С распространением распределенных систем управления версиями (DVCS), таких как Git и Mercurial, я все чаще вижу дискуссии на тему правильного использования ветвления(брэнч) и слияния(мердж), и о том, как это укладывается в идею непрерывной интеграции (CI). В данном вопросе есть определенная неясность, особенно когда речь заходит о feature branching (ветвь на функциональность) и ее соответствие идеям CI.
Основная идея feature branch заключается в создании нового брэнча, когда вы начинаете работать над какой-то функциональностью. В DVCS вы делаете это в своем собственном репозитории, но те же принципы работают и в централизованных VCS.
Я проиллюстрирую свои мысли следующим рядом диаграмм. В них основная линия разработки (trunk) отмечена синим, и двое разработчиков, отмеченные зеленым и фиолетовым (Reverend Green и Professor Plum).
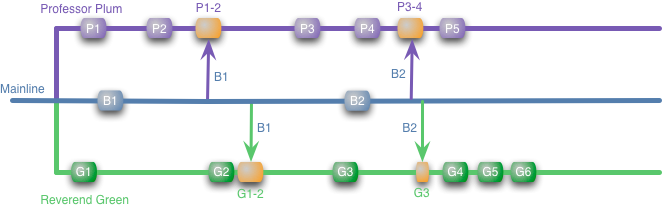
Я использую обозначенные цветные прямоугольники как обозначения локальным коммитам в брэнчи. Стрелки между брэнчами, обозначают слияния, оранжевые прямоугольники выделяют сами слияния. В этом примере, есть обновления в основной линии, скажем пара починенных багов. Когда это происходит, наши разработчики сливают их в свои локальные ветви. Для того, чтобы получить ощущение времени, давайте предположим, что речь идет о нескольких днях работы, когда каждый разработчик коммитит свои изменения примерно раз в день.
Чтобы убедиться что код работает, они могут запускать билды и тесты на свои ветки. В рамках данной статьи предположим, что вместе с каждым коммитом и мерджем бегут автоматические билды и тесты на брэнч, в который он был сделан.
Основное преимущество feature branching заключается в том, что каждый разработчик может работать над своей задачей и быть изолированным от того что происходит вокруг. Они могут сливать изменения из основной линии в своем собственном темпе и быть уверенными, что это не помешает разрабатываемой функциональности. Более того, это дает возможность команде выбрать, что из новых разработок внести в релиз, а что оставить на потом. Если Reverend Green опаздывает, мы можем предоставить версию только с изменениями Professor Plum. Или же мы можем наоборот, отложить дополнения профессора, быть может потому что мы не уверены, что они работают так, как мы хотим. В данном случае мы просто попросим профессора не сливать свои изменения в основную линию, до тех пор пока мы не будем готовы выпустить его функциональность. Такой подход дает нам возможность проявлять избирательность, команда решает какую функциональность сливать перед каждым релизом.
Несмотря на всю привлекательность этого образа, в данном подходе могут таиться определенные проблемы.
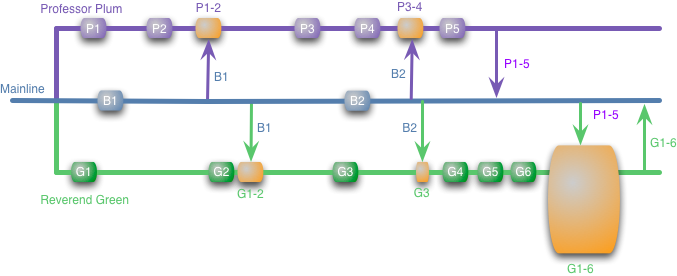
Хотя разработчики могут работать над своей функциональностью в изоляции, в какой то момент результат их трудов должен быть интегрирован. В нашем примере Professor Plum с легкостью обновляет основную линию своими изменениями, слияния нету, ведь он уже получил все изменения в основной линии в свою ветвь (и прошел билд). Однако не все так просто для Reverend Green, он должен слить все свои изменения (G1-6) с изменениями Professor Plum (P1-5).
(В этом примере многие пользователи DVCS могут почувствовать что я пропускаю многие детали, в таком простом, даже упрощенном объяснении feature branching. Я объясню более сложную схему позже.)
Я сделал этот прямоугольник мерджа огромным, потому что это опасный мердж. Он может пройти без проблем, вероятно, что разработчики работали над разными частями кода без интеракций, и тогда слияние пройдет гладко. Но они так же могли работать над частями которые взаимодействуют, и в тогда их ожидает кромешный ад.
