Comments 43
Поправьте меня меня если я не прав
Так как фильтр Гауса является сепарабельным то количество операций на точку (при реализации горизонтальный +вертикальный проходы) не будет превышать O(r*2) (умножить) ценой 2x памяти.
Так как фильтр Гауса является сепарабельным то количество операций на точку (при реализации горизонтальный +вертикальный проходы) не будет превышать O(r*2) (умножить) ценой 2x памяти.
Во-первых, O® это тоже самое, что O(r*2). Это — для расчёта FIR фильтром.
В описанном методе идёт O(1) для изображения фиксированого размера.
Память нужна на источник, промежуточный буфер хранения, и приёмник. Если источник не нужен, или совпадает с приёмником, можно писать туда же.
Если очень большое изображение и очень дорога память, можно размывать кусочками, но ценой лишних вычислений.
В описанном методе идёт O(1) для изображения фиксированого размера.
Память нужна на источник, промежуточный буфер хранения, и приёмник. Если источник не нужен, или совпадает с приёмником, можно писать туда же.
Если очень большое изображение и очень дорога память, можно размывать кусочками, но ценой лишних вычислений.
Про O(..) само собой — я просто хотел явно указать что не O(r^2)
Память нужна ровно 2x если не нужно исходное изображение.
Память нужна ровно 2x если не нужно исходное изображение.
Ну да, но если считать просто свёртку лобовым методом, то память тоже нужна 2x
Про сепарабельность еще:
В общем данный способ всегда используют в гейм деве для размытия.
Гоняются данные с нужным кернелом между 2умя текстурами.
В общем данный способ всегда используют в гейм деве для размытия.
Гоняются данные с нужным кернелом между 2умя текстурами.
Некоторое время назад мы тоже были озабочены похожей оптимизацией для размытия в играх — но из за того, что алгоритм требует чтения и записи данных из одного и того же источника нам это не подошло.
А почему нельзя читать и записывать из одного и того же источника?
Результат при чтении и записи данных в одну и туже текстуру не определен.
Коротко о причине:
Из за кэшов на чтение/запись и затраты на их синхронизацию.
Коротко о причине:
Из за кэшов на чтение/запись и затраты на их синхронизацию.
Это что за архитектура? Насколько я понял, рассчёт на видеокартах идёт?
И да, почему нельзя записывать в цикле y[i-3], а все промежуточные y держать в регистре каком-нибудь?
И да, почему нельзя записывать в цикле y[i-3], а все промежуточные y держать в регистре каком-нибудь?
На GPU.
На GPU эти подпрограммы (шейдера) выполняются параллельно для каждого пиксела без какой либо связи с другим пикселами — именно по этому на регистрах не получится так как единственная связь между вызовами программы для каждого пикселя это источники данных (текстуры)
На GPU эти подпрограммы (шейдера) выполняются параллельно для каждого пиксела без какой либо связи с другим пикселами — именно по этому на регистрах не получится так как единственная связь между вызовами программы для каждого пикселя это источники данных (текстуры)
Ну я немного знаком с GPU, и по прежнему не понимаю, в чём проблема.
Пусть каждая нить фильтрует свою строку. Они гарантировано не будут писать в одно место (и читать из одного места тоже не будут, но это не важно, как я понимаю).
То, что вам нужно получать y как результат — ну не храните его в памяти. На момент расчёта y4 вам уже не нужен будет y0, и его можно писать в память.
Ну да, вам придётся отфильтровать текстуру 4 раза. Но сбросить весь кэш можно же между проходами, верно?
Пусть каждая нить фильтрует свою строку. Они гарантировано не будут писать в одно место (и читать из одного места тоже не будут, но это не важно, как я понимаю).
То, что вам нужно получать y как результат — ну не храните его в памяти. На момент расчёта y4 вам уже не нужен будет y0, и его можно писать в память.
Ну да, вам придётся отфильтровать текстуру 4 раза. Но сбросить весь кэш можно же между проходами, верно?
Более того — никто не гарантирует что пиксель (0,1) будет рендерится сразу после (0,0)
Так что даже если бы поддерживалась возможность чтения записи из одного источника данных то ничего не работало бы
Так что даже если бы поддерживалась возможность чтения записи из одного источника данных то ничего не работало бы
В общем — при повторном чтении уже нашел про сепарабельность фильтра в статье — так что мой первый комментарии можно игнорить.
Не так хорошо дружу с математикой, как хотелось бы. Приведенная формула для y(n), насколько я понял, для одномерного случая. Как быть для двухмерного?
Не могли бы вы привести сам код размытия, с помощью которого получилась финальная картинка?
Не могли бы вы привести сам код размытия, с помощью которого получилась финальная картинка?
Для двумерного — сначала фильтруем по строкам, потом результат по столбцам. Ссылку на код на сайте интела я тоже дал.
