В рамках рабочих задач недавно мною было проведено небольшое исследование на тему целесообразности использования опции prefetchCount при работе с брокером сообщений RabbitMQ.
Хочу поделиться этим материалом в виде слайдов и комментариев к ним.
Тесты проводились на конкретном проекте, но в целом они справедливы для большинства случаев, где обработка сообщений (выполнение задач) занимает хоть сколько-то существенное время (при обработке менее 1000 сообщений в секунду).
* на слайдах вместо слова «подписчик» используется «консумер», в комментариях для единообразия тоже
* рассматривается отдельно взятая очередь с пятью консумерами (C1..C5)
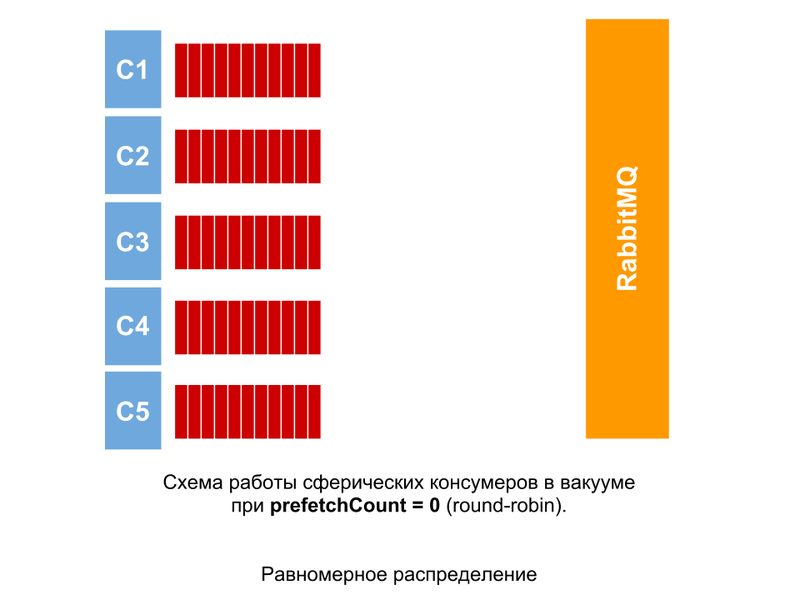
Такую картину можно было бы наблюдать, если обработка всех сообщений занимала абсолютно равное количество времени. При prefetchCount = 0 сообщения раздаются консумерам по очереди, не зависимо от того, сколько сообщений не подтверждены.
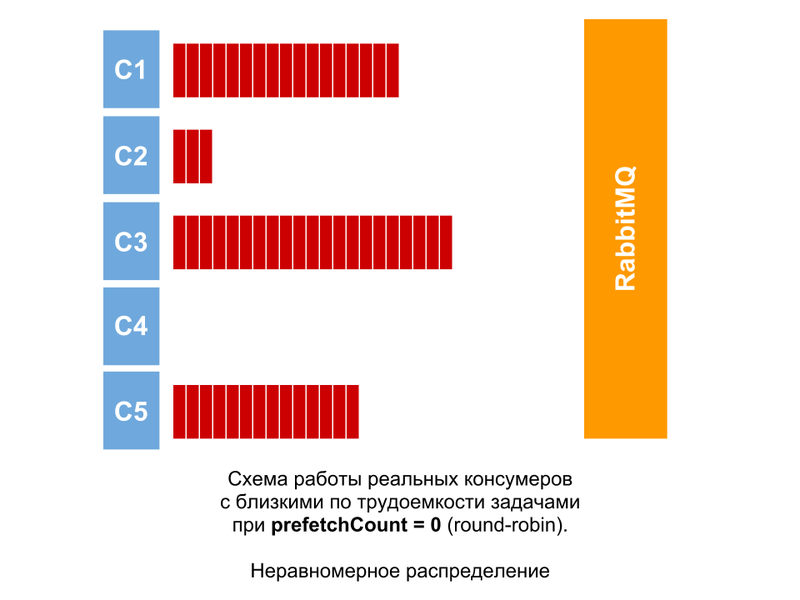
На самом деле, задачи всегда будут отличаться по трудоемкости, хотя бы незначительно. Поэтому даже если они равны (очень близки), то картина будет приблизительно такой. Разница в количестве неподтвержденных сообщений у консумеров будет расти, если не все из них успевают обрабатывать свои сообщения.

