Введение
В это статье я расскажу о применении инструмента изначально предназначенного для функционального тестирования при тестировании нагрузочном web части системы электронного документооборота (СЭД).
Зачем вообще это понадобилось? Мы преследовал две цели – введение автоматических тестов для наших web-приложений и создание нагрузочных тестов на основе функциональных тестов.
Почему для теста использовался именно Selenium, а не более подходящий инструмент – LoadRunner, jMeter? С помощью LoadRunner’s нагрузочный тест был проведён, но результаты были поставлены под сомнения – при эмуляции двухсот пользователей страницы загружалась за 2 секунды плюс-минус 2%, хотя при открытии этих же страниц из браузера отображение происходило более чем за 3 секунды. Так что хотелось провести нагрузочные тесты максимально приближенные к реальности, а это можно сделать только с помощью полной эмуляции поведения пользователя. Для этого как раз подходили инструменты для функционального тестирования с их работой с браузерами – сайт открывался бы через обычный браузер, т.е. так как делал бы это пользователь.
Про Selenium
Для функционального тестирования был выбран именно Selenium по простой причине – он лучший из бесплатных инструментов для функционального тестирования. Если точнее – у него хорошая поддержка удалённого управления (Selenium Server, Selenium Grid), много документации (в том числе и на русском языке ( habrahabr.ru/post/151715 habrahabr.ru/post/152653 ) и поддержка всех основных браузеров (хотя это уже больше заслуга WebDriver).
Общая архитектура
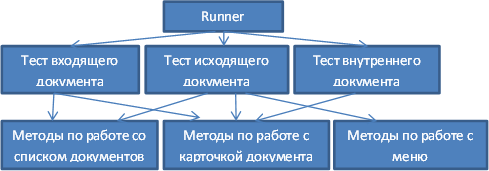
Приложение разделено на уровни (для наглядности на схеме элементы каждого уровня имеют осмысленные названия, а не просто Тест 1, Методы 2).
Первый уровень – уровень «запускальщика» тестов. Он просто запускает тесты. В настройках конфигурируется количество потоков, количество запусков теста, классы теста.
Второй уровень – сами тесты. Они выполняют бизнес операции – авторизируются, открывают списки документов, открывают документа, переходят по вкладкам документов.
Третий уровень – уровень работы с web-элементами. В нём содержаться атомарные пользовательские операции по работе с системой – открытие списка документов, переход к определённому документу, работа с вкладками документа.
Для начала перечисленных действий будет достаточно для обеспечения минимальной работы с системой. В дальнейшем они будут добавляться.
Разделение на эти уровни даёт следующее выгоду – можно запускать тесты как с «запускальщикам», так и без – просто запуск одного теста из среды разработки. Вынесение атомарных пользовательских операций на отдельный уровень позволит в дальнейшем отказаться от написания тестов на Java, а разработать свой DSL ( ru.wikipedia.org/wiki/Предметно-ориентированный_язык_программирования) для того, что бы тесты могли писать любые люди.
Запуск тестов
Программа для запуска jUnit тестов довольно проста и состоит из трёх классов – класс, который выполняет указанные тесты в своём потоке; класс «слушателя» jUnit теста для подсчёта времени выполнения теста; класс для формирования потоков и их запуска.
Код Runner’а
final int threadCount = readThreadCount();
final int invocationCount = readInvocationCount();
final List<Class> testClasses = readTestClasses();
ExecutorService taskExecutor = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
taskExecutor.execute(new TestRunner(invocationCount, testClasses));
}
taskExecutor.shutdown();
taskExecutor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
Код класса запускающего тесты
public class TestRunner implements Runnable {
public void run() {
JUnitCore jUnitRunner = new JUnitCore();
jUnitRunner.addListener(new TimeListener());
for (int i = 0; i < invocationCount; i++) {
for (Class clazz : testClasses) {
jUnitRunner.run(clazz);
}
Thread.sleep(invocationTimeOut);
}
}
}
Код listener’а
public class TimeListener extends RunListener {
private EtmPoint point;
public void testStarted(Description description) throws Exception {
point = EtmManager.getEtmMonitor().createPoint(description.getClassName() + "." + description.getMethodName(););
}
public void testFinished(Description description) throws Exception {
point.collect();
}
public void testFailure(Failure failure) throws Exception {
log.error("Error in test.", failure.getException());
}
}
Тесты
Тесты были написаны простые, но, тем не менее, отражающие работу пользователя – открытие списка документов, открытие карточки документа, переход по вкладкам карточки.
