Уважаемое хабросообщество, решил поделиться с вами моими наработками в изучении нейросети Машины Больцмана, сделанными в студенческие года.
В России по данной теме было крайне мало информации. Даже руководитель нашей кафедры не мог мне помочь с материалом. Благо наш университет состоял в единой международной базе, и была возможность воспользоваться зарубежным опытом. В частности, большая часть была найдена в литературе оксфордского университета. По сути, данная статья является сборником информации из различных источников, переосмысленная и изложенная достаточно понятным языком, как мне кажется. Надеюсь кому-то будет интересно. Когда-то меня это заставляло не спать ночами.
Итак, приступим.
Сеть Хопфилда
Среди различных конфигураций искуственных нейронных сетей (НС) встречаются такие, при классификации которых по принципу обучения, строго говоря, не подходят ни обучение с учителем [1], ни обучение без учителя [2]. В таких сетях весовые коэффициенты синапсов рассчитываются только однажды перед началом функционирования сети на основе информации об обрабатываемых данных, и все обучение сети сводится именно к этому расчету. С одной стороны, предъявление априорной информации можно расценивать, как помощь учителя, но с другой – сеть фактически просто запоминает образцы до того, как на ее вход поступают реальные данные, и не может изменять свое поведение, поэтому говорить о звене обратной связи с «миром» (учителем) не приходится. Из сетей с подобной логикой работы наиболее известны сеть Хопфилда, которая обычно используются для организации ассоциативной памяти. Именно ее мы и рассмотрим.
Структурная схема сети Хопфилда приведена на рисунке ниже. Она состоит из единственного слоя нейронов, число которых является одновременно числом входов и выходов сети. Каждый нейрон связан синапсами со всеми остальными нейронами, а также имеет один входной синапс, через который осуществляется ввод сигнала. Выходные сигналы, как обычно, образуются на аксонах.
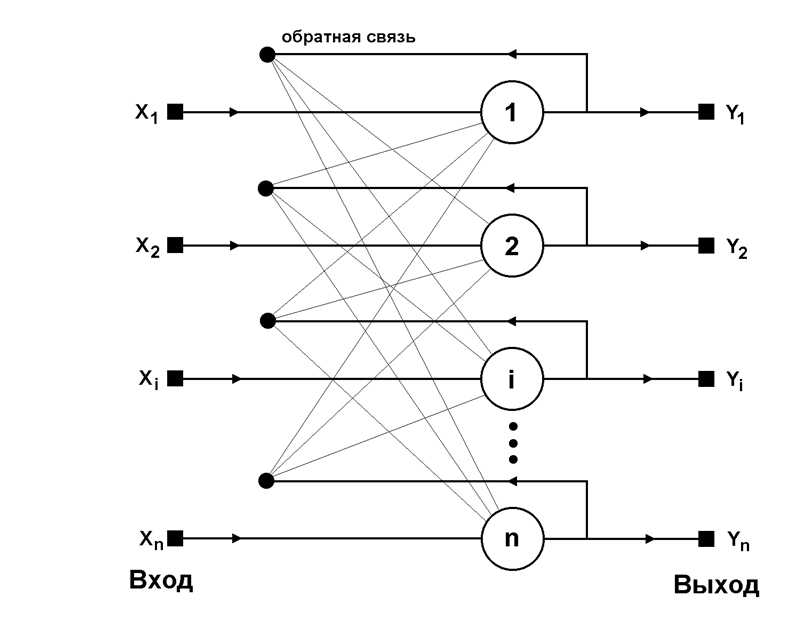
Задача, решаемая данной сетью в качестве ассоциативной памяти, как правило, формулируется следующим образом. Известен некоторый набор двоичных сигналов (изображений, звуковых оцифровок, прочих данных, описывающих некие объекты или характеристики процессов), которые считаются образцовыми. Сеть должна уметь из произвольного неидеального сигнала, поданного на ее вход, выделить («вспомнить» по частичной информации) соответствующий образец (если такой есть) или «дать заключение» о том, что входные данные не соответствуют ни одному из образцов. В общем случае, любой сигнал может быть описан вектором X = { xi: i=0...n-1}, n – число нейронов в сети и размерность входных и выходных векторов. Каждый элемент xi равен либо +1, либо -1. Обозначим вектор, описывающий k-ый образец, через Xk, а его компоненты, соответственно, – xik, k=0...m-1, m – число образцов. Когда сеть распознает (или «вспомнит») какой-либо образец на основе предъявленных ей данных, ее выходы будут содержать именно его, то есть Y = Xk, где Y – вектор выходных значений сети: Y = { yi: i=0,...n-1}. В противном случае, выходной вектор не совпадет ни с одним образцовым.
