Под стеком web-приложений мы будем подразумевать множество программных продуктов с открытым исходным кодом: операционная система, web -сервер, сервер БД и среду исполняемого кода. Наиболее известным и обыденным стеком является LAMP. Это акроним для стека web-приложений на базе бесплатных решений с открытым исходным кодом. Название составлено из первых букв входящего в его состав продуктов: Linux (операционная система), web -сервер Apache, база данных MySQL, и PHP (иногда Perl или Python). Опубликованные нами ранее материалы, посвященные вопросам безопасности, рекомендуют держать различные сетевые службы на выделенных под эти цели серверах или виртуальных машинах. Это позволит изолировать скомпрометированные и взломанные злоумышленником элементы системы, в случае если последний получит возможность эксплуатации ошибок в одном из звеньев сети обслуживания. Статья также является ответом на наиболее часто задаваемые нашими читателями вопросы, присланными нам по электронной почте. В руководстве я объясню, как построить решение на базе физических или виртуальных серверов, одинаково подходящих для раздачи статического и динамического контента, для приложений, требующих наличие БД и кэширования.
Что случится в случае если, скажем, будет скомпрометирован web-сервер Apache? Злоумышленник получит доступ к вашей базе данных, кэш-памяти и, так же, к другим элементам системы или сети. В таком случае вам необходимо разделить службы сервера следующим образом:
Дробная установка имеет целый ряд преимуществ:
Добавьте к этому продвинутые возможности из области High-availability, такие как failover (перенос образов/контейнеров дробных частей системы на другие ресурсы из-за начальной настройки хост-системы vm00 на подобное сетевое взаимодействие [Virtual-IP на уровне vm00]), балансировка нагрузки, CDN, становящиеся много удобнее в случае подобной настройки системы.

Давайте посмотрим, как работает наша система с реверс-прокси сервером. В этом примере я размещу прокси и HTTP сервера до брандмауэра. (см. рис. 1). Веб-сайт www.example.com будет размещаться по статическому IPv4-адреу 202.54.1.1, который закрепляется за устройством eth0. Внутренний IP 192.168.1.1 назначается устройству eth1. Это узел нашего реверс-прокси сервера. Остальные сервера — внутри локальной сети и не могут быть доступны напрямую через Интернет.
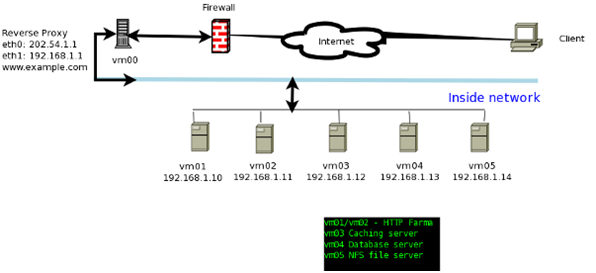
Правилами аппаратного или программного (OpenBSD/Linux) брандмауэра узла 202.54.1.1 разрешается доступ лишь к портам 80 и 443. Все остальные порты – заблокированы. На каждом узле VM также работают iptables и доступ разрешен только к необходимым портам. Ваш обратный прокси-сервер определяет пул HTTP-серверов следующим образом:
Apache и Lighttpd сервера получают доступ к файлам через NFS сервер, настроенный на vm05. Web-сервер Apache настроен для работы с PHP. Наши PHP приложение настроено для подключения к серверу БД, размещенному на vm04. Наше PHP приложение используют vm03 в качестве кеша SQL посредством использования Memcached сервера.
Примечание: Вы можете также поместить реверс-прокси сервер на DMZ, а HTTP и другие сервера – за брандмауэром для повышения безопасности. Но это увеличит стоимость проекта.
От переводчика:
Автор оригинального цикла статей на редкость немногословен и трудночитаем. Мы постараемся сохранить его лаконичность там, где это возможно и добавим разъяснений, где автор сам плохо понимает, что он хочет сказать. Перевод допускает ряд отступлений от принятых в профессиональной среде терминов и устойчивых выражений. Переводчик просит проявить снисхождение к подобным случаям в форме личных сообщений, если обнаруженное затрудняет понимание текста и обнажает невежественность писавшего.
