 HOLO — приставка от греческого ὅλος, «весь».
HOLO — приставка от греческого ὅλος, «весь».Введение
Не без волнения рад представить вашему вниманию свою разработку, позволяющую объединять музыкальную библиотеку в единое целое с целью поиска «похожей» музыки.
Ещё несколько лет назад, на пике самостоятельного изучения MATLAB, мне захотелось создать программу, которая позволяла бы по заданному образцу музыки находить другие композиции «в том же духе». Куча уважительных причин заставляли откладывать реализацию всё дальше и дальше, но в какой-то момент дело сдвинулось с мёртвой точки. В результате, слегка изменив основу для разработки, первая версия программы была сделана.
Постановка задачи
Итак, постановка задачи выглядит следующим образом:
- Есть сравнительно большая (>10 тыс. файлов) музыкальная коллекция на жёстком диске, целиком которую использовать и каталогизировать стало затруднительно, из-за чего многие композиции месяцами и годами ни разу не попадают в плейлист.
- Необходимо провести оценку численных характеристик композиций, не используя никакой информации кроме формы звуковой волны, содержащейся в файле (никаких имён файлов, альбомов, id3-тегов и тому подобное в расчёт не берётся).
- Подать анализатору на вход одну или несколько композиций в качестве образцов.
- Вывести список композиций, не совпадающих со списком образцов и отсортированных в порядке возрастания их «расстояния» от образцов.
Платформой для разработки стал C#, как наиболее простой лично для меня язык, достаточно быстрый и имеющий хорошую среду разработки. Беглый поиск по Codeplex и подобным сайтам позволил избежать изобретения некоторых велосипедов, в частности используются следующие библиотеки:
- NAudio – для считывания аудиофайлов.
- Meta.Numerics – для FFT-преобразования.
- SQLite + SQLite netFX wrapper для хранения и обработки данных.
- Также на стадии исследования подключена библиотека ALGLIB в версии для .NET.
Архитектурно программа состоит из двух подсистем – формирование базы данных о музыкальной коллекции и система поиска по базе данных.
Теория
Формирование базы данных реализовано следующим образом:
Анализируемый файл представляется в виде вектора из семплов, из которого извлекается N снимков (snap) длиной L семплов, каждый из которых приводится в АЧХ (fft-snap) при помощи FFT-преобразования. Это преобразование, по сути, превращает временной ряд в набор амплитуд разных частот, из которых состоит временной ряд. Затем fft-snap пропорционально сжимается в K раз (downscale ratio), чтобы уменьшить количество анализируемых в дальнейшем частот.
Далее каждая частота получившегося набора снимков рассматривается по-отдельности – рассчитываются статистические характеристики, такие как среднее значение (mean), медиана (median), стандартное отклонение (stdev), скос (skewness) и крутизна (kurtosis). В результате, для каждой композиции имеем набор из L/2K частот (FFT получается практически симметричным относительно середины), для каждой из которых рассчитаны 5 статистик. В базу данных кладётся имя файла, путь к нему на диске и 5L/2K вещественных чисел, каждое из которых помечено именем статистики, которое оно представляет.
Например, мы анализируем файл, сделав 40 снимков длиной в 64000 семплов, сжатых в 1000 раз. В итоге имеем вектор из 5*(64000/1000)/2 = 160 чисел для каждой композиции.
На этом основной этап формирования БД для анализа считаем завершённым. Вспомогательными шагами являются:
- Построение индекса по таблице статистики.
- Расчёт габаритных значений для каждой статистики (максимум, минимум, среднее и коридор – разница между максимумом и минимумом).
