
Проведено сравнение производительности ядер HTTP-серверов, построенных с использованием семи C/C++ библиотек, а также (в познавательных целях) — других готовых решений в этой области (nginx и node.js).
HTTP-сервер — это сложный и интересный механизм. Есть мнение, что плох программист, не написавший свой компилятор, я бы заменил «компилятор» на «HTTP-сервер»: это и парсер, и работа с сетью, и асинхронность с многопоточностью и много чего еще....
Тесты по всем возможным параметрам (отдача статики, динамики, всевозможные модули шифрования, прокси и т.п.) — задача не одного месяца кропотливой работы, поэтому задача упрощена: будем сравнивать производительность ядер. Ядро HTTP-сервера (как и любого сетевого приложения) — это диспетчер событий сокетов и некий первичный механизм их обработки (реализованный в виде пула потоков, процессов и т.п.). Сюда же можно отнести парсер HTTP-пакетов и генератор ответов. На первый взгляд, все должно свестись к тестированию возможностей того или иного системного механизма обработки асинхронных событий (select, epoll и т.п.), их мета-обёрток (libev, boost.asio и др.) и ядра ОС, однако конкретная реализация в виде готового решения дает существенную разницу в производительности.
Был реализован свой вариант HTTP-сервера на libev. Конечно, реализована поддержка небольшого подмножества требований пресловутого rfc2616 (вряд ли ее полностью реализует хоть один HTTP-сервер), лишь необходимый минимум для соответствия требованиям, предъявляемым к участникам данного тестирования,
- Слушать запросы на 8000-ом порту;
- Проверять метод (GET);
- Проверять путь в запросе (/answer);
- Ответ должен содержать:
HTTP/1.1 200 OK Server: bench Connection: keep-alive Content-Type: text/plain Content-Length: 2 42
- На любой другой метод\путь — должен возвращаться ответ с кодом ошибки 404 (страница не найдена).
Как видите — никаких расширений, обращений к файлам на диске, интерфейсов шлюза и т.п. — все максимально упрощено.
В случаях, когда сервер не поддерживает keep-alive соединения (кстати, этим отличился только cpp-netlib), тестирование проводилось в соотв. режиме.
Предыстория
Изначально стояла задача реализовать HTTP-сервер с нагрузкой в сотни миллионов обращений в сутки. Предполагалось, что будет относительно небольшое кол-во клиентов, генерирующих 90% запросов, и большое число клиентов, генерирующих оставшиеся 10%. Каждый запрос нужно отправлять дальше, на несколько других серверов, собирать ответы и возвращать результат клиенту. От скорости и качества ответа зависел весь успех проекта. Поэтому просто взять и использовать первое попавшееся готовое решение не представлялось возможным. Нужно было получить ответы на следующие вопросы:
- Стоит ли изобретать свой велосипед или же использовать существующие решения?
- Подходит ли node.js для высоконагруженных проектов?
Если да, то выкинуть заросли С++ кода и переписать все в 30 строк на JS.
Были и менее значимые вопросы, например, влияет ли HTTP keep-alive на производительность? (спустя год ответ был озвучен здесь — влияет, и весьма существенно).
Разумеется, сначала был изобретён свой велосипед, затем появился node.js (узнал про него два года назад), ну а потом захотелось узнать: насколько существующие решения эффективнее собственного, не зря ли было потрачено время? Собственно, так и появился данный пост.
