Продолжение, начало здесь.
Для этого эксперимента мы создали индексы на полях id и floatvalue (текстовые поля опустили, тему полнотекстового индекса затрагивать не будем, так как это материал для отдельной статьи). В качестве запросов использовались выборки из диапазонов:
Но для начала, необходимо оценить, насколько упала скорость вставки после добавления индексов. Для этого добавим еще по 250 000 записей в MongoDB и POstgreSQL.
MongoDB
PostgreSQL
После несложных вычислений можно понять, что по скорости вставки MongoDB остался бесспорным лидером: после добавления индексов его скорость вставки упала всего на ~10% и составила 3600 объектов в секунду. Тогда как скорость вставки у PostgreSQL упала на ~30% и составила около 536 записей в секунду.
Хотелось бы, чтобы ситуация с выборкой сложилась аналогичным образом. Выполняем следующие запросы:
MongoDB
PostgreSQL
Однако после сравнения скорости выполнения операций ситуация по выборкам изменилась в пользу PostgreSQL:
Также стоит отметить, что при выборке не из диапазона, а с указанием конкретных цифр (н.п.
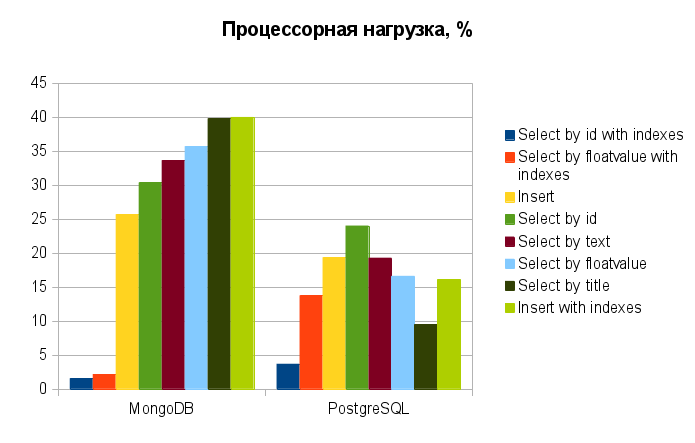
Еще одним откровением стало, что при использовании индексов MongoDB настолько резко снижает потребление процессорного времени (до 1-2 % против 30-40 % при поиске без индексации), что даже обгоняет в этом PostgreSQL (снижение до 4-14 % против 5-25 %).
Прежде чем что-то подытоживать, делюсь, как и обещал результирующей табличкой и диаграммами потребления ресурсов по запросам:

А теперь о результатах.
Невооруженным взглядом можно сразу заметить одно преимущество MongoDB перед PostgreSQL: скорость вставки. Она практически на порядок выше как с использованием индексов, так и без них. Более того, использование индексов не так значительно её снижает (всего на ~10% против 30%-ного снижения у PostgreSQL). Это действительно превосходный результат! Но… как часто вы используете вставку относительно выборки (по всевозможным условиям)?
При выборке из коллекции без индексов MongoDB также лидирует, хотя уже и не столь значительно. Неплохо! Но... как часто вы работаете с таблицами без индексов?
Не подумайте, что своими вопросами я пытаюсь отвернуть вас от noSQL СУБД. Таблицы без индексов (не имею ввиду первичный) имеют место быть в тех или иных решениях. Приоритет скорости вставки для некоторых задач — тоже весьма реален и, более того, иногда очень востребован. Вопрос в том, нужно ли это конкретно вам? Конретно для вашей текущей задачи? Это (весьма поверхностное) тестирование не призвано дать ответ на, не скрою, довольно популярный вопрос «Что лучше SQL или noSQL?». Оно призвано навести вас на размышления, оценить потребности и возможности при выборе того или иного решения для той или иной задачи.
Напоследок скажу, что мы, например, используем оба типа СУБД, в зависимости от структуры данных, целей и вариантов работы с ними. Комплексный подход гораздо лучше и позволяет максимально оптимально работать с любыми данными.
Эксперимент II: Index
Для этого эксперимента мы создали индексы на полях id и floatvalue (текстовые поля опустили, тему полнотекстового индекса затрагивать не будем, так как это материал для отдельной статьи). В качестве запросов использовались выборки из диапазонов:
- 10 000 < id < 100 000
- 200 000 < floatvalue < 300 000
Но для начала, необходимо оценить, насколько упала скорость вставки после добавления индексов. Для этого добавим еще по 250 000 записей в MongoDB и POstgreSQL.