Кошмары могут принимать различные формы, и инструменты разработки могут спасти от некоторых. Самые стандартные могут быть в трудностях слияния исходников, когда два разработчика работают над одними и теме же файлами. Современные DVCS неплохо справляются с подобными проблемами, иногда даже кажется, что не без помощи магии. Git имеет репутацию инструмента, который умеет хорошо разбираться со сложными конфликтами. Настолько хорошо, что мы даже оставим этот вопрос за рамками данной статьи.
Проблема которая беспокоит нас сильнее, это семантические конфликты. Самым простым примером может быть тот случай, в котором Professor Plum изменяет имя метода, который Reverend Green вызывает в своем коде. Инструменты для рефакторинга помогут вам переименовать метод без проблем, но только в вашем коде. Поэтому, если G1-6 содержат новый код, который вызывает foo, Professor Plum не узнает об этом, поскольку это изменение не находится в его брэнче. Осознание того, где собака зарыта к нам прийдет только в большом мердже.
Переименование функции является самым явным примером семантического конфликта. На практике они могут быть намного более скрытны. Тесты — ключ разгадки к ним, но чем больше кода надо слить, тем больше шансов на конфликты и тем сложнее их починить. Риск конфликтов в целом и семантических в частности делает большие слияния страшными.
Последствием страха перед большими мерджами является нежелание реафакторинга. Содержать код в чистоте требует постоянных усилий и чтобы в этом преуспеть каждый должен прибирать мусор когда его видит. Однако, такой рефакторинг в feature branch проблематичен, постольку поскольку он делает Большой Страшный Мердж еще больше и страшнее. В результате разработчики боятся рефакторинга как огня и код обрастает уродами.
В приведенной выше проблеме я вижу основную причину, по которой feature branching является плохой идеей. В тот момент когда команда боится рефакторинга для поддержания здорового кода — они в продолжительном пике без шансов на элегантный выход.
Именно эти проблемы и должна решать непрерывная интеграция. С CI моя диаграмма будет выглядеть так.
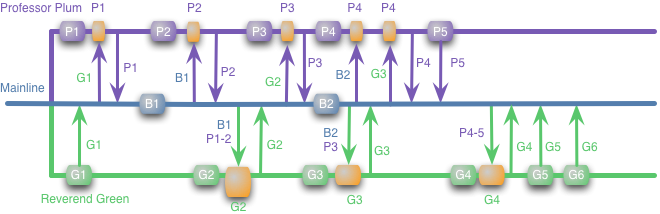
Здесь намного больше мерджей, но слияние это одно из тех вещей которые лучше делать понемногу часто чем редко и тоннами. В резулттате если Professor Plum изменяет часть кода на котором зависит Reverend Green, наш зеленый коллега выяснит это намного раньше, в мерждах P1-2. На данный момент ему нужно изменить G1-2 для работы с этими изменениями, вместо G1-6 (как это было в прошлом примере).
CI эффективен для нейтрализации проблем больших мерджей, но кроме этого это еще и критически важный коммуникационный механизм. В данном сценарии потенциальный конфликт проявится, когда Professor Plum сольет G1 и поймет что Reverend Green использует библиотеки профессора. Тогда Professor Plum может найти Reverend Green и вместе они могут обсудить взаимодействие их функциональности. Быть может функциональность Professor Pum требует некоторые изменения, которые не уживаются с функциональностью Reverend Green. Вдвоем они могут принять намного лучшие решения по дизайну, которые не помешают их работе. С изолированными брэнчами наши разработчики не узнают о проблеме до последнего момента, когда часто уже поздно чтобы решить конфликт безболезненно. Коммуникация одна из ключевых факторов в разработке программного обеспечения и одно из главных свойств CI — это содействие ей.
Важно упомянуть что в большинстве случаев feature branching имеет другой подход к CI. Один из принципов CI в том, что все коммитят в основную линию каждый день, так что если feature branch живет больше чем один день — это превращает его в что то очень далекое от CI. Я слышал людей, говорящих что они используют CI потому что их билды бегут на CI сервере, на каждой ветви и на каждый коммит. Это непрерывная сборка, и это хорошо, но тут нету интеграции, поэтому это и не CI.