Если, например, сигналы представляют собой некие изображения, то, отобразив в графическом виде данные с выхода сети, можно будет увидеть картинку, полностью совпадающую с одной из образцовых (в случае успеха) или же «вольную импровизацию» сети (в случае неудачи).
На стадии инициализации сети весовые коэффициенты синапсов устанавливаются следующим образом [3][4]:
 (1)
(1)
Здесь i и j – индексы, соответственно, предсинаптического и постсинаптического нейронов; xik, xjk – i-ый и j-ый элементы вектора k-ого образца.
Алгоритм функционирования сети следующий (p – номер итерации):
1. На входы сети подается неизвестный сигнал. Фактически его ввод осуществляется непосредственной установкой значений аксонов:
Yi(0) = xi, i = 0...n-1 (2)
поэтому обозначение на схеме сети входных синапсов в явном виде носит чисто условный характер. Ноль в скобке справа от yi означает нулевую итерацию в цикле работы сети.
2. Рассчитывается новое состояние нейронов
 (3)
(3)
и новые значения аксонов
 (4)
(4)

Рис. 4 Активационные функции
где f – активационная функция в виде скачка, приведенная на рисунке (4)
3. Проверка, изменились ли выходные значения аксонов за последнюю итерацию. Если да – переход к пункту 2, иначе (если выходы застабилизировались) – конец. При этом выходной вектор представляет собой образец, наилучшим образом сочетающийся с входными данными.
Как говорилось выше, иногда сеть не может провести распознавание и выдает на выходе несуществующий образ. Это связано с проблемой ограниченности возможностей сети. Для сети Хопфилда число запоминаемых образов m не должно превышать величины, примерно равной 0.15•n. Кроме того, если два образа А и Б сильно похожи, они, возможно, будут вызывать у сети перекрестные ассоциации, то есть предъявление на входы сети вектора А приведет к появлению на ее выходах вектора Б и наоборот.
Так же для полного понимания функционирования сети необходимо упомянуть о правиле Хебба.
Правило обучения для сети Хопфилда опирается на исследования Дональда Хебба (D.Hebb, 1949), который предположил, что синаптическая связь, соединяющая два нейрона будет усиливатьося, если в процессе обучения оба нейрона согласованно испытывают возбуждение либо торможение. Простой алгоритм, реализующий такой механизм обучения, получил название правила Хебба. Рассмотрим его подробно.
Пусть задана обучающая выборка образов ха, a = 1..p. Требуется построить процесс получения матрицы связей W, такой, что соответствующая нейронная сеть будет иметь в качестве стационарных состояний образы обучающей выборки (значения порогов нейронов T обычно полагаются равными нулю).
В случае одного обучающего образа правило Хебба приводит к требуемой матрице:
Wij = ξi * ξj (5)
Покажем, что состояние S = x является стационарным для сети Хопфилда с указанной матрицей. Действительно, для любой пары нейронов i и j энергия их взаимодействия в состоянии x достигает своего минимально возможного значения.
Eij = -(1/2) xi xj xi xj = -1/2. (6)
При этом Е — полная энергия равна E = -(1/2) N2, что отвечает глобальному минимуму.
