Всем привет, хабрачитатели!
Это статья про очередной хабрапарсер.
В конце сентября я читал какую то статью и там опять были слова «стартап», «инновации», «javascript», «фреймворк».
Казалось что в каждом посте они есть. И я решил это проверить. Подробности под катом.
Написание парсера заняло чуть больше месяца. Писал изредка по настроению, разбирался с LINQ, MySQL и попутно написал еще 2 парсера.
Пользовался SharpDevelop 4.3 и MySQL 5.5.25 из набора Денвер.
В качестве клиента на мускул использую Heidi SQL.
В базе данных 2 таблицы — tpost
и twordsinpost
Смысл работы — программа проверяет подключение к базе данных. Если удается, пользователь вводит id первого поста и последнего, программа создает для каждого id URL и качает с него страницу. Скачка происходит в однопоточном режиме, чтобы сервер хабра на меня не обиделся. Обработка страниц многопоточная, и загрузка в БД опять в один поток.
В скачанной странице через XPath выкусывается название поста, автор, дата и сама статья. Комменты пока не трогал — их много, это будет возможно реализовано в хабрапарсер 2.0.
В самой статье через регулярку убираются все знаки препинания, кроме точек и пробелов. Все слова переводятся в нижний регистр. Далее подсчитывается, сколько раз каждое слово встречается в данной статье, и записывается в БД.
Поначалу решил подключиться к MySQL через адаптеры (ADO.NET). MySQL connector 5.2.7 подключался к базе, но делал это крайне медленно. Добавление порядка 2000 строк занимало почти 5 минут.
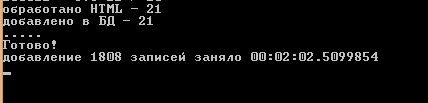
Поэтому написал запросы по старинке, ручками. До Entity Framework еще не добрался, да и не думаю что оно будет быстрее. При этом подключение через адаптеры к MS SQL работает шустро — так же как и с запросами руками. Для тренировки забил MS SQL до 2,5 млн записей — скорость добавления не упала. Но я отвлекся.
Как всегда, при отладке вылезли баги.
1. На хабре бывают статьи без единого слова. До ноября их 716. Крайняя.
Находятся по подзапросу.
2. На хабре бывают статьи без автора. До ноября их 371. Крайняя.
Находятся по подзапросу.
3. На хабре есть статья с вирусом. К сожалению, не смог вспомнить адрес. На нее ругался антивирус (AVG) и прибивал всю программу. Пришлось его выключать.
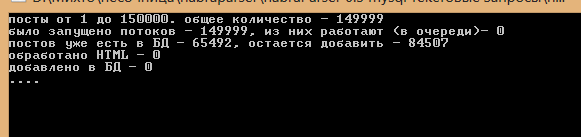
Добавление 200 000 статей было разбито на 2 этапа и заняло в общем 26 часов. Последние статьи были за начало ноября и портили статистику, поэтому я их удалил.
Сейчас в базе примерно 34 миллиона записей. База весит 3 Гб (с индексацией) и включает 199983 статьи.
Настройки MySQL. Вот ini-файл запуска.
Ноут — i7, 8 Гб ОЗУ, HDD.
Сделал индексацию по полям (id_post, word, count) в таблице twordsinpost. Вроде стало пошустрее — вместо 2 минут на запрос уходит 30 секунд. Посоветуйте кстати как оптимизировать базу такого размера?
Есть мысль выложить базу на сайт, и написать на PHP простейшую обертку, но пока не научусь заставлять MySQL работать быстрее, приходится запросы набирать ручками. Да и гибче так.
Сам парсер!
Парсер жестко забит на IP 127.0.0.1, название БД — «habraparser», user — «root», password — «1».
Прописано тут — cDataBase.Connect ().
За неимением лучшего выкинул код, базу и результаты на свой дропбокс.
Результаты всех запросов лежат в файле. Или опять же на ргхосте. Поехали!
На хабре 83174 пустых постов.
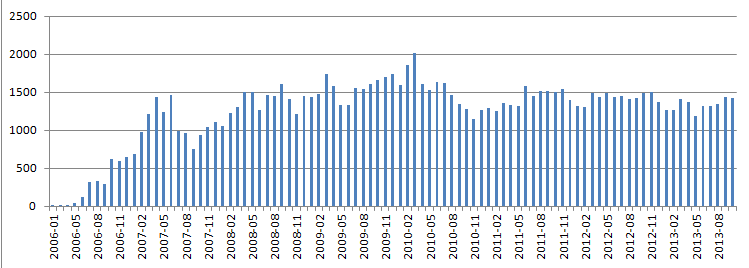
Количество постов по месяцам — запрос
Запрос на количество различных слов — запрос. Нужно заменить слово WORD на свое. Очень интересно.