Если задачи могут значительно отличаться по трудоемкости [например, на нашем проекте разброс в пару порядков], то при получении сообщения, обработка которого займет много времени, будет накапливаться количество неподтвержденных сообщений. Визуально (мониторя очередь) кажется, что сообщения зависают, т.к. свободные консумеры обрабатывают новые сообщения мгновенно, а у занятого сообщения накапливаются. Эти сообщения не будут отданы на обработку другим консумерам, если только не отвалится соединение с обрабатывающим [на схеме — C4]. Также в этом случае наблюдаются значительные простои у свободных консумеров.


Но куда интереснее дела обстоят, когда в очереди есть сообщения, и происходит перезапуск консумеров (или просто первый запуск). Консумеры стартуют вместе, но все-равно с минимальным временным интервалом. И поэтому как только первый запускается, он сразу получает пачку сообщений (т.к. на этот момент других консумеров еще нет). Путем большого количества экспериментов было выявлено число 50. Далее сообщения распределяются равномерно.
В ситуации, когда в очереди находится сообщение, при старте консумеров, один из них его получает. Когда после этого приходит еще одно сообщение, оно отправляется тому же консумеру. Причиной этого может быть сброс указателя, т.к. количество консумеров изменилось с момента передачи на обработку первого сообщения.

При использовании опции prefetchCount = n [в примере n=1, но может быть и 2, 5, 10...] консумер не получает следующие n сообщений, пока не подтвердит предыдущие. Таким образом можно получить равномерную загруженность, не зависимо от равномерности трудоемкости задач. Не возникнет ситуации, когда в очереди есть сообщения, а какие-то консумеры простаивают (при простое в очереди будет не более n сообщений на консумер).
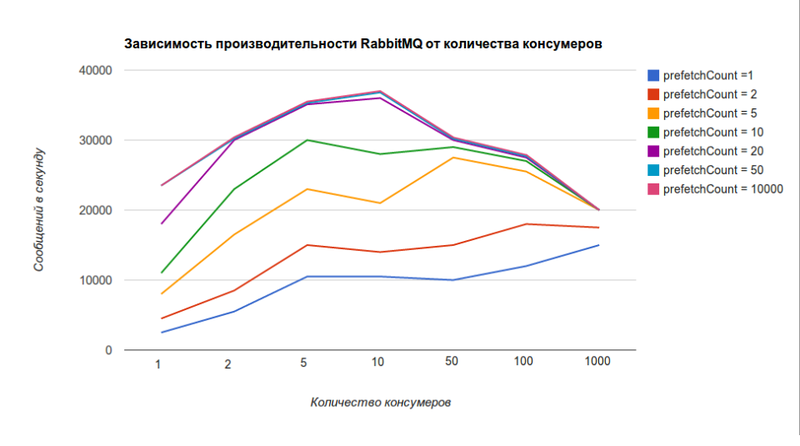
Но не все так просто. Чем меньше значение prefetchCount, тем ниже производительность RabbitMQ (значение 0 соответствует бесконечности и на графике близко к значению 10000). Этот график взят с официального сайта.
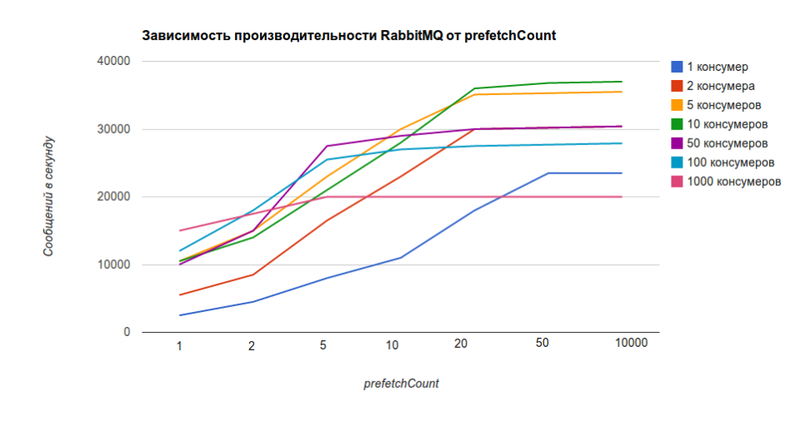
Тот же график, только зависимость от значения prefetchCount, а не от количества консумеров.
