Немного перефразируя википедию, инструментирование это отслеживание параметров уровня производительности кода, возможность диагностировать ошибки и записывать информацию для отслеживания причин их возникновения.
Инструментирование JavaScript кода может понадобиться по целому ряду причин. Наиболее распространные: отладка, профилирование, трассировка, логирование. Как правило, движки в которых выполняется JavaScript предоставляют способы инструментирования кода без его изменения. В своей прошлой статье я описал некоторые средства которыми это осуществляется, а тажке существующие ограничения, в конечном итоге сподвигшие меня на начало описанного в той статье проекта и изучение вопроса инструментирования JavaScript путем автоматического изменения кода. Эта тема на мой взгляд обделена вниманием, но заслуживает раскрытия, тем более в комментариях был выражен интерес к концептуальному подходу модификации кода.
Итак, зачем и как можно автоматически изменять код?
Для простейшей отладки, например, может понадобиться изменить каждую функцию скрипта обернув ее тело в try-catch блок.
Простая трассировка или логирование может осуществляться вставкой console.log, профилирование вставкой console.time/console.profile в начало и конец каждой функции, или, если точность замера не так важна или выполняющая среда не поддерживает console.time/console.profile, старым добрым Date.now().
Более глубокая и полная трассировка может понадобиться для последующего анализа тестового или сценарного покрытия кода. Собираемая инструментационными инструкциями информация о выполнении кода сохраняется туда, откуда инструмент может позже взять ее для отчета. Качественный анализ тестового покрытия предполагает отслеживание выполнения (а соответственно инструментирование) не только строк кода, но и ветвей логических и тернарных операторов.
Инструментирование кода для последующей трассировки такого рода осуществляют инструменты code coverage. Из тех с которыми мне пришлось и понравилось работать не могу не отметить istanbul. Инструмент написан на JavaScript, что в том числе помогает его популярности в использовании в grunt расширениях. Я использую istanbul вместе с Jasmine как для анализа покрытия тестами клиентского кода (PhantomJs плюс grunt-template-jasmine-istanbul), так и серверного (с grunt-jasmine-node-coverage). Взглянуть на пример отчета покрытия кода istanbul для самого себя можно здесь.

Еще более сложная модификация кода может понадобиться в средствах визуализации и анализа выполнения кода, упомянутых в прошлой статье.
Каким же образом можно автоматически изменять JavaScript код, находить нужные места и вставлять туда инструментационные инструкции? Можно конечно пытаться сделать это регулярными выражениями и вызвать дьявола, как в этом stackoverflow ответе, но правильный ответ на этот вопрос следующий: JavaScript код нужно парсить, обходить полученное абстрактное синтаксическое дерево, изменять интересующие нас узлы, преобразовывать измененное дерево назад в код.
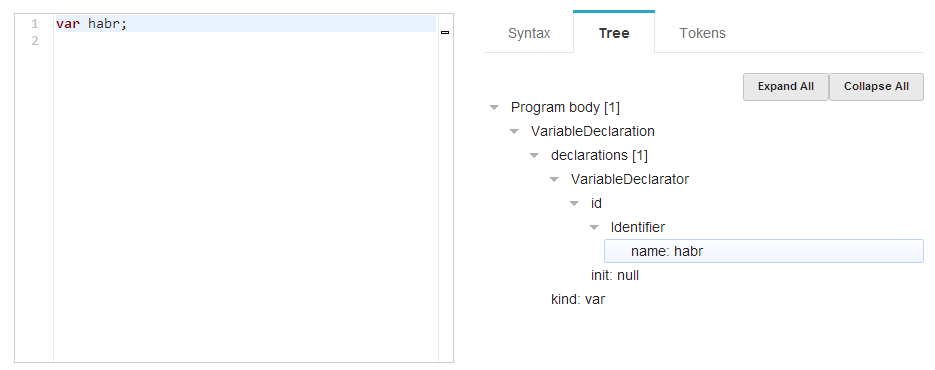
Существует множество легко находимых парсеров JavaScript, некоторые мы используем постоянно, даже уже и не задумываясь о том, что это еще и парсер (например, uglify.js или различные beautifier-ы JavaScript). В своем проекте я использовал esprima для получения изначального синтаксического дерева. Дерево представляет собой иерархический JSON, описывающий анализируемый код. Поиграть с синтаксическими деревьями, а также посмотреть другие примеры использования esprima, можно на сайте инструмента.
