В этой статье я расскажу как мы построили процесс разработки сайта не поднимая локальных копий веб-сервера в небольшой команде разработчиков с использованием Xdebug на тестовом сервере и автоматического развертывания репозитория на боевой сервер.
в нашем случае проект существовал без репозитория, отдельная тема как его туда добавить(т.к. надо исключить массу файлов которые не нужно добавлять в репу), но допустим репа уже есть на Bitbucket, а файлы на сервере лежат в обычной директории
Если у вас еще не установлен Git — ставим
В PHPStorm прописываем путь до Git'а (это файл bin/git.exe) — Settings -> Version Control -> Git -> Path to Git executable
В PHPStorm вкладка VSC -> Checkout from Version Control -> Git
указываем имя новой директории проекта и путь к репозиторию, например
Теперь файлы которые вы правите локально будут автоматически загружаться на сервер.
Теперь после каждого push'а все файлы на сервере будут приводится к файлам из репозитория, можно такой же подход реализовать и на тест сервере, но в этом случае если один разработчик имеет незапушеные файлы, то на сервере они затрутся и их придется заново загружать.
Как установить его не буду описывать, будем считать что Xdebug установлен, правим конфиг /etc/php5/conf.d/xdebug.ini:
Обратите внимание на директиву remote_connect_back — она позволяет коннектиться не к заданному IP машины разработчика, а к IP клиента который находится в окружении PHP (REMOTE_ADDR), т.о. с Xdebug могут работать одновременно несколько человек. Это не значит что Xdebug будет запущен при каждом обращении к серверу, для его старта по прежнему требуется передать определенные cookies — подробнее
Вбиваем тут IDE key указанный нами в xdebug.idekey ключ PHPSTORM и появившиеся ссылки внизу перестакиваем на панель закладок
Настраивать в PHPStorm специально ничего не надо, все уже настроено, но на всякий случай настройки тут — Project Settings -> PHP -> Debug
теперь чтобы отладчик заработал нужно:
Поскольку соединение идет из вне, а многие теперь сидят за роутерами, то на роутере нужно сделать проброс порта 9000 на ваш локальный IP адрес, на D-link DIR 300 это выглядит примерно так:

Если debugger выдает ошибку, что не может найти соответствующий текущий исполняемый файл на локальной машине, то в настройках PHP -> Servers можно задать соответствие путей на сервере путям на локале.
Ссылки:
http://git-scm.com/
http://xdebug.org/
http://bitbucket.org/
http://jetbrains.com/phpstorm/
Немного о причинах НЕ поднимать локальную копию веб-сервера:
Но отказываясь от создания локальной копии сервера, мы теряем массу плюсов такого подхода:
Если отладку можно получить с помощью Xdebug, а скорость переехав на другой сервер, то третье преимущество может стать серьезной помехой, поэтому моя статья актуальна в первую очередь небольшим командам, где можно давать задачи т.о. чтобы они практически не пересекались между собой.
Есть еще один вариант организации серверов разработки — каждому участнику проекта создается своя копия файлов и домены на сервере, т.о. сервер один, причем удаленный, но при этом каждый разработчик не мешает другому… минус такого подхода в высокой сложности организации, особенно если у проекта много поддоменов.
- Если вы работаете под Windows, а веб-сервер на линукс, то локальный сервер для сложного портала(в котором много специфического софта) под винду поднять бывает вообще невозможно, остается поднимать копию на виртуальной машине, но в этом случае разница в настройке ПО разработчика между настройкой под виртуальную машину и настройкой под удаленный веб-сервер заключается лишь в IP адресе.
- Если таки поднимать локальную копию, то придется постоянно синхронизировать настройки ПО сервера, базу данных и кроме того остается вопрос как быть с крон-задачами, которые часто должны выполняться под утро.
- Если сайт распологается на нескольких серверах или даже отдельные его части занимают несколько серверов(например, масштабированные таблицы — часть таблицы на одном, часть на другом сервере), то все это тоже может сильно усложнить задачу создания локального сервера.
- Производительность вашей машины и сервера может сильно различаться, что может иметь влияние и на код.
- Далеко не все участники проекта могут распологать достаточными навыками системного администрирования.
Но отказываясь от создания локальной копии сервера, мы теряем массу плюсов такого подхода:
- Запуск интерпретатора из IDE и соответственно отладка.
- Скорость закачки файлов и пинг.
