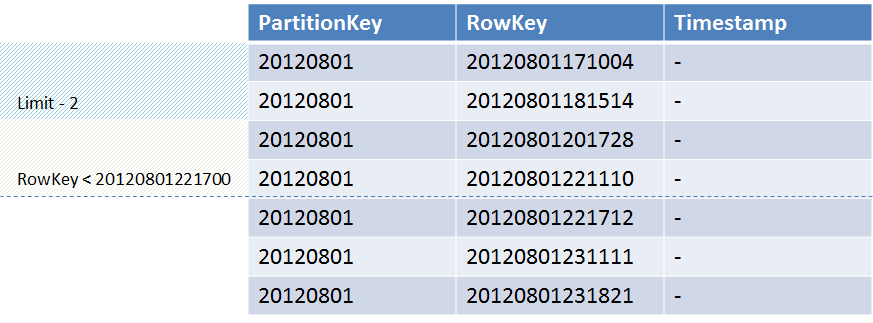
В качестве примера можно рассмотреть таблицу, в которой несколько записей с ключом RowKey от даты. И нам требуется выбрать 2 записи у которых RowKey меньше, чем 20120801221700. Мы ожидаем, что хранилище вернет записи с ключами «20120801221110» и «20120801201728». Но в соответствие с порядком сортировки хранилище вернет значения «20120801171004» и «20120801181514».
Побороть это можно использовав инвертированный ключ. Так, в случае с датой – это DateTime.MaxValue – CurrentDateTime. Тогда при выборке будет использоваться обратное условие и оно будет работать корректно.
При проектировании приложения следует ориентироваться на рекомендации, которые дает Microsoft в отношении Storage Table (http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx). Смысл этих рекомендаций очень простой. Проектируйте приложения таким образом, чтобы ключей разделов было не слишком много, и не слишком мало. А также, чтобы записей в каждом разделе было не слишком много. Желательно, чтобы они распределялись по разделам равномерно. Если же возможно предугадать нагрузку на разделы – то разделы, которые будут подвеграться большей нагрузке следует заполнять меньшим количеством записей. Исходя из архитектуры Storage Tables, разделы, которые подвергаются большой нагрузке, автоматически реплицируются. И чем меньше будет размер раздела – тем быстрее будет происходить репликация.
При разработке перед нами возникла проблема выбора ключей разделов для таблицы, в которой хранятся данные для идентификации и аутентификации пользователей. Так как мы идентифицируем пользователя в первую очередь по email – то необходимо было выбрать систему, по которой они распределялись бы по разделам. Проведя небольшой экспермент было установлено, что хорошее равномерное распределение дает хеширование MD5 и последующее выделение части битов из хеша для определения номера раздела.
Вот такой незамысловатый код позволит получать нужное колчиество бит из хеша MD5 и использовать из как номер раздела:
Этот метод, как и многие другие, доступен в составе CPlaseEngine, ссылку на который можно найти в конце статьи.
В последствие мы расширили эту практику и на другие части нашей системы, и она показала себя с очень хорошей стороны. Хотя в некоторых случаях разделять на разделы выгоднее по идентификатору пользователя. Либо по части идентификатора пользователя. Это позволяет строить запросы для выбора данных, касающихся определенного пользователя. При этом запросы получаются эффективные в том плане, что выбирать приходится из одного раздела.
Как можно было заметить ранее, часто ключ для записи связан с какой-нибудь датой. Чаще всего датой создания. В нашей системе это встречается очень часто. И это очень эффективно для записей, из которых после требуется получить список начиная с какой-нибудь даты.
Естественно, ключ записи должен быть уникальным. Эта уникальность должна быть для пары «ключ раздела»-«ключ записи». Поэтому при генерации ключа безопасней всего добавить к нему несколько случайных символов.
Если вы планируете выбирать записи в виде списков, то общая рекомендациея для генерации ключа записи – связывать его с параметром, относительно которого вы будете строить список. Так, например, если вы строите список значений по датам – то лучше всего использовать дату при генерации ключа.
Практика разделения по хешу ключа может применяться не только в отношении Table Storage. Она очень хорошо распространяется и на файловую систему. При кешировании сущностей из Table Storage в кеш на экземпляре мы также используем разделение по хешу от пути файла.