Подготовка
Железо
- Процессор: CPU: AMD FX(tm)-8120 Eight-Core Processor
- Cеть: localhost (почему — см. в TODO)
Софт
- ОС: FreeBSD 9.1-RELEASE-p7
Тюнинг
Обычно в нагрузочном тестировании сетевых приложений принято изменять следующий стандартный набор настроек:
/etc/sysctl.conf
kern.ipc.somaxconn=65535
net.inet.tcp.blackhole=2
net.inet.udp.blackhole=1
net.inet.ip.portrange.randomized=0
net.inet.ip.portrange.first=1024
net.inet.ip.portrange.last=65535
net.inet.icmp.icmplim=1000
net.inet.tcp.blackhole=2
net.inet.udp.blackhole=1
net.inet.ip.portrange.randomized=0
net.inet.ip.portrange.first=1024
net.inet.ip.portrange.last=65535
net.inet.icmp.icmplim=1000
/boot/loader.conf
kern.ipc.semmni=256
kern.ipc.semmns=512
kern.ipc.semmnu=256
kern.ipc.maxsockets=999999
kern.ipc.nmbclusters=65535
kern.ipc.somaxconn=65535
kern.maxfiles=999999
kern.maxfilesperproc=999999
kern.maxvnodes=999999
net.inet.tcp.fast_finwait2_recycle=1
kern.ipc.semmns=512
kern.ipc.semmnu=256
kern.ipc.maxsockets=999999
kern.ipc.nmbclusters=65535
kern.ipc.somaxconn=65535
kern.maxfiles=999999
kern.maxfilesperproc=999999
kern.maxvnodes=999999
net.inet.tcp.fast_finwait2_recycle=1
Однако в моем тестировании они не приводили к повышению производительности, а в некоторых случаях даже приводили к значительному замедлению, поэтому в финальных тестах никаких изменений настроек в системе не проводилось (т.е. все настройки по умолчанию, ядро GENERIC).
Участники
Библиотечные
| Имя | Версия | События | Поддержка keep-alive | Механизм |
|---|---|---|---|---|
| cpp-netlib | 0.10.1 | Boost.Asio | нет | многопоточный |
| hand-made | 1.11.30 | libev | да | многопроцессный (один поток на процесс), асинхронный |
| libevent | 2.0.21 | libevent | да | однопоточный*, асинхронный |
| mongoose | 5.0 | select | да | однопоточный, асинхронный, со списком (подробнее) |
| onion | 0.5 | libev | да | многопоточный |
| Pion Network Library | 0.5.4 | Boost.Asio | да | многопоточный |
| POCO C++ Libraries | 1.4.3 | select | да | многопоточный (отдельный поток для входящих соединений), с очередью (подробнее) |
Готовые решения
| Имя | Версия | События | Поддержка keep-alive | Механизм |
|---|---|---|---|---|
| Node.js | 0.10.17 | libuv | да | модуль cluster (многопроцессная обработка) |
| nginx | 1.4.4 | epoll, select, kqueue | да | многопроцессная обработка |
*для тестов переделан по схеме «многопроцессный — один процесс один поток»
Дисквалифицированы
| Имя | Причина |
|---|---|
| nxweb | только Linux |
| g-wan | только Linux (и вообще...) |
| libmicrohttpd | постоянные падения при нагрузках |
| yield | ошибки компиляции |
| EHS | ошибки компиляции |
| libhttpd | синхронный, HTTP/1.0, не дает поменять заголовки |
| libebb | ошибки компиляции, падения |
В качестве клиента использовалось приложение от разработчиков lighttpd — weighttpd. Изначально планировалось использовать httperf, как более гибкий инструмент, но он постоянно падает. Кроме того, weighttpd основан на libev, который гораздо лучше подходит для FreeBSD, чем httperf с select-ом. В качестве главного тестового скрипта (обертки над weighttpd с подсчётом расхода ресурсов и пр.) рассматривался gwan-овский ab.c, переделанный под FreeBSD, но в последствии был переписан с нуля на Пайтоне (bench.py в приложении).
Клиент и сервер запускались на одной и той же физической машине.
В качестве переменных значений использовались:
- Количество серверных потоков (1, 2 и 3)
- Количество параллельно открытых запросов клиентов (10, 100, 200, 400, 800)
В каждой конфигурации выполнялось по 20-30 итераций, 2 млн. запросов за итерацию.
Результаты
В первой версии статьи были допущены грубые нарушения в методике тестировании, на что было указано в комментариях пользователями VBart и wentout. Так, в частности, не использовалось строгое разделение задач по ядрам процессора, общее кол-во потоков сервера\клиента превышало допустимые нормы. Также не были отключены опции, влияющие на результаты измерений (AMD Turbo Core), не были указаны погрешности измерений. В текущей версии статьи используется подход, описанный здесь.
