SAT уже тем хорош, что он ум в порядок приводит
Ломоносов (оригинал)
Введение
На хабре уже немало статей, посвященных проблеме P vs. NP и задаче о выполнимости логических формул (SATisfiability problem). Однако, большинство из них не отвечает на несколько самых важных вопросов. Почему эта проблема действительна важна для нас? Что будет, если её решат? Где это все вообще применяется? И почему необходимо иметь хотя бы общее представление, о чем там идет речь?
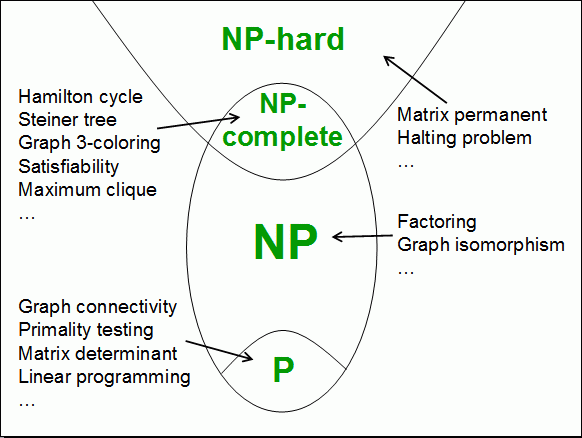
Если мы детально проанализируем наиболее заметные работы на хабре по данной теме [1, 2, 3, 4, 5, 6, 7], то заметим, что с одной стороны, люди обладающие знаниями в области вычислительной сложности не cмогут почерпнуть ничего принципиально нового в данных статьях. С другой стороны, данные статьи по-прежнему не являются общедоступными. Иллюстрация из заголовка наглядно демонстрирует проблему: тем, кому было не понятно, из неё ничего не ясно, а те, кто об этом уже слышал, в ней не нуждаются.
Данная статья преследует две цели: первое — дать общее представление о проблеме и ответить на вопрос, почему же нам стоить знать об этой задаче (первая часть), второе — предоставить материал «на вырост», который будет интересен людям интересующимся тематикой, а так же может быть полезен для изучения темы в дальнейшем (вторая часть).
Структура статьи
Для удобства прочтения и навигации предоставляем краткий обзор содержимого статьи.
- Общедоступный материал
- Почему SAT важен для нас всех? Приложения/Интересные NP задачи и SAT
- История SAT и NP-полноты
- «Интуитивное определение» SAT, NP и P
- Что будет, если… P != NP, P = NP
- 2-SAT полиномиален: алгоритм и интуиция
- Задачка на подумать
- Специализированный материал (смотрите в следующих сериях)
- Формальное определение. Несимметричность проблемы разрешимости для NP и CoNP
- 2+p-SAT полиномиален?
- Зависимость сложности от числа переменных
- Я решил P vs. NP, что мне делать? Куда писать?
- Теоремы о невыразимости: почему статью Романова [3] ожидает reject
- О современных SAT solver'ах
- Что почитать?
- Задачка на подумать
Disclaimer
Данная работа является общеобразовательным материалом и предназначена исключительно для ознакомления с проблематикой SAT. Вычислительная сложность и SAT не является основными направлениями моих исследований, а лежат в смежной научной области, поэтому в случае сомнения всегда обращайтесь к указанному первоисточнику.
Общедоступный материал
Почему SAT важен для нас всех? Приложения
Для того, чтобы ответить на этот вопрос нужно прежде всего понять какие математические задачи затрагивают нашу каждодневную жизнь фактического без нашего ведома и как эти задачи связаны с SAT.
Приведем список задач, которые встречаются вокруг нас и скажем, как они связаны с SAT.
- Прежде всего упомянем криптографический алгоритм RSA, которые используется для обеспечения безопасности банковских транзакций, а так же для создания безопасного соединения. Алгоритм RSA может быть «взломан» с помощью SAT.
- Многие рекомендательные системы (например, в составе Netflix) используют алгоритм разложения булевых матриц для рекомендации контента. Оптимальное разложение таких матриц может быть найдено с помощью SAT.
- Задача оптимального распределения задач по процессорам может быть решена с помощью SAT. Большое число задач планирования сводится к SAT, например, open shop scheduling, где задачи (jobs) должны пройти определенные стадии (выполненными определенными рабочими) и необходимо минимизировать общую продолжительность обработки всех задач.
- NASA проверяет спецификации своего программного обеспечения и моделей своего технического обеспечения с помощью методов model checking, напрямую связанного с SAT.
- Популярный метод кластеризации k-means (метод к-средних) может быть решен с помощью SAT.