MongoDB
Insert 250000 records complete! Total time: 69.453 sec
PostgreSQL
psql -d prefTest -f 250k.p5.sql (Total time: 466.153 sec)
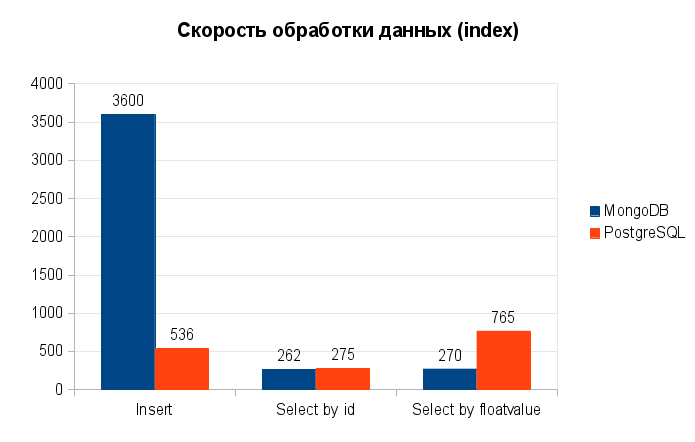
После несложных вычислений можно понять, что по скорости вставки MongoDB остался бесспорным лидером: после добавления индексов его скорость вставки упала всего на ~10% и составила 3600 объектов в секунду. Тогда как скорость вставки у PostgreSQL упала на ~30% и составила около 536 записей в секунду.
Хотелось бы, чтобы ситуация с выборкой сложилась аналогичным образом. Выполняем следующие запросы:
MongoDB
db.tmp.find({$and:[{id:{$gt:10000}},{id:{$lt:100000}}]})db.tmp.find({$and:[{floatvalue: {$lt:300000}},{floatvalue: {$gt:200000}}]})
PostgreSQL
select * from tmp where id>10000 and id<100000select * from tmp where floatvalue<300000 and floatvalue>200000
Однако после сравнения скорости выполнения операций ситуация по выборкам изменилась в пользу PostgreSQL:
Также стоит отметить, что при выборке не из диапазона, а с указанием конкретных цифр (н.п.
floatvalue=1234567.76545) обе СУБД показали результат в 0 миллисекунд. Поэтому такие операции здесь даже не рассматриваются. Это к вопросу о разумном использовании индексов в соответствии с планируемыми условиями выборки. Здесь же индексы и запросы используются только с целью нагрузочного тестирования.Еще одним откровением стало, что при использовании индексов MongoDB настолько резко снижает потребление процессорного времени (до 1-2 % против 30-40 % при поиске без индексации), что даже обгоняет в этом PostgreSQL (снижение до 4-14 % против 5-25 %).
Итоги
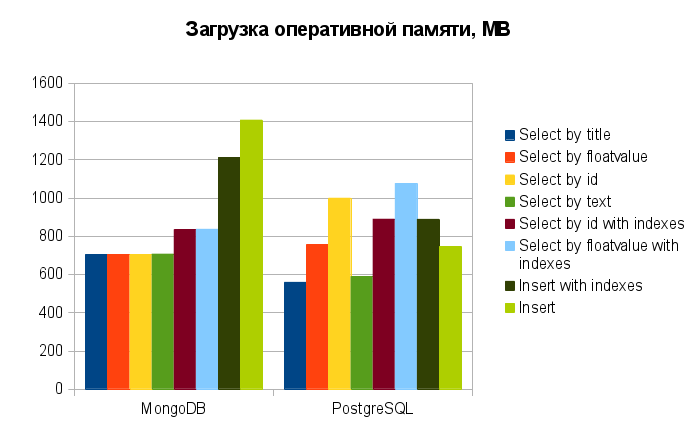
Прежде чем что-то подытоживать, делюсь, как и обещал результирующей табличкой и диаграммами потребления ресурсов по запросам:
А теперь о результатах.
Невооруженным взглядом можно сразу заметить одно преимущество MongoDB перед PostgreSQL: скорость вставки. Она практически на порядок выше как с использованием индексов, так и без них. Более того, использование индексов не так значительно её снижает (всего на ~10% против 30%-ного снижения у PostgreSQL). Это действительно превосходный результат! Но… как часто вы используете вставку относительно выборки (по всевозможным условиям)?
При выборке из коллекции без индексов MongoDB также лидирует, хотя уже и не столь значительно. Неплохо! Но... как часто вы работаете с таблицами без индексов?
Не подумайте, что своими вопросами я пытаюсь отвернуть вас от noSQL СУБД. Таблицы без индексов (не имею ввиду первичный) имеют место быть в тех или иных решениях. Приоритет скорости вставки для некоторых задач — тоже весьма реален и, более того, иногда очень востребован. Вопрос в том, нужно ли это конкретно вам? Конретно для вашей текущей задачи? Это (весьма поверхностное) тестирование не призвано дать ответ на, не скрою, довольно популярный вопрос «Что лучше SQL или noSQL?». Оно призвано навести вас на размышления, оценить потребности и возможности при выборе того или иного решения для той или иной задачи.
Напоследок скажу, что мы, например, используем оба типа СУБД, в зависимости от структуры данных, целей и вариантов работы с ними. Комплексный подход гораздо лучше и позволяет максимально оптимально работать с любыми данными.