LAMP: Типовая и дробная установки
Скорее всего, ваше решение, построенное на базе одного выделенного или виртуального сервера, выглядит следующим образом: Большой сервер / Виртуальная машина
+-----------------------------------------+
| Apache + PHP / Perl @ 75.126.153.206:80 |
| Mysql@127.0.0.1: 3306 (или UNIX сокета) |
| Pgsql@127.0.0.1: 5432 (или UNIX сокета) |
| Netfilter для фильтрации трафика |
+-----------------------------------------+
*** Выделенный LAMP сервер ***
ОС: RHEL/CentOS/Debian/Ubuntu/*BSD/Unix
Оперативная память: 4-8GiB ECC
Процессор: Один или два Intel / AMD
Хранилище: RAID-1/5 сервер-класса SATA/SAS
Что случится в случае если, скажем, будет скомпрометирован web-сервер Apache? Злоумышленник получит доступ к вашей базе данных, кэш-памяти и, так же, к другим элементам системы или сети. В таком случае вам необходимо разделить службы сервера следующим образом:
//////////////////////////
/ Интернет/маршрутизатор /
//////////////////////////
\
\
----------| vm00
75.126.153.206:80 - eth0
192.168.1.1 - eth1
+-----------------------------+
| Реверс-прокси |
| Межсетевой экран (Firewall) | eth0:192.168.1.10/vm01
+-----------------------------+ +----------------------+
| | Lighttpd |
+-----------------------------------+ статический контент |
| | /var/www/static |
| +----------------------+
|
| eth0:192.168.1.11/vm02
+-----------------------------------+-----------------------+
| | Apache+php+perl+python|
| | /var/www/html |
| +-----------------------+
|
| eth0:192.168.1.12/vm03
+-----------------------------------+-----------------------+
| |Кэш SQL БД |
| |Redis/Memcached и т.д. |
| +-----------------------+
|
| eth0:192.168.1.13/vm04
| (или выделенный сервер БД на шасси RAID-10)
+-----------------------------------+------------------------+
| | Mysql/pgsql сервер БД |
| | @192.168.1.13:3306/5432|
| +------------------------+
|
| eth0:192.168.1.14/vm05
| (или сервер-хранилище с доступом по NFSv4 на шасси RAID-10)
+-----------------------------------+------------------------+
| NFSv4 на Linux |
| /export/{static,html |
+------------------------+
Дробная установка имеет целый ряд преимуществ:
- Безопасность
- Масштабируемость
- Оптимизация
- Простота использования
- Простота мониторинга
Добавьте к этому продвинутые возможности из области High-availability, такие как failover (перенос образов/контейнеров дробных частей системы на другие ресурсы из-за начальной настройки хост-системы vm00 на подобное сетевое взаимодействие [Virtual-IP на уровне vm00]), балансировка нагрузки, CDN, становящиеся много удобнее в случае подобной настройки системы.
Роли каждой виртуальной машины / сервера:
Ниже приводится детальная информация о назначении машин. WordPress-блог, сайт на базе Drupal или же приложение «на заказ», размещенные на подобных серверах, могут легко обслуживать миллионы хитов в месяц.Как это работает?
Давайте посмотрим, как работает наша система с реверс-прокси сервером. В этом примере я размещу прокси и HTTP сервера до брандмауэра. (см. рис. 1). Веб-сайт www.example.com будет размещаться по статическому IPv4-адреу 202.54.1.1, который закрепляется за устройством eth0. Внутренний IP 192.168.1.1 назначается устройству eth1. Это узел нашего реверс-прокси сервера. Остальные сервера — внутри локальной сети и не могут быть доступны напрямую через Интернет.
Правилами аппаратного или программного (OpenBSD/Linux) брандмауэра узла 202.54.1.1 разрешается доступ лишь к портам 80 и 443. Все остальные порты – заблокированы. На каждом узле VM также работают iptables и доступ разрешен только к необходимым портам. Ваш обратный прокси-сервер определяет пул HTTP-серверов следующим образом:
## апстрим-канал www.example.com ##
upstream mybackend {
server 192.168.1.10:80; #server1
server 192.168.1.11:80; #server2
....
..
..
server 192.168.1.100:80; # server100
}
Apache и Lighttpd сервера получают доступ к файлам через NFS сервер, настроенный на vm05. Web-сервер Apache настроен для работы с PHP. Наши PHP приложение настроено для подключения к серверу БД, размещенному на vm04. Наше PHP приложение используют vm03 в качестве кеша SQL посредством использования Memcached сервера.
Примечание: Вы можете также поместить реверс-прокси сервер на DMZ, а HTTP и другие сервера – за брандмауэром для повышения безопасности. Но это увеличит стоимость проекта.
Хватит говорить, покажи мне процесс настройки серверов
Большинство перечисленных в этой заметке действий, пишутся с предположением, что они будут выполнены root-пользователем в bash-консоли CentOS 6.x/Red Hat Enterprise Linux 6.x. Тем не менее, вы можете легко копировать настройки на любой другой *NIX подобные операционные системы.- Вводная часть
- Шаг №1: Настройка / Установка: NFS файловый сервер
- Шаг №2: Настройка / установка: сервер баз данных MySQL
- Шаг №3: Настройка / Установка: Memcached сервера кэширования
- Шаг №4: Настройка / Установка: Apache + php5 приложение веб-сервера
- Шаг №5: Настройка / Установка: веб-сервер Lighttpd для статических активов</a
Шаг №6: Настройка / Установка: Nginx обратный (reverse) прокси-сервер
