Comments 19
А мне картинки понравились!
На мой взгляд, окончательный вывод: используйте несколько ядер. Это: 1) нагляднее 2) выигрывает по производительности при >~ 10 блоках 3) не сильно хуже на >10 блоках.
Блоки на то и блоки, что предполагается, что вычисления в них происходят независимо.
PS Интересная ситуация: если открыть большинство журнальных статей по моделированию с использованием CUDA, то треть будет посвящена самой технологии. И тут то же самое! А теперь представьте, что весь выпуск — статьи по моделированию. Треть выпуска — основы CUDA…
На мой взгляд, окончательный вывод: используйте несколько ядер. Это: 1) нагляднее 2) выигрывает по производительности при >~ 10 блоках 3) не сильно хуже на >10 блоках.
Блоки на то и блоки, что предполагается, что вычисления в них происходят независимо.
PS Интересная ситуация: если открыть большинство журнальных статей по моделированию с использованием CUDA, то треть будет посвящена самой технологии. И тут то же самое! А теперь представьте, что весь выпуск — статьи по моделированию. Треть выпуска — основы CUDA…
Ну всё об одном и том же в одном выпуске — такого не бывает. А что, каждая статья в отдельно взятом месте в таком случае побуждает на изучение данной технологии, мощь то у неё колоссальная!
Очень рад, что картинки не вызывают отторжения.
Касательно содержания статей в журналах, то, думаю, зависит от степени популярности журнала. В суровом научном введение будет меньше, в научно-популярном — шире. Вообще же, бытует мнение, что хорошая научная статья должна во многом быть самодостаточной, во введение рассказывать о некоторых необходимых основах.
Касательно содержания статей в журналах, то, думаю, зависит от степени популярности журнала. В суровом научном введение будет меньше, в научно-популярном — шире. Вообще же, бытует мнение, что хорошая научная статья должна во многом быть самодостаточной, во введение рассказывать о некоторых необходимых основах.
В CUDA API неспроста отсутствует встроенный примитив синхронизации всех блоков (тредов) грида. Связано это с тем, что грид может (и должен, согласено Best Practices Guide) содержать блоков больше, чем SM-ов. Всвязи с этим, все неявные алгоритмы, которые вводят зависимости по данным между независимыми блоками (а значит, и SM-ами), могут приводить к простою, и снижению производительности.
Но и это еще не все. Гораздо хуже ситуация может случиться при определенных типах зависимостей, где все SM-ы получат по блоку на исполнение, и будут ждать некоторое условие, которое может произойти, а может и нет, в зависимости от того, в каком порядке SM-планировщик будет получать работу. Такие сценарии крайне тяжело отлаживать, поэтому рекомендуется отдавать предпочтение самым простым и доступным способам синхронизации.
Касаемо разделения (I) & (II) на независимые кернелы, это не самый плохой вариант. При использовании асинхронного API и cuda-канала, отличного от нуля, оверхед на запуск кернела будет только в самом первом запуске. Все остальные кернелы будут запланированы из внутренней очереди в драйвере. Это конечно при условии, что вам не требуется между (I) и (II) вставлять операции копирования памяти.
В заключение, отмечу, что в CUDA 5.0 и в самой продвинутой карте семейства Kepler доступна технология запуска кернела _изнутри_ другого кернела. Это в разы увеличивает гибкость программирования на CUDA, но к сожалению, доступность железа пока отстает.
Но и это еще не все. Гораздо хуже ситуация может случиться при определенных типах зависимостей, где все SM-ы получат по блоку на исполнение, и будут ждать некоторое условие, которое может произойти, а может и нет, в зависимости от того, в каком порядке SM-планировщик будет получать работу. Такие сценарии крайне тяжело отлаживать, поэтому рекомендуется отдавать предпочтение самым простым и доступным способам синхронизации.