Для запоминания других образов может применяется итерационный процесс:
Wij(a) = Wij(a-1) + ξi(a) + ξj(a), W(0) = 0, a = 1..p (7)
который приводит к полной матрице связей в форме Хебба:
 (8)
(8)
Устойчивость совокупности образов не столь очевидна, как в случае одного образа. Ряд исследований показывает, что нейронная сеть, обученная по правилу Хебба, может в среднем, при больших размерах сети N, хранить не более чем p » 0.14 N различных образов. Устойчивость может быть показана для совокупности ортогональных образов, когда
 (9)
(9)
В этом случае для каждого состояния xa произведение суммарного входа i-го нейрона hi на величину его активности Si = xia оказывается положительным, следовательно само состояние xa является состоянием притяжения (устойчивым аттрактором):
 (10)
(10)
Таким образом, правило Хебба обеспечивает устойчивость сети Хопфилда на заданном наборе относительно небольшого числа ортогональных образов.
Синхронный и асинхронный вариант активации
Рассмотрим поведение сети во времени при фиксированной матрице весов. Пускай в момент t=0 мы предали вектору состояния некоторое значение. Существуют два варианта дальнейшего процесса работы сети: синхронный и асинхронный. Синхронный вариант работы заключается в том, что все нейроны одновременно изменят своё состояние в момент t+1 согласно состоянию сети на момент t. В случае асинхронной работы в момент t+1 своё состояние изменяет только один нейрон, в момент t+2 некоторый другой нейрон согласно состоянию сети в момент t+1 и т.д. (каждый раз нейрон выбирается случайно). В любом случае с течением времени сеть каким-то образом изменяет своё состояние. Утверждается, что при наложенных нами условиях на матрицу весов сеть через какое-то конечное время придёт в стационарное состояние, то есть. Так же утверждается, что это стационарное состояние S достигается и является одним и тем же вне зависимости от синхронности работы нейронов.
Машины Больцмана (Вероятностная сеть)
Одним из основных недостатков сети Хопфилда является тенденция «стабилизации» выходного сигнала в локальном, а не в глобальном минимуме. Желательно, чтобы сеть находила глубокие минимумы чаще, чем мелкие, и чтобы относительная вероятность перехода сети в один из двух различных минимумов зависела только от соотношения их глубин. Это позволило бы управлять вероятностями получения конкретных выходных векторов путем изменения профиля энергетической поверхности системы за счет модификации весов связей.
Идея использования «теплового шума» для выхода из локальных минимумов и повышения вероятности попадания в более глубокие минимумы принад¬лежит С. Кирпатрику. На основе этой идеи разработан алгоритм имитации отжига.
Введем некоторый параметр t — аналог уровня теплового шума. Тогда вероятность активности некоторого нейрона к определяется на основе вероятност¬ной функции Больцмана:
Рk=1/(1 + ехр(-Еk/t)) (11)
где t — уровень теплового шума в сети; Ек — сумма весов связей к-го нейрона со всеми активными в данный момент нейронами. Кривая изменения вероятности активности к-го нейрона показана на рисунке 5. При уменьшении t колебания активности нейрона уменьшаются; при t = 0 кривая становится пороговой.

Изменение вероятности активности нейрона в зависимости от параметра t.
Специалисты по статистике называют такие сети случайными марковскими полями. Сеть, использующая для обучения алгоритм имитации отжига, назвается машиной Больцмана в честь австрийского физика Л. Больцмана, одного из создателей статистической механики. Сформулируем задачу обучения вероятностной сети, в которой вероятность активности нейрона вычисляется по формуле (11). Пусть для каждого набора возможных входных векторов требуется получить с определенной вероятностью все допустимые выходные вектора. В большенстве случаев эта вероятность близка к нулю. Процедура обучения машины Больцмана сводится к выполнению следующих чередующихся шагов:
1) Подать на вход сети входной вектор и зафиксировать выходной (как в процедуре обучения с учителем). Предоставить сети возможность приблизиться к состоянию теплового равновесия:
а) приписать состоянию каждого нейрона с вероятностью рк (см. формулу (7.2)) значение единица (активный нейрон) и с вероятностью 1-рк — нуль (не активный нейрон);
б)уменьшить параметр t, перейти к а).
В соответствии с правилом Хебба увеличить вес связи между активными нейронами на величину δ. Эти действия повторить для всех пар векторов обучающей выборки.