Ранее я сказал в скобках, что есть и другие способы feature branching. Скажем Professor Plum и Reverend Green в начале итерации вместе заваривают ароматный зеленый чай и обсуждают свои задачи. Они обнаруживают что среди задач есть взаимодействующие части и решают интегрироваться между друг другом вот так:
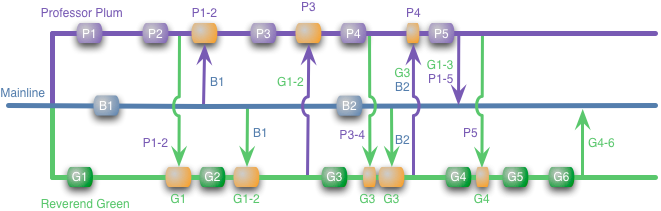
С таким подходом они сливаются с основной линией в конце, как и в первом примере, но они так же часто делают мерджи между собой, чтобы избежать Большого Страшного Мерджа. Идея в том что основное преимущество feature branching это изоляция. Когда вы изолируете изолируете ваши брэнчи, есть риск мерзкого конфликта, нарастающего вне вашего ведения. Тогда изоляция это иллюзия, которая болезненно разобьется раньше или позже.
Все же, это более трудоемкая интеграция является формой CI или речь идет совсем о другом звере? Я думаю, что они разные, опять же, ключевое свойство CI в том, что каждый интегрируется с основной линией каждый день. Интеграция среди feature branches, которую я с вашего позволения назову «беспорядочной интеграцией» (promiscuous integration, PI), не включает и даже не нуждается в основной линии. Я считаю что эта разница очень важна.
И все же, если PI отличается от CI, то при каких случая PI лучше чем CI?
С CI вы теряете возможность использовать систему управления версиями для выборочного подхода к изменениям. Каждый разработчик влияет на основную линию, поэтому вся функциональность растет в ней же. С CI, основная линия должна всегда быть здоровой, и в теории (а часто и на практике) вы можете делать релиз после каждого коммита. Имея полузаконченную функциональность, или функциональность которую вы предпочитаете не выпускать, вы не повредите функциональности всей системы, но потребует кое какой маскировки, чтобы спрятать это от пользовательского интерфейса, как например не включение нового пункта в меню.
В таких случаях PI может предоставить что то посередине.Это позволяет Reverend Green выбрать когда принять изменения Professor Plum. Если Professor Plum делает какие то изменения в API ядра системы в P2, Reverend Green может импортировать P1-2 но оставить остальные, до тех пор пока Professor Plum не закончит свою работу и не сольет в основную ветвь.
Однако в общем я не считаю что выборка функциональности для релиза с помощью VCS это хорошая идея.
Я предпочитаю проектировать программное обеспечение так, чтобы можно было включить и выключить функциональность при помощи изменения конфигурации. Для этого есть две полезные техники FeatureToggles и BranchByAbstraction. Они требуют от вас больше размышлений на тему того, что и как разделить на модули и как контролировать эти варианты, но мы пришли к выводу что результат намного более аккуратен, чем тот что выходит, если надеяться на VCS.
Что больше всего меня беспокоит в PI это его подверженность способностям коммуникации внутри команды. С CI основная линия служит коммуникационной точкой. Даже если Professor Plum и Reverend Green никогда не разговаривали, они найдут возникающий конфликт в день его формирования. С PI они будут должны заметить то, что работают над взаимодействующим кодом. Постоянно обновляющаяся основная линия способствует уверенности каждому в том, что он интегрируется со всеми, не надо выяснять кто чем занимается, соответственно и меньше шансов на изменения, которые остаются скрытыми до поздней интеграции.
PI возник из опен-сорса и, предположительно, менее интенсивный темп опен сорс проекта может быть фактором для него. В работе на полную ставку вы работаете немало часов в день над проектом. Это позволяет работать над функциональностью с приоритетами. С опен сорсом люди часто жертвуют час тут и пару дней там. Функциональность может занять одному разработчику не мало времени для выполнения, в то время когда другие, с большим количеством свободного времени, смогут довести свои изменения до приемлемого качества раньше. В такой ситуации выборочный подход может быть более важен.