Теперь можно приступать к анализу. Простейший способ оценить близость двух точек в 160-мерном пространстве – посчитать евклидово расстояние между ними (сумма квадратов попарных разностей соответствующих статистик, квадратный корень не извлекаем — он удлиняет вычисления, но на результат сортировки не влияет). Казалось бы – бери и считай, но разные частоты в АЧХ композиции имеют разные разбросы и расчёт расстояния «в лоб» будет давать искажённое расстояние, с сильным акцентом на низкие частоты. Для того чтобы компенсировать нежелательный эффект, мы поделим квадрат разности между значениями на квадрат среднего значения амплитуды данной частоты. Таким образом, исходно анизотропное пространство характеристик распределения частот, в котором мы вычисляем расстояние, становится значительно более изотропным, то есть однородным.
Теоретически, можно провести кластерный анализ, объединяющий композиции по степени их близости, но пока было решено отказаться от применения этого метода, так как в его основе также лежит расчет расстояния между точками в пространстве (с выбором разных метрик), но алгоритм оказывается более сложным и не очень полезным в задаче сортировки композиций по возрастанию расстояния.
Практика
Пожалуй, теории пока достаточно, расскажу о практических результатах на основе моей коллекции музыки. Количество треков 30277, жанры самые разные – классическая музыка, рок, хард-рок, эмбиент, драм-н-бейс, хаус, техно, этника, весь спектр металла от лёгкого дума до самого ядерного и быстрого.
Анализ всей моей коллекции занял два с половиной дня, база данных без постобработки занимает 180 мегабайт, вместе с индексами — 460.
Интерфейс программы в части поиска заключается в динамическом формировании SQL-запроса, в котором реализован алгоритм расчёта евклидова расстояния для нормированных статистик по каждой частоте.
Имеется возможность указать как одну композицию в качестве образца, так и несколько. Вообще, возможность поиска песен, близких сразу к нескольким образцам, сильно увеличивает точность поиска, так как одна композиция может иметь паразитные вариации по статистикам, возникающие по разным причинам, но нивелируемые благодаря тому, что несколько образцов по-сути образуют центроид в многомерном пространстве, паразитные вариации которого сильно уменьшены. Главное при определении нескольких образцов — быть уверенным в том, что между образцами действительно имеется явная общность (например, композиции с одного альбома или в одном узком жанре и т.д.). Если образцы будут сильно отличающимися между собой, то выдача близких композиций будет нерелевантной.
Запрос при одном образце выполняется в среднем около минуты, при увеличении количества образцов время увеличивается пропорционально.
Образец SQL выглядит следующим образом:
select b.id, sum(((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue))/(c1.value*c1.value)) as distance,
10000*max((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue)/(c2.value*c2.value)) as maxdiff,
10000*avg((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue)/(c2.value*c2.value)) as meandiff
from stats a, stats b, feature c1, feature c2
where
a.id in (631, 1919) and b.id not in (631, 1919) and
a.statname = c1.statname and c1.feature = 'mean' and
a.statname = c2.statname and c2.feature = 'max_min' and
a.statname = b.statname and c1.statname = c2.statname and
a.statvalue <= b.statvalue + 75*c2.value/100 and a.statvalue >= b.statvalue - 75*c2.value/100 and
a.statname in ('b_median_FFT1_01', 'b_median_FFT1_02', 'b_median_FFT1_03', 'b_median_FFT1_04', 'b_median_FFT1_05', 'b_median_FFT1_06', 'b_median_FFT1_07', 'b_median_FFT1_08', 'b_median_FFT1_09', 'b_median_FFT1_10', 'b_median_FFT1_11', 'b_stdev_FFT1_01', 'b_stdev_FFT1_02', 'b_stdev_FFT1_03', 'b_stdev_FFT1_04', 'b_stdev_FFT1_05', 'b_stdev_FFT1_06', 'b_stdev_FFT1_07', 'b_stdev_FFT1_08', 'b_stdev_FFT1_09', 'b_stdev_FFT1_10', 'b_stdev_FFT1_11',
'b_skewn_FFT1_01', 'b_skewn_FFT1_02', 'b_skewn_FFT1_03', 'b_skewn_FFT1_04', 'b_skewn_FFT1_05', 'b_skewn_FFT1_06', 'b_skewn_FFT1_07', 'b_skewn_FFT1_08', 'b_skewn_FFT1_09', 'b_skewn_FFT1_10', 'b_skewn_FFT1_11', 'b_kurto_FFT1_01', 'b_kurto_FFT1_02', 'b_kurto_FFT1_03', 'b_kurto_FFT1_04', 'b_kurto_FFT1_05', 'b_kurto_FFT1_06', 'b_kurto_FFT1_07', 'b_kurto_FFT1_08', 'b_kurto_FFT1_09', 'b_kurto_FFT1_10', 'b_kurto_FFT1_11')
group by b.id
having maxdiff <= 100 and meandiff <= 64
order by distance limit 30;
В качестве примера, приведу результат работы запроса из трёх образцов песен, взятых с альбома “Songs of Darkness, Words of Light” группы My Dying Bride:
Эти композиции являются хорошим образцом жанра death-doom metal.