2) Подать на вход сети входной вектор без фиксации выходного вектора. Повторить пункты а), б). Уменьшить вес связи между активными нейронами на величину δ.
Результирующее изменение веса связи между двумя произвольно взятыми нейронами на определенном шаге обучения будет пропорционально разности между вероятностями активности этих нейронов на 1-м и 2-м шаге. При повто¬рении шагов 1 и 2 эта разность стремится к нулю.
Второй способ обучения – обучение без учителя – заключается в предварительном расчете коэффициентов в матрице весов. Данные расчеты основаны на предварительном знании условия решаемой задачи.
Друзья, это пока все что я успел вспомнить и найти в своих запасниках.
В следующей статье хочу описать уже прикладной аспект этого вопроса, а именно разработку программы использующую алгоритм Машины Больцмана. Решение будет на задача коммивояжора.
Всем спасибо за внимание.
Очень жду комментариев и вопросов.
В России по данной теме было крайне мало информации. Даже руководитель нашей кафедры не мог мне помочь с материалом. Благо наш университет состоял в единой международной базе, и была возможность воспользоваться зарубежным опытом. В частности, большая часть была найдена в литературе оксфордского университета. По сути, данная статья является сборником информации из различных источников, переосмысленная и изложенная достаточно понятным языком, как мне кажется. Надеюсь кому-то будет интересно. Когда-то меня это заставляло не спать ночами.
Итак, приступим.
Сеть Хопфилда
Среди различных конфигураций искуственных нейронных сетей (НС) встречаются такие, при классификации которых по принципу обучения, строго говоря, не подходят ни обучение с учителем [1], ни обучение без учителя [2]. В таких сетях весовые коэффициенты синапсов рассчитываются только однажды перед началом функционирования сети на основе информации об обрабатываемых данных, и все обучение сети сводится именно к этому расчету. С одной стороны, предъявление априорной информации можно расценивать, как помощь учителя, но с другой – сеть фактически просто запоминает образцы до того, как на ее вход поступают реальные данные, и не может изменять свое поведение, поэтому говорить о звене обратной связи с «миром» (учителем) не приходится. Из сетей с подобной логикой работы наиболее известны сеть Хопфилда, которая обычно используются для организации ассоциативной памяти. Именно ее мы и рассмотрим.
Структурная схема сети Хопфилда приведена на рисунке ниже. Она состоит из единственного слоя нейронов, число которых является одновременно числом входов и выходов сети. Каждый нейрон связан синапсами со всеми остальными нейронами, а также имеет один входной синапс, через который осуществляется ввод сигнала. Выходные сигналы, как обычно, образуются на аксонах.
Задача, решаемая данной сетью в качестве ассоциативной памяти, как правило, формулируется следующим образом. Известен некоторый набор двоичных сигналов (изображений, звуковых оцифровок, прочих данных, описывающих некие объекты или характеристики процессов), которые считаются образцовыми. Сеть должна уметь из произвольного неидеального сигнала, поданного на ее вход, выделить («вспомнить» по частичной информации) соответствующий образец (если такой есть) или «дать заключение» о том, что входные данные не соответствуют ни одному из образцов. В общем случае, любой сигнал может быть описан вектором X = { xi: i=0...n-1}, n – число нейронов в сети и размерность входных и выходных векторов. Каждый элемент xi равен либо +1, либо -1. Обозначим вектор, описывающий k-ый образец, через Xk, а его компоненты, соответственно, – xik, k=0...m-1, m – число образцов. Когда сеть распознает (или «вспомнит») какой-либо образец на основе предъявленных ей данных, ее выходы будут содержать именно его, то есть Y = Xk, где Y – вектор выходных значений сети: Y = { yi: i=0,...n-1}. В противном случае, выходной вектор не совпадет ни с одним образцовым.
Если, например, сигналы представляют собой некие изображения, то, отобразив в графическом виде данные с выхода сети, можно будет увидеть картинку, полностью совпадающую с одной из образцовых (в случае успеха) или же «вольную импровизацию» сети (в случае неудачи).
