Всем привет. На этой неделе в курсе по машинному обучению профессор Andrew Ng рассказал слушателям про метод главных компонент, с помощью которого можно уменьшить размерность пространства признаков ваших данных. Но к сожалению он не рассказал про метод вычисления собственных векторов и собственных чисел матрицы, просто сказал, что это сложно и посоветовал использовать матлаб/октавовскую функцию [U S V] = svd(a).
Для моего проекта мне понадобилась реализация этого метода на c#, чем я сегодня и занимался. Сам метод главных компонент очень элегантный и красивый, а если не понимать математику которая лежит за всем этим, то это можно это все назвать шаманством. Проблема вычисления собственных векторов матрицы в том, что не существует быстрого способа вычисления их точных значений, так что приходится выкручиваться. Я хочу рассказать об одном из таких способов выкрутиться, а так же приведу код на c# выполняющий эту процедуру. Прошу под кат.
Часть первая: инициализация алгоритма. На вход алгоритму подается массив данных, а так же размерность пространства, до которой необходимо уменьшить данные.
Часть вторая: уменьшение размерности входного вектора. На вход подается вектор, размерности как и в массиве данных, использованном на шаге инициализации; на выходе вектор меньшей размерности (или проекция входного вектора на ортонормированный базис образованный выборкой из собственных векторов).
Часть третья: восстановление размерность вектора (конечно же с потерей информации). На вход подается вектор размерности равной той, до которой мы уменьшали векторы; на выходе вектор исходной размерности.
Как видно вся вычислительная сложность находится в шаге инициализации при вычислении матрицы ковариации и собственных векторов. На вычислении ковариационной матрицы я не буду останавливаться, т.к. она вычисляется наивно по определению. Изучив несколько алгоритмов вычисления собственных векторов матрицы я остановился на итеративном методе QR декомпозиции. У него есть существенно ограничение, он выдает более менее точный результат только для симметричных матриц, но нам повезло :), матрица ковариации как раз именно такая. Вторым ограничение этого алгоритма является то, что матрица должна быть полноранговой.
Итеративный QR метод поиска собственных векторов, очевидно использует QR разложение, так что для начала придется реализовать этот процесс. Для реализации этого процесса был выбран алгоритм Грэма-Шмидта.
Для этого нам понадобится функция, которая вычисляет проекцию вектора a на вектор b: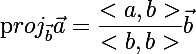 , где <> — обозначают скалярное произведение векторов.
, где <> — обозначают скалярное произведение векторов.
Я не буду останавливаться на еще более простых функциях, типа ScalarVectorProduct, для того что бы размер кода в тексте не превысил критическую норму.
Итак собственно сама процедура QR разложения IList<double[]> DecompositionGS(double[][] a) получает на вход матрицу, и выдает в ответ две матрицы:
Первым делом мы разбиваем матрицу на столбцы и записываем их в список av:
Инициализируем два вспомогательных списка:
Это те самые одноименные списки, использующиеся на схеме алгоритма:
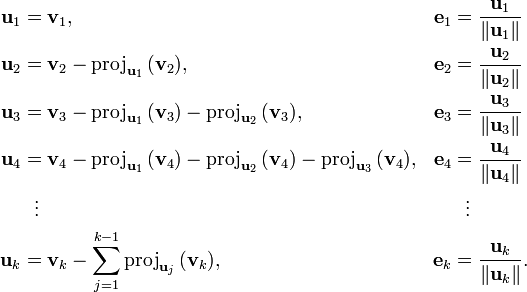
После инициализации, первые u и e у нас вычислены, продолжаем в цикле вычислять последующие значения:
И наконец формируем данные в выходном формате:
Ура! Теперь для этого нужен тест:
Функция Helper.AreEqualMatrices сравнивает поэлементно матрицы с точностью до третьего параметра.