Важно осознавать, что инструменты, которыми вы, пользуетесь не зависят от стратегии которую вы выбираете. Несмотря на то, что многие ассоциируют DVCS с feature branching, они могут быть использованы и с CI. Все, что вам нужно сделать, это пометить одну из веток как основную линию. Если все делают pull и push в эту ветку каждый день, тогда у вас есть самая что ни на есть основная линия. На самом деле, в хорошо дисциплинированной команде я предпочту использовать DVCS для CI проекта, чем централизованную VCS. С менее дисциплинированной командой я буду беспокоиться что использование DVCS подтолкнет людей к ветвям-долгожителям, в тот момент когда централизованная VCS и усложнение брэнчинга подтолкнет их к частым коммитам в основную линию.
P. S. От переводчика на изучение вопросов к подходам использования VCS меня сподвигла эта статья, благодаря которой я начал искать более подробные описания «правильного» использования бранчинга и натолкнулся на выше переведенный текст. Хотя я не претендую на качество перевода, мне просто хочется попасть в ленту к разработчикам и дать им повод задуматься от противоположного принятому в опен сорсе подходу (форкинг). Не бейте больно палками, но критикуйте конструктивно, я это делаю в первый раз :-).
Простой (изолированный) Feature Branch
Основная идея feature branch заключается в создании нового брэнча, когда вы начинаете работать над какой-то функциональностью. В DVCS вы делаете это в своем собственном репозитории, но те же принципы работают и в централизованных VCS.
Я проиллюстрирую свои мысли следующим рядом диаграмм. В них основная линия разработки (trunk) отмечена синим, и двое разработчиков, отмеченные зеленым и фиолетовым (Reverend Green и Professor Plum).
Я использую обозначенные цветные прямоугольники как обозначения локальным коммитам в брэнчи. Стрелки между брэнчами, обозначают слияния, оранжевые прямоугольники выделяют сами слияния. В этом примере, есть обновления в основной линии, скажем пара починенных багов. Когда это происходит, наши разработчики сливают их в свои локальные ветви. Для того, чтобы получить ощущение времени, давайте предположим, что речь идет о нескольких днях работы, когда каждый разработчик коммитит свои изменения примерно раз в день.
Чтобы убедиться что код работает, они могут запускать билды и тесты на свои ветки. В рамках данной статьи предположим, что вместе с каждым коммитом и мерджем бегут автоматические билды и тесты на брэнч, в который он был сделан.
Основное преимущество feature branching заключается в том, что каждый разработчик может работать над своей задачей и быть изолированным от того что происходит вокруг. Они могут сливать изменения из основной линии в своем собственном темпе и быть уверенными, что это не помешает разрабатываемой функциональности. Более того, это дает возможность команде выбрать, что из новых разработок внести в релиз, а что оставить на потом. Если Reverend Green опаздывает, мы можем предоставить версию только с изменениями Professor Plum. Или же мы можем наоборот, отложить дополнения профессора, быть может потому что мы не уверены, что они работают так, как мы хотим. В данном случае мы просто попросим профессора не сливать свои изменения в основную линию, до тех пор пока мы не будем готовы выпустить его функциональность. Такой подход дает нам возможность проявлять избирательность, команда решает какую функциональность сливать перед каждым релизом.
Несмотря на всю привлекательность этого образа, в данном подходе могут таиться определенные проблемы.
Хотя разработчики могут работать над своей функциональностью в изоляции, в какой то момент результат их трудов должен быть интегрирован. В нашем примере Professor Plum с легкостью обновляет основную линию своими изменениями, слияния нету, ведь он уже получил все изменения в основной линии в свою ветвь (и прошел билд). Однако не все так просто для Reverend Green, он должен слить все свои изменения (G1-6) с изменениями Professor Plum (P1-5).
(В этом примере многие пользователи DVCS могут почувствовать что я пропускаю многие детали, в таком простом, даже упрощенном объяснении feature branching. Я объясню более сложную схему позже.)
Я сделал этот прямоугольник мерджа огромным, потому что это опасный мердж. Он может пройти без проблем, вероятно, что разработчики работали над разными частями кода без интеракций, и тогда слияние пройдет гладко. Но они так же могли работать над частями которые взаимодействуют, и в тогда их ожидает кромешный ад.
Кошмары могут принимать различные формы, и инструменты разработки могут спасти от некоторых. Самые стандартные могут быть в трудностях слияния исходников, когда два разработчика работают над одними и теме же файлами. Современные DVCS неплохо справляются с подобными проблемами, иногда даже кажется, что не без помощи магии. Git имеет репутацию инструмента, который умеет хорошо разбираться со сложными конфликтами. Настолько хорошо, что мы даже оставим этот вопрос за рамками данной статьи.