На стадии инициализации сети весовые коэффициенты синапсов устанавливаются следующим образом [3][4]:
(1)Здесь i и j – индексы, соответственно, предсинаптического и постсинаптического нейронов; xik, xjk – i-ый и j-ый элементы вектора k-ого образца.
Алгоритм функционирования сети следующий (p – номер итерации):
1. На входы сети подается неизвестный сигнал. Фактически его ввод осуществляется непосредственной установкой значений аксонов:
Yi(0) = xi, i = 0...n-1 (2)
поэтому обозначение на схеме сети входных синапсов в явном виде носит чисто условный характер. Ноль в скобке справа от yi означает нулевую итерацию в цикле работы сети.
2. Рассчитывается новое состояние нейронов
(3)и новые значения аксонов
(4)Рис. 4 Активационные функции
где f – активационная функция в виде скачка, приведенная на рисунке (4)
3. Проверка, изменились ли выходные значения аксонов за последнюю итерацию. Если да – переход к пункту 2, иначе (если выходы застабилизировались) – конец. При этом выходной вектор представляет собой образец, наилучшим образом сочетающийся с входными данными.
Как говорилось выше, иногда сеть не может провести распознавание и выдает на выходе несуществующий образ. Это связано с проблемой ограниченности возможностей сети. Для сети Хопфилда число запоминаемых образов m не должно превышать величины, примерно равной 0.15•n. Кроме того, если два образа А и Б сильно похожи, они, возможно, будут вызывать у сети перекрестные ассоциации, то есть предъявление на входы сети вектора А приведет к появлению на ее выходах вектора Б и наоборот.
Так же для полного понимания функционирования сети необходимо упомянуть о правиле Хебба.
Правило обучения для сети Хопфилда опирается на исследования Дональда Хебба (D.Hebb, 1949), который предположил, что синаптическая связь, соединяющая два нейрона будет усиливатьося, если в процессе обучения оба нейрона согласованно испытывают возбуждение либо торможение. Простой алгоритм, реализующий такой механизм обучения, получил название правила Хебба. Рассмотрим его подробно.
Пусть задана обучающая выборка образов ха, a = 1..p. Требуется построить процесс получения матрицы связей W, такой, что соответствующая нейронная сеть будет иметь в качестве стационарных состояний образы обучающей выборки (значения порогов нейронов T обычно полагаются равными нулю).
В случае одного обучающего образа правило Хебба приводит к требуемой матрице:
Wij = ξi * ξj (5)
Покажем, что состояние S = x является стационарным для сети Хопфилда с указанной матрицей. Действительно, для любой пары нейронов i и j энергия их взаимодействия в состоянии x достигает своего минимально возможного значения.
Eij = -(1/2) xi xj xi xj = -1/2. (6)
При этом Е — полная энергия равна E = -(1/2) N2, что отвечает глобальному минимуму.
Для запоминания других образов может применяется итерационный процесс:
Wij(a) = Wij(a-1) + ξi(a) + ξj(a), W(0) = 0, a = 1..p (7)
который приводит к полной матрице связей в форме Хебба:
(8)Устойчивость совокупности образов не столь очевидна, как в случае одного образа. Ряд исследований показывает, что нейронная сеть, обученная по правилу Хебба, может в среднем, при больших размерах сети N, хранить не более чем p » 0.14 N различных образов. Устойчивость может быть показана для совокупности ортогональных образов, когда
(9)В этом случае для каждого состояния xa произведение суммарного входа i-го нейрона hi на величину его активности Si = xia оказывается положительным, следовательно само состояние xa является состоянием притяжения (устойчивым аттрактором):
(10)Таким образом, правило Хебба обеспечивает устойчивость сети Хопфилда на заданном наборе относительно небольшого числа ортогональных образов.