Итеративный QR метод основан на замечательной теореме, суть которой в том, что если инициализировать матрицу А ноль как и повторять следующий процесс бесконечно много раз:
и повторять следующий процесс бесконечно много раз:
а затем перемножить все полученные Q, то в результате получится матрица, в колонках которой будут собственные вектора исходной матрицы, значения которых будут тем точнее, чем дольше выполнялся процесс. Другими словами, при стремлении количества итераций к бесконечности, произведение будет стремиться к точным значениям собственных векторов. В то же время последняя
будет стремиться к точным значениям собственных векторов. В то же время последняя  будет на главной диагонали содержать собственные числа матрицы, приближенные конечно. Напоминаю что этот алгоритм более менее точно работает только для симметричных матриц.
будет на главной диагонали содержать собственные числа матрицы, приближенные конечно. Напоминаю что этот алгоритм более менее точно работает только для симметричных матриц.
Итак, метод QR итерации IList<double[][]> EigenVectorValuesExtractionQRIterative(double[][] a, double accuracy, int maxIterations) получает на вход по мимо самой матрицы, так же еще несколько параметров:
На выходе получаем две матрицы:
Итак начнем писать алгоритм, для начала создадим матрицы, которые будут содержать собственные векторы и собственные значения исходной матрицы:
И запустим цикл до остановки алгоритма:
Сформируем выходные данные:
И конечно же тест:
Стоит отметить, что собственные векторы могут менять направление от итерации к итерации, что будет видно по смене знаков их координат, но очевидно, что это не существенно.
Теперь все готово для имплементации сабжа статьи.
Скрытым параметром модели (класса) будет являться некоторое подмножество собственных векторов матрицы ковариации от исходных данных:
Конструктор принимает на вход массив данных и размерность, до которой следует уменьшить пространство признаков, а так же параметры для QR декомпозиции. Внутри вычисляется матрица ковариации и берутся первые несколько собственных векторов. Вообще существует способ выбрать оптимальное количество собственных векторов для нужного параметра потери информации, т.е. до какой размерности можно уменьшить пространство, потеряв при этом не более фиксированного процента информации, но я этот шаг опускаю, про него можно послушать в лекции Andrew Ng на сайте курса.
Затем реализуем прямое и обратное преобразование по формулам из начала статьи.
Для тестирования придумаем небольшой массив данных, и проверяя на матлабе значения (используя код из домашки по PCA =), напишем класс для тестирования:
Для моего проекта мне понадобилась реализация этого метода на c#, чем я сегодня и занимался. Сам метод главных компонент очень элегантный и красивый, а если не понимать математику которая лежит за всем этим, то это можно это все назвать шаманством. Проблема вычисления собственных векторов матрицы в том, что не существует быстрого способа вычисления их точных значений, так что приходится выкручиваться. Я хочу рассказать об одном из таких способов выкрутиться, а так же приведу код на c# выполняющий эту процедуру. Прошу под кат.
Метод главных компонент (пока без кода)
Часть первая: инициализация алгоритма. На вход алгоритму подается массив данных, а так же размерность пространства, до которой необходимо уменьшить данные.
- Вычисляется ковариационная матрица (у этой матрицы есть замечательное свойство — она симметричная, это нам очень пригодится)
- Вычисляются собственные вектора матрицы
- Выбираются первые эн собственных векторов, где эн это та самая размерность, до которой нужно уменьшить размерность пространства признаков; выбранные векторы можно записать вертикально и собрать в матрицу
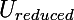
Часть вторая: уменьшение размерности входного вектора. На вход подается вектор, размерности как и в массиве данных, использованном на шаге инициализации; на выходе вектор меньшей размерности (или проекция входного вектора на ортонормированный базис образованный выборкой из собственных векторов).
- Умножив скалярно входной вектор на все вектора из выборки собственных векторов, получается уменьшенный вектор:
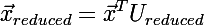
Часть третья: восстановление размерность вектора (конечно же с потерей информации). На вход подается вектор размерности равной той, до которой мы уменьшали векторы; на выходе вектор исходной размерности.
