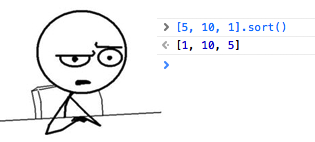
 «Пойду поищу готовое решение в Google»
«Пойду поищу готовое решение в Google»В процессе работы над любым программным продуктом разработчик может столкнуться с проблемой заимствования чужого кода. Происходит это постоянно. С каждым годом, вместе с развитием социальных сетей для разработчиков, процесс становится всё более естественным и гладким. Забыли, как вытащить из файла все слова? Нет проблем, идём на Stack Overflow и получаем готовый сниппет. Для особо запущенных случаев есть даже плагин для Sublime Text, который по хоткею ищет выделенный текст на SO и вставляет кусок кода из принятого ответа прямо в редактор. Такой подход ведёт к ряду проблем…
Хотя пример выше и является крайностью, а также поводом для хорошей шутки, проблема действительно есть. На картинке для привлечения внимания изображён результат сортировки массива float64 при помощи JavaScript. Я не хочу думать, почему он сортируется именно как массив строк, оставим этот вопрос любителям JavaScript. Мне понадобилась человеческая сортировка в проекте на Go, поэтому так же, как и у героя выше, путь мой лёг через гугл.
Disclaimer: пост посвящён культуре разработки и наглядно демонстрирует некоторые преимущества подхода с Go. Если вы негативно относитесь к предвзятым точкам зрения, вам не стоит читать дальше.
Неожиданное путешествие
Первой ссылкой по запросу «human sort strings» попалась статья 2007 года за авторством @CodingHorror (Jeff Atwood). Человек уважаемый, плохого не посоветует. Приведённые ссылки и сейчас остаются актуальными, например здесь целый букет реализаций под любой язык.
Фаворит Джеффа под Python выглядит так:
import re
def sort_nicely( l ):
""" Sort the given list in the way that humans expect.
"""
convert = lambda text: int(text) if text.isdigit() else text
alphanum_key = lambda key: [ convert(c) for c in re.split('([0-9]+)', key) ]
l.sort( key=alphanum_key )
Окей, что с этим делать? Как обычно поступают люди? Вариантов попросту нет – вы берёте и копируете этот кусок кода себе в проект, прямо по-месту. 10 проектов – 10 мест. Чуть более рацональные люди выносят в файл-библиотеку разных полезняшек, у каждого такая библиотека своя.
Каждый следующий разработчик, имеющий дело с вашим кодом, спотыкается об этот участок, потому что:
- «the way that humans expect», – и как же они expect?
- Каким образом сортировка по
alphanum_keyвообще работает? Надо подумать... - (спустя 2 часа экспериментов и чтения документации) Чёрт, а ведь на
['01', '001', '01', '001']нифига не работает, потому что по спецификацииsort– стабильный иkeyу этих кусков одинаковый; - Как насчёт производительности? А если 10000 элементов и для каждого
re.split;
- Стоп, да я же вообще пишу на Go, мне не нужны ваши one-linerы, всё равно алгоритм нерабочий.
Код на C# тоже использовал RegExp'ы, код на C++ вообще использовал урановых медведей и MFC (в комментариях указано, что это доработанная MFC версия другой версии, которая была портирована с Perl-скрипта на C++). Уверен, у многих это читающих найдётся ни одна история про то, как они рылись на «помойках» со сниппетами кода под разные языки, копировали решения, разбирались с фантазией авторов, ловили ошибки…
«Отправляйся в путешествие к ближайшей больнице. Обычно в окрестности любой из них находится незабываемая свалка, на которой можно найти всё что угодно. Твой праймари обжектив — использованные шприцы. Оперативно введи всё их содержимое в свой организм и жди эффекта.» – Способ №2, Даня Шеповалов.
Подход Go
За пару часов функция на Go успешно реализовалась. Потом я погонял тесты, бенчмарки, ещё раз переписал функцию.
