Качаете и раздаете торренты на высокой скорости, но из-за этого прыгает пинг в онлайн-играх, и играть становится невозможно? Сожитель совершает видеозвонок по скайпу, а вы не хотите ему мешать? Держите файлопомойку, которая занимает весь канал, а QoS настраивать лень? Заливаете видео на youtube с телефона, скорость ограничить не можете?
fq_codel — планировщик пакетов (qdisc) с активным управлением очередью, который решит все ваши проблемы!
Все еще не верите? Посмотрите видео!
На видео видно, что компьютер слева, подключенный через обычный домашний роутер с прошивкой cerowrt (измененный OpenWRT), открывает сайты значительно быстрее, чем правый компьютер с тем же роутером, но со стандартной прошивкой.
Перед прочтением этой статьи рекомендую прочитать TCP Congestion Control или Почему скорость прыгает (и сразу небольшое дополнение к ней: TCP-YeAH теперь отлично работает на ядрах 3.9+ и стоит использовать именно его).
Планировщик пакетов (network scheduler, packet scheduler) — код, который управляет очередью сетевых пакетов. Он может отбрасывать пакеты если буфер переполнился, менять порядок отправки пакетов в сеть. На данный момент, в ядре Linux по умолчанию используется pfifo_fast — алгоритм управления очередью типа First in, first out с учетом ToS пакета.
Планировщики drop-tail (коим является pfifo_fast) работают просто — если буфер не заполнен, помещаем пакет в очередь, иначе отбрасываем, однако планировщики с активным управлением потоком (Active Queue Management, одним из которых является fq_codel) более умные: они могут помечать или отбрасывать пакеты до того, как очередь заполнится, таким образом подстраиваясь под утилизацию канала.
Bufferbloat это то, что вы наблюдаете при высокой загрузке канала. Словами это можно описать как тормозит! Вы раздаете торренты на всю ширину своего канала, при этом загрузка страниц в браузере проходит заметно дольше. Почему это происходит?
Все относительно просто: т.к. торрент-клиент постоянно раздает, очередь пакетов почти всегда заполнена, и пакет на загрузку сайта (на получение IP-адреса из имени, на подключение к этому адресу) встает одним из последних в очередь практически каждый раз. С алгоритмами планировщиков сетевых пакетов с активным управлением потоком такого не происходит, потому что они, во-первых, стараются поддерживать как можно меньшую очередь пакетов, а во-вторых, они могут их перемешивать, таким образом, ваша отдача чуть-чуть (очень близко к незаметному в домашних условиях) уменьшится, но сайты будут открываться гораздо быстрее, чем с алгоритмами с фиксированными размерами очередей и fifo, которые используются по умолчанию.
fq_codel — один из самых эффективных и современных алгоритмов, использующий AQM.
С использованием pfifo_fast пинг при забитом канале повышается до 8мс.
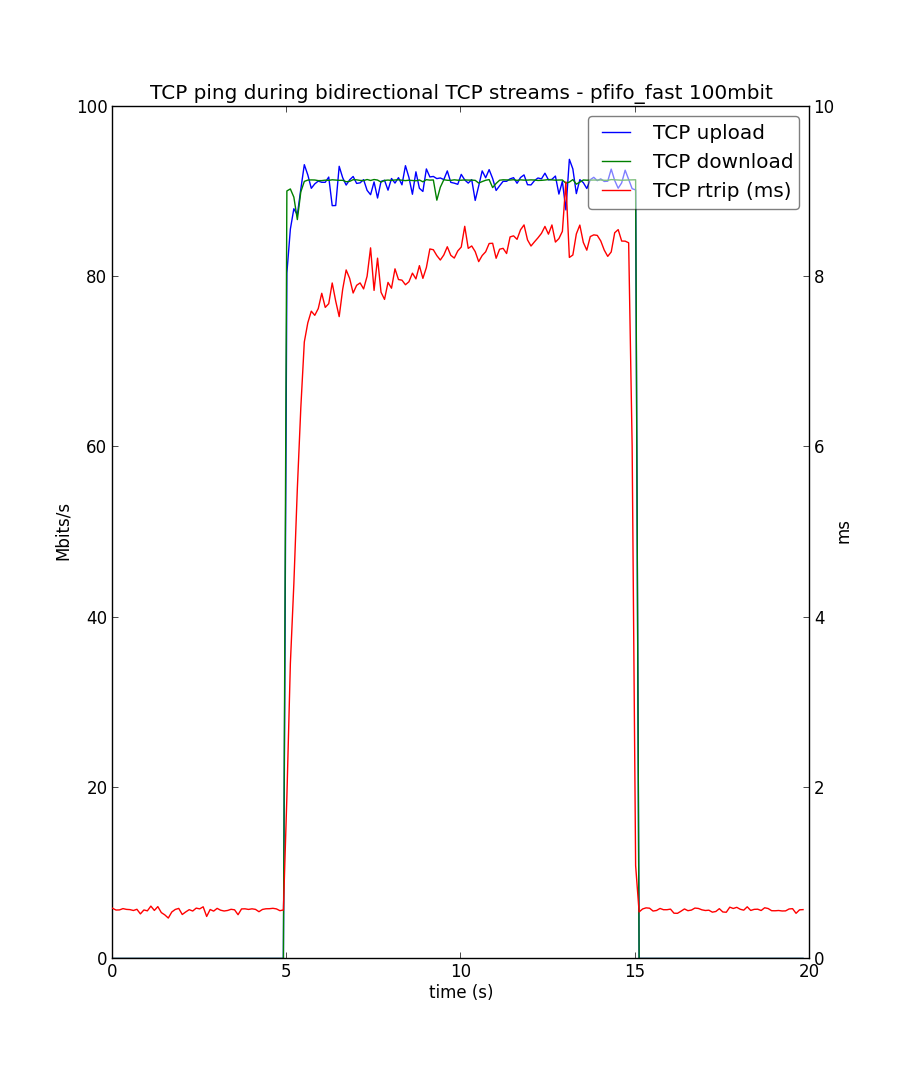
В то время, с использованием fq_codel он повышается всего до 2мс.