- Если транспонировать матрицу то в ней окажется столько же строк как и размерность входного вектора на предыдущем шаге, а искомый вектор восстанавливается по формуле:
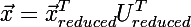
Как видно вся вычислительная сложность находится в шаге инициализации при вычислении матрицы ковариации и собственных векторов. На вычислении ковариационной матрицы я не буду останавливаться, т.к. она вычисляется наивно по определению. Изучив несколько алгоритмов вычисления собственных векторов матрицы я остановился на итеративном методе QR декомпозиции. У него есть существенно ограничение, он выдает более менее точный результат только для симметричных матриц, но нам повезло :), матрица ковариации как раз именно такая. Вторым ограничение этого алгоритма является то, что матрица должна быть полноранговой.
QR декомпозиция
Итеративный QR метод поиска собственных векторов, очевидно использует QR разложение, так что для начала придется реализовать этот процесс. Для реализации этого процесса был выбран алгоритм Грэма-Шмидта.
Для этого нам понадобится функция, которая вычисляет проекцию вектора a на вектор b:
, где <> — обозначают скалярное произведение векторов.public static double[] VectorProjection(double[] a, double[] b)
{
double k = ScalarVectorProduct(a, b)/ScalarVectorProduct(b, b);
return ScalarToVectorProduct(k, b);
}
Я не буду останавливаться на еще более простых функциях, типа ScalarVectorProduct, для того что бы размер кода в тексте не превысил критическую норму.
Итак собственно сама процедура QR разложения IList<double[]> DecompositionGS(double[][] a) получает на вход матрицу, и выдает в ответ две матрицы:
- первая содержит в своих колонках ортонормированный базис, такой что
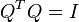 ;
; - вторая матрица будет верхней треугольной.
Первым делом мы разбиваем матрицу на столбцы и записываем их в список av:
List<double[]> av = new List<double[]>();
foreach (double[] vector in DecomposeMatrixToColumnVectors(a))
{
av.Add(vector);
}
Инициализируем два вспомогательных списка:
List<double[]> u = new List<double[]>();
u.Add(av[0]);
List<double[]> e = new List<double[]>();
e.Add(ScalarToVectorProduct(1 / NormOfVector(u[0]), u[0]));
Это те самые одноименные списки, использующиеся на схеме алгоритма:
После инициализации, первые u и e у нас вычислены, продолжаем в цикле вычислять последующие значения:
for (int i = 1; i < a.Length; i++)
{
double[] projAcc = new double[a.Length];
for (int j = 0; j < projAcc.Length; j++)
{
projAcc[j] = 0;
}
for (int j = 0; j < i; j++)
{
double[] proj = VectorProjection(av[i], e[j]);
for (int k = 0; k < projAcc.Length; k++)
{
projAcc[k] += proj[k];
}
}
double[] ui = new double[a.Length];
for (int j = 0; j < ui.Length; j++)
{
ui[j] = a[j][i] - projAcc[j];
}
u.Add(ui);
e.Add(ScalarToVectorProduct(1/NormOfVector(u[i]), u[i]));
}
И наконец формируем данные в выходном формате:
double[][] q = new double[a.Length][];
for (int i = 0; i < q.Length; i++)
{
q[i] = new double[a.Length];
for (int j = 0; j < q[i].Length; j++)
{
q[i][j] = e[j][i];
}
}
double[][] r = new double[a.Length][];
for (int i = 0; i < r.Length; i++)
{
r[i] = new double[a.Length];
for (int j = 0; j < r[i].Length; j++)
{
if (i >= j)
{
r[i][j] = ScalarVectorProduct(e[j], av[i]);
}
else {
r[i][j] = 0;
}
}
}
r = Transpose(r);
List<double[][]> res = new List<double[][]>();
res.Add(q);
res.Add(r);
return res;
Ура! Теперь для этого нужен тест:
[Test(Description = "Test of QRDecompositionGS")]
public void QRDecompositionGSTest()
{
double[][] a = new double[][]
{
new double[] {12, -51, 4},
new double[] {6, 167, -68},
new double[] {-4, 24, -41}
};
IList<double[][]> res = LinearAlgebra.QRDecompositionGS(a);
double[][] expQ = new double[][]
{
new double[] {6.0/7, -69.0/175, -58.0/175},
new double[] {3.0/7, 158.0/175, 6.0/175},
new double[] {-2.0/7, 6.0/35, -33.0/35}
};
double[][] expR = new double[][]
{
new double[] {14, 21, -14},
new double[] {0, 175, -70},
new double[] {0, 0, 35}
};
Assert.True(Helper.AreEqualMatrices(expQ, res[0], 0.0001), "expQ != Q");
Assert.True(Helper.AreEqualMatrices(expR, res[1], 0.0001), "expR != R");
}
Функция Helper.AreEqualMatrices сравнивает поэлементно матрицы с точностью до третьего параметра.