Касаемо разделения (I) & (II) на независимые кернелы, это не самый плохой вариант. При использовании асинхронного API и cuda-канала, отличного от нуля, оверхед на запуск кернела будет только в самом первом запуске. Все остальные кернелы будут запланированы из внутренней очереди в драйвере. Это конечно при условии, что вам не требуется между (I) и (II) вставлять операции копирования памяти.
В заключение, отмечу, что в CUDA 5.0 и в самой продвинутой карте семейства Kepler доступна технология запуска кернела _изнутри_ другого кернела. Это в разы увеличивает гибкость программирования на CUDA, но к сожалению, доступность железа пока отстает.
Как уже пишут выше, разбивайте на ядра.
Преимущества тут такие:
1) Простота кода
2) Простота тестирования
3) Возможность использовать более быстрые структуры памяти (surface, texture).
Преимущества тут такие:
1) Простота кода
2) Простота тестирования
3) Возможность использовать более быстрые структуры памяти (surface, texture).
>например, для моей Tesla блок может содержать максимум 512 потоков
Уж не знаю на какой странице такое написано, но это крайне неправдовподобно, т.к. даже для моей GT555M ограничение составляет 1024, такие данные следует запрашивать непосредственно у карты, с помощью спец. функций.
>Однако, чем больше становится блоков, тем метод MKL отстает по производительности все меньше. Для 32-х блоков он даже
незначительно обыгрывает метод SKL. Связано это с тем, что чем больше блоков, тем больше больше потоков (имеющих threadIdx.x == 0) читают переменную count из медленной глобальной памяти.
Необоснованно. Попробуйте удалить обращение к глобальной памяти и провести ту же серию экспериментов, скорее всего картина будет та же.
>Если же рассматривать изменение относительной производительности в зависимости от числа потоков в блоке, при постоянном количестве самих блоков, то тоже можно заметить некоторую закономерность. Но тут работают неизвестные автору эффекты, связанные с синхронизацией потоков в блоке, управлением warp`ами в SM.
Эта особенность непосредственно связана с предыдущим замечанием. Я недавно проводил исследование на эту тему, статья скоро должна быть опубликована в «Вестнике ННГУ». Если коротко, для максимальной производительности, размер блока должен быть кратен 32 (для всех NVIDIA) и числу ядер SM, а также превышать общее число ядер на всей карте (На самом деле исследование проводилось на OpenCL, но сомневаюсь что на CUDA результат будет другим).
И ещё замечание: такие вещи как
if (threadIdx.x == 0)
while (count != 0);
делать категорически нельзя. Если внимательно прочитать (1), то там описана работа планировщика с условными конструкциями. А именно: он сначала запускает все потоки, которые идут по одной ветке, и лишь после их завершения запускает потоки, которые идут по другой. А это значит, что потенциально подобная конструкция может привести к дедлоку.
Уж не знаю на какой странице такое написано, но это крайне неправдовподобно, т.к. даже для моей GT555M ограничение составляет 1024, такие данные следует запрашивать непосредственно у карты, с помощью спец. функций.
>Однако, чем больше становится блоков, тем метод MKL отстает по производительности все меньше. Для 32-х блоков он даже
незначительно обыгрывает метод SKL. Связано это с тем, что чем больше блоков, тем больше больше потоков (имеющих threadIdx.x == 0) читают переменную count из медленной глобальной памяти.
Необоснованно. Попробуйте удалить обращение к глобальной памяти и провести ту же серию экспериментов, скорее всего картина будет та же.
>Если же рассматривать изменение относительной производительности в зависимости от числа потоков в блоке, при постоянном количестве самих блоков, то тоже можно заметить некоторую закономерность. Но тут работают неизвестные автору эффекты, связанные с синхронизацией потоков в блоке, управлением warp`ами в SM.
Эта особенность непосредственно связана с предыдущим замечанием. Я недавно проводил исследование на эту тему, статья скоро должна быть опубликована в «Вестнике ННГУ». Если коротко, для максимальной производительности, размер блока должен быть кратен 32 (для всех NVIDIA) и числу ядер SM, а также превышать общее число ядер на всей карте (На самом деле исследование проводилось на OpenCL, но сомневаюсь что на CUDA результат будет другим).