Например, при запросе «хабр%» встретилось слово «хабрареволюция». А на запрос «путин%» сами посмотрите.
И самый главный запрос — на упоминание слова в постах по месяцам — запрос.
Все точно так же, заменяете «WORD» на свое. Я начал со слова «java».

Затем слово «google».
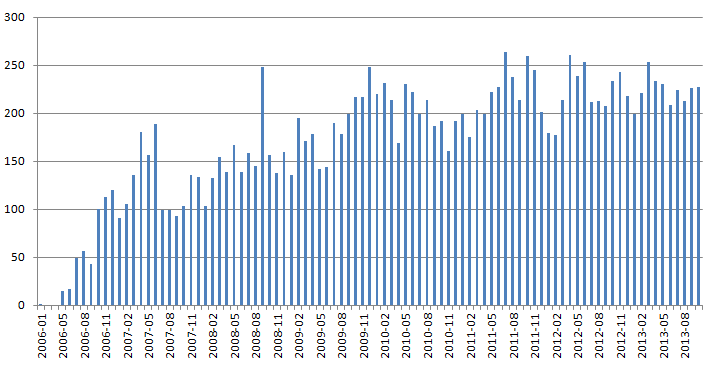
Затем слово «хабр%».
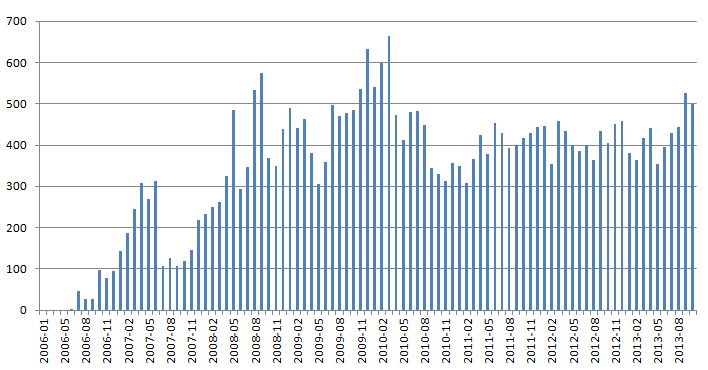
Найти слово «C#» не представляется возможным, поскольку я походу регуляркой удалил решетку. То же и с «C++». Увы.
Слово «android».
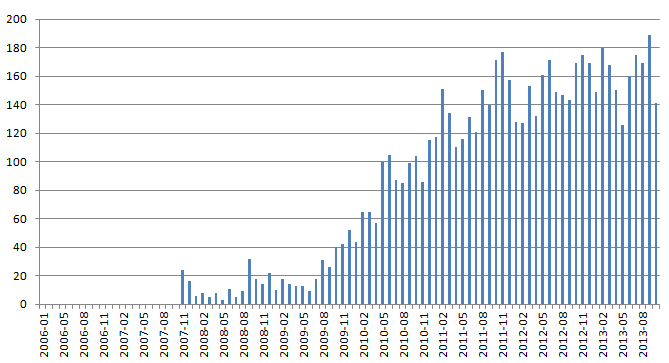
Слово «apple».
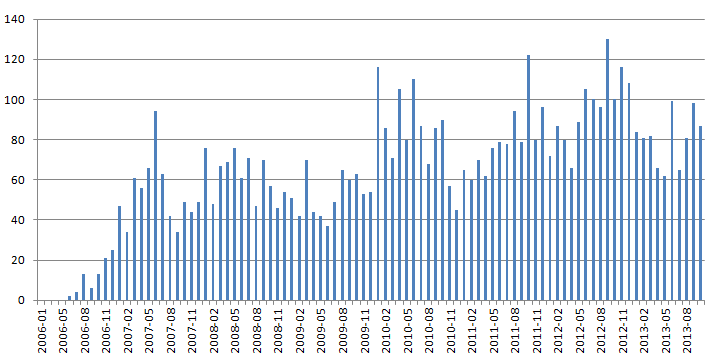
И наконец мои любимые. «Стартап%».
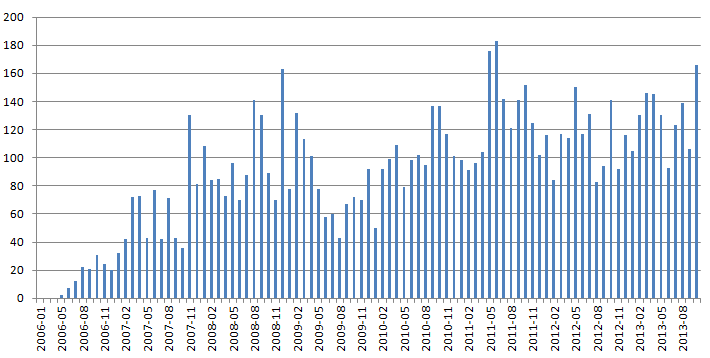
«javascript».
