Всем привет. Продолжая тему того, что Andrew Ng не успел рассказать в курсе по машинному обучению, приведу пример своей реализации алгоритма k-средних. У меня стояла задача реализовать алгоритм кластеризации, но мне необходимо было учитывать степень корреляции между величинами. Я решил использовать в качестве метрики расстояние Махаланобиса, замечу, что размер данных для кластеризации не так велик, и не было необходимости делать кэширование кластеров на диск. За реализацией прошу под кат.
Для начала рассмотрим, в чем проблема, почему бы просто не заменить Евклидово расстояние на любую другую метрику. Алгоритму k-средних на вход подается два параметра: данные для кластеризации и количество кластеров, на которые необходимо разбить данные. Алгоритм состоит из следующих шагов.
Для вникания в математику, которая находится за этим простым алгоритмом, советую почитать статьи по Байесовой кластеризации и алгоритму expectation-maximization.
Проблема замены Евклидова расстояния на другую метрику заключается в М-шаге. Например, если у нас текстовые данные и в качестве метрики используется расстояние Левенштейна, то найти среднее значение это не совсем тривиальная задача. Для меня даже найти среднее по Махаланобису оказалось не быстро решаемой задачей, но мне повезло и я наткнулся на статью, в которой описан очень простой способ выбора «центроида», и мне не пришлось ломать голову над средним значением по Махаланобису. В кавычках потому, что не ищется точное значение центроида, а выбирается его приближенное значение, которое в той статье называют кластеройд (или по аналогии с k-medoids можно назвать медоидом). Таким образом, шаг максимизации заменяется следующим алгоритмом.
Кстати, для меня вопрос сходимости пока открыт, но благо существует много способов остановить алгоритм на некотором субоптимальном решении. В данной реализации мы будем останавливать алгоритм, если функция стоимости начинает расти.
Функцией стоимости для текущего разбиения будет использоваться следующая формула: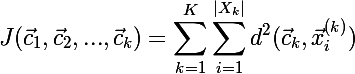 , где K — это количество кластеров,
, где K — это количество кластеров, 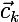 — текущий центр кластера,
— текущий центр кластера,  — множество элементов, отнесенных к кластеру k, а
— множество элементов, отнесенных к кластеру k, а  — i-й элемент кластера k.
— i-й элемент кластера k.
Насчет поиска среднего расстояния стоит отметить, что если функция метрики непрерывна и дифференцируема, то для поиска кластероида можно использовать алгоритм градиентного спуска, который минимизирует следующую функцию стоимости: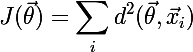 , где иксы — это элементы, отнесенные к текущему кластеру. Я планирую рассмотреть этот вариант в следующей статье, а пока в реализации мы учтем, что в скором времени для некоторых метрик будет добавлен свой способ поиска центроида/кластероида.
, где иксы — это элементы, отнесенные к текущему кластеру. Я планирую рассмотреть этот вариант в следующей статье, а пока в реализации мы учтем, что в скором времени для некоторых метрик будет добавлен свой способ поиска центроида/кластероида.
Для начала давайте создадим общее представление метрики и затем имплементируем общую логику и конкретную реализацию нескольких метрик.
Таким образом, метрика абстрагирована от типа данных и мы сможем реализовать ее как Евклидово расстояние между числовыми векторами, так и расстояние Левенштейна между строками и предложениями.
Теперь создадим базовый класс для метрик, в котором имплементируем функцию поиска кластероида простым методом, описанным выше.
В методе GetCentroid мы ищем элемент, для которого сумма квадратов расстояний до остальных элементов данных минимальна. Сперва составляем симметричную матрицу, в которой в элементах находятся расстояния между соответствующими элементами данных. Используя свойства метрик: d(x, x) = 0 и d(x, y) = d(y, x), мы можем смело заполнить диагональ нулями и отразить матрицу по главной диагонали. Затем суммируем по строкам и ищем минимальное значение.
Для примера давайте создадим реализацию расстояний Махаланобиса и Евклида.
Как видно из кода, метод GetCentroid не переопределен, хотя в следующей статье я попробую переопределить этот метод алгоритмом градиентного спуска.
В реализации расстояния Евклида, метод GetCentroid переопределен, и ищет точное значение центроида: вычисляются средние значения каждой из координат.
Перейдем к имплементации алгоритма кластеризации. Опять же, вначале создадим интерфейс для алгоритмов кластеризации.
Где результат кластеризации выглядит следующим образом:
И класс элемента данных:
Нам интересно только свойство Input, т.к. это обучение без учителя.
Перейдем к реализации алгоритма k-means, используя вышеупомянутые интерфейсы.