И ещё замечание: такие вещи как
if (threadIdx.x == 0)
while (count != 0);
делать категорически нельзя. Если внимательно прочитать (1), то там описана работа планировщика с условными конструкциями. А именно: он сначала запускает все потоки, которые идут по одной ветке, и лишь после их завершения запускает потоки, которые идут по другой. А это значит, что потенциально подобная конструкция может привести к дедлоку.
1) В качестве подтверждения своих слов о максимальном количестве потоков в блоке, привожу значения некоторых полей структуры, которую дала мне cudaGetDeviceProperties(...). Судя по интернетам, у Вас ядро GF106 с поддержкой версии 2.1. Выглядит поновее того, что доступно для моего пользования.
2) А как можно удалить обращения к глобальной памяти, если именно там хранится переменная count, инкрементируемая «отработавшими» блоками? Именно она и считывается в циклах. Чем больше потоков, тем больше циклов, тем больше считываюний…
3) Про кратность 32-м и превышение количеством числа ядер говорится в «CUDA C Best Practices Guide». Но я правда не знаю причин тому, и не понимаю, как это следует из Вашего замечания №2. Но в любом случае с интересом ознакомлюсь с Вашей работой! Судя по сайту «Вестника ННГУ», скачать электронный вариант можно. У Вас в каком номере?
4) Как раз по невнимательности подробности обработки условных конструкций пропустил. Но как из того, что сперва выполняется одна ветка, а уже после — другая, может следовать дедлок? Каждый поток threadIdx.x == 0 непременным образом сделает "+1" к счетчику. Поэтому и все threadIdx.x == 0 выйдут из цикла.
2) А как можно удалить обращения к глобальной памяти, если именно там хранится переменная count, инкрементируемая «отработавшими» блоками? Именно она и считывается в циклах. Чем больше потоков, тем больше циклов, тем больше считываюний…
3) Про кратность 32-м и превышение количеством числа ядер говорится в «CUDA C Best Practices Guide». Но я правда не знаю причин тому, и не понимаю, как это следует из Вашего замечания №2. Но в любом случае с интересом ознакомлюсь с Вашей работой! Судя по сайту «Вестника ННГУ», скачать электронный вариант можно. У Вас в каком номере?
4) Как раз по невнимательности подробности обработки условных конструкций пропустил. Но как из того, что сперва выполняется одна ветка, а уже после — другая, может следовать дедлок? Каждый поток threadIdx.x == 0 непременным образом сделает "+1" к счетчику. Поэтому и все threadIdx.x == 0 выйдут из цикла.
Смысле заключается в том, что размер блока очень сильно влияет на производительность, сильнее чем число обращений к глобальной памяти (имеется в виду, когда их немного, как в Вашем случае). Есть ещё один важный фактор — кратность размеру блока (8 в Вашем случае, а у меня например 48). Я конечно понимаю, что этот алгоритм не будет работать если просто удалить обращение к глобальной памяти, я предлагаю набросать «пустышку», которая либо вообще не будет обращаться к глобальной памяти, либо число этих обращений не будет зависеть от числа блоков, и посмотреть как будет изменяться производительность в зависимости от числа блоков.
Про дедлок, я сказал что ПОДОБНАЯ конструкция может привести к дедлоку. Просто представьте, что все процессоры заняты веткой, в которой крутится цикл, а счётчик убавить получается некому.
Статья должна выйти в ближайшем номере (я надеюсь), в дополнении от ВМК. Название: «АНАЛИЗ ВЛИЯНИЯ РАЗМЕРА РАБОЧЕЙ ГРУППЫ НА ПРОИЗВОДИТЕЛЬНОСТЬ OPENCL-РЕАЛИЗАЦИИ ВЫЧИСЛИТЕЛЬНОГО АЛГОРИТМА НА ПРИМЕРЕ МЕТОДА ГАУССА РЕШЕНИЯ СЛАУ». Если интересно, код уже опубликован: github.com/Dem0n3D/solecl правда инструкцию по сборке пока не писал, а там используется обёртка QtOpeCL.