Проблема которая беспокоит нас сильнее, это семантические конфликты. Самым простым примером может быть тот случай, в котором Professor Plum изменяет имя метода, который Reverend Green вызывает в своем коде. Инструменты для рефакторинга помогут вам переименовать метод без проблем, но только в вашем коде. Поэтому, если G1-6 содержат новый код, который вызывает foo, Professor Plum не узнает об этом, поскольку это изменение не находится в его брэнче. Осознание того, где собака зарыта к нам прийдет только в большом мердже.
Переименование функции является самым явным примером семантического конфликта. На практике они могут быть намного более скрытны. Тесты — ключ разгадки к ним, но чем больше кода надо слить, тем больше шансов на конфликты и тем сложнее их починить. Риск конфликтов в целом и семантических в частности делает большие слияния страшными.
Последствием страха перед большими мерджами является нежелание реафакторинга. Содержать код в чистоте требует постоянных усилий и чтобы в этом преуспеть каждый должен прибирать мусор когда его видит. Однако, такой рефакторинг в feature branch проблематичен, постольку поскольку он делает Большой Страшный Мердж еще больше и страшнее. В результате разработчики боятся рефакторинга как огня и код обрастает уродами.
В приведенной выше проблеме я вижу основную причину, по которой feature branching является плохой идеей. В тот момент когда команда боится рефакторинга для поддержания здорового кода — они в продолжительном пике без шансов на элегантный выход.
Непрерывная интеграция
Именно эти проблемы и должна решать непрерывная интеграция. С CI моя диаграмма будет выглядеть так.
Здесь намного больше мерджей, но слияние это одно из тех вещей которые лучше делать понемногу часто чем редко и тоннами. В резулттате если Professor Plum изменяет часть кода на котором зависит Reverend Green, наш зеленый коллега выяснит это намного раньше, в мерждах P1-2. На данный момент ему нужно изменить G1-2 для работы с этими изменениями, вместо G1-6 (как это было в прошлом примере).
CI эффективен для нейтрализации проблем больших мерджей, но кроме этого это еще и критически важный коммуникационный механизм. В данном сценарии потенциальный конфликт проявится, когда Professor Plum сольет G1 и поймет что Reverend Green использует библиотеки профессора. Тогда Professor Plum может найти Reverend Green и вместе они могут обсудить взаимодействие их функциональности. Быть может функциональность Professor Pum требует некоторые изменения, которые не уживаются с функциональностью Reverend Green. Вдвоем они могут принять намного лучшие решения по дизайну, которые не помешают их работе. С изолированными брэнчами наши разработчики не узнают о проблеме до последнего момента, когда часто уже поздно чтобы решить конфликт безболезненно. Коммуникация одна из ключевых факторов в разработке программного обеспечения и одно из главных свойств CI — это содействие ей.
Важно упомянуть что в большинстве случаев feature branching имеет другой подход к CI. Один из принципов CI в том, что все коммитят в основную линию каждый день, так что если feature branch живет больше чем один день — это превращает его в что то очень далекое от CI. Я слышал людей, говорящих что они используют CI потому что их билды бегут на CI сервере, на каждой ветви и на каждый коммит. Это непрерывная сборка, и это хорошо, но тут нету интеграции, поэтому это и не CI.
«Беспорядочная» интеграция
Ранее я сказал в скобках, что есть и другие способы feature branching. Скажем Professor Plum и Reverend Green в начале итерации вместе заваривают ароматный зеленый чай и обсуждают свои задачи. Они обнаруживают что среди задач есть взаимодействующие части и решают интегрироваться между друг другом вот так:
С таким подходом они сливаются с основной линией в конце, как и в первом примере, но они так же часто делают мерджи между собой, чтобы избежать Большого Страшного Мерджа. Идея в том что основное преимущество feature branching это изоляция. Когда вы изолируете изолируете ваши брэнчи, есть риск мерзкого конфликта, нарастающего вне вашего ведения. Тогда изоляция это иллюзия, которая болезненно разобьется раньше или позже.
Все же, это более трудоемкая интеграция является формой CI или речь идет совсем о другом звере? Я думаю, что они разные, опять же, ключевое свойство CI в том, что каждый интегрируется с основной линией каждый день. Интеграция среди feature branches, которую я с вашего позволения назову «беспорядочной интеграцией» (promiscuous integration, PI), не включает и даже не нуждается в основной линии. Я считаю что эта разница очень важна.