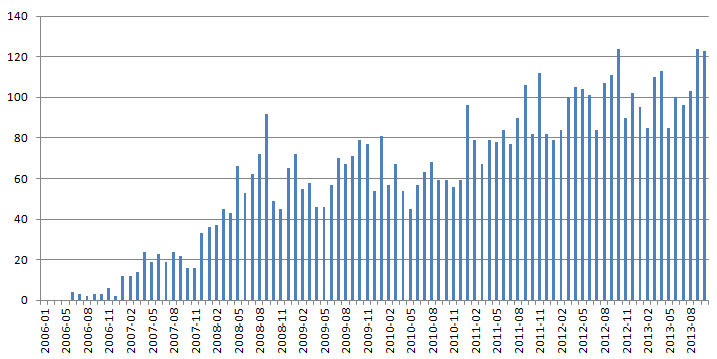
«фреймворк» или «framework».
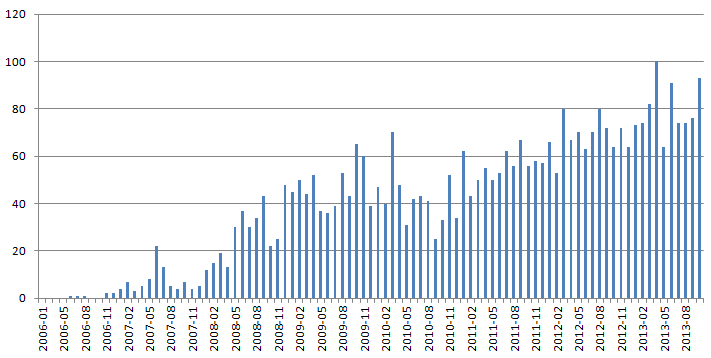
«инноваци%».
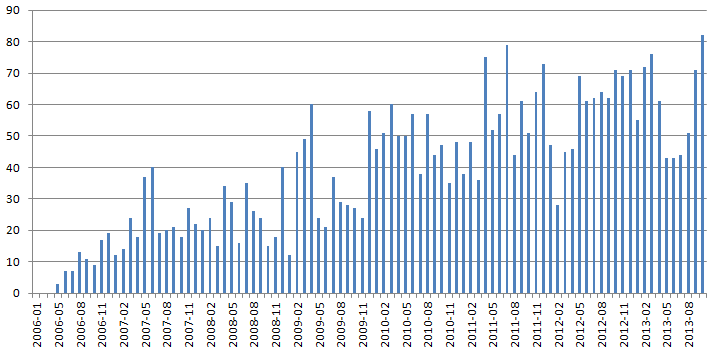
UPD
Специально по просьбе lomalkin — «bitcoin%».

И напоследок самое вкусное.
Код. Выложил в архиве, если надо залью куда-нибудь еще. Залил на ргхост.
Файл со всеми часто употребляемыми словами. Оно же на ргхосте.
Сама база. 1 077 Мб. Скачать бесплатно без смс. Зеркало. Создавать через HeidiSQL.
В комментах можете предлагать еще интересные слова.
Надеюсь, читать было интересно! Всем спасибо за внимание! С уважением, Muxto.
UPD.
По просьбам трудящихся выложил топ-100 слов на хабре. Удивило слово «т» на 92 месте. А также число 5 упоминается чаще чем 4.
Это статья про очередной хабрапарсер.
В конце сентября я читал какую то статью и там опять были слова «стартап», «инновации», «javascript», «фреймворк».
Казалось что в каждом посте они есть. И я решил это проверить. Подробности под катом.
Написание парсера заняло чуть больше месяца. Писал изредка по настроению, разбирался с LINQ, MySQL и попутно написал еще 2 парсера.
Пользовался SharpDevelop 4.3 и MySQL 5.5.25 из набора Денвер.
В качестве клиента на мускул использую Heidi SQL.