Посмотрим, выдача размером в 30 композиций выглядит следующим образом:
Плюс ещё 3 нерелевантных трека и 1 дубликат того что уже есть в списке. По-моему, уже достаточно приемлемо. Во всяком случае, я бы не отвергал такой плейлист, если бы захотелось послушать чего-то «в духе MDB».
- F.U.B.A.R. — Crawling Релевантность, пожалуй, только по фактуре гитарного звука.
- The Soundbyte — The Dark Много электроники, но по атмосфере совпадение отличное.
- AHAB — Ahabs Oath В точку!
- Gorement — Into Shadows Чуть более экстремально чем образец, тем не менее очень близко.
- Tombs — Marina Абстрактный сладж-дум, по фактуре похож.
- Esoteric — Allegiance В точку!
- Autechre — Eutow Очень неожиданный вариант, но если послушать, то можно почувствовать параллели по фактуре звука.
- Entombed — Retaliation Не в точку, но очень близко.
- Quake Mission Pack 1 — Scourge of Armagon — 04-music-track-4.mp3 Смешной вариант, но в целом релевантность оказалась высокая.
- Nile — Divine Intent Первая часть песни в точку, дальше звучит более интенсивно, чем образцы.
- Янтарные Слёзы — За Край Небес В точку!
- NEUROSIS — Times of grace Слегка другой жанр, но релевантность высокая.
- Young Widows — In And Out Of Youth Высокая релевантность.
- Empyrium — Autumn Grey Views Тоже дум-метал.
- Dark Tranquillity — Hours Passed In Exile Более экстремально, но релевантность хорошая.
- Shape of Despair – Quiet These Paintings Are В точку!
- Rosetta — A Determinism of Morality Высокая релевантность.
- Solstafir – Ghosts of Light Очень высокая релевантность.
- Led Zeppelin — Ten Years Gone Неожиданный вариант, но в целом тоже принимается.
- Typhus — ***CENSORED*** Релевантность высокая, название трека зацензурировал как неприличное для сайта.
- Voivod — Divine Sun Релевантность приемлемая.
- Cradle of Filth — Malice Through The Looking Glass Очень хороший, хотя и неожиданный вариант.
- Suffocation — Redemption Релевантность портится из-за большей экстремальности.
- Nihilist –Abnormally Deceased Совпадение по фактуре гитарного звука.
- Reverend Bizarre – The Gate of Nanna В точку!
- Goresleeps — Avalon Dreams (The Voice From Legend) В точку!
Плюс ещё 3 нерелевантных трека и 1 дубликат того что уже есть в списке. По-моему, уже достаточно приемлемо. Во всяком случае, я бы не отвергал такой плейлист, если бы захотелось послушать чего-то «в духе MDB».
Мог бы привести другие примеры, но в целом хочу сказать, что пока наиболее простым по идентификации жанром для программы является эмбиент (Aidan Baker, Tetsu Inoue, Lustmord и другие, тысячи их).