fq_codel включен в ядро Linux начиная с версии 3.5. Вам нужна карточка, драйвер которой поддерживает BQL (многие популярные карты), однако fq_codel может работать и без BQL, но вам придется сделать искусственный шейпер вручную. В простейшем случае, будет достаточно установить root qdisc в fq_codel для определенного сетевого интерфейса:
Но рекомендуется использовать скрипт debloat.sh, либо его более фичастый аналог debloat на lua
В ArchLinux есть пакет в AUR
Более того, если вы используете роутер с последней версией прошивки OpenWRT, то все настройки уже сделаны за вас!
Вот, собственно, и все. Давайте сделаем интернет быстрее!
fq_codel — планировщик пакетов (qdisc) с активным управлением очередью, который решит все ваши проблемы!
Все еще не верите? Посмотрите видео!
На видео видно, что компьютер слева, подключенный через обычный домашний роутер с прошивкой cerowrt (измененный OpenWRT), открывает сайты значительно быстрее, чем правый компьютер с тем же роутером, но со стандартной прошивкой.
Перед прочтением этой статьи рекомендую прочитать TCP Congestion Control или Почему скорость прыгает (и сразу небольшое дополнение к ней: TCP-YeAH теперь отлично работает на ядрах 3.9+ и стоит использовать именно его).
Планировщик пакетов. Что это?
Планировщик пакетов (network scheduler, packet scheduler) — код, который управляет очередью сетевых пакетов. Он может отбрасывать пакеты если буфер переполнился, менять порядок отправки пакетов в сеть. На данный момент, в ядре Linux по умолчанию используется pfifo_fast — алгоритм управления очередью типа First in, first out с учетом ToS пакета.
Планировщики drop-tail (коим является pfifo_fast) работают просто — если буфер не заполнен, помещаем пакет в очередь, иначе отбрасываем, однако планировщики с активным управлением потоком (Active Queue Management, одним из которых является fq_codel) более умные: они могут помечать или отбрасывать пакеты до того, как очередь заполнится, таким образом подстраиваясь под утилизацию канала.
Bufferbloat
Bufferbloat это то, что вы наблюдаете при высокой загрузке канала. Словами это можно описать как тормозит! Вы раздаете торренты на всю ширину своего канала, при этом загрузка страниц в браузере проходит заметно дольше. Почему это происходит?
Все относительно просто: т.к. торрент-клиент постоянно раздает, очередь пакетов почти всегда заполнена, и пакет на загрузку сайта (на получение IP-адреса из имени, на подключение к этому адресу) встает одним из последних в очередь практически каждый раз. С алгоритмами планировщиков сетевых пакетов с активным управлением потоком такого не происходит, потому что они, во-первых, стараются поддерживать как можно меньшую очередь пакетов, а во-вторых, они могут их перемешивать, таким образом, ваша отдача чуть-чуть (очень близко к незаметному в домашних условиях) уменьшится, но сайты будут открываться гораздо быстрее, чем с алгоритмами с фиксированными размерами очередей и fifo, которые используются по умолчанию.
fq_codel — один из самых эффективных и современных алгоритмов, использующий AQM.
С использованием pfifo_fast пинг при забитом канале повышается до 8мс.
В то время, с использованием fq_codel он повышается всего до 2мс.
Звучит здорово! Как попробовать?
fq_codel включен в ядро Linux начиная с версии 3.5. Вам нужна карточка, драйвер которой поддерживает BQL (многие популярные карты), однако fq_codel может работать и без BQL, но вам придется сделать искусственный шейпер вручную. В простейшем случае, будет достаточно установить root qdisc в fq_codel для определенного сетевого интерфейса:
sudo tc qdisc add dev eth0 root fq_codelНо рекомендуется использовать скрипт debloat.sh, либо его более фичастый аналог debloat на lua
В ArchLinux есть пакет в AUR
Более того, если вы используете роутер с последней версией прошивки OpenWRT, то все настройки уже сделаны за вас!
Заключение
Вот, собственно, и все. Давайте сделаем интернет быстрее!