Для серверов, запущенных в однопоточном режиме, получены следующие результаты (взяты максимальные медианы по комбинациям серверных/клиентских потоков):
| Место | Имя | Клиентск. потоков | Проц. время | Запросов | ||
|---|---|---|---|---|---|---|
| Польз. | Сист. | Успешных (в сек.) | Неуспешных (%) | |||
| 1 | nginx | 400 | 10 | 10 | 101210 | 0 |
| 2 | mongoose | 200 | 12 | 15 | 53255 | 0 |
| 3 | libevent | 200 | 16 | 33 | 39882 | 0 |
| 4 | hand-made | 100 | 20 | 32 | 38550 | 0 |
| 5 | onion | 10 | 22 | 33 | 29230 | 0 |
| 6 | POCO | 10 | 25 | 50 | 20943 | 0 |
| 7 | pion | 10 | 24 | 83 | 16526 | 0 |
| 8 | node.js | 10 | 23 | 173 | 9374 | 0 |
| 9 | cpp-netlib | 10 | 100 | 183 | 5362 | 0 |
Масштабируемость:
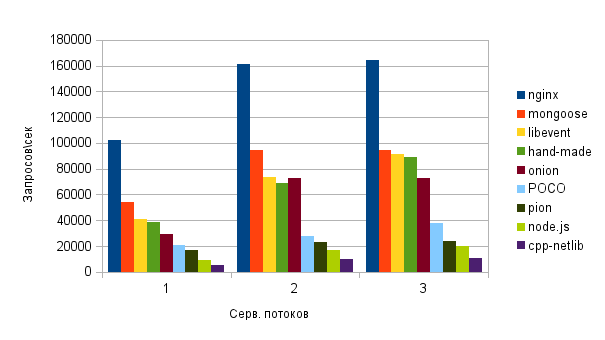
В теории, если бы ядер было больше, мы бы наблюдали линейный рост производительности. К сожалению, проверить теорию не представляется возможным — ядер не хватает.
nginx, откровенно говоря, удивил — ведь по сути это готовое, многофункциональное, модульное решение, а результаты на порядок превзошли узкоспециализированные библиотеки. Респект.
mongoose пока сыроват, версия 5.0 не обкатана и ветка находится в активной стадии разработки.
cpp-netlib показал худший результат. Мало того что он единственный не поддерживал HTTP keep-alive соединения, так ещё и падал где-то в недрах boost-а, было проблематично выполнить все итерации подряд. Однозначно, решение сырое, документация — устаревшая. Законное последнее место.
node.js уже ругали здесь, не буду так категоричен, но V8 еще пилить и пилить. Что это за high-load решение, которое даже без полезной нагрузки так жадно потребляет ресурсы и выдаёт 10-20% производительности топовых участников тестирования?
HTTP keep-alive on/off: если в посте разница доходила до x2 раз, то в моих тестах разница была до х10.
Погрешность по ministat: No difference proven at 95.0% confidence.
TODO
- бенчмарк в режиме «клиент и сервер на разных машинах». Нужно быть осторожным — все может упереться в сетевые железки, причём не только модели сетевых карт, а свичей, роутеров и т.п. — всю инфраструктуру между реальными машинами. Для начала можно попробовать прямое подключение;
- тестирование клиентской HTTP API (организовать в виде сервера и прокси). Проблема в том, что далеко не все библиотеки предоставляют API для реализации HTTP-клиента. С другой стороны, некоторые популярные библиотеки (libcurl, например) предоставляют исключительно клиентский набор API;
- использование других HTTP-клиентов. httperf не использовался по указанным выше причинам, ab — по многим отзывам устарел и не держит реальных нагрузок. Многие рекомендовали . Здесь представлена пара десятков решений, какие-то из них стоило бы сравнить;
- аналогичный бенчмарк в Linux-среде. Вот это должна быть интересная тема (как минимум — новая волна для холиварных обсуждений);
- прогнать тесты на топовом Intel Xeon с кучей ядер.
Ссылки
Stress-testing httperf, siege, apache benchmark, and pronk — HTTP-клиенты для нагрузочного тестирования серверов.
Performance Testing with Httperf — советы и рекомендации о проведении бенчмарков.
ApacheBench & HTTPerf — описание процесса бенчмарка от G-WAN.
Warp — еще один high-load HTTP-сервер с претензией, Haskell.
Приложение
В приложении вы найдёте исходники и результаты всех итераций тестирования, а также подробные сведения по сборке и установке HTTP-серверов.
