Comments 18
Спасибо за статью.
Хотелось бы спросить, использую ОП Лукаса-Канаде в openCV, столкнулся с непониманием, как работают status и err, status часто для точки равен 1, даже если точка явна не та (в моем случае отслеживаемый объект перекрывается, а точки разбегаются по всему изображению и считаются найденными, использую костыль в виде дисперсии точек), и как ориентироваться на err? Как по нему можно судить о вероятности та/не та точка?
Хотелось бы спросить, использую ОП Лукаса-Канаде в openCV, столкнулся с непониманием, как работают status и err, status часто для точки равен 1, даже если точка явна не та (в моем случае отслеживаемый объект перекрывается, а точки разбегаются по всему изображению и считаются найденными, использую костыль в виде дисперсии точек), и как ориентироваться на err? Как по нему можно судить о вероятности та/не та точка?
Хмм… Насколько я понял из исходников, status выставляется false только если выходим за границу изображения, получаем (почти) нулевой детерминант системы или очень маленькое собственное значение, то есть в тех случаях, когда имеет место неоднозначность в перемещении. То, что для человека очевидно, что точка найдена не верно, еще не значит, что это очевидно для компьютера) То есть действительно надо ориентироваться на err, скорее чем на status. Опять же насколько я понял, err рассчитывается как разброс значений сдвига внутри окна, то есть на границах объектов у вас наверняка будет большое значение err (по сути ошибочно), а в остальных случаях большое значение err как раз должно свидетельствовать о том, что точка посчиталась неправильно. Вообще ИМХО считать дисперсию сдвигов точек для оценки адекватности результата — не такой уж и костыль, хотя по замыслу должно получиться что-то похожее на err.
Спасибо за статью, в своё время потратил немало времени, чтобы на интуитивном уровне понять, как считать оптические потоки. Кстати, если говорить конкретно про алгоритм Лукаса-Канаде, то у него есть расширения для работы с другими трансформациями, а не только с перемещением. Например, в ASM и AAM модифицированный Лукас-Канаде применяется для рассчёта параметров (покусочного) аффинного преобразования, что позволяет, например, отслеживать изменения положения ключевых точек на лице. Ну и в целом алгоритм очень мощный :)
(Не пиара ради, а из добрых побуждений: некоторое время назад я сделал небольшой сервис, позволяющий писать посты с использованием Markdown и LaTeX, а затем автоматически конвертировать в HTML. Мат. формулы при этом конвертируются в ссылки на гифки с codecogs, поэтому необходимость перезаливать их на habrastorage отпадает. Возможно, вам будет удобней.)
(Не пиара ради, а из добрых побуждений: некоторое время назад я сделал небольшой сервис, позволяющий писать посты с использованием Markdown и LaTeX, а затем автоматически конвертировать в HTML. Мат. формулы при этом конвертируются в ссылки на гифки с codecogs, поэтому необходимость перезаливать их на habrastorage отпадает. Возможно, вам будет удобней.)
Ну так я и не говорю про только перемещение. Алгоритм сам по себе обнаруживает перемещение каждой отдельной точки, а получив поле таких перемещений, можно вычислять афинные, проективные и прочие преобразования, заниматься сегментацией и даже 3д-реконструкцией. В статье на практике рассматривались перемещения как самый простой и понятный случай, на котором алгоритмы можно потестировать.
И да, я ждал комментария про редактор формул) codecogs показывает внизу страницы html-код, который можно вставить прямо в статью безо всяких habrastorage'й. Я заливал картинки чисто на всякий случай, это моя первая статья тут и не хотелось облажаться на оформлении.
И да, я ждал комментария про редактор формул) codecogs показывает внизу страницы html-код, который можно вставить прямо в статью безо всяких habrastorage'й. Я заливал картинки чисто на всякий случай, это моя первая статья тут и не хотелось облажаться на оформлении.
На самом деле codecogs довольно стабильно работает, поэтому можно не бояться, что формулы вдруг перестанут отображаться.
И да, хорошее начало, буду ждать дальнейших статей!
И да, хорошее начало, буду ждать дальнейших статей!
С некоторых пор все картинки, вставленные в посты, должны вроде автоматически заливаться на habrastorage (возможно с некоторой задержкой), то есть необходимость «заливать» должна была отпасть.
Однако в этом посте есть несколько формул, которые так и остались ссылками на codecogs. Интересно, почему так получилось?
Однако в этом посте есть несколько формул, которые так и остались ссылками на codecogs. Интересно, почему так получилось?
Не совсем понял, как работать с вашим сервисом. Вбиваю в редактор формулу e = m * c^{2}, жму кнопку Copy as HTML и он просто помещает формулу в тег . Или я как-то неправильно генерирую картинки по формулам?
p.s. и да, он полностью совместим с LaTeX и я могу полностью все форматирование текста сделать в его синтаксисе?
p.s. и да, он полностью совместим с LaTeX и я могу полностью все форматирование текста сделать в его синтаксисе?
Хм, почему-то Хабр съел предыдущий комментарий. Если вкратце, то мат. формулы нужно оборачивать в одиночные (инлайн) или двойные (на отдельной строке) символы доллара. Пример.
Полноценные LaTeX-документы не поддерживаются — для этого есть другие конвертеры. Вместо этого, Nerdbin позволяет писать статьи в Markdown и добавлять формулы (по аналогии с математическими сайтами сети StackExchange). Для просмотра в самом редакторе используется MathJax, а для вставки на другие сайты генерируется HTML со ссылками на codecogs. Поэтому всё, что поддерживается в codecogs, будет поддерживаться и при конвертации в HTML (если появляются какие-то проблемы, о них можно написать сюда).