Итеративный QR метод
Итеративный QR метод основан на замечательной теореме, суть которой в том, что если инициализировать матрицу А ноль как
а затем перемножить все полученные Q, то в результате получится матрица, в колонках которой будут собственные вектора исходной матрицы, значения которых будут тем точнее, чем дольше выполнялся процесс. Другими словами, при стремлении количества итераций к бесконечности, произведение
Итак, метод QR итерации IList<double[][]> EigenVectorValuesExtractionQRIterative(double[][] a, double accuracy, int maxIterations) получает на вход по мимо самой матрицы, так же еще несколько параметров:
- double accuracy — точность которой мы хотим достичь, алгоритм остановится если изменения в значениях собственных векторов будут не более чем это значение;
- int maxIterations — максимальное количество итераций.
На выходе получаем две матрицы:
- первая содержит в своих колонках собственные векторы матрицы a;
- вторая матрица на своей главной диагонали содержит собственные значения матрицы a.
Итак начнем писать алгоритм, для начала создадим матрицы, которые будут содержать собственные векторы и собственные значения исходной матрицы:
double[][] aItr = a;
double[][] q = null;
И запустим цикл до остановки алгоритма:
for (int i = 0; i < maxIterations; i++)
{
IList<double[][]> qr = QRDecompositionGS(aItr);
aItr = MatricesProduct(qr[1], qr[0]);
if (q == null)
{
q = qr[0];
}
else {
double[][] qNew = MatricesProduct(q, qr[0]);
bool accuracyAcheived = true;
for (int n = 0; n < q.Length; n++)
{
for (int m = 0; m < q[n].Length; m++)
{
if (Math.Abs(Math.Abs(qNew[n][m]) - Math.Abs(q[n][m])) > accuracy)
{
accuracyAcheived = false;
break;
}
}
if (!accuracyAcheived)
{
break;
}
}
q = qNew;
if (accuracyAcheived)
{
break;
}
}
}
Сформируем выходные данные:
List<double[][]> res = new List<double[][]>();
res.Add(q);
res.Add(aItr);
return res;
И конечно же тест:
[Test(Description = "Test of Eigen vectors extraction")]
public void EigenVectorExtraction()
{
double[][] a = new double[][]
{
new double[] {1, 2, 4},
new double[] {2, 9, 8},
new double[] {4, 8, 2}
};
IList<double[][]> ev = LinearAlgebra.EigenVectorValuesExtractionQRIterative(a, 0.001, 1000);
double expEV00 = 15.2964;
double expEV11 = 4.3487;
double expEV22 = 1.0523;
Assert.AreEqual(expEV00, Math.Round(Math.Abs(ev[1][0][0]), 4));
Assert.AreEqual(expEV11, Math.Round(Math.Abs(ev[1][1][1]), 4));
Assert.AreEqual(expEV22, Math.Round(Math.Abs(ev[1][2][2]), 4));
}
Стоит отметить, что собственные векторы могут менять направление от итерации к итерации, что будет видно по смене знаков их координат, но очевидно, что это не существенно.
Реализация метода главных компонент
Теперь все готово для имплементации сабжа статьи.