- Разработчики работают каждый со своей копией сервера, поэтому они друг другу никак не могут помешать.
Если отладку можно получить с помощью Xdebug, а скорость переехав на другой сервер, то третье преимущество может стать серьезной помехой, поэтому моя статья актуальна в первую очередь небольшим командам, где можно давать задачи т.о. чтобы они практически не пересекались между собой.
Есть еще один вариант организации серверов разработки — каждому участнику проекта создается своя копия файлов и домены на сервере, т.о. сервер один, причем удаленный, но при этом каждый разработчик не мешает другому… минус такого подхода в высокой сложности организации, особенно если у проекта много поддоменов.
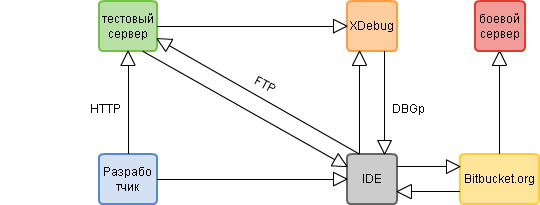
Пояснения к схеме:
- Разработчик имеет копию репозитория
- Тестовый и боевой веб-сервер в качестве корневой директории проекта имеет рабочую копию репозитория
- Файлы проекта связаны в PHPStorm с рабочей директорией тестового веб-сервера, это значит при Ctrl+S происходит автоматический аплод редактируемого файла на сервер
Как происходит разработка:
- разработчик правит код локально
- нажимает Ctrl+S файл загружается на сервер
- запускает в браузере нужную станицу тестового веб-сервера(или выполняет на ней нужное действие), смотрит результат
- если необходимо запускает дебаггер с помощью Xdebug
- если все устраивает делает коммиты в репозиторий и потом Push
- хранилище(в нашем случае это Bitbucket) автоматически после каждого Push'а опрашивает указанный скрипт на боевом сервере
- при опросе этот скрипт вызывает git pull и т.о. приводит рабочую директорию боевого веб-сервера до актуальной версии из репозитория
Подготовка сервера
в нашем случае проект существовал без репозитория, отдельная тема как его туда добавить(т.к. надо исключить массу файлов которые не нужно добавлять в репу), но допустим репа уже есть на Bitbucket, а файлы на сервере лежат в обычной директории
- логинимся под юзером проекта:
su myproject - генерим SSH ключи для авторизации на bitbucket без пароля
ssh-keygen -t rsa - получаем публичный ключ
и добавляем его на Bitbucket в раздел Deployment keys в настройках проектаcat ~/.ssh/id_rsa.pub - клонируем проект во временную директорию ~/tmp/myproject.ru:
mkdir ~/tmp mkdir ~/tmp/myproject.ru cd ~/tmp/myproject.ru git clone git@bitbucket.org:username/myproject.ru.git - копируем .git и .gitignore в рабочую директорию проекта (у нас это /vhosts/myproject.ru/), остальные файлы не копируем!
cp -r .git .gitignore /vhosts/myproject.ru/ rm -rf ~/tmp/myproject.ru - приводим файлы к состоянию из репозитория
cd /vhosts/myproject.ru git reset --hard
Подготовка клиента
Если у вас еще не установлен Git — ставим
В PHPStorm прописываем путь до Git'а (это файл bin/git.exe) — Settings -> Version Control -> Git -> Path to Git executable
Клонируем репозиторий:
В PHPStorm вкладка VSC -> Checkout from Version Control -> Git
указываем имя новой директории проекта и путь к репозиторию, например
username@bitbucket.org/username/myproject.ru.gitСихноризируем файлы с удаленным сервером:
- Добавляем сервер и указываем его доступы File -> Settings -> Deployment
- в Root path указываем путь до корня проекта (в моем случае /vhosts/myprojet.ru/) — корень проекта на сервере должен совпадать по иерархии файлов с корневой директорией репозитория
- Переходим во вкладку Mappings и указываем в Deployment path on server — / и в Web path on server тоже — / (если тот начинается с корня сайта)
- Выбираем наш сервер в списке и жмем на кнопку Use as default
- Далее в Deployment -> Options нужно выбрать On explicit save action (Ctrl+S) в Upload changed files automatically to the default server
- В Warn when uploading over newer file выбираем Compare timestamp & size (хотя можно и по содержимому) и отмечаем Notify about remote changes, это позволит узнать если кто-то правил тот же файл
Теперь файлы которые вы правите локально будут автоматически загружаться на сервер.