Двумерную картинку я вообще получил имитацией метода в excel, а потом перевёл из таблицы в текстовый pbm, вот так. Ну лень писать было :-)
Ну вот код из оптимизатора, например, который по IIR фильтру фильтрует туда-обратно:
Двумерную картинку я вообще получил имитацией метода в excel, а потом перевёл из таблицы в текстовый pbm, вот так. Ну лень писать было :-)
Ну вот код из оптимизатора, например, который по IIR фильтру фильтрует туда-обратно:
int CSignal::setAsConvIIR(CSignal &signal, CFilterIIR &filter)
{
if (signal.nOf!=nOf)
return -1;
int orderOfFilter = filter.orderOf();
flpointt* memTmp = (flpointt*) _alloca(sizeof(flpointt)*nOf);
for(int i=0; i<nOf; i++)
{
memTmp[i]=0;
}
for(int i=offs; i<nOf; i++)
{
memTmp[i]=signal.s[i]*filter.b[0];
for(int j=1; j<filter.p; j++)
{
memTmp[i]+=signal.s[i-j]*filter.b[j];
}
for(int j=0; j<filter.q; j++)
{
memTmp[i]+=memTmp[i-j-1]*filter.a[j];
}
}
for(int i=nOf-orderOfFilter-1; i<nOf; i++)
{
s[i]=0;
}
for(int i=nOf-orderOfFilter-1; i>=0; i--)
{
s[i]=memTmp[i]*filter.b[0];
for(int j=1; j<filter.p; j++)
{
s[i]+=memTmp[i+j]*filter.b[j];
}
for(int j=0; j<filter.q; j++)
{
s[i]+=s[i+j+1]*filter.a[j];
}
}
return 0;
}
Я думаю что если автор приведет пример того как работает (что это такое в данном случает) сепарабельность то станет понятно почему из 2d все вдруг стало 1d
Рядом «Честную»-то выложить бы не помешало!
Респект! Побольше бы таких статей на хабре.
Подобный метод применяется в детекторе границ Deriche. Довольно любопытный способ.
Напишите, пожалуйста, «гаусса» с большой буквы.
Спасибо.
Спасибо.
Одна из самых быстрых честных реализаций — через преобразование Фурье.
1. Делаем прямое преобразование изображения и фильтра (не только гауссового, но и любого другого)
2. Поэлементно перемножаем полученные спектры
3. С результатом делаем обратное преобразование Фурье
4. PROFIT
Сложность преобразования Фурье — O(nlog(n)), где n — количество пикселов в изображении
Время работы алгоритма не зависит от размера фильтра — 1 пиксел или же 1000.
Время работы — около 0.5 секунд для 12 мегапиксельной картинки на процессоре i7.
1. Делаем прямое преобразование изображения и фильтра (не только гауссового, но и любого другого)
2. Поэлементно перемножаем полученные спектры
3. С результатом делаем обратное преобразование Фурье
4. PROFIT
Сложность преобразования Фурье — O(nlog(n)), где n — количество пикселов в изображении
Время работы алгоритма не зависит от размера фильтра — 1 пиксел или же 1000.
Время работы — около 0.5 секунд для 12 мегапиксельной картинки на процессоре i7.
Предложенный алгоритм имеет сложность O(n) где n количество пикселей на изображении. Это меньше n log(n)
Кстати, если расскажите про алгоритм Блюстейна для БПФ произвольного размера, то тоже будет хорошо :-) Я, например, не очень понял.
Кстати, если расскажите про алгоритм Блюстейна для БПФ произвольного размера, то тоже будет хорошо :-) Я, например, не очень понял.
Насколько я понял, предложенный алгоритм не относится к «честным», т.е. дает очень похожую, но не идентичную картинку. Это уже не гауссово размытие, а имитация гауссового размытия. В ряде областей это очень критично, например когда идет сложная обработка или восстановление изображений с участием гауссового фильтра.
Маленькая ремарка: преобразование Фурье гауссовского распределения — тоже гауссовское, так что реально только надо преобразовывать саму картинку.
Ага, но еще нужно сообразить, какое у гауссианы будет \sigma в спектральной области, причем с учетом того, какой вариант записи DFT используется и в 95% случаев сделать это правильно не получается. Из тех, кому удалось, 4% отваливается на необходимости доопределить исходную картинку нулями, предварительно центрировав. Ну а необходимость определить ДПФ гауссианы с учетом хитрого порядка отсчетов при двумерном FFT доводит процент отвалившихся до 99.(9).
Отличнейшая статья! Очень пригодилось на практике. Благодаря ей удалось разобраться в методе довольно быстро. Но после реализации возникли вопросы:
А чему равна sigma при подсчёте коэффициентов? Она должна быть равна радиусу или половине радиуса? У меня получилось, что размытие вдвое сильнее, так как у нас два прохода.
Кроме того, во второй формуле указан знак минус, но на практике надо +.
На практике я также столкнулся с небольшой проблемой. А именно: после двух проходов симметрии не получилось, а справа всегда возникает небольшое остаточное значение:
Возможно, я что-то делаю неверно? Похоже мне не удаётся верно реализовать разворот между проходами на правой границе. Глазом это не заметно, но как0то не правильно это.
А чему равна sigma при подсчёте коэффициентов? Она должна быть равна радиусу или половине радиуса? У меня получилось, что размытие вдвое сильнее, так как у нас два прохода.