Обход дерева с модификацией я реализовал без дополнительных инструментов. Тем не менее, такие инструменты существуют, например falafel и burrito, и избавляют от написания инфраструктуры для обхода дерева, позволяя сконцентрироваться на задаче по поиску и модификации нужных узлов.
Важно отметить, что для многих задач модификации кода (для задач моего проекта и для задач инструментов анализа покрытия кода) важна позиция узлов изначального дерева. При вставке новых узлов в дерево (инструментационных инструкций) и последующей генерации измененного кода, инструкции старого кода будут смещены. Инструментационные инструкции, описывающие выполнение кода, должны сообщать изначальные позиции (строки/столбцы) этого кода. Парсеры умеют по требованию включать информацию о позиции кода в генерируемое дерево.
Генерацию кода для измененного дерева я произвожу с помощью escodegen, который понимает формат синтаксического дерева, выдаваемого esprima.
К сожалению, разные парсеры/генераторы вольны использовать и используют различные форматы синтаксических деревьев. К счастью, несколького популярных парсеров используют формат синтаксического дерева SpiderMonkey parser API, и esprima/escodegen входят в число этих парсеров/генераторов.
Для того чтобы при отладке спрятать инструментационные инструкции и заставить клиентский код в отладчике выглядеть так, как будто он не инструментирован, при генерации кода измененного дерева можно использовать source maps. С использованием escodegen, все что для этого нужно, это установка одного флага (options.sourceMap).
Завершая, хочется заметить, что недеструктивная автоматическая модификация кода требует хорошего знания спецификации языка (или постоянной сверки с ней). В качестве постскриптума, могу привести пример подводного камня на который я натолкнулся.
В прототипе проекта я поголовно оборачивал все что можно в блоки, то есть
что я считал недеструктивным изменением. И все было хорошо, пока я не набрел на библиотеку, которая ломалась после модификации.
Инструментирование JavaScript кода может понадобиться по целому ряду причин. Наиболее распространные: отладка, профилирование, трассировка, логирование. Как правило, движки в которых выполняется JavaScript предоставляют способы инструментирования кода без его изменения. В своей прошлой статье я описал некоторые средства которыми это осуществляется, а тажке существующие ограничения, в конечном итоге сподвигшие меня на начало описанного в той статье проекта и изучение вопроса инструментирования JavaScript путем автоматического изменения кода. Эта тема на мой взгляд обделена вниманием, но заслуживает раскрытия, тем более в комментариях был выражен интерес к концептуальному подходу модификации кода.
Итак, зачем и как можно автоматически изменять код?
Для простейшей отладки, например, может понадобиться изменить каждую функцию скрипта обернув ее тело в try-catch блок.
Простая трассировка или логирование может осуществляться вставкой console.log, профилирование вставкой console.time/console.profile в начало и конец каждой функции, или, если точность замера не так важна или выполняющая среда не поддерживает console.time/console.profile, старым добрым Date.now().