- Большинство интересных задач связанных с графами (например, в социальных сетях, граф — это отношение дружбы между пользователями) — поиск наибольшего сообщества, где каждый дружит с каждым, поиск самого длинного пути и многие другие задачи на графах могут быть решены с помощью SAT. Задача из жизни московской области (и не только): составить расписание мусоровозов таким образом, чтобы они объехали все пункты сбора мусора по одному разу за минимальное время. Большое число задач в логистике сводится к задаче SAT.
- Даже задача о ранце может быть решена с помощью SAT. Задача состоит в том, чтобы имея ранец фиксированного размера, набрать в него предметов наибольшей ценности (зная размеры всех предметов заранее).
- Многие видео игры могут быть решены с помощью SAT (и даже Марио!) Так же пазл Судоку и, внимание, Сапер могут быть решены с помощью SAT!
- Задачи о сериализации истории транзакций в базах данных может быть решена с помощью SAT.
Визуализация задач, решаемых с помощью SAT (due to Bart Selman, взято отсюда)

Что значит «могут быть решены» и при чем тут NP
Упрощенно говоря, если у нас есть эффективное решение задачи SAT, то мы можем эффективно решать все указанные задачи. Что конкретно подразумевается под эффективностью зависит от конкретной задачи, но здесь будем считать, что время работы является приемлемым для пользователя (для составления расписания школы на семестр, мы можем посвятить пару дней вычислениям, а для метода кластеризации, мы бы хотели получить результат в интерактивном режиме). А для многих из указанных выше задач верно и обратное, если мы умеем эффективно решать их, то мы умеет эффективно решать SAT (это и называется NP-полнотой — данное определение неформально, но достаточно для общего понимания).
Все эти задачи лежат в классе NP — позднее мы опишем класс детальнее, сейчас же нам стоит отметить, что, если известно эффективное решение задачи SAT, то мы можем эффективно решать любую задачу в классе NP. Иначе говоря, SAT — это задача представитель класса, она является «сложнейшей» в своем классе и позволяет решить все другие задачи в NP.
История SAT и NP-полноты
NP-полнота
Теория вычислительной сложности, в которой языки и функции выделяют в разные классы по количеству времени и памяти необходимые для их вычислений, родилась из теории вычислимости (т.е. работ 30ых годов Гёделя, Чёрча и Тьюринга), когда Хартманис, Штернc, Левис (1965) предложили одну из первых подобных классификаций функций (оригинальные работы: тут и тут).
Концепция NP-полноты развивалась в 1960х-1970х годах независимо в СССР и CША (Эдмондс, Левин, Яблонский et al.). В 1971 году Стивен Кук сформулировал гипотезу о P vs. NP. Теорему о том, что SAT является «универсальной задачей» для класса NP и позволяет решить любую задачу в этом классе (NP-полнота) независимо доказали Леонид Левин (1973) и Стивен Кук, и называется теоремой Левина-Кука. В 1982ом Кук получит за эту работу премию Тьюринга.
В 1972ом Карп публикует Reducibility among combinatorial problems, список показывающий, что SAT далеко не единственная интересная задача в NP и огромное количество задач лежит в NP и эквивалентно SAT. В 1985ом Карп получит за эту работу премию Тьюринга.
В 1974ом Фагин покажет, что NP тесно связан с классической логикой, а именно, что NP эквивалентен экзистенциальным логическим структурам второго порядка (теорема Фагина).
В 1975ом году Бейкер, Джил, Соловэй получили первый фундаментальный мета-результат о неразрешимости задачи P vs. NP с помощью регуляризируемых методов т.е. это первый результат, показывающий, что целый класс методов не может ответить на вопрос равенства P vs. NP (подробнее об этом написано здесь).
В 1979ом году Гэри и Джонсон напишут "Вычислительные машины и труднорешаемые задачи", один из наиболее полных источников информации по NP-полноте и подробный каталог задач. Несмотря на то, что некоторые теоретические результаты в данный момент считаются устаревшими, это один из наиболее фундаментальных трудов в области вычислительной сложности.
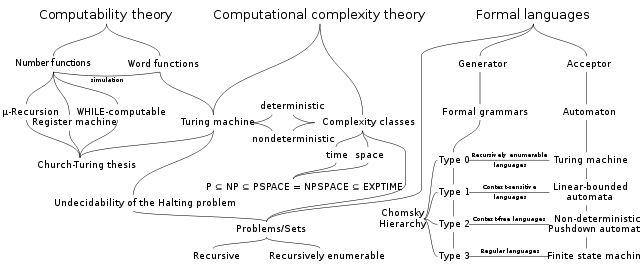
Визуализация отношений между формальными языками, теорий вычислительной сложности и теории вычислений (отсюда):
Очень краткая история SAT-solvers
В 1960х Дэвис и Путман начали применять классически дедуктивные (говоря упрощенно, методы для доказательства теорем) методы для решения SAT (оригинальная работа).