Про дедлок, я сказал что ПОДОБНАЯ конструкция может привести к дедлоку. Просто представьте, что все процессоры заняты веткой, в которой крутится цикл, а счётчик убавить получается некому.
Статья должна выйти в ближайшем номере (я надеюсь), в дополнении от ВМК. Название: «АНАЛИЗ ВЛИЯНИЯ РАЗМЕРА РАБОЧЕЙ ГРУППЫ НА ПРОИЗВОДИТЕЛЬНОСТЬ OPENCL-РЕАЛИЗАЦИИ ВЫЧИСЛИТЕЛЬНОГО АЛГОРИТМА НА ПРИМЕРЕ МЕТОДА ГАУССА РЕШЕНИЯ СЛАУ». Если интересно, код уже опубликован: github.com/Dem0n3D/solecl правда инструкцию по сборке пока не писал, а там используется обёртка QtOpeCL.
В код влезать лучше не буду, а подожду статьи. Думаю, такая «пустышка» годна. По вертикальной оси абсолютное время, что выдает cudaEventElapsedTime(...):

Особо отмечу, то запускалось на Tesla с 30-ю SM. Так что, двукратное «увеличение крутизны» при переходе от 30 к 31 блокам понятно: одному SM приходится выполнять два одинаковых блока. Следовательно, он тратит в ~2 раза больше времени. А вся эскадра плывет со скоростью самого медленного корабля…
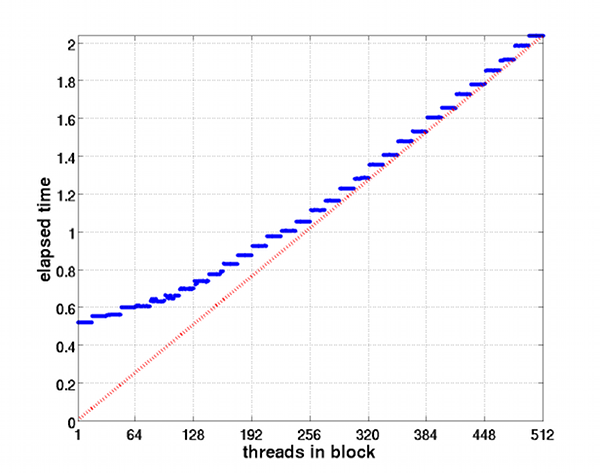
А тут запускался 1 блок, но число потоков в нем менялось шагом 1. Ступеньки, как я понимаю, обусловлены размерностью warp`ов. Кстати, интересно, что происходит внутри: формально появляются warp`ы с числом потоков меньше 32. Красная пунктирная кривая отражает просто пропорциональную зависимость. Из этого графика становится понятно, что лучше блоки делать не «толще» 256-ти потоков.
Особо отмечу, то запускалось на Tesla с 30-ю SM. Так что, двукратное «увеличение крутизны» при переходе от 30 к 31 блокам понятно: одному SM приходится выполнять два одинаковых блока. Следовательно, он тратит в ~2 раза больше времени. А вся эскадра плывет со скоростью самого медленного корабля…
А тут запускался 1 блок, но число потоков в нем менялось шагом 1. Ступеньки, как я понимаю, обусловлены размерностью warp`ов. Кстати, интересно, что происходит внутри: формально появляются warp`ы с числом потоков меньше 32. Красная пунктирная кривая отражает просто пропорциональную зависимость. Из этого графика становится понятно, что лучше блоки делать не «толще» 256-ти потоков.
Из этих графиков я могу предположить, что CUDA как-то иначе распределяет потоки, т.к. в OpenCL размер блока влияет на время отнюдь не линейно и даже не монотонно. Возможно, именно поэтому вопросу выбора размера блока в CUDA уделяется так мало внимания.