Более глубокая и полная трассировка может понадобиться для последующего анализа тестового или сценарного покрытия кода. Собираемая инструментационными инструкциями информация о выполнении кода сохраняется туда, откуда инструмент может позже взять ее для отчета. Качественный анализ тестового покрытия предполагает отслеживание выполнения (а соответственно инструментирование) не только строк кода, но и ветвей логических и тернарных операторов.
|
=> | |
Инструментирование кода для последующей трассировки такого рода осуществляют инструменты code coverage. Из тех с которыми мне пришлось и понравилось работать не могу не отметить istanbul. Инструмент написан на JavaScript, что в том числе помогает его популярности в использовании в grunt расширениях. Я использую istanbul вместе с Jasmine как для анализа покрытия тестами клиентского кода (PhantomJs плюс grunt-template-jasmine-istanbul), так и серверного (с grunt-jasmine-node-coverage). Взглянуть на пример отчета покрытия кода istanbul для самого себя можно здесь.
Еще более сложная модификация кода может понадобиться в средствах визуализации и анализа выполнения кода, упомянутых в прошлой статье.
Каким же образом можно автоматически изменять JavaScript код, находить нужные места и вставлять туда инструментационные инструкции? Можно конечно пытаться сделать это регулярными выражениями и вызвать дьявола, как в этом stackoverflow ответе, но правильный ответ на этот вопрос следующий: JavaScript код нужно парсить, обходить полученное абстрактное синтаксическое дерево, изменять интересующие нас узлы, преобразовывать измененное дерево назад в код.
Существует множество легко находимых парсеров JavaScript, некоторые мы используем постоянно, даже уже и не задумываясь о том, что это еще и парсер (например, uglify.js или различные beautifier-ы JavaScript). В своем проекте я использовал esprima для получения изначального синтаксического дерева. Дерево представляет собой иерархический JSON, описывающий анализируемый код. Поиграть с синтаксическими деревьями, а также посмотреть другие примеры использования esprima, можно на сайте инструмента.
Обход дерева с модификацией я реализовал без дополнительных инструментов. Тем не менее, такие инструменты существуют, например falafel и burrito, и избавляют от написания инфраструктуры для обхода дерева, позволяя сконцентрироваться на задаче по поиску и модификации нужных узлов.
Важно отметить, что для многих задач модификации кода (для задач моего проекта и для задач инструментов анализа покрытия кода) важна позиция узлов изначального дерева. При вставке новых узлов в дерево (инструментационных инструкций) и последующей генерации измененного кода, инструкции старого кода будут смещены. Инструментационные инструкции, описывающие выполнение кода, должны сообщать изначальные позиции (строки/столбцы) этого кода. Парсеры умеют по требованию включать информацию о позиции кода в генерируемое дерево.
Генерацию кода для измененного дерева я произвожу с помощью escodegen, который понимает формат синтаксического дерева, выдаваемого esprima.
К сожалению, разные парсеры/генераторы вольны использовать и используют различные форматы синтаксических деревьев. К счастью, несколького популярных парсеров используют формат синтаксического дерева SpiderMonkey parser API, и esprima/escodegen входят в число этих парсеров/генераторов.
Для того чтобы при отладке спрятать инструментационные инструкции и заставить клиентский код в отладчике выглядеть так, как будто он не инструментирован, при генерации кода измененного дерева можно использовать source maps. С использованием escodegen, все что для этого нужно, это установка одного флага (options.sourceMap).
Завершая, хочется заметить, что недеструктивная автоматическая модификация кода требует хорошего знания спецификации языка (или постоянной сверки с ней). В качестве постскриптума, могу привести пример подводного камня на который я натолкнулся.
В прототипе проекта я поголовно оборачивал все что можно в блоки, то есть
|
превращалось в | |
что я считал недеструктивным изменением. И все было хорошо, пока я не набрел на библиотеку, которая ломалась после модификации.
Читатель может при желании проверить свои знания/память до чтения ответа
Знать о том, что в языке есть labels я конечно знал, но использовал в своей практике крайне редко и не ожидал определенного поведения для случая с continue label. Ломающим сценарием было:
(см. комментарии к статье для более подробного объяснения)
l1:
for (var x in y) {
continue l1;
}(см. комментарии к статье для более подробного объяснения)