Кроме того, во второй формуле указан знак минус, но на практике надо +.
На практике я также столкнулся с небольшой проблемой. А именно: после двух проходов симметрии не получилось, а справа всегда возникает небольшое остаточное значение:
Возможно, я что-то делаю неверно? Похоже мне не удаётся верно реализовать разворот между проходами на правой границе. Глазом это не заметно, но как0то не правильно это.
Впрочем, в процентном отношении около 0.5%, что не так уж много… видимо поэтому на глаз и не видно
Выложите excel файл, сейчас по виду понять сложно
Вы мне результат показали, я вижу что он кривоват.
А вы мне покажите, как вы его получили.
А вы мне покажите, как вы его получили.
Идея реализовать всё это в экселе частично помогла.
Теперь, когда я стал пытаться повторить это в экселе, я вижу, что у меня есть ошибка, которую я благополучно исправил. Но небольшая асимметрия всё равно сохраняется, а на концах до нулей далековато.
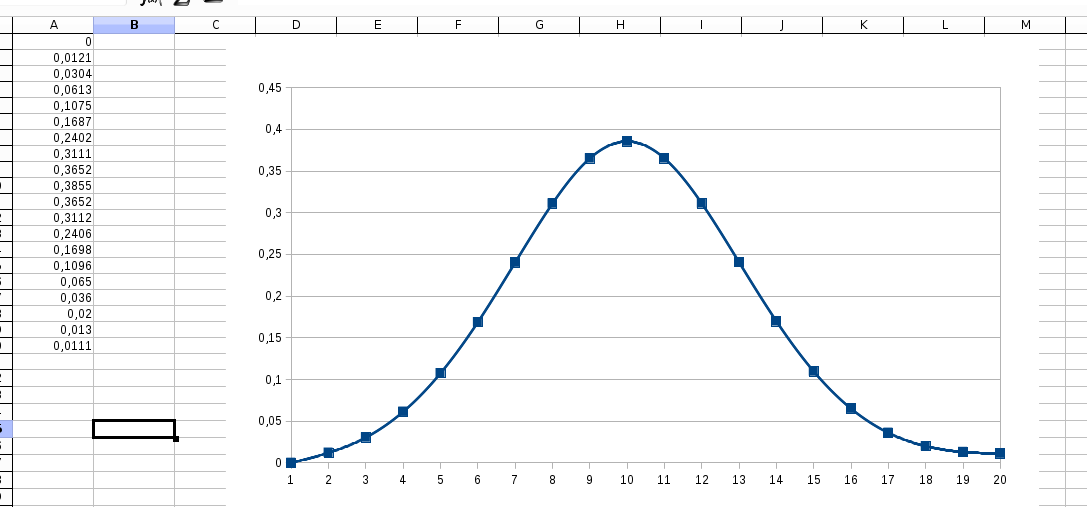
1iir-gaussian2.ods
Небольшой комментарий по реализации в экселе. В таблице есть три столбца. Первый соответствует входным данным, второй (G) первому проходу, а столбец J — второму и финальному проходу (справа налево). На первом проходе первые три точки считаются не так как все. На втором проходе последние три считаются не как все.
Внизу и на втором листе есть график.
Теперь, когда я стал пытаться повторить это в экселе, я вижу, что у меня есть ошибка, которую я благополучно исправил. Но небольшая асимметрия всё равно сохраняется, а на концах до нулей далековато.
1iir-gaussian2.ods
Небольшой комментарий по реализации в экселе. В таблице есть три столбца. Первый соответствует входным данным, второй (G) первому проходу, а столбец J — второму и финальному проходу (справа налево). На первом проходе первые три точки считаются не так как все. На втором проходе последние три считаются не как все.
Внизу и на втором листе есть график.
И да, всё это для радиуса 3.0 (соответственно, сигма была взята 1.5)
Ясно, что если бы расчёт был бы честным, то там нулей было бы куда больше. И если бы максимум был бы 1, а не 255, то относительная погрешность ещё бы выросла. Хотя сейчас, после исправления, разница между левой и правой частью составляет 0.01% от максимума. Возможно, это и есть предел точности для метода?
Во-первых, я не понял что значит «первые три отсчёта считаем не как все». Там формула та же, просто нужно ставить вместо отсчётов с отрицательными координатами нули.
Во-вторых, вы взяли до радиуса 3.0 сигм?
В целом, я думаю что поставив больше экспериментов (увеличив дальность расчётов, например) сами ответите на все вопросы :-) Математически всё должно получаться симметрично, зачит вопрос только в ошибках округления и насколько далеко считаем.
Во-вторых, вы взяли до радиуса 3.0 сигм?
В целом, я думаю что поставив больше экспериментов (увеличив дальность расчётов, например) сами ответите на все вопросы :-) Математически всё должно получаться симметрично, зачит вопрос только в ошибках округления и насколько далеко считаем.
В функции gaussCoef есть переменная z0_im, значение которой не используется. Так задумано или это ошибка?
Sign up to leave a comment.
Быстрое размытие по Гауссу