Полноценные LaTeX-документы не поддерживаются — для этого есть другие конвертеры. Вместо этого, Nerdbin позволяет писать статьи в Markdown и добавлять формулы (по аналогии с математическими сайтами сети StackExchange). Для просмотра в самом редакторе используется MathJax, а для вставки на другие сайты генерируется HTML со ссылками на codecogs. Поэтому всё, что поддерживается в codecogs, будет поддерживаться и при конвертации в HTML (если появляются какие-то проблемы, о них можно написать сюда).
то есть лучше применять даже не всеми любимый gaussian blur (усреднение с весовыми коэффициентами), а прямо таки box filter (равномерное усреднение по окну), да еще и несколько раз подряд
На самом деле усреднение по окну несколько раз подряд эквивалентно однократному усреднению с весовыми коэффициентами, которые рассчитаны специальным образом. А именно, следует подвергнуть квадратное окно усреднению квадратным же окном необходимое количество раз. Получившийся результат и будет коэффициентами двумерного FIR-фильтра, который, будучи применен к некоторому изображению, даст такой же результат, как усреднение по окну несколько раз подряд.
Исходя из этого, вместо многократного применения фильтра обычно лучше сразу рассчитать коэффициенты требуемого (результирующего) фильтра и применить его один раз.
Исключение составляют лишь случаи, когда возможно применить технику Multi-Rate Processing. Идея в том, что для фильтрации сигнала узкополосным фильтром имеет смысл сначала отфильтровать его другим фильтром, имеющим более широкую полосу пропускания, а затем понизить частоту дискретизации. После этого фильтровать уже окончательным фильтром. За счет снижения частоты дискретизации достигается существенная экономия по числу операций (умножение, сложение). Промежуточный decimation можно выполнять несколько раз, в зависимости от задачи.
Кстати к вопросу о соотнесении похожих точек на разных изображениях — есть метод Корреляции Цифровых Изображений, суть которого в общем то та же, только используется он для точных определений деформации деталей и других изделий, но в частности применим и для определения оптического потока. Только формулы немного другие (которых я не нашел в вашей статье). Самая известная и широко используемая формула:
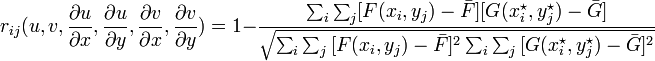
В основе, опять же, лежит интенсивность пикселей. Только берется не точка и ее окрестность, а целые куски изображений, чаще всего квадратные. Потом по этой формуле определяем корреляцию между этим «куском» и подобластью на исходном изображении и определяем, куда переместился тот или иной «кусок».
В OpenCV готовой реализации полного алгоритма нет, но есть функция MatchTemplate, в которой реализованы некоторые из формул определения корреляции. Только «кусков» изображений будет не одно, как на примере, а много (тот же самый принцип dense и sparse), и корреляция считается не по всей картинке, а по относительно небольшим областям.
В итоге получаем матрицу перемещения точек, которая показывает координаты перемещения точек на изображении.
Кстати с помощью дополнительных вычислений можно повысить точность до 1/100 пикселя.
Разумеется, этот метод совершенно не применим на низкоконтрастных изображениях.
В основе, опять же, лежит интенсивность пикселей. Только берется не точка и ее окрестность, а целые куски изображений, чаще всего квадратные. Потом по этой формуле определяем корреляцию между этим «куском» и подобластью на исходном изображении и определяем, куда переместился тот или иной «кусок».
В OpenCV готовой реализации полного алгоритма нет, но есть функция MatchTemplate, в которой реализованы некоторые из формул определения корреляции. Только «кусков» изображений будет не одно, как на примере, а много (тот же самый принцип dense и sparse), и корреляция считается не по всей картинке, а по относительно небольшим областям.
В итоге получаем матрицу перемещения точек, которая показывает координаты перемещения точек на изображении.
Кстати с помощью дополнительных вычислений можно повысить точность до 1/100 пикселя.
Разумеется, этот метод совершенно не применим на низкоконтрастных изображениях.
Ну это как раз по сути поблочное сравнивание (block matching), вычисленное через взаимную корреляцию, я кратенько упоминал его в начале, без формул. По замыслу оно работает очень медленно и с заметными ограничениями, хотя я может что-то про него не знаю. Не заострял внимание на этом методе, потому что мне казалось, что он не совсем про оптический поток. В принципе по замыслу эту методику действительно тоже можно применять для нахождения оптического потока, так что в целом замечание верное.
отличная статья, где все объяснено на высоком уровне, но просто съязвить охота, чтобы подзадорить автора: Ждем когда он узнает, про явные и неявные схемы в численном анализе.
Узнал (вернее вспомнил, проходили на вычматах). Это как-то должно повлиять на данную статью?
нет, я же написал, что статья, действительно, отлично написана. Лично мой опыт говорит, что классические схемы, которые часто и дают или описывают, работают только для учебных примеров. В некотором роде, трюки при переходе от явных схем к неявным и дают ту разницу, которую завуалировано вы описали в статье (безотносительно оптического потока). Я неправ?
Sign up to leave a comment.
То, что вы хотели знать про оптический поток, но стеснялись спросить