В базе данных 2 таблицы — tpost
CREATE TABLE `tpost` (
`id_post` int(10) unsigned NOT NULL,
`date` date NOT NULL,
`name_post` varchar(255) NOT NULL,
`author` varchar(255) NOT NULL,
PRIMARY KEY (`id_post`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT="инфа о постах\r\n";
и twordsinpost
CREATE TABLE `twordsinpost` (
`id_post` int(10) unsigned NOT NULL,
`count` int(11) NOT NULL,
`word` varchar(255) NOT NULL,
CONSTRAINT `FK_twordsinposts_tpost` FOREIGN KEY (`id_post`) REFERENCES `tpost` (`id_post`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT="количество слов в каждом посте";
Смысл работы — программа проверяет подключение к базе данных. Если удается, пользователь вводит id первого поста и последнего, программа создает для каждого id URL и качает с него страницу. Скачка происходит в однопоточном режиме, чтобы сервер хабра на меня не обиделся. Обработка страниц многопоточная, и загрузка в БД опять в один поток.
В скачанной странице через XPath выкусывается название поста, автор, дата и сама статья. Комменты пока не трогал — их много, это будет возможно реализовано в хабрапарсер 2.0.
В самой статье через регулярку убираются все знаки препинания, кроме точек и пробелов. Все слова переводятся в нижний регистр. Далее подсчитывается, сколько раз каждое слово встречается в данной статье, и записывается в БД.
Поначалу решил подключиться к MySQL через адаптеры (ADO.NET). MySQL connector 5.2.7 подключался к базе, но делал это крайне медленно. Добавление порядка 2000 строк занимало почти 5 минут.
Поэтому написал запросы по старинке, ручками. До Entity Framework еще не добрался, да и не думаю что оно будет быстрее. При этом подключение через адаптеры к MS SQL работает шустро — так же как и с запросами руками. Для тренировки забил MS SQL до 2,5 млн записей — скорость добавления не упала. Но я отвлекся.
Как всегда, при отладке вылезли баги.
1. На хабре бывают статьи без единого слова. До ноября их 716. Крайняя.
Находятся по подзапросу.
2. На хабре бывают статьи без автора. До ноября их 371. Крайняя.
Находятся по подзапросу.
3. На хабре есть статья с вирусом. К сожалению, не смог вспомнить адрес. На нее ругался антивирус (AVG) и прибивал всю программу. Пришлось его выключать.
Добавление 200 000 статей было разбито на 2 этапа и заняло в общем 26 часов. Последние статьи были за начало ноября и портили статистику, поэтому я их удалил.
Сейчас в базе примерно 34 миллиона записей. База весит 3 Гб (с индексацией) и включает 199983 статьи.
Настройки MySQL. Вот ini-файл запуска.
Ноут — i7, 8 Гб ОЗУ, HDD.
Сделал индексацию по полям (id_post, word, count) в таблице twordsinpost. Вроде стало пошустрее — вместо 2 минут на запрос уходит 30 секунд. Посоветуйте кстати как оптимизировать базу такого размера?
Есть мысль выложить базу на сайт, и написать на PHP простейшую обертку, но пока не научусь заставлять MySQL работать быстрее, приходится запросы набирать ручками. Да и гибче так.
Сам парсер!
Парсер жестко забит на IP 127.0.0.1, название БД — «habraparser», user — «root», password — «1».
Прописано тут — cDataBase.Connect ().
За неимением лучшего выкинул код, базу и результаты на свой дропбокс.
Итак, самое интересное!
Результаты всех запросов лежат в файле. Или опять же на ргхосте. Поехали!
На хабре 83174 пустых постов.
Количество постов по месяцам — запрос
Запрос на количество различных слов — запрос. Нужно заменить слово WORD на свое. Очень интересно.
Например, при запросе «хабр%» встретилось слово «хабрареволюция». А на запрос «путин%» сами посмотрите.
И самый главный запрос — на упоминание слова в постах по месяцам — запрос.
Все точно так же, заменяете «WORD» на свое. Я начал со слова «java».
Затем слово «google».
Затем слово «хабр%».
Найти слово «C#» не представляется возможным, поскольку я походу регуляркой удалил решетку. То же и с «C++». Увы.
Слово «android».
Слово «apple».
И наконец мои любимые. «Стартап%».
«javascript».
«фреймворк» или «framework».
«инноваци%».
UPD
Специально по просьбе lomalkin — «bitcoin%».
И напоследок самое вкусное.
Код. Выложил в архиве, если надо залью куда-нибудь еще. Залил на ргхост.
Файл со всеми часто употребляемыми словами. Оно же на ргхосте.
Сама база. 1 077 Мб. Скачать бесплатно без смс. Зеркало. Создавать через HeidiSQL.
В комментах можете предлагать еще интересные слова.
Надеюсь, читать было интересно! Всем спасибо за внимание! С уважением, Muxto.
UPD.
По просьбам трудящихся выложил топ-100 слов на хабре. Удивило слово «т» на 92 месте. А также число 5 упоминается чаще чем 4.