Скрытым параметром модели (класса) будет являться некоторое подмножество собственных векторов матрицы ковариации от исходных данных:
private IList<double[]> _eigenVectors = null;
Конструктор принимает на вход массив данных и размерность, до которой следует уменьшить пространство признаков, а так же параметры для QR декомпозиции. Внутри вычисляется матрица ковариации и берутся первые несколько собственных векторов. Вообще существует способ выбрать оптимальное количество собственных векторов для нужного параметра потери информации, т.е. до какой размерности можно уменьшить пространство, потеряв при этом не более фиксированного процента информации, но я этот шаг опускаю, про него можно послушать в лекции Andrew Ng на сайте курса.
internal DimensionalityReductionPCA(IList<double[]> dataSet, double accuracyQR, int maxIterationQR, int componentsNumber)
{
double[][] cov = BasicStatFunctions.CovarianceMatrixOfData(dataSet);
IList<double[][]> eigen = LinearAlgebra.EigenVectorValuesExtractionQRIterative(cov, accuracyQR, maxIterationQR);
IList<double[]> eigenVectors = LinearAlgebra.DecomposeMatrixToColumnVectors(eigen[0]);
if (componentsNumber > eigenVectors.Count)
{
throw new ArgumentException("componentsNumber > eigenVectors.Count");
}
_eigenVectors = new List<double[]>();
for (int i = 0; i < componentsNumber; i++)
{
_eigenVectors.Add(eigenVectors[i]);
}
}
Затем реализуем прямое и обратное преобразование по формулам из начала статьи.
public double[] Transform(double[] dataItem)
{
if (_eigenVectors[0].Length != dataItem.Length)
{
throw new ArgumentException("_eigenVectors[0].Length != dataItem.Length");
}
double[] res = new double[_eigenVectors.Count];
for (int i = 0; i < _eigenVectors.Count; i++)
{
res[i] = 0;
for (int j = 0; j < dataItem.Length; j++)
{
res[i] += _eigenVectors[i][j]*dataItem[j];
}
}
return res;
}
public double[] Reconstruct(double[] transformedDataItem)
{
if (_eigenVectors.Count != transformedDataItem.Length)
{
throw new ArgumentException("_eigenVectors.Count != transformedDataItem.Length");
}
double[] res = new double[_eigenVectors[0].Length];
for (int i = 0; i < res.Length; i++)
{
res[i] = 0;
for (int j = 0; j < _eigenVectors.Count; j++)
{
res[i] += _eigenVectors[j][i]*transformedDataItem[j];
}
}
return res;
}
Тестирование
Для тестирования придумаем небольшой массив данных, и проверяя на матлабе значения (используя код из домашки по PCA =), напишем класс для тестирования:
[TestFixture(Description = "Test of DimensionalityReductionPCA")]
public class DimensionalityReductionPCATest
{
private IList<double[]> _data = null;
private IDataTransformation<double[]> _transformation = null;
private double[] _v = null;
[SetUp]
public void SetUp()
{
_v = new double[] { 1, 0, 3 };
_data = new List<double[]>()
{
new double[] {1, 2, 23},
new double[] {-3, 17, 5},
new double[] {13, -6, 7},
new double[] {7, 8, -9}
};
_transformation = new DimensionalityReductionPCA(_data, 0.0001, 1000, 2);
}
[Test(Description = "Test of DimensionalityReductionPCA transform")]
public void DimensionalityReductionPCATransformTest()
{
double[] reduced = _transformation.Transform(_v);
double[] expReduced = new double[] {-2.75008, 0.19959};
Assert.IsTrue(Helper.AreEqualVectors(expReduced, reduced, 0.001));
double[] reconstructed = _transformation.Reconstruct(reduced);
double[] expReconstructed = new double[] {-0.21218, -0.87852, 2.60499};
Assert.IsTrue(Helper.AreEqualVectors(expReconstructed, reconstructed, 0.001));
}
Ссылки
- курс по machine learning
- статья в которой описан итеративный QR метод
- куча ссылок на википедию в тексте статьи