В 1962ом году Дэвис, Патнем, Логеман, Лавленд предложили DPLL алгоритм, основанный на поиске с возвратом и распространении детерминированных вычислений (unit-propagation). Говоря упрощенно, алгоритм предполагал значение некоторой переменной равной истине и вычислял все детерминированные следствия подобного решения и повторял, пока не найдет решения. Данный алгоритм служил основой многих SAT solver'ов на протяжении десятилетий.
В 1992ом Селман, Левескью и Митчелл предложили метод локального поиска в статье GSAT. GSAT — означает Greedy SAT, локальный так как принимает решение о значении переменных на основе только локальной информации. Алгоритм начинал с произвольного назначения значений переменных и изменял значение переменной, если она давала наибольший прирост выполненных предложений. Впоследствии методы локального поиска в самых различных вариациях были интегрированы в большинство SAT solver'ов — в 1999 Хеглер Хус в своей PhD диссертации приводит обширное исследование по стохастическому локальному поиску и его применениям (работа доступна здесь).
В 1996ом Маркес-Силва (Marques-Silva) и Сакалах предложили алгоритм Conflict-Driven-Clause-Learning (CDCL), подобно DPLL он принимает решения о значении переменных и проводил детерминированные вычисления, с другой стороны он хранит в памяти граф имликаций и запоминает некоторые комбинации, которые не ведут к решению и может эффективно избегать «бесполезных» решений и эффективно отсекать пространство решений содержащее конфликт установленный ранее.
C 2001го начали появляться Locality Based Search SAT-solver'ы, эффективно выбирающие подпространства для полного поиска на основе локальной информации, такие как BerkMin (Berkley-Minsk) и многие другие.
«Интуитивное определение» SAT, NP и P
SAT
Начнём с определения, что же такое пропозиционная логика: это набор переменных { x, y, z,… } и набор коннекторов { and, or, — (not), →}. Каждая переменная может быть либо «ложна», либо «истинна». Коннекторы определены стандартно:
- x and y истинно тогда и только тогда, когда (для краткости будем писать iff – if and only if) x истинно и y истинно, классический «И»
- x or y истинно iff по крайней мере одна из переменных x\y истинна, классический «ИЛИ»
- -x истинно iff x ложно, классическое отрицание
- x → y ложно iff x истинно, а y ложно – рассмотрим на примере:
«Если был дождь, то трава мокрая»
Утверждение неверно, тогда и только тогда, когда дождь был (x верно), а трава по-прежнему сухая (y ложно).
Формула F – это синтаксически правильный набор переменных и коннекторов, т. е. →, and, or соединяют переменные или другие формулы, -(not) стоит перед переменной или формулой. Пример, F = (x → (y or z)) and (z → -x).
Говорят, что формула F выполнима (SAT), iff её переменным можно приписать значения «истина»\«ложь» (мы называем такую функцию I от английского Interpretation), таким образом, что F истинна. Для краткости пишем I(F) = «истина».
Любая пропозиционная формула F может быть приведена к виду CNF (conjunctive normal form) т. е. быть представлена в виде
F' = c1 and c2 and … cn
где ci – это (x or y or z), а x, y, z – это переменные или их отрицания.
Пример F = (x or -y or -z) and (-x or -y or h) and (z or h).
Подробнее о данном преобразовании написано здесь (для того, чтобы каждое предложение содержало не более трех переменных, потребуется ввести дополнительные переменные, но это исключительно технические детали).
В таком виде, когда формула имеет вид описанный выше задача носит название 3-SAT, подчёркивая тот факт, кто каждое предложение ci содержит не более трех переменных или их отрицаний.
Постановка задачи 3-SAT звучит следующим образом:
Дано: пропозиционная формула F в виде 3-CNF
Найти:: функцию I, приписывающую значение «истина»\«ложь» всем переменным, такую что I(F) = «истина»
класс P
P он же PTIME – задачи разрешимые за полиномиальное время, это значит, что число шагов алгоритма в данном классе растёт не более, чем некоторый полином от входных данных. Подробнее о различных алгоритмах и анализе сложности в PTIME уже было написано на хабре [9, 10, 11, 12, 13].