Горизонтальное масштабирование тесно связано с разделением данных и чем эффективнее вы будете разделять данные – тем эффективнее будет работать система в целом. Windows Azure как платформа дает очень мощную инфраструктуру для построения надежных, масштабируемых, отказоустойчивых сервисов. Но при этом не стоит забывать о том, что для построения таких сервисов внутренняя архитектура должна соотвествовать принципам построения высоконагруженных систем.
Также я с радостью хочу сообщить, что в открытом доступе на CodePlex появился наш OpenSource проект CPlaseEngine. В нем собраны инструменты, которые позволят разрабатывать сервисы на платформе Windows Azure более эффективно. Скачать его можно по адресу https://cplaseengine.codeplex.com/.
Читайте в серии:
Горизонтальное масштабирование во многом опирается на разделение данных и платформа Windows Azure не исключение. Одной из составляющих частей платформы является Azure Storage Table — NoSQL база данных с неограниченным ростом. Но многие разработчики игнорируют её в пользу привычного и знакомого SQL. При этом довольно часто задачи решаются с помощью Azure Storage Table намного эффективнее, чем с применением Azure SQL.
Здесь вы найдете практику и сценарии применения Azure Storage Tables.
В общем про Azure Table Storage
Самым распространенным сценарием применения является хранение списков. Он прекрасно вписывается в архитектуру Azure Storage Tables. Списки могут быть очень разные, но самый частоупотребимый – это записи по дате.
Первое, на что стоит обратить внимание при работе –это то, как из таблицы выбираются значения. Особенностей здесь несколько:
- Значения выбираются частями не больше, чем по 1000 значений;
- Выборка без указания ключа раздела (PartitionKey) работает очень медленно;
- При выборе диапазона значений по ключу правильно срабатывает условие «меньше или равно»;
Про выборку частями нужно помнить всегда, потому как Table Storage может вернуть любое количество записей и токен продолжения. Хотя чаще всего это происходит когда записей больше 1000. В SDK есть механизм, который позволяет обрабатывать это в автоматическом режиме, так что очень сильно беспокоиться об этом не стоит. Нужно только помнить о том, что каждый запрос – это дополнительная транзакция. Если у вас будет 2001 запись в выборке – тобудет как минимум 3 обращения к хранилищу.
Также нужно помнить про PartitionKey. Это очень важный ключ, который отвечает за разделение данных по разделам. Если в запросе вы не укажете его – то облачному хранилищу придется опрашивать все разделы и затем собирать данные в один набор. При этом разные разделы могут располагаться на различных серверах. И это не добавит производительности вашим запросам. К тому же увеличит число транзакций к хранилищу.
И наконец, наменее очевидная особенность – это выборка записей по условию. Экспериментальным путем было обнаружено, что если указывать для RowKey условие «меньше» или «меньше или равно» — то выбранные значения будут идти от минимального до того, который будет удовлетворять условию. При этом порядок возвращаемых записей будет от меньшего к большему. То есть если у вас в таблице 10 000 записей, которые удовлетворяют условию, а вам нужны только первые 100, у которых RowKey меньше определенного значения – то хранилище выберет вам 100 записей начиная от минимального значения RowKey.
В качестве примера можно рассмотреть таблицу, в которой несколько записей с ключом RowKey от даты. И нам требуется выбрать 2 записи у которых RowKey меньше, чем 20120801221700. Мы ожидаем, что хранилище вернет записи с ключами «20120801221110» и «20120801201728». Но в соответствие с порядком сортировки хранилище вернет значения «20120801171004» и «20120801181514».
Побороть это можно использовав инвертированный ключ. Так, в случае с датой – это DateTime.MaxValue – CurrentDateTime. Тогда при выборке будет использоваться обратное условие и оно будет работать корректно.