Синхронный и асинхронный вариант активации
Рассмотрим поведение сети во времени при фиксированной матрице весов. Пускай в момент t=0 мы предали вектору состояния некоторое значение. Существуют два варианта дальнейшего процесса работы сети: синхронный и асинхронный. Синхронный вариант работы заключается в том, что все нейроны одновременно изменят своё состояние в момент t+1 согласно состоянию сети на момент t. В случае асинхронной работы в момент t+1 своё состояние изменяет только один нейрон, в момент t+2 некоторый другой нейрон согласно состоянию сети в момент t+1 и т.д. (каждый раз нейрон выбирается случайно). В любом случае с течением времени сеть каким-то образом изменяет своё состояние. Утверждается, что при наложенных нами условиях на матрицу весов сеть через какое-то конечное время придёт в стационарное состояние, то есть. Так же утверждается, что это стационарное состояние S достигается и является одним и тем же вне зависимости от синхронности работы нейронов.
Машины Больцмана (Вероятностная сеть)
Одним из основных недостатков сети Хопфилда является тенденция «стабилизации» выходного сигнала в локальном, а не в глобальном минимуме. Желательно, чтобы сеть находила глубокие минимумы чаще, чем мелкие, и чтобы относительная вероятность перехода сети в один из двух различных минимумов зависела только от соотношения их глубин. Это позволило бы управлять вероятностями получения конкретных выходных векторов путем изменения профиля энергетической поверхности системы за счет модификации весов связей.
Идея использования «теплового шума» для выхода из локальных минимумов и повышения вероятности попадания в более глубокие минимумы принад¬лежит С. Кирпатрику. На основе этой идеи разработан алгоритм имитации отжига.
Введем некоторый параметр t — аналог уровня теплового шума. Тогда вероятность активности некоторого нейрона к определяется на основе вероятност¬ной функции Больцмана:
Рk=1/(1 + ехр(-Еk/t)) (11)
где t — уровень теплового шума в сети; Ек — сумма весов связей к-го нейрона со всеми активными в данный момент нейронами. Кривая изменения вероятности активности к-го нейрона показана на рисунке 5. При уменьшении t колебания активности нейрона уменьшаются; при t = 0 кривая становится пороговой.
Изменение вероятности активности нейрона в зависимости от параметра t.
Специалисты по статистике называют такие сети случайными марковскими полями. Сеть, использующая для обучения алгоритм имитации отжига, назвается машиной Больцмана в честь австрийского физика Л. Больцмана, одного из создателей статистической механики. Сформулируем задачу обучения вероятностной сети, в которой вероятность активности нейрона вычисляется по формуле (11). Пусть для каждого набора возможных входных векторов требуется получить с определенной вероятностью все допустимые выходные вектора. В большенстве случаев эта вероятность близка к нулю. Процедура обучения машины Больцмана сводится к выполнению следующих чередующихся шагов:
1) Подать на вход сети входной вектор и зафиксировать выходной (как в процедуре обучения с учителем). Предоставить сети возможность приблизиться к состоянию теплового равновесия:
а) приписать состоянию каждого нейрона с вероятностью рк (см. формулу (7.2)) значение единица (активный нейрон) и с вероятностью 1-рк — нуль (не активный нейрон);
б)уменьшить параметр t, перейти к а).
В соответствии с правилом Хебба увеличить вес связи между активными нейронами на величину δ. Эти действия повторить для всех пар векторов обучающей выборки.
2) Подать на вход сети входной вектор без фиксации выходного вектора. Повторить пункты а), б). Уменьшить вес связи между активными нейронами на величину δ.
Результирующее изменение веса связи между двумя произвольно взятыми нейронами на определенном шаге обучения будет пропорционально разности между вероятностями активности этих нейронов на 1-м и 2-м шаге. При повто¬рении шагов 1 и 2 эта разность стремится к нулю.
Второй способ обучения – обучение без учителя – заключается в предварительном расчете коэффициентов в матрице весов. Данные расчеты основаны на предварительном знании условия решаемой задачи.
Друзья, это пока все что я успел вспомнить и найти в своих запасниках.
В следующей статье хочу описать уже прикладной аспект этого вопроса, а именно разработку программы использующую алгоритм Машины Больцмана. Решение будет на задача коммивояжора.
Всем спасибо за внимание.
Очень жду комментариев и вопросов.
