При оптимизации времени выполнения алгоритма, использующего LDPC декодер, профайлер привел к функции, вычисляющей следующее значение:
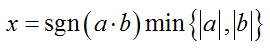
где a и b — целые числа. Количество вызовов шло на миллионы, а реализация ее была достаточно проста и бесхитростна:
Функция состоит, по сути, из трех последовательных операций сравнения. Это дает (с учетом оптимизации компилятора) два (если числа разных знаков) или три (если одного) условных перехода для получения результата. Вспомнив о потенциальных проблемах конвеера при большом количестве условных переходов, было решено уменьшить их количество или даже избавиться от них. Для оценки быстродействия был написан небольшой
Для начала, закомментируем вызов расчетной функции чтобы оценить время выполнения цикла с генерацией случайных чисел (к сожалению, вызов QueryPerformanceCounter() сам по себе довольно медленный и приводит к значительному искажению результата если его делать внутри цикла). Запускаем проект несколько раз, чтобы убедится в повторяемости результата. На машине с процессором Intel Core i7-3770 c частотой 3.4 ГГц время выполнения составляет в среднем 9.2 секунды. Если раскомментировать вызов расчетной функции, пересобрать проект и повторить эксперимент — получаем примерно 11.5 секунд. Прирост времени выполнения налицо, с ним и будем бороться.
Попробуем избавиться от условных операторов. Для начала выясним знак произведения a и b. Вычислять его в лоб некорректно из-за возможного переполнения. Так как нам важен только знак (то есть значение бита знакового разряда целого числа), то уместно воспользоваться операцией xor для определения знака произведения a и b. Далее, сдвинем результат a xor b вправо на 31 бит (оставляя только знаковый разряд) и получим 0 в случае неотрицательного числа и 1 в случае отрицательного. Умножим это значение на два, вычтем из единицы и получим -1 для отрицательного числа и 1 для неотрицательного:
Заменим вызов LLR() на LLR_2() и посмотрим, что получилось. В ассемблерном коде теперь ни одного условного перехода, зато появились три инструкции целочисленного умножения imul (умножение на 2 компилятор сам заменяет на сдвиг). Прогнав тестовую программу, получаем следующий результат — время выполнения составляет 9.4 секунды! Итого, сравнивая времена «нетто» (2.1 и 0.2 секунды соответственно) для двух вариантов расчета искомого значения, получаем десятикратное* увеличение скорости выполнения требуемой операции.
Попробуем пойти еще немного дальше. Целочисленное умножение необходимо только для перемены знака числа, которую можно выполнить напрямую. В частности, вычисление модуля числа a можно реализовать следующим образом:
Заменяем вызов LLR()_2 на LLR_3() и видим, что значимого прироста это не дает (время выполнения составляет примерно те же 9.4 секунды с небольшой разницей в третьем знаке в меньшую сторону). Получается, что imul на современных процессорах выполняется довольно быстро!
Вернемся к алгоритму, с которого все началось. Описанной оптимизацией только лишь одной функции удалось сократить время обработки единичного блока данных со 160 до 140 секунд (при выполнении на i7), что составляет более 10% и является весьма неплохим результатом. На очереди еще несколько похожих функций…
Ну и напоследок предлагаю вариант реализации функции определения максимума двух целых 32-разряздных чисел. Написан он был уже чисто из академического любопытства. Желающие могут не спешить заглядывать под спойлер и попробовать реализовать подобное сами. Вариант без условных переходов работает примерно втрое быстрей стандартного макроса __max() (при выполнении на i7). Удачи в оптимизации ваших программ!
*UPD. В комментариях пользователь shodan привел пример, в котором rand() убран из подсчета времени, а чтение данных производится из заранее сформированного массива. В этом случае прирост производительности приблизительно трехкратный. По-видимому, это связано с более эффективной работой конвеера при чтении данных из массива.
где a и b — целые числа. Количество вызовов шло на миллионы, а реализация ее была достаточно проста и бесхитростна:
int LLR(int a, int b)
{
if (a>0)
return (b>0) ? __min(a,b) : -__min(a,-b);
else
return (b>0) ? -__min(-a,b) : __min(-a,-b);
}
Функция состоит, по сути, из трех последовательных операций сравнения. Это дает (с учетом оптимизации компилятора) два (если числа разных знаков) или три (если одного) условных перехода для получения результата. Вспомнив о потенциальных проблемах конвеера при большом количестве условных переходов, было решено уменьшить их количество или даже избавиться от них. Для оценки быстродействия был написан небольшой
тестовый проект
Сборка производилась в MSVS 2008 в конфигурации Release (настройки по умолчанию) для платформы x86.
#include <Windows.h>
static inline int LLR(int a, int b)
{
if (a>0)
return (b>0) ? __min(a,b) : -__min(a,-b);
else
return (b>0) ? -__min(-a,b) : __min(-a,-b);
}
int _tmain(int argc, _TCHAR* argv[])
{
SetPriorityClass(GetCurrentProcess(),REALTIME_PRIORITY_CLASS);
SetThreadPriority(GetCurrentThread(),THREAD_PRIORITY_TIME_CRITICAL);
srand(0);
int x(0);
__int64 t1,t2;
QueryPerformanceCounter((LARGE_INTEGER*)&t1);
for (size_t i=0;i<MAXUINT>>4;i++)
{
int a = rand() - RAND_MAX / 2;
int b = rand() - RAND_MAX / 2;
/* x += LLR(a,b);*/
}
QueryPerformanceCounter((LARGE_INTEGER*)&t2);
t2 -= t1;
QueryPerformanceFrequency((LARGE_INTEGER*)&t1);
_tprintf_s(_T("%f"),t2/(t1*1.));
return 0;
}
Сборка производилась в MSVS 2008 в конфигурации Release (настройки по умолчанию) для платформы x86.