Практика выбора ключей разделов
При проектировании приложения следует ориентироваться на рекомендации, которые дает Microsoft в отношении Storage Table (http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx). Смысл этих рекомендаций очень простой. Проектируйте приложения таким образом, чтобы ключей разделов было не слишком много, и не слишком мало. А также, чтобы записей в каждом разделе было не слишком много. Желательно, чтобы они распределялись по разделам равномерно. Если же возможно предугадать нагрузку на разделы – то разделы, которые будут подвеграться большей нагрузке следует заполнять меньшим количеством записей. Исходя из архитектуры Storage Tables, разделы, которые подвергаются большой нагрузке, автоматически реплицируются. И чем меньше будет размер раздела – тем быстрее будет происходить репликация.
При разработке перед нами возникла проблема выбора ключей разделов для таблицы, в которой хранятся данные для идентификации и аутентификации пользователей. Так как мы идентифицируем пользователя в первую очередь по email – то необходимо было выбрать систему, по которой они распределялись бы по разделам. Проведя небольшой экспермент было установлено, что хорошее равномерное распределение дает хеширование MD5 и последующее выделение части битов из хеша для определения номера раздела.
Вот такой незамысловатый код позволит получать нужное колчиество бит из хеша MD5 и использовать из как номер раздела:
using System.Security.Cryptography;
using System.Text;
public static string GetHashMD5Binary(string Input, int BitCount = 128)
{
if (Input == null) return null;
byte[] MD5Bytes = MD5.Create().ComputeHash(
Encoding.Default.GetBytes(Input));
int Len = MD5Bytes.Length;
string Result = "";
int HasBits = 0;
for (int i = 0; i < Len; i++)
{
Result += Convert.ToString(MD5Bytes[i], 2).PadLeft(8, '0');
HasBits += 8;
if (HasBits >= BitCount) break;
}
if (BitCount < 1 || BitCount >= 128) return Result;
return Result.Substring(0, BitCount);
}
Этот метод, как и многие другие, доступен в составе CPlaseEngine, ссылку на который можно найти в конце статьи.
В последствие мы расширили эту практику и на другие части нашей системы, и она показала себя с очень хорошей стороны. Хотя в некоторых случаях разделять на разделы выгоднее по идентификатору пользователя. Либо по части идентификатора пользователя. Это позволяет строить запросы для выбора данных, касающихся определенного пользователя. При этом запросы получаются эффективные в том плане, что выбирать приходится из одного раздела.
Практика выбора ключей для записей
Как можно было заметить ранее, часто ключ для записи связан с какой-нибудь датой. Чаще всего датой создания. В нашей системе это встречается очень часто. И это очень эффективно для записей, из которых после требуется получить список начиная с какой-нибудь даты.
Естественно, ключ записи должен быть уникальным. Эта уникальность должна быть для пары «ключ раздела»-«ключ записи». Поэтому при генерации ключа безопасней всего добавить к нему несколько случайных символов.
Если вы планируете выбирать записи в виде списков, то общая рекомендациея для генерации ключа записи – связывать его с параметром, относительно которого вы будете строить список. Так, например, если вы строите список значений по датам – то лучше всего использовать дату при генерации ключа.
Распространение и обобщение
Практика разделения по хешу ключа может применяться не только в отношении Table Storage. Она очень хорошо распространяется и на файловую систему. При кешировании сущностей из Table Storage в кеш на экземпляре мы также используем разделение по хешу от пути файла.
Горизонтальное масштабирование тесно связано с разделением данных и чем эффективнее вы будете разделять данные – тем эффективнее будет работать система в целом. Windows Azure как платформа дает очень мощную инфраструктуру для построения надежных, масштабируемых, отказоустойчивых сервисов. Но при этом не стоит забывать о том, что для построения таких сервисов внутренняя архитектура должна соотвествовать принципам построения высоконагруженных систем.
Также я с радостью хочу сообщить, что в открытом доступе на CodePlex появился наш OpenSource проект CPlaseEngine. В нем собраны инструменты, которые позволят разрабатывать сервисы на платформе Windows Azure более эффективно. Скачать его можно по адресу https://cplaseengine.codeplex.com/.
Читайте в серии:
- «AtContent.com. Внутреннее устройство и архитектура»,
- «Механизм обмена сообщениями между ролями и экземплярами»,
- «Кэширование данных на экземпляре и управление кешированием»,
- «Эффективное управление облачными очередями (Azure Queue)»,
- «Расширения LINQ для Azure Table Storage, реализующие операции Or и Contains».