Я вижу CI в основном как средство для рождения release candidate на каждом коммите. Задача CI системы и процесс деплоймента опровергнуть готовность к продакшену текущего release candidate. Эта модель нуждается в какой то основной линии разработки которая представляет текущее состояние полной картины.
--Dave Farley
Беспорядочная интеграция vs непрерывная интеграция
И все же, если PI отличается от CI, то при каких случая PI лучше чем CI?
С CI вы теряете возможность использовать систему управления версиями для выборочного подхода к изменениям. Каждый разработчик влияет на основную линию, поэтому вся функциональность растет в ней же. С CI, основная линия должна всегда быть здоровой, и в теории (а часто и на практике) вы можете делать релиз после каждого коммита. Имея полузаконченную функциональность, или функциональность которую вы предпочитаете не выпускать, вы не повредите функциональности всей системы, но потребует кое какой маскировки, чтобы спрятать это от пользовательского интерфейса, как например не включение нового пункта в меню.
В таких случаях PI может предоставить что то посередине.Это позволяет Reverend Green выбрать когда принять изменения Professor Plum. Если Professor Plum делает какие то изменения в API ядра системы в P2, Reverend Green может импортировать P1-2 но оставить остальные, до тех пор пока Professor Plum не закончит свою работу и не сольет в основную ветвь.
Однако в общем я не считаю что выборка функциональности для релиза с помощью VCS это хорошая идея.
Feature branching это модулярная архитектура для нищих, вместо того чтобы строить систему с возможностью легкой замены функциональности при райнтайме/деплойменте, люди привязывают себя к source control для этого механизма через ручной мердж.
— Dan Bodart
Я предпочитаю проектировать программное обеспечение так, чтобы можно было включить и выключить функциональность при помощи изменения конфигурации. Для этого есть две полезные техники FeatureToggles и BranchByAbstraction. Они требуют от вас больше размышлений на тему того, что и как разделить на модули и как контролировать эти варианты, но мы пришли к выводу что результат намного более аккуратен, чем тот что выходит, если надеяться на VCS.
Что больше всего меня беспокоит в PI это его подверженность способностям коммуникации внутри команды. С CI основная линия служит коммуникационной точкой. Даже если Professor Plum и Reverend Green никогда не разговаривали, они найдут возникающий конфликт в день его формирования. С PI они будут должны заметить то, что работают над взаимодействующим кодом. Постоянно обновляющаяся основная линия способствует уверенности каждому в том, что он интегрируется со всеми, не надо выяснять кто чем занимается, соответственно и меньше шансов на изменения, которые остаются скрытыми до поздней интеграции.
PI возник из опен-сорса и, предположительно, менее интенсивный темп опен сорс проекта может быть фактором для него. В работе на полную ставку вы работаете немало часов в день над проектом. Это позволяет работать над функциональностью с приоритетами. С опен сорсом люди часто жертвуют час тут и пару дней там. Функциональность может занять одному разработчику не мало времени для выполнения, в то время когда другие, с большим количеством свободного времени, смогут довести свои изменения до приемлемого качества раньше. В такой ситуации выборочный подход может быть более важен.
Важно осознавать, что инструменты, которыми вы, пользуетесь не зависят от стратегии которую вы выбираете. Несмотря на то, что многие ассоциируют DVCS с feature branching, они могут быть использованы и с CI. Все, что вам нужно сделать, это пометить одну из веток как основную линию. Если все делают pull и push в эту ветку каждый день, тогда у вас есть самая что ни на есть основная линия. На самом деле, в хорошо дисциплинированной команде я предпочту использовать DVCS для CI проекта, чем централизованную VCS. С менее дисциплинированной командой я буду беспокоиться что использование DVCS подтолкнет людей к ветвям-долгожителям, в тот момент когда централизованная VCS и усложнение брэнчинга подтолкнет их к частым коммитам в основную линию.
P. S. От переводчика на изучение вопросов к подходам использования VCS меня сподвигла эта статья, благодаря которой я начал искать более подробные описания «правильного» использования бранчинга и натолкнулся на выше переведенный текст. Хотя я не претендую на качество перевода, мне просто хочется попасть в ленту к разработчикам и дать им повод задуматься от противоположного принятому в опен сорсе подходу (форкинг). Не бейте больно палками, но критикуйте конструктивно, я это делаю в первый раз :-).