На вход алгоритму кластеризации подаются следующие данные (я немного сократил свой код, чтобы не заморачиваться на способах инициализации начальных центроидов, мы будем использовать случайную инициализацию точек, мы можем себе это здесь позволить, т.к. мы кластеризуем числовые данные
Проблема
Для начала рассмотрим, в чем проблема, почему бы просто не заменить Евклидово расстояние на любую другую метрику. Алгоритму k-средних на вход подается два параметра: данные для кластеризации и количество кластеров, на которые необходимо разбить данные. Алгоритм состоит из следующих шагов.
- Начальная инициализация центроидов кластеров каким-либо способом (например, можно задать начальные значения случайно выбранными точками из пространства, в котором определены данные; можно выбрать случайные точки из входного массива данных и т.д.).
- E-шаг (expectation): происходит ассоциация между элементами данных и кластерами, которые представлены в виде своих центров (центроидами).
- M-шаг (maximization): пересчитываются центры кластеров, как средние значения от данных, которые были включены с соответствующий кластер (или, другими словами, происходит модификация параметров модели таким образом, чтобы максимизировать вероятность попадания элемента в выбранный кластер). В случае, если кластер после шага 2 оказался пустым, то происходит переинициализация каким-либо другим способом.
- Шаги 2-3 повторяются до сходимости, либо пока не будет достигнут другой критерий остановки алгоритма (например, если превышается некоторое количество итераций).
Для вникания в математику, которая находится за этим простым алгоритмом, советую почитать статьи по Байесовой кластеризации и алгоритму expectation-maximization.
Проблема замены Евклидова расстояния на другую метрику заключается в М-шаге. Например, если у нас текстовые данные и в качестве метрики используется расстояние Левенштейна, то найти среднее значение это не совсем тривиальная задача. Для меня даже найти среднее по Махаланобису оказалось не быстро решаемой задачей, но мне повезло и я наткнулся на статью, в которой описан очень простой способ выбора «центроида», и мне не пришлось ломать голову над средним значением по Махаланобису. В кавычках потому, что не ищется точное значение центроида, а выбирается его приближенное значение, которое в той статье называют кластеройд (или по аналогии с k-medoids можно назвать медоидом). Таким образом, шаг максимизации заменяется следующим алгоритмом.
- M-шаг: среди всех элементов данных, которые были отнесены к центроиду, выбирается тот элемент, для которого сумма расстояний до всех остальных элементов кластера минимальна; этот элемент становится новым центром кластера.
Кстати, для меня вопрос сходимости пока открыт, но благо существует много способов остановить алгоритм на некотором субоптимальном решении. В данной реализации мы будем останавливать алгоритм, если функция стоимости начинает расти.
Функцией стоимости для текущего разбиения будет использоваться следующая формула:
, где K — это количество кластеров, — текущий центр кластера, — множество элементов, отнесенных к кластеру k, а — i-й элемент кластера k.Насчет поиска среднего расстояния стоит отметить, что если функция метрики непрерывна и дифференцируема, то для поиска кластероида можно использовать алгоритм градиентного спуска, который минимизирует следующую функцию стоимости:
, где иксы — это элементы, отнесенные к текущему кластеру. Я планирую рассмотреть этот вариант в следующей статье, а пока в реализации мы учтем, что в скором времени для некоторых метрик будет добавлен свой способ поиска центроида/кластероида.Метрики
Для начала давайте создадим общее представление метрики и затем имплементируем общую логику и конкретную реализацию нескольких метрик.
public interface IMetrics<T>
{
double Calculate(T[] v1, T[] v2);
T[] GetCentroid(IList<T[]> data);
}
Таким образом, метрика абстрагирована от типа данных и мы сможем реализовать ее как Евклидово расстояние между числовыми векторами, так и расстояние Левенштейна между строками и предложениями.
Теперь создадим базовый класс для метрик, в котором имплементируем функцию поиска кластероида простым методом, описанным выше.
public abstract class MetricsBase<T> : IMetrics<T>
{
public abstract double Calculate(T[] v1, T[] v2);
public virtual T[] GetCentroid(IList<T[]> data)
{
if (data == null)
{
throw new ArgumentException("Data is null");
}
if (data.Count == 0)
{
throw new ArgumentException("Data is empty");
}
double[][] dist = new double[data.Count][];
for (int i = 0; i < data.Count - 1; i++)
{
dist[i] = new double[data.Count];
for (int j = i; j < data.Count; j++)
{
if (i == j)
{
dist[i][j] = 0;
}
else
{
dist[i][j] = Math.Pow(Calculate(data[i], data[j]), 2);
if (dist[j] == null)
{
dist[j] = new double[data.Count];
}
dist[j][i] = dist[i][j];
}
}
}
double minSum = Double.PositiveInfinity;
int bestIdx = -1;
for (int i = 0; i < data.Count; i++)
{
double dSum = 0;
for (int j = 0; j < data.Count; j++)
{
dSum += dist[i][j];
}
if (dSum < minSum)
{
minSum = dSum;
bestIdx = i;
}
}
return data[bestIdx];
}
}
В методе GetCentroid мы ищем элемент, для которого сумма квадратов расстояний до остальных элементов данных минимальна. Сперва составляем симметричную матрицу, в которой в элементах находятся расстояния между соответствующими элементами данных. Используя свойства метрик: d(x, x) = 0 и d(x, y) = d(y, x), мы можем смело заполнить диагональ нулями и отразить матрицу по главной диагонали. Затем суммируем по строкам и ищем минимальное значение.