Для иллюстрации приведем простой пример: алгоритм сортировки пузырьком (псевдокод из вики)
procedure bubbleSort( A : list of sortable items )
n = length(A)
repeat
swapped = false
for i = 1 to n-1 inclusive do
if A[i-1] > A[i] then
swap(A[i-1], A[i])
swapped = true
end if
end for
n = n - 1
until not swapped
end procedure
Входным параметром является массив чисел для сортировки. Нас интересует рост времени в зависимости от роста длины массива т.е. зависимость времени TIME от n. Заметим, что каждая итерация цикла repeat выполняет не более 3*n шагов и устанавливает по крайней мере один элемент массива на нужное место. Значит, что цикл repeat выполняется не более, чем n раз. Это значит, что количество операций (оно же TIME) растет как некоторый квадрат от длины массива (и линейный член из «n = length(A)» ) т.е.
TIME(n) = a * n2 + b * n + C
Иначе говоря, время работы алгоритма ограничено некоторым полиномом от n, в данном случае мы говорим, что время работы алгоритма растет не быстрее квадрата числа элементов и записываем это используя Big-O запись
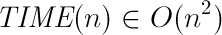
класс NP
NP обозначает nondeterministic polynomial time. Очень часто его ошибочно называются non-polynomial time, по этому поводу родилась шутка:
Делить алгоритмы на полиномиальные и не-полиномиальные, это примерно как делить вселенную на бананы и не-бананы.
В данной статье нас не интересует формальное определение NP (это будет в специализированном материале), но рассмотрим интуитивное представление класса NP. Сама природа и внутренние механизмы NP следуют так называемому guess-and-check методу. Т.е. пространство поиска решений экспоненциально (достаточно большое, чтобы исключить возможность перебора), а проверка решения является простой задачей. Можно рассматривать NP, как класс задач, в котором нужно найти решение («угадать» — guess часть) среди большого количества вариантов, а потом проверить его корректность (check часть).
С точки зрения SAT, пространство решений это всевозможные наборы значений переменных, если у нас k различных переменных в формуле, то у нас 2k возможных «интерпретаций» формулы, т.е. пространство поиска I экспоненциально. Однако, если мы «угадали» I, то мы можем за полиномиальное время проверить истинность формулы.
Что будет если P != NP
Ничего не будет, только кто-то получит миллион долларов.
Что будет если P = NP
Тут две новости: хорошая и плохая.
Хорошие. Мы будем очень быстро решать кучу задач оптимизации, задачи на графы, составлять расписания, собирать пазлы, проверять различные свойства баз данных, а так же эффектно проверять работоспособность спецификаций NASA.
Плохие. Рушится вся современная криптография, а вместе с ней по удар попадает банковская система. Люди начнут писать ботов для Марио.
2-SAT in P.
Рассмотрим интересную вариацию SAT, в которой каждое предложение (clause) ограничен двумя переменными. Здесь и далее, автор всё существенно упрощает для облегчения восприятия материала.
Дано: F – формула вида c1 and c2 and c3 … and cn,
где сi имеет вид (x or y) и x, y – это переменные или их отрицания, т. е. x это некоторая переменная v или -v.
Найти: функцию I, приписывающую значение «истина»\«ложь» всем переменным, такую что I(F) = «истина»
Утверждение: Существую полиномиальный алгоритм P, такой что, если функция I существует, то P(F) = I, а иначе, P(F) = {}.
(*) функция I не единственна, если она существует и P возвращает некоторую функцию I (в книгах по теории алгоритмов и сложности, все тоже самое будет написано формальным языком, но эти детали несущественны для восприятия общей идеи о том, почему 2-SAT полиномиален)
Набросок доказательства:
Для начала преобразуем исходную формулу, используя следующие равенство:

Можете проверить его с помощью таблицы истинности. Интуиция за этим правилом следующая:
«Если был дождь, то трава мокрая» (x → y, x — был дождь, y – трава мокрая)
Это значит, что если трава сухая (не мокрая: y ложно), то дождя точно не было (x ложно).
Если трава мокрая, то либо дождь был (x истинно, в некотором смысле, x «объясняет» почему y истинно), либо дождя не было (х ложно), на интуитивном уровне мы подразумеваем, что существует другая причина, из-за которой y истинно (z – сосед полил газон и поэтому трава мокрая).
Преобразуем F с помощью (*) к виду c'1 and c'2 … and c'n где с'i имеет вид (x → y), x,y – переменные или их отрицания. В результате F – это граф импликаций. Пример, подобного графа ниже:
с1 = Если был дождь, то трава мокрая.
с2 = Если сосед полил газон, то трава мокрая.