Настройка автопула на боевом сервере:
- Создаем shell скрипт для автоматического pull'а проекта /vhosts/myproject.ru/gitsync.sh:
Поскольку git выдает ошибку при pull, если добавлены новые файлы, но при этом не зафиксированы, а git reset --hard их не удаляет, то мы парсим вывод git status и удаляем новые файлы, чтобы они были загружены из репозитория, кроме того git reset --hard отменяет все изменения в файлах, чтобы не было конфликтов.#!/bin/sh cd /vhosts/myproject.ru && git reset --hard && git status --porcelain -uall | egrep '^\?\?' | awk '{ print $2; }' | xargs rm && git pull
Не забываем добавить права на исполнение скрипту
chmod a+x /vhosts/myproject.ru/gitsync.sh - Поскольку операции с репозиторием проходят от пользователя-владельца файлов, а веб-сервер работает от другого пользователя, то нужно ему добавить разрешение на запуск авто-pull скрипта от чужого имени без пароля через /etc/sudoers
# /etc/sudoers # # This file MUST be edited with the 'visudo' command as root. # # See the man page for details on how to write a sudoers file. # Defaults env_reset #Чтобы можно было выполнять sudo без терминала, т.е. прямо от веб-сервера Defaults:www-data !requiretty # Host alias specification # User alias specification # Cmnd alias specification # User privilege specification root ALL=(ALL) ALL # Allow members of group sudo to execute any command # (Note that later entries override this, so you might need to move # it further down) %sudo ALL=(ALL) ALL # #includedir /etc/sudoers.d #разрешаем запуск скрипта от чужого имени без пароля www-data ALL = (myproject) NOPASSWD: /vhosts/myproject.ru/gitsync.sh - Созадем php скрипт, который будет из веба запускать наш shell скрипт /vhosts/myproject.ru/htdocs/gitsync.php (название можно выбрать более секретное, как и добавить передачу пароля):
<?php $output = array(); exec('sudo -u myproject /vhosts/myproject.ru/gitsync.sh 2>&1', $output); foreach ($output as $line) { echo $line."\r\n"; } die(); ?> - в Bitbucket в настройках проекта во вкладке Services в раздел POST пишем путь до скрипта автопула:
myproject.ru/gitsync.phpи жмем Save
Теперь после каждого push'а все файлы на сервере будут приводится к файлам из репозитория, можно такой же подход реализовать и на тест сервере, но в этом случае если один разработчик имеет незапушеные файлы, то на сервере они затрутся и их придется заново загружать.
Подключаем Xdebug
Как установить его не буду описывать, будем считать что Xdebug установлен, правим конфиг /etc/php5/conf.d/xdebug.ini:
zend_extension=/usr/lib/php5/20090626/xdebug.so
xdebug.remote_enable=1
xdebug.remote_connect_back=1
xdebug.idekey=PHPSTORM
xdebug.remote_port=9000
Обратите внимание на директиву remote_connect_back — она позволяет коннектиться не к заданному IP машины разработчика, а к IP клиента который находится в окружении PHP (REMOTE_ADDR), т.о. с Xdebug могут работать одновременно несколько человек. Это не значит что Xdebug будет запущен при каждом обращении к серверу, для его старта по прежнему требуется передать определенные cookies — подробнее
Вбиваем тут IDE key указанный нами в xdebug.idekey ключ PHPSTORM и появившиеся ссылки внизу перестакиваем на панель закладок
Настраивать в PHPStorm специально ничего не надо, все уже настроено, но на всякий случай настройки тут — Project Settings -> PHP -> Debug
теперь чтобы отладчик заработал нужно:
- в PHPStorm включить прослушку коннектов дебаггеров — кнопка Start Listen PHP Debug Connection
- открыть сайт, ткнуть закладку Start debugger, перезагрузить страницу
- PHPStorm должен маякнуть о входящем подключении и открыть дебаггер
Поскольку соединение идет из вне, а многие теперь сидят за роутерами, то на роутере нужно сделать проброс порта 9000 на ваш локальный IP адрес, на D-link DIR 300 это выглядит примерно так:
Если debugger выдает ошибку, что не может найти соответствующий текущий исполняемый файл на локальной машине, то в настройках PHP -> Servers можно задать соответствие путей на сервере путям на локале.
Ссылки:
http://git-scm.com/
http://xdebug.org/
http://bitbucket.org/
http://jetbrains.com/phpstorm/