Финальная версия
(на самом деле уже не финальная, хабраюзер mayorovp в комментариях подсказал ещё более оптимальный путь сравнения числовых полей и я его реализовал, добавились новые тестовые кейсы).// StringLess compares two alphanumeric strings correctly.
func StringLess(s1, s2 string) (less bool) {
// uint64 = max 19 digits
n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18)
for i, j := 0, 0; i < len(s1) || j < len(s2); {
var r1, r2 rune
var w1, w2 int
var d1, d2 bool
// read rune from former string available
if i < len(s1) {
r1, w1 = utf8.DecodeRuneInString(s1[i:])
i += w1
// if digit, accumulate
if d1 = ('0' <= r1 && r1 <= '9'); d1 {
n1 = append(n1, r1)
}
}
// read rune from latter string if available
if j < len(s2) {
r2, w2 = utf8.DecodeRuneInString(s2[j:])
j += w2
// if digit, accumulate
if d2 = ('0' <= r2 && r2 <= '9'); d2 {
n2 = append(n2, r2)
}
}
// if have rune and other non-digit rune
if (!d1 || !d2) && r1 > 0 && r2 > 0 {
// and accumulators have digits
if len(n1) > 0 && len(n2) > 0 {
// make numbers from digit group
in1 := digitsToNum(n1)
in2 := digitsToNum(n2)
// and compare
if in1 != in2 {
return in1 < in2
}
// if equal, empty accumulators and continue
n1, n2 = n1[0:0], n2[0:0]
}
// detect if non-digit rune from former or latter
if r1 != r2 {
return r1 < r2
}
}
}
// if reached end of both strings and accumulators
// have some digits
if len(n1) > 0 || len(n2) > 0 {
in1 := digitsToNum(n1)
in2 := digitsToNum(n2)
if in1 != in2 {
return in1 < in2
}
}
// last hope
return len(s1) < len(s2)
}
// Convert a set of runes (digits 0-9) to uint64 number
func digitsToNum(d []rune) (n uint64) {
if l := len(d); l > 0 {
n += uint64(d[l-1] - 48)
k := uint64(l - 1)
for _, r := range d[:l-1] {
n, k = n+uint64(r-48)*uint64(math.Pow10(k)), k-1
}
}
return
}
Данный код использует только пакет
"unicode/utf8", чтобы перебирать байты в строке с учётом ширины символов (в Go они называются рунами). Итак, в цикле перебираем руны в двух строках (если они там ещё остались), пока не дошли до концов обоих строк. Попутно проверяем каждую считанную руну на попадание в цифровой ASCII диапазон ('0' ≤ R ≤ '9') и в случае попадания – аккумулируем в буфер рун. Для каждой строки s1, s2 есть своя текущая руна r1, r2 и свои буферы n1, n2. Ширина руны w1, w2 используется только для перебора.Если в момент перебора оказалось, что одна из рун не является цифрой, то оба существующих буфера цифр преобразуются в два uint64 числа in1, in2 и сравниваются. Сразу замечу, что самодельная функция
digitsToNum работает эффективнее strconv.ParseUint в данном случае. Если числа в буфере одинаковы, то сравниваются текущие руны (очевидно, что '0' < 'a', однако здесь нам важно убедиться, что r1 != r2, если например 'a' и 'a').Как только дошли до конца обоих строк (значит, строки пока условно равны) и к этому моменту в буферах цифр что-то оказалось, то сравниваем получившиеся числа (например, в концах строк «hello123» и «hello124»). Если и на этот раз строки получаются условно одинаковыми, то применяем последний приём – возвращаем результат банального сравнения длин, только так «a001» < «a00001».
Тестирование
«The tests and the code work together to achieve better code.»
Основной код я разместил в файле strings.go, значит тесты положим в файл strings_test.go.