По нему видно, что при 5 консумерах для prefetchCount = 1 RabbitMQ сможет отдавать 10k сообщений в секунду, а для prefetchCount = 0 — 36k сообщений в секунду, что в 3,6 раза больше.
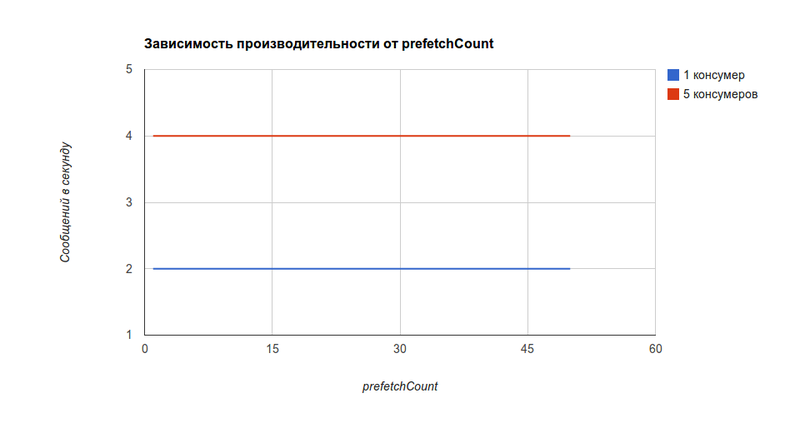
Но узким местом в большинстве случаев будет не производительность RabbitMQ, а производительность консумеров (ниже на несколько порядков). На испытуемом проекте наблюдалась такая зависимость (а точнее, ее отсутствие) от значения prefetchCount [она будет справедлива, как я уже упомянул, для консумеров, обрабатывающих менее 1000 сообщений в секунду].
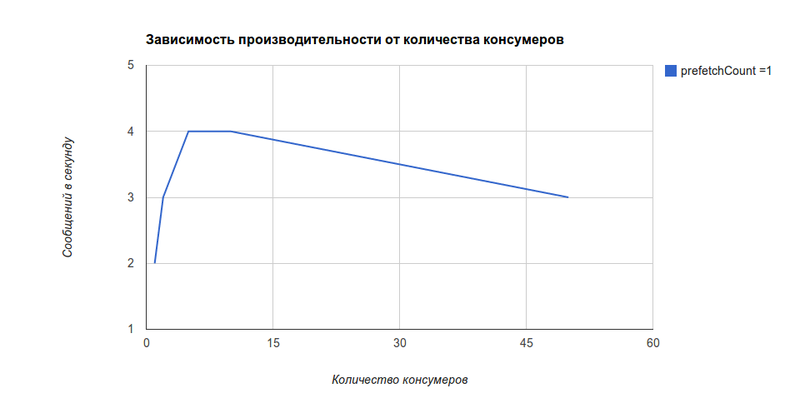
При этом зависимоть производительности от количества консумеров [на нашем проекте] получилась похожая, но реально зависит от ресурсоемкости самих консумеров, производительности сервера, разнесены ли консумеры по разным серверам, etc.

Максимальные потери из-за использования prefetchCount = 1 (в сравнении с идеальными условиями с первого слайда) составляют 0,03%. При этом ожидаемый выигрыш времени за счет равномерного распределения и меньших простоев составит порядка 50..100% (в 1,5..2 раза), т.к. в реальной очереди при prefetchCount = 0 время обработки сообщений часто сводится ко времени работы одного консумера из-за простоя остальных (как на третьем слайде). Также очередь движется более прогнозируемо, и отсутствуют эффекты «зависания».
[само собой, для других проектов, цифры будут отличаться]
Результатами Ваших тестов и наблюдений, связанных с prefetchCount, предлагаю поделиться в комментариях.
Хочу поделиться этим материалом в виде слайдов и комментариев к ним.
Тесты проводились на конкретном проекте, но в целом они справедливы для большинства случаев, где обработка сообщений (выполнение задач) занимает хоть сколько-то существенное время (при обработке менее 1000 сообщений в секунду).