Для написания тестов использовался jUnit. Хотя также можно использовать TestNG, который поддерживает параллельный запуск тестов (а при нагрузочном тестировании это обязательное требование). Но выбран был именно jUnit по двум причинам: 1) в компании он широко распространён и давно используется 2) нужно было всё равно писать свой «запускальщик» который бы позволил, не изменяя тесты, запускать их в разных потоках (в TestNG параллельный запуск настраивается в самих тестах) и собирать статистику по их выполнению.
Помимо тестов были написаны дополнительные модули – pool webdriver’ов (здесь слово webdriver используется в терминологии Selenium’а), pool пользователей, pool документов, rule (в терминологии jUnit) по снятию скриншотов при ошибке, rule по выдаче webdriver тесту, rule авторизации.
Pool webdriver’ов – это класс, который управляет получением webdriver из сервера Selenium’а и распределяет их между тестами. Нужен для того, что бы абстрагировать работу с Selenium’ом – тесты будут получать webdriver’ы и отдавать их этому pool’у. Webdriver’ы при этом не закрываются (не вызывается метод close). Это нужно потому, что бы не перезапускать браузер. Т.е. таким образом получается «реиспользование» webdriver’ов другими тестами. Но повторное использование имеет свои минусы – при возвращении webdriver’а в pool нужно «подчистить» за собой – удалить все cookie или, если это сделать нельзя, выполнить logout.
Так же, как в последствии выяснилось, этот pool должен перезапускать webdriver’ы, сессия которых завершилась. Такое возможно, когда произошла ошибка на стороне сервера.
Pool пользователей нужен в основном при нагрузочном тестировании, когда нужно запускать одинаковые тесты под различными пользователями. Он всего лишь по кругу отдаёт логин/пароль очередного пользователя.
Pool документов, так же как и пользователей, нужен в основном при нагрузочной тестировании – он по кругу возвращает id документов определённого типа.
Rule по снятию скриншотов при ошибке, нужен, как следует из названия, снимать скриншот при ошибке выполнения теста. Он сохраняет его в папку и записывает в лог название скриншота со stacktrace’ом ошибки. Очень помогает в дальнейшем «увидеть» ошибку, а не только прочитать её в логах. ( internetka.in.ua/selenium-rule-screenshot )
Rule по выдаче webdriver’а тесту нужен для того, что бы автоматизировать получение перед началом тестового метода и возврат при его окончании webdriver’а из pool’а webdriver’ов.
Rule авторизации нужен так же для автоматизации, только теперь авторизации – что бы в каждом тестовом методе не писать login\logout.
Сбор статистики
Для сбора статистики было решено не изобретать велосипед, а использовать что-нибудь из готовых framework’ов. Поиск в интернете, к сожалению, не дал широкого выбора – всего один инструмент – JETM (http://jetm.void.fm/), да и он уже не изменялся с 2009 года. Хотя обладает хорошей документацией и небольшой плюсы – удалённое подключение по HTTP для просмотра статистики в реальном времени.
Код конфигурации монитора и запуска http-консоли:
BasicEtmConfigurator.configure();
EtmMonitor etmMonitor = EtmManager.getEtmMonitor();
etmMonitor.start();
HttpConsoleServer server = new HttpConsoleServer(etmMonitor);
server.start();
Сбор статистики происходил из двух мест – собиралось общее время выполнение тестовых методов (из уровня «запускальщика») и время выполнения атомарных пользовательских операций (из третьего уровня). Для решения первой проблемы использовался наследник RunListener’а, в котором переопределялись методы начала и окончания теста и в них собиралась информация о выполнении.