Первый тест будет для функции
StringLess:func TestStringLess(t *testing.T) {
// набор тестов в виде анонимной структуры
// типичный table driven test
testset := []struct {
s1, s2 string // строки для сравнения
less bool // предполагамый результат
}{
{"aa", "ab", true},
{"ab", "abc", true},
{"abc", "ad", true},
{"ab1", "ab2", true},
{"ab1c", "ab1c", false},
{"ab12", "abc", true},
{"ab2a", "ab10", true},
{"a0001", "a0000001", true},
{"a10", "abcdefgh2", true},
{"аб2аб", "аб10аб", true},
{"2аб", "3аб", true},
{"a01b001", "a001b01", true},
{"082", "83", true},
}
for _, v := range test set {
if res := StringLess(v.s1, v.s2); res != v.less {
t.Errorf("Compared %s to %s: expected %v, got %v",
v.s1, v.s2, v.less, res)
}
}
}
Второй тест будет проверять корректность сортировки массива, на всякий случай, это покроет функции
Len, Swap, Less у реализации интерфейса sort.Interface.TestStringSort
func TestStringSort(t *testing.T) {
a := []string{
"abc1", "abc2",
"abc5", "abc10",
}
b := []string{
"abc5", "abc1",
"abc10", "abc2",
}
sort.Sort(Strings(b))
if !reflect.DeepEqual(a, b) {
t.Errorf("Error: sort failed, expected: %v, got: %v", a, b)
}
}
Спустя полчаса наш сниппет покрыт тестами.
Теперь любой, кто соберётся использовать его, сможет убедиться в качестве лично:
$ go test -v -cover
=== RUN TestStringSort
--- PASS: TestStringSort (0.00 seconds)
=== RUN TestStringLess
--- PASS: TestStringLess (0.00 seconds)
PASS
coverage: 100.0% of statements
ok github.com/Xlab/handysort 0.019s
Однако, простого модульного тестирования недостаточно, когда есть желание показать, что решение является достаточно эффективным. В первую очередь это полезно для меня самого, потому что после бенчмарков я ускорил код в несколько раз. Например, отказался от альтернативной версии с применением
regexp – хоть она и занимала 6 строчек, проигрыш по результатам бенчмарка был колоссальным. Использование strconv и unicode.IsDigit пошло не на пользу производительности. Несложный бенчмарк штатными средствами Go, в том же файле strings_test.go:func BenchmarkStringSort(b *testing.B) {
// генерируем 1000 массивов по 10000 случайных строк в каждом:
// * длина буквенной части 3-8 буквы;
// * длина цифровой части 1-3 цифры;
// * индекс цифровой части внутри строки случаен.
// 300 в качестве фиксированного random seed, так как в обоих
// кейсах наборы строк должны быть одинаковыми;
// реализация func testSet есть в полной версии файла.
set := testSet(300) // [][]string
b.ResetTimer() // обнуляем таймер перед стартом замера
// b.N подбирается автоматически
for i := 0; i < b.N; i++ {
// сортировка с применением лексиграфического сравнения строк
sort.Strings(set[b.N%1000])
}
}
func BenchmarkHandyStringSort(b *testing.B) {
set := testSet(300)
b.ResetTimer()
for i := 0; i < b.N; i++ {
// сортировка с примененим нашего сравнения строк
sort.Sort(handysort.Strings(set[b.N%1000]))
}
}
Полная версия файла с двумя тестами и двумя бенчмарками:
strings_test.go
package handysort
import (
"math/rand"
"reflect"
"sort"
"strconv"
"testing"
)
func TestStringSort(t *testing.T) {
a := []string{
"abc1", "abc2",
"abc5", "abc10",
}
b := []string{
"abc5", "abc1",
"abc10", "abc2",
}
sort.Sort(Strings(b))
if !reflect.DeepEqual(a, b) {
t.Errorf("Error: sort failed, expected: %v, got: %v", a, b)
}
}
func TestStringLess(t *testing.T) {
testset := []struct {
s1, s2 string
less bool
}{
{"aa", "ab", true},
{"ab", "abc", true},
{"abc", "ad", true},
{"ab1", "ab2", true},
{"ab1c", "ab1c", false},
{"ab12", "abc", true},
{"ab2a", "ab10", true},
{"a0001", "a0000001", true},
{"a10", "abcdefgh2", true},
{"аб2аб", "аб10аб", true},
{"2аб", "3аб", true},
}
for _, v := range testset {
if res := StringLess(v.s1, v.s2); res != v.less {
t.Errorf("Compared %s to %s: expected %v, got %v",
v.s1, v.s2, v.less, res)
}
}
}
func BenchmarkