
Большая часть аудитории Хабра регулярно пишет код. В текстовом редакторе или IDE. И сколько бы не было в нем окошек и менюшек, а сердце любого редактора — это компонент (widget), который редактирует и подсвечивает код.
Больше года назад на Хабре был цикл статей от namespace про компонент QScintilla (1, 2, 3), и моя статья с его критикой. Получилась некоторая недосказанность. Ясно, что все плохо, но не понятно, что делать.
Сейчас я написал свой
Эта статья расскажет о том, как устроена подсветка синтаксиса в моем проекте: какие проблемы возникали, и как они решались. Она про подходы, а не про специфику конкретного GUI-инструментария. Если интересно заглянуть «под капот» текстового редактора, добро пожаловать под кат.
Сразу оговорюсь, что это не фундаментальная научная статья. Это мой опыт. Будет очень интересно почитать в комментариях про альтернативные подходы и решения.
Мотивация
Я делаю текстовый редактор в духе vim и emacs. Универсальный, кроссплатформенный, расширяемый, ориентированный на опытных пользователей. Но с чуть более интуитивным и современным GUI на PyQt. И для этого мне нужен редактор кода.
Вариантов нашлось всего 2: QScintilla и katepart.
Изначально я использовал QScintilla, но из-за недостатков, перечисленных здесь, решил от него отказаться.
katepart очень хорош, но не устраивает тем, что зависит от библиотек KDE. А иметь их в зависимостях не очень удобно, особенно для Windows и MacOS.
Разбор кода
Мой проект не ориентирован на какую-то конкретную технологию, языков хочется подсвечивать много. Больше, чем я в состоянии освоить сам. Поэтому было решено использовать существующую базу описаний синтаксиса от katepart.
Для каждого из поддерживаемых языков программирования в katepart существует Highlight Definition — XML-файл с описанием синтаксиса и подсветки.
Highlight Definition описывает нечто вроде конечного автомата. Автомат последовательно разбирает текст, меняя при этом свое состояние — «Context». У каждого из контекстов есть набор правил, по которому нужно перейти в другой контекст. Автомат помнит, из какого состояния он перешел в текущее, и может возвращаться в предыдущие контексты (стек контекстов).
Пример: C++. В контексте код есть правило: если встретился символ " — перейти в контекст «строка». Контекст «строка» подсвечивает символы красным цветом и подержит правило: если встретился символ " — вернуться в предыдущий контекст.
Для каждого из контекстов задан стиль, которым он подсвечивает текст.
Система очень удобная и универсальная. Формат файлов хорошо документирован. Наверное, именно поэтому katepart подсвечивает около 2 сотен языков и форматов.
Минусом, на мой взгляд, является лишь то, что интерпретатор, который разбирает код на основе Syntax Definition, в большинстве случаев будет хуже по производительности, чем парсер для конкретного языка программирования.
Оптимизация

Когда я написал подсветку синтаксиса, радости моей не было предела. Все работает, все красиво. Все 59 файликов на разных языках из коллекции katepart выглядят правильно и открываются шустро. Ура! Кто сказал, что Python медленный язык?!
А потом я попробовал открыть большой файлик. Реально большой. И
Пару часов с профайлером ускорили подсветку в несколько раз. Но, все равно получалось слишком медленно. А пространство для оптимизации было практически исчерпано. Можно было ускорить парсер еще на пару десятков процентов за счет жутко запутанного кода, но такая оптимизация погоды не делает.
Я стал осваивать написание модулей на C. Это оказалось совсем не сложно, Python к расширениям очень дружелюбен.
В процессе написания парсера возникла проблема: в C нет регулярных выражений. А зависимости подключать очень не хотелось. Проблема решилась за счет того, что взаимодействие C-Python работает в 2-х направлениях. Python вызывает C для парсинга, а из С дергается функция на Python для того, чтобы проверить регулярное выражение.
Когда я начал тестировать парсер с расширением, выяснилось, что производительность не существенно отличается от версии на Python. Снова взял профайлер и пошел искать проблему.
Оказалось, что 90% времени мой парсер вызывает Python для проверки регулярных выражений. Что же, хак не удался. Пришлось использовать внешнюю библиотеку. Так у компонента появилась единственная зависимость — библиотека обработки регулярных выражений на C pcre. С ней производительность получилась вполне приемлемой (цифры будут ниже).
В итоге в целесообразности использования Python я не разочаровался. Парсер на C — это примерно 1/3 кодовой базы моего компонента. Думаю, по трудозатратам такой гибридный вариант получился легче, чем решение на С++.
Асинхронная подсветка
Большинство текстовых файлов довольно небольшие по размеру. Но иногда мне приходилось редактировать исходники, в которых больше 300К строк. Насколько бы не был крут разработчик парсера, и насколько бы не был быстр его язык, а разбираться до конца такой файл будет дольше, чем пользователь согласен ждать.
katepart подсвечивает код в потоке GUI. И делает это лениво — подсвечивается столько, сколько нужно отрисовать на экране. Такой подход очень хорошо работает, если файл открывается в начале. Однако если перескочить в конец большого файла — GUI просто зависает. Меня такой подход не устроил.
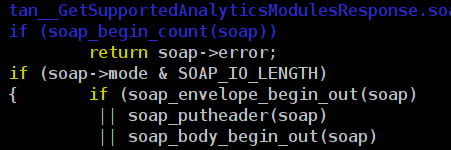
vim и emacs при необходимости отрисовать конец большого файла разбирают текст с середины. Подход хорош тем, что позволяет не блокировать GUI надолго при подсветке. Но не все так просто. Языки программирования разбираются последовательно. Например, чтобы правильно обработать символ конца многострочного комментария, нужно знать, начался ли комментарий в предыдущей строчке. Получается, что в некоторых случаях парсинг с середины будет выдавать неправильную подсветку (как на скриншоте из vim).