с3 = Если трава мокрая, то хорошо растут сорняки.
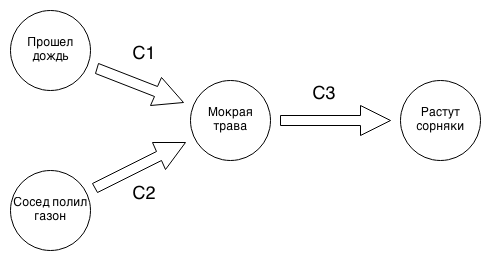
Мы видим, что если в графе импликаций выйдя из некоторой вершины v (например, был дождь), нельзя достичь вершины -v (дождя не было), то система импликаций непротиворечива. Интуиция следующая: если мы сделаем некоторое предположение, например, что дождь был, то мы сразу заключаем, что трава мокрая и растут сорняки (осталось только выбрать поливал ли газон сосед) и не получаем противоречия, то у нас есть часть функции I, в частности приняв решение, что дождь был, мы получили значения для «трава мокрая» и «хорошо растут сорняки», нам осталось принять решение о значение «сосед полил газон».
Сколько всего таких решений нужно принять? Не более чем n – число предложений. Сколько операций нужно совершить при принятии одного решения? Для каждого решения нам нужно обойти ребра графа не более одного раза, т. е. совершить не более n операций на одно решение. Значит, что нужно совершить не более чем n2 операций для нахождения I. ■
Задача «на подумать»
Данная задача может потребовать дополнительного изучения и поиска литературы.
Тривиальное решение SAT
УсловиеКаждую пропозиционную формулу F = c1 and c2 and c3 and cn можно привезти к дизъюнктивной нормальной форме (DNF) т. е. к виду F' = c'1 or c'2 … or c'k, где с'i имеет вид (x and y and z), x, y, z – переменные или их отрицания. Например, с помощью последовательного применения правил Де Моргана (ссылка) и раскрытия скобок.
Для F' существует тривиальный алгоритм поиска функции I. Необходимо, чтобы по крайней мере один из c'i был истинным. Напишем простой псевдокод решающий задачу:
#Input: F — propositional formula in disjunctive normal form (DNF)
#Output: {SAT, UNSAT}
for each c in F do
if c is SAT:
return SAT
return UNSAT
Для каждого предложения (сlause) ci алгоритм поиска I так же тривиальный, если предложение ci не содержит некоторой переменной v и её отрицания одновременно, то ci выполнимо (SAT).
Итого: получаем тривиальный алгоритм проверки формулы на выполнимость
Найти: где ошибка?
Ссылки и источники
Картинка во введении взята из
Computational Complexity and the Anthropic Principle Scott Aaronson
Слайды
Why SAT Scales: Phase Transition Phenomena & Back Doors to Complexity slides courtesy of Bart Selman Cornell University.
Слайды основаны на статье:
2+P-SAT: Relation of typical-case complexity to the nature of the phase transition (Monasson, Remi; Zecchina, Riccardo; Kirkpatrick, Scott; Selman, Bart; and Troyansky, Lidror.)
Остальные статьи можно найти здесь
Подробнее об истории NP можно прочитать здесь:
The History and Status of the P versus NP Question by Michael Sipser
P versus NP by Elvira Mayordomo
Подробнее о SAT-solver'ах:
SAT Solvers: A Condensed History
Understanding Modern SAT Solvers — автор Armin Biere, пожалуй, самый известный разработчик SAT Solver'ов в мире. Дональд Кнут, который сейчас пишет «The Art of Computer Programming: Volume 4B, Pre-fascicle 6A Satisfiability», говорит, что по многим вопросам консультируется именно у него.
Towards a new era of SAT Solvers
Материал с Хабры:
[1] Почему я не верю в простые алгоритмы для NP-полных задач
[2] Еще немного про P и NP
[3] Открытое письмо ученым и эталонная реализация алгоритма Романова для NP-полной задачи 3-ВЫП
[4] Опубликовано доказательство P ≠ NP?
[5] P=NP? Важнейшая нерешенная задача теоретической информатики.
[6] Теоретическая информатика в Академическом Университете
[7] Топ-10 результатов в области алгоритмов за 2012 год
[8] Доказано, что игра Super Mario является NP-полной задачей
[9] Введение в анализ сложности алгоритмов (часть 1)
[10] Введение в анализ сложности алгоритмов (часть 2)
[11] Введение в анализ сложности алгоритмов (часть 3)
[12] Введение в анализ сложности алгоритмов (часть 4)
[13] Знай сложности алгоритмов

{kind=link}