Для начала, закомментируем вызов расчетной функции чтобы оценить время выполнения цикла с генерацией случайных чисел (к сожалению, вызов QueryPerformanceCounter() сам по себе довольно медленный и приводит к значительному искажению результата если его делать внутри цикла). Запускаем проект несколько раз, чтобы убедится в повторяемости результата. На машине с процессором Intel Core i7-3770 c частотой 3.4 ГГц время выполнения составляет в среднем 9.2 секунды. Если раскомментировать вызов расчетной функции, пересобрать проект и повторить эксперимент — получаем примерно 11.5 секунд. Прирост времени выполнения налицо, с ним и будем бороться.
Попробуем избавиться от условных операторов. Для начала выясним знак произведения a и b. Вычислять его в лоб некорректно из-за возможного переполнения. Так как нам важен только знак (то есть значение бита знакового разряда целого числа), то уместно воспользоваться операцией xor для определения знака произведения a и b. Далее, сдвинем результат a xor b вправо на 31 бит (оставляя только знаковый разряд) и получим 0 в случае неотрицательного числа и 1 в случае отрицательного. Умножим это значение на два, вычтем из единицы и получим -1 для отрицательного числа и 1 для неотрицательного:
int sign = 1-2*((unsigned)a^b)>>31);
int c;
c = 1-2*(((unsigned)a)>>31);
a *= c;
c = 1-2*(((unsigned)b)>>31);
b *= c;
int numbers[2], min;
numbers[0] = b;
numbers[1] = a;
a -= b;
c = (unsigned(a))>>31;
min = numbers[c];
следующую функцию
static inline int LLR_2(int a, int b)
{
int sign, numbers[2];
sign = 1-2*(((unsigned)a^b)>>31);
a *= 1-2*(((unsigned)a)>>31);
b *= 1-2*(((unsigned)b)>>31);
numbers[0] = b;
numbers[1] = a;
a -= b;
return sign*numbers[((unsigned)a)>>31];
}
Заменим вызов LLR() на LLR_2() и посмотрим, что получилось. В ассемблерном коде теперь ни одного условного перехода, зато появились три инструкции целочисленного умножения imul (умножение на 2 компилятор сам заменяет на сдвиг). Прогнав тестовую программу, получаем следующий результат — время выполнения составляет 9.4 секунды! Итого, сравнивая времена «нетто» (2.1 и 0.2 секунды соответственно) для двух вариантов расчета искомого значения, получаем десятикратное* увеличение скорости выполнения требуемой операции.
Попробуем пойти еще немного дальше. Целочисленное умножение необходимо только для перемены знака числа, которую можно выполнить напрямую. В частности, вычисление модуля числа a можно реализовать следующим образом:
unsigned int mask[] = {0,(unsigned)-1};
unsigned int constant[] = {0, 1};
int c = ((unsigned)a)>>31;
a = a^mask[c]+constant[c];
третий вариант
static unsigned int mask[] = {0,(unsigned)-1};
static unsigned int constant[] = {0, 1};
static inline int LLR_3(int a, int b)
{
int sign,c, numbers[2];
sign = (_rotl(a^b,1) & 1);
c = ((_rotl(a,1) & 1));
a = (a^mask[c])+constant[c];
c = ((_rotl(b,1) & 1));
b = (b^mask[c])+constant[c];
numbers[0] = b;
numbers[1] = a;
c = ((_rotl(a-b,1) & 1));
return (numbers[c]^mask[sign])+constant[sign];
}
Заменяем вызов LLR()_2 на LLR_3() и видим, что значимого прироста это не дает (время выполнения составляет примерно те же 9.4 секунды с небольшой разницей в третьем знаке в меньшую сторону). Получается, что imul на современных процессорах выполняется довольно быстро!
Вернемся к алгоритму, с которого все началось. Описанной оптимизацией только лишь одной функции удалось сократить время обработки единичного блока данных со 160 до 140 секунд (при выполнении на i7), что составляет более 10% и является весьма неплохим результатом. На очереди еще несколько похожих функций…
Ну и напоследок предлагаю вариант реализации функции определения максимума двух целых 32-разряздных чисел. Написан он был уже чисто из академического любопытства. Желающие могут не спешить заглядывать под спойлер и попробовать реализовать подобное сами. Вариант без условных переходов работает примерно втрое быстрей стандартного макроса __max() (при выполнении на i7). Удачи в оптимизации ваших программ!
Скрытый текст
static inline int max(int a, int b)
{
int numbers[2][2];
numbers[0][0] = b;
numbers[0][1] = a;
numbers[1][0] = a;
numbers[1][1] = b;
int sign_a = (unsigned)a>>31;
int sign_b = (unsigned)b>>31;
int sign_ab = (unsigned)(a^b)>>31;
int abs_a = (1-2*sign_a)*a;
int abs_b = (1-2*sign_b)*b;
int sign_a_b = (unsigned)(abs_a-abs_b)>>31;
int c0 = sign_ab;
int c1 = ((1^(sign_a_b)^(sign_a | sign_b)) & (1^c0)) | (sign_ab & sign_a);
int result = numbers[c0][c1];
return result;
}
*UPD. В комментариях пользователь shodan привел пример, в котором rand() убран из подсчета времени, а чтение данных производится из заранее сформированного массива. В этом случае прирост производительности приблизительно трехкратный. По-видимому, это связано с более эффективной работой конвеера при чтении данных из массива.