Сейчас, когда рост тактовых частот перешел в рост количества ядер, часто актуальна оптимизация вычислений за счет разделения по ядрам. Но и здесь возникают проблемы, и не только потому, что парсить файл нужно последовательно.
Пользователь постоянно редактирует код. Поток GUI обрабатывает нажатия клавиш и меняет документ. Если при этом документ парсится и подсвечивается в потоках, изменения нужно синхронизировать. Инструментарий Qt пока не везде ориентирован на многопоточность, я не нашел способа надежно синхронизировать доступ к документу. Пришлось от потоков отказаться.
В итоге экспериментов у меня получилось следующее решение: файл разбирается и подсвечивается в потоке GUI по таймеру. Таймер работает 20 милисекунд, потом возвращает управление в main loop для обработки действий пользователя, потом снова вызывается… Если пользователь открыл огромный файл и сразу перескочил в его конец — файл отображается, но без подсветки.
Код можно править, а подсветка появится чуть позже.
Инкрементальная подсветка
Когда пользователь редактирует код — подсвечивать заново текст нужно с того места, которое редактируется, а не с начала. И, как правило, меняется одна или несколько строк.

В процессе парсинга к каждой строке файла прикрепляется блок метаданных с состоянием парсера. Если текст был изменен, метаданные используются, чтобы начать разбор с конкретной строки.
Продолжается инткрементальный парсинг до тех пор, пока не будет найдена строка, метаданные которой не изменились после нового парсинга.
Сравнение производительности
Сравнение производительности подсветки — дело не благодарное. Уж очень от многих факторов она зависит: железа, версий софта, языка, содержимого конкретного файла, фазы луны,…
Однако без него статья была бы не полной. Поэтому придется раздел добавить.
Отказ от ответственности
Как уже сказано выше, производительность зависит от многих факторов, и при других обстоятельствах картина может коренным образом отличаться.
Этот раздел — не основная цель статьи. Измерения производились только на одном файле на одном языке, очень поверхностно. Цифры, наблюдения и выводы могут содержать грубые ошибки.
Поэтому методику измерений не публикую; предлагаю считать, что информацию, приведенную ниже, я выдумал сам исключительно для развлечения аудитории Хабра.
Приведенная информация ни в коем случае не может быть использована для выводов о том, что текстовый редактор X лучше, чем текстовый редактор Y.
Этот раздел — не основная цель статьи. Измерения производились только на одном файле на одном языке, очень поверхностно. Цифры, наблюдения и выводы могут содержать грубые ошибки.
Поэтому методику измерений не публикую; предлагаю считать, что информацию, приведенную ниже, я выдумал сам исключительно для развлечения аудитории Хабра.
Приведенная информация ни в коем случае не может быть использована для выводов о том, что текстовый редактор X лучше, чем текстовый редактор Y.
Я открыл большой C++ файл (364121 строка) в нескольких редакторах, которые мне интересны, и собрал свои наблюдения в эту таблицу.
| Компонент или редактор | Время на подсветку всего файла | Блокирует GUI | Проблемы подсветки |
|---|---|---|---|
| Qutepart | 44 секунды | Никогда | Открывает файл 3 секунды |
| katepart | Был убит через 6 минут | Пока не подсветит столько, сколько нужно отобразить | |
| QScintilla | 3 секунды | Никогда | Тормозит при редактировании |
| Scintilla | 3 секунды | Никогда | Тормозит при редактировании |
| Sublime Text | 23 секунды | При редактировании, пока не обновит всю изменившуюся подсветку | |
| gedit | 8 секунд | Никогда | Тормозит при редактировании |
| Qt Creator | 20 секунд | При редактировании висит, пока не обновит всю изменившуюся подсветку | |
| Ninja IDE | 14 секунд | При открытии | Подсветил только первые 51 строки. Жутко тормозит при редактировании. |
| vim | Мгновенно | Никогда | Парсит файл с середины, в некоторых случаях показывает неправильный результат. |
| emacs | Мгновенно | Никогда | Парсит файл с середины, в некоторых случаях показывает неправильный результат. Вешается на время около минуты при перемотке вверх. |
Как видим, Qutepart медленнее всех подсвечивает текст. Это закономерно, поскольку используется интерпретируемый язык, связка Python-Qt и интерпретируемые определения синтаксиса в виде XML.
С другой стороны, высокоуровневый язык и технологии позволяют подсвечивать много языков, не блокировать GUI и не показывать артефактов.
При работе с реальными файлами в абсолютном большинстве случаев файл открывается уже подсвеченным, и при редактировании пользователь не видит, как обновляется подсветка. Поэтому текущее положение дел меня устраивает и от дальнейшей оптимизации я отказался.
И что же получилось
У меня получился компонент для редактирования кода Qutepart и текстовый редактор на его основе Enki.
Зависит компонент от PyQt и от pcre. Требует сборки модуля расширения на C. Для небольших файлов можно обойтись без расширения и без pcre.
Из katepart позаимствованы файлы Syntax Definition и алгоритмы выравнивания кода.
Как и katepart, проект доступен под LGPL.
Сегодня я выпустил первую версию Qutepart и Enki на его основе, потому что решил, что текущая версия уже лучше, чем вариант на QScintilla. Функциональности пока не много. TODO-list большой. Периодически пополняется за счет пожеланий от пользователей и становится меньше за счет сделанных фич.
Буду рад отзывам от Хабра-сообщества!