Решение второй проблемы можно было выполнить «в лоб» — в начале и конце каждого метода, время выполнения которого нужно записывать, писать код для отсчёта этого времени. Но так как методов уже сейчас больше пяти, а в дальнейшем их будет гораздо больше, то хотелось бы это автоматизировать. Для этого воспользовался AOP, а конкретно AspectJ. Был написан простой аспект, который добавлял подсчёт времени выполнения всех public методов из классов с пользовательскими операциями. Время подсчитывалось только успешно выполненных методов, что бы методы, вылетевшие с ошибкой на середине выполнения, не портили статистику. Так же обнаружился один недочёт при сборе статистики по названиям методов – так как методы по работе с пользовательскими операциями были универсальны и вызывались всеми тестами, но статистику нужно было собирать по типам документов. Поэтому статистика собиралась не только по названию методов, но ещё и по их аргументам, идентифицирующих тип документа.
Код метода аспекта
@Around("execution(public static * <Пакет с классами пользовательских операций>.*.*(..))")
public Object profileMethod(ProceedingJoinPoint thisJoinPoint) throws Throwable {
EtmPoint point = EtmManager.getEtmMonitor().createPoint(getPointName(thisJoinPoint));
Object result = thisJoinPoint.proceed();
point.collect();
return result;
}
Метод getPointName формирует название точки среза времени на основе названия метода и его параметров.
Браузеры для нагрузочного тестирования
После написания всех тестов встал вопрос, на каких браузерах его запускать. В случае функционального тестирования здесь всё просто – нужно запускать тесты на тех браузерах, на которых будут работать пользователи. Для нас это IE 9. Поэтому попробовал запустить тесты на IE с несколькими экземплярами браузера на машину, что бы один компьютер смог эмулировать работу нескольких пользователей (В Selenium один WebDriver – это один экземпляр браузера). В результате на моей машине (4Гб ОЗУ, 2.3 Core 2 Duo) нормально работало только 4 экземпляра IE. Что не очень хорошо – для эмуляции двухсот пользователей потребуется 50 машин. Нужно было искать альтернативу. А это: а) другие desktop браузеры б) headless браузеры.
Из desktop браузеров протестированы были FF и Chrome. С Chrome ситуация была аналогичная, плюс он для своей работы требовал запуска в отдельном процессе WebDriver’а на каждый экземпляр Chrome. Что повышало требования к ресурсам. С FF ситуация была чуть лучше – нормально работало 5 браузеров без дополнительного запуска WebDriver’ов. Но ситуацию это не сильно улучшило.
Тогда бы пришлось тестировать headless браузеры – браузеры, которые полностью работают с сайтом (строят DOM, выполняют JS), но не отображают его. По идее они должны работать быстрее. Из всех headless браузеров остановился на 2 – PhantomJS и HttpUnit. Перспективно выглядел PhantomJS, основанный на Webkit. Но по факту он ни чем не отличался от FF по потреблению ресурсов, но имел следующие минусы – иногда не находил элементы на странице и не корректно отображал сайт на скриншотах. Так что не удавалось понять, почему произошла ошибка. С HtmlUnit всё гораздо проще – его webdriver не поддерживал alert, а это для нашего web приложения было критично.
В итоге вернулись к использованию FF в нагрузочном тестировании. Хотя в нём тоже возникли проблемы с alert’ами – иногда возникали ошибки java.lang.Boolean cannot be cast to java.lang.String (java.lang.ClassCastException) (вот ссылка на ошибку в Google Code code.google.com/p/selenium/issues/detail?id=3565). Исправить эту ошибку не получилось, но зато получилось отказаться совсем от alert’ов. Так что в дальнейшем можно попробовать опять использовать HtmlUnit. Хотя у всех headless браузеров есть одно общее неудобство, связанное с их спецификой, — они не отображают страницы и так просто нельзя понять, из-за чего произошла ошибка. Возможность снятия скриншота не сильно помогает – иногда он не информативен.
Конфигурация Selenium’а
Сервер Selenium’а поддерживает запуск в двух режимах – как standalone сервер (режим запуска по умолчанию) и как часть общей сети из Selenium серверов – Selenium Grid (режимы запуска с –role hub и –role node). Так как нам нужно было использовать большое количество компьютеров, то первый режим не очень подходит – в этом случае нужно будет управлять каждым сервером в отдельности. Т.е., по сути, писать свой менеджер серверов. Хотя, по началу, мне это вариант импонировал – в таком случае у нас будет полный контроль над тем, на какой машине какой браузер запускать. Но в дальнейшем я от него отказался – полный контроль над запуском браузеров оказался не нужен, плюс Selenium Grid подкупил своей простотой в использовании. (ссылка на страницу конфигурации Selenium Grid code.google.com/p/selenium/wiki/Grid2)
В итоге пришли к следующей конфигурации: На одном компьютере запускался Selenium в режиме hub с дополнительным параметром –timeout 0. Это нужно было потому, что иногда сессии закрывались по timeout из за длительного бездействия тестов. На других компьютерах запускался Selenium в режиме node. Для мощных компьютеров, способных обеспечить работу 15 браузеров, node Selenium’а запускался с дополнительной настройкой, позволяющей запускать 15 копий FF и указывающей, что одновременно можно работать с 15 сессиями.