Хотя так же можно предположить, что в моём алгоритме присутствуют дополнительные факторы, которые способствуют такой зависимости (например те же ветвления). В любом случае, мне кажется очень маловероятным, что причиной таких отличий является модель видеокарты. Особенно учитывая, что во многих статьях можно увидеть подобные результаты. Но я всё же попробую запустить Вашу «пустышку» у себя.
Хотя так же можно предположить, что в моём алгоритме присутствуют дополнительные факторы, которые способствуют такой зависимости (например те же ветвления). В любом случае, мне кажется очень маловероятным, что причиной таких отличий является модель видеокарты. Особенно учитывая, что во многих статьях можно увидеть подобные результаты. Но я всё же попробую запустить Вашу «пустышку» у себя.
Да, пока писал пост и, затем, читал комментарии, стал все больше с клонятся к разбиению ядра на части. Однако меня продолжает смущать такой момент. Мое большое ядро делает несколько тысяч последовательных преобразований X->P->X, используя при этом одинаковый для всех потоков массив, из которого выбираются весовые коэффициенты. Его размер около 5KB, и его копии хранятся в разделяемой памяти каждого блока. Если из одного ядра, делать много меленьких, то каждый запуск оных должен же сопровождаться записью этого массива в разделяемую память? Если я прав, то получается очень много лишних обращений к разделяемой памяти.
Открою страшную тайну: я решил доморощенным образом вычислять преобразование Фурье. Весьма вероятно именно поэтому мое ядро очень прожорливо до регистров, и на каждом SM я запускаю по одному блоку в 256 потоков. И grid из 30*256 потоков по кускам (из 30*256 точек) определяет функцию-образ, создавая как раз все те печальные ситуации, о которых писал Toshas.
Открою страшную тайну: я решил доморощенным образом вычислять преобразование Фурье. Весьма вероятно именно поэтому мое ядро очень прожорливо до регистров, и на каждом SM я запускаю по одному блоку в 256 потоков. И grid из 30*256 потоков по кускам (из 30*256 точек) определяет функцию-образ, создавая как раз все те печальные ситуации, о которых писал Toshas.
Код одного большого ядра разделяется на части в два отдельных. Они будут последовательно вызываться хостом. Одно ядро делает этап (i), второе — этап (ii). Делается это, как писали коллеги выше, для:
- Простоты (кода, отладки);
- Возможности использовать другие типы структур памяти (правда, наверно, в моей задаче это не поможет; надо еще почитать, чтобы ответить точно);
- Синхронизации всех потоков запущенного grid`а, что как раз и необходимо в первую очередь для моего алгоритма.
Да, а одно преобразование X->P или P->X как раз и есть вычисление Фурье-образа.
Вот, пожалуйста! По данным этой программы и строились графики.
Если большая часть итеративного процесса может выполняться на регистрах и разделяемой памяти, то механизм синхронизации разбиением на кернелы может внести избыточные задержки на синхронизацию через глобальную память (очень дорогая она!).
Из вашего описания я понял, что ваш подход чем-то напоминает семпл reduce, когда каждый блок считает частичную сумму, потом один из блоков ждет когда все завершатся (читая значение атомарного счетчика выполненных блоков), и суммирует частичные суммы. Такой подход не вводит зависимостей между блоками (если реализован в точности как в семпле), и может сэкономить много времени.
Из вашего описания я понял, что ваш подход чем-то напоминает семпл reduce, когда каждый блок считает частичную сумму, потом один из блоков ждет когда все завершатся (читая значение атомарного счетчика выполненных блоков), и суммирует частичные суммы. Такой подход не вводит зависимостей между блоками (если реализован в точности как в семпле), и может сэкономить много времени.
Изначально я хотел изобразить нечто подобное, но потом подумал (возможно, не очень хорошо) и решил сделать проще. Если у меня есть функция X(x) и я вычисляю от нее Фурье-образ P(p), то каждый поток считает интеграл для одной точки pj. Если точек не больше, чем максимально возможное количество потоков. Если больше — то один поток обрабатывает несколько точек.
Sign up to leave a comment.
CUDA: синхронизация блоков