Недостатки
Конечно, они тоже есть, прежде всего из-за того что алгоритм сравнения далёк от совершенства.
- Программа не учитывает среднюю громкость. Поэтому, кстати, в выдаче могут вылезти песни 80-х, в то время как образец из 2000-х, когда война громкостей уже была на исходе.
- По моей БД регулярно появляются заведомо нерелевантные композиции из ограниченного списка, наличие которых в результатах я пока объяснить не могу. Для таких случаев сделан список исключений.
- По-моему мнению, главный фейл – программа практически никогда не выдаёт песни с того же альбома, если в качестве образца уже взято несколько. В редких случаях одна-две, не более того.
- Похожий недостаток – вывести все песни, скажем, Земфиры, задав в качестве образца две-три её же песни. Голос, конечно, отличительная особенность, но фоновые инструменты, звучащие по-разному в разных композициях нарушат условия для благоприятного поиска. Возможно, если повысить разрешение анализа по частотам и добавить количество образцов по каждой песне, то на что-то можно надеяться, но тогда скорость работы может сильно упасть.
- Центральные моменты N-го порядка в целом неплохо характеризуют композиции, но две из них (skewness & kurtosis) трудно привязать к слышимым характеристикам звука. Может быть, это и не настолько плохо, но хотелось бы иметь более понимаемые метрики.
- Скорость работы: в среднем по минуте ожидания на каждый трек в списке образцов – в целом терпимо, но очень хотелось бы быстрее. Текущая архитектура запроса с сортировкой по возрастанию неизбежно заставляет SQLite делать полный прогон всех композиций, не смотря на наличие индексов, отключение же сортировки может многократно ускорить работу. Кстати, на случай работы без сортировки предусмотрены дополнительные методы отбора вариантов.
Исходники выложил на Github. (Кое-как удалось сделать пуш репозитория, первый раз в жизни, эхехех. Желающие помочь с выкладкой — прошу в ЛС, нужна небольшая консультация)
Для нежелающих возиться с гитхабом, выложил бинарники на гугл.драйв. Нужно нажать Ctrl+S чтобы сохранить архив себе.
По первым пользователям стало понятно что не у всех стоит ACM-кодек MP3, из-за этого файлы могут не обрабатываться. Не уверен, но скорее всего должна помочь установка K-Lite Codec Pack, например.
Прошу сильно строго не судить, делается всё на энтузиазме. Программирование на C# не является для меня основным профессиональным занятием.
Программа умеет сохранять и открывать плейлист, по двойному клику из списка образцов и списка результатов треки также можно открывать на прослушивание.
Если найдутся желающие помочь с оптимизацией SQL-запроса или формулированию дополнительных метрик кроме вышеописанных — пишите личные сообщения, буду рад сотрудничеству.
Если возникнут какие-либо ошибки при попытке запуска программы — тем более пишите, постараюсь помочь во всём.