Проведение тестов
Тесты проводились следующим образом – на одном компьютере запускался один экземпляр браузера, который выполнял тестовые сценарии несколько раз и с которого снимали время выполнения. На остальных компьютерах запускались те же тестовые сценарии, но уже на нескольких браузерах. Такое разделение для замера времени нужно для того, что бы одновременная работа браузеров не отражалась на результате измерения. Так как если делать те же измерения на нескольких запущенных браузерах, то время будет чуть больше.
Пару слов нужно сказать о тестовых сценариях и подсчёте времени их выполнения. Каждый сценарий включал в себя открытие документов каждого типа. Т.е. сначала открывался входящий документ, потом исходящий документа и т.д. Вот здесь нужно учесть следующую ситуацию – если нужно снять время открытия только входящего документа, и при этом запустить на всех машинах выполнения только это сценария, то время будет существенно меньше (на 50%) чем, если бы снимать время при одновременном выполнении всех сценариев. В моём случае, скорее всего это было связано с кешированием на уровнях web приложения и СУБД. И тем, что открывалось мало уникальных документов. Возможно, при большом количестве разных документов различия будут не столь существенны.
В идеале хотелось бы получить распределение пользователей и документов таким, каким оно будет в реально работающей системе. Т.е., например, в реальной системе будет 10 человек работать с входящими и 30 с исходящими. И в нагрузочном тесте так же отразить это соотношение – количество тестов по исходящим в три раза больше чем с входящими документами. Но так как ещё тестируемая система пока не вошла в эксплуатацию и этих данных пока нет, то тестирования происходило без их учёта.
Подведение итогов
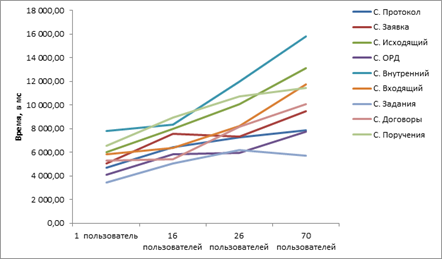
В результате тестов для 1-го, 16-ти, 26-ти и 70 пользователей был составлен график по каждым сценариям. Пока ещё количество пользователей не слишком большое, что бы сделать точные выводы, но уже сейчас можно проследить темпы роста времени.
Зависимость времени открытия документов от количества работающих пользователей:

Зависимость времени списка документов от количества работающих пользователей:
Дальше тесты будут продолжаться, что бы построить график до 200 пользователей. В результате должен получиться график, похожий на этот (взят из msdn.microsoft.com/en-us/library/bb924375.aspx):
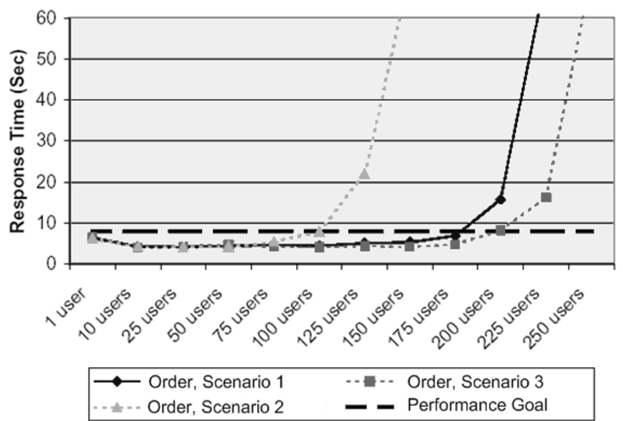
По нему уже можно будет точно определить возможности системы и найти её узкие места.