Для примера давайте создадим реализацию расстояний Махаланобиса и Евклида.
internal class MahalanobisDistanse : MetricsBase<double>
{
private double[][] _covMatrixInv = null;
internal MahalanobisDistanse(double[][] covMatrix, bool isInversed)
{
if (!isInversed)
{
_covMatrixInv = LinearAlgebra.InverseMatrixGJ(covMatrix);
}
else
{
_covMatrixInv = covMatrix;
}
}
public override double Calculate(double[] v1, double[] v2)
{
if (v1.Length != v2.Length)
{
throw new ArgumentException("Vectors dimensions are not same");
}
if (v1.Length == 0 || v2.Length == 0)
{
throw new ArgumentException("Vector dimension can't be 0");
}
if (v1.Length != _covMatrixInv.Length)
{
throw new ArgumentException("CovMatrix and vectors have different size");
}
double[] delta = new double[v1.Length];
for (int i = 0; i < v1.Length; i++)
{
delta[i] = v1[i] - v2[i];
}
double[] deltaS = new double[v1.Length];
for (int i = 0; i < deltaS.Length; i++)
{
deltaS[i] = 0;
for (int j = 0; j < v1.Length; j++)
{
deltaS[i] += delta[j]*_covMatrixInv[j][i];
}
}
double d = 0;
for (int i = 0; i < v1.Length; i++)
{
d += deltaS[i]*delta[i];
}
d = Math.Sqrt(d);
return d;
}
}
Как видно из кода, метод GetCentroid не переопределен, хотя в следующей статье я попробую переопределить этот метод алгоритмом градиентного спуска.
internal class EuclideanDistance : MetricsBase<double>
{
internal EuclideanDistance()
{
}
#region IMetrics Members
public override double Calculate(double[] v1, double[] v2)
{
if (v1.Length != v2.Length)
{
throw new ArgumentException("Vectors dimensions are not same");
}
if (v1.Length == 0 || v2.Length == 0)
{
throw new ArgumentException("Vector dimension can't be 0");
}
double d = 0;
for (int i = 0; i < v1.Length; i++)
{
d += (v1[i] - v2[i]) * (v1[i] - v2[i]);
}
return Math.Sqrt(d);
}
public override double[] GetCentroid(IList<double[]> data)
{
if (data.Count == 0)
{
throw new ArgumentException("Data is empty");
}
double[] mean = new double[data.First().Length];
for (int i = 0; i < mean.Length; i++)
{
mean[i] = 0;
}
foreach (double[] item in data)
{
for (int i = 0; i < item.Length; i++)
{
mean[i] += item[i];
}
}
for (int i = 0; i < mean.Length; i++)
{
mean[i] = mean[i]/data.Count;
}
return mean;
}
#endregion
}
В реализации расстояния Евклида, метод GetCentroid переопределен, и ищет точное значение центроида: вычисляются средние значения каждой из координат.
Кластеризация
Перейдем к имплементации алгоритма кластеризации. Опять же, вначале создадим интерфейс для алгоритмов кластеризации.
public interface IClusterization<T>
{
ClusterizationResult<T> MakeClusterization(IList<DataItem<T>> data);
}
Где результат кластеризации выглядит следующим образом:
public class ClusterizationResult<T>
{
public IList<T[]> Centroids { get; set; }
public IDictionary<T[], IList<DataItem<T>>> Clusterization { get; set; }
public double Cost { get; set; }
}
И класс элемента данных:
public class DataItem<T>
{
private T[] _input = null;
private T[] _output = null;
public DataItem(T[] input, T[] output)
{
_input = input;
_output = output;
}
public T[] Input
{
get { return _input; }
}
public T[] Output
{
get { return _output; }
set { _output = value; }
}
}
Нам интересно только свойство Input, т.к. это обучение без учителя.
Перейдем к реализации алгоритма k-means, используя вышеупомянутые интерфейсы.
internal class KMeans : IClusterization<double>
На вход алгоритму кластеризации подаются следующие данные (я немного сократил свой код, чтобы не заморачиваться на способах инициализации начальных центроидов, мы будем использовать случайную инициализацию точек, мы можем себе это здесь позволить, т.к. мы кластеризуем числовые данные
IClusterization):
- clusterCount - количество кластеров на которые необходимо разбить данные
IMetrics metrics - метрика для кластеризации