* на слайдах вместо слова «подписчик» используется «консумер», в комментариях для единообразия тоже
* рассматривается отдельно взятая очередь с пятью консумерами (C1..C5)
Идеальные условия
Такую картину можно было бы наблюдать, если обработка всех сообщений занимала абсолютно равное количество времени. При prefetchCount = 0 сообщения раздаются консумерам по очереди, не зависимо от того, сколько сообщений не подтверждены.
Равные задачи
На самом деле, задачи всегда будут отличаться по трудоемкости, хотя бы незначительно. Поэтому даже если они равны (очень близки), то картина будет приблизительно такой. Разница в количестве неподтвержденных сообщений у консумеров будет расти, если не все из них успевают обрабатывать свои сообщения.
Неравные задачи
Если задачи могут значительно отличаться по трудоемкости [например, на нашем проекте разброс в пару порядков], то при получении сообщения, обработка которого займет много времени, будет накапливаться количество неподтвержденных сообщений. Визуально (мониторя очередь) кажется, что сообщения зависают, т.к. свободные консумеры обрабатывают новые сообщения мгновенно, а у занятого сообщения накапливаются. Эти сообщения не будут отданы на обработку другим консумерам, если только не отвалится соединение с обрабатывающим [на схеме — C4]. Также в этом случае наблюдаются значительные простои у свободных консумеров.
Epic fail
Рестарт
Но куда интереснее дела обстоят, когда в очереди есть сообщения, и происходит перезапуск консумеров (или просто первый запуск). Консумеры стартуют вместе, но все-равно с минимальным временным интервалом. И поэтому как только первый запускается, он сразу получает пачку сообщений (т.к. на этот момент других консумеров еще нет). Путем большого количества экспериментов было выявлено число 50. Далее сообщения распределяются равномерно.
В ситуации, когда в очереди находится сообщение, при старте консумеров, один из них его получает. Когда после этого приходит еще одно сообщение, оно отправляется тому же консумеру. Причиной этого может быть сброс указателя, т.к. количество консумеров изменилось с момента передачи на обработку первого сообщения.
Fair dispatch
При использовании опции prefetchCount = n [в примере n=1, но может быть и 2, 5, 10...] консумер не получает следующие n сообщений, пока не подтвердит предыдущие. Таким образом можно получить равномерную загруженность, не зависимо от равномерности трудоемкости задач. Не возникнет ситуации, когда в очереди есть сообщения, а какие-то консумеры простаивают (при простое в очереди будет не более n сообщений на консумер).
Производительность RabbitMQ
Но не все так просто. Чем меньше значение prefetchCount, тем ниже производительность RabbitMQ (значение 0 соответствует бесконечности и на графике близко к значению 10000). Этот график взят с официального сайта.
Тот же график, только зависимость от значения prefetchCount, а не от количества консумеров.
По нему видно, что при 5 консумерах для prefetchCount = 1 RabbitMQ сможет отдавать 10k сообщений в секунду, а для prefetchCount = 0 — 36k сообщений в секунду, что в 3,6 раза больше.
Производительность консумеров
Но узким местом в большинстве случаев будет не производительность RabbitMQ, а производительность консумеров (ниже на несколько порядков). На испытуемом проекте наблюдалась такая зависимость (а точнее, ее отсутствие) от значения prefetchCount [она будет справедлива, как я уже упомянул, для консумеров, обрабатывающих менее 1000 сообщений в секунду].
При этом зависимоть производительности от количества консумеров [на нашем проекте] получилась похожая, но реально зависит от ресурсоемкости самих консумеров, производительности сервера, разнесены ли консумеры по разным серверам, etc.
Выводы
Максимальные потери из-за использования prefetchCount = 1 (в сравнении с идеальными условиями с первого слайда) составляют 0,03%. При этом ожидаемый выигрыш времени за счет равномерного распределения и меньших простоев составит порядка 50..100% (в 1,5..2 раза), т.к. в реальной очереди при prefetchCount = 0 время обработки сообщений часто сводится ко времени работы одного консумера из-за простоя остальных (как на третьем слайде). Также очередь движется более прогнозируемо, и отсутствуют эффекты «зависания».
[само собой, для других проектов, цифры будут отличаться]
Результатами Ваших тестов и наблюдений, связанных с prefetchCount, предлагаю поделиться в комментариях.