Бонус: немного графиков по результатам анализа моей коллекции
Медиана частоты №10 из 31 против крутизны
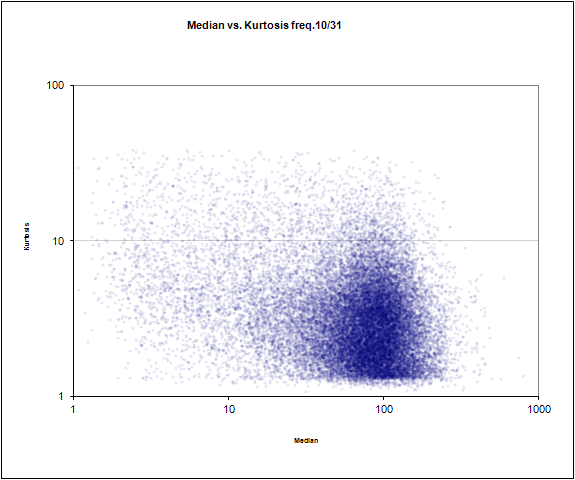
Медиана частоты №10 из 31 против скоса
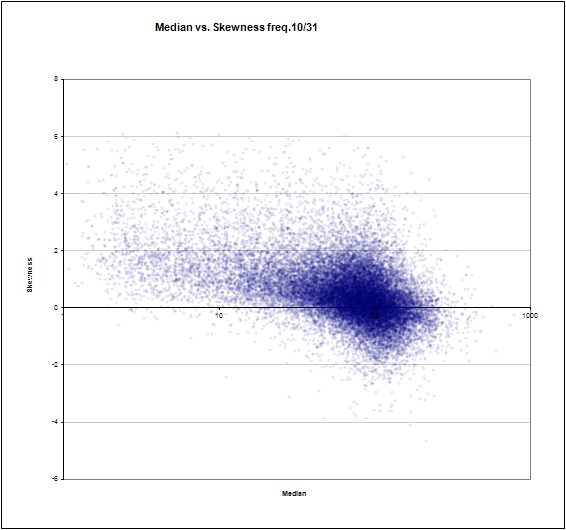
Медиана частоты №10 из 31 против стандартного отклонения

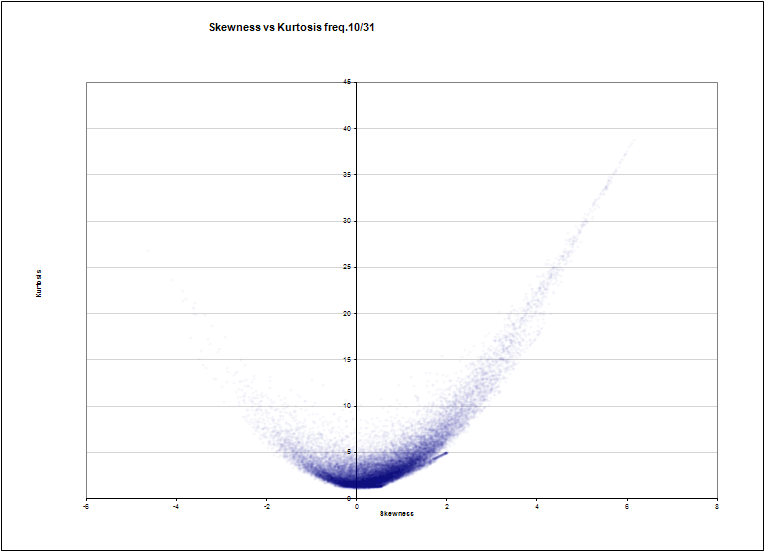
Крутизна частоты №10 из 31 против скоса (обычная зашумлённая парабола, не так ли?)
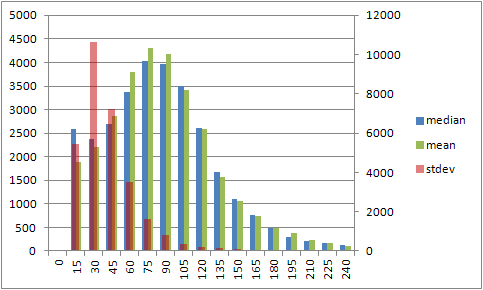
Гистограмма распределения среднего и медианы по левой оси и стандартного отклонения по правой
Пример среднего значения по всем частотам (делалось для базы по 100 частотам, отнормировано по среднему значению)

График сглаженного значения скоса по всем частотам (100 частот, отнормировано по среднему значению)

Медиана частоты №10 из 31 против скоса
Медиана частоты №10 из 31 против стандартного отклонения
Крутизна частоты №10 из 31 против скоса (обычная зашумлённая парабола, не так ли?)
Гистограмма распределения среднего и медианы по левой оси и стандартного отклонения по правой
Пример среднего значения по всем частотам (делалось для базы по 100 частотам, отнормировано по среднему значению)
График сглаженного значения скоса по всем частотам (100 частот, отнормировано по среднему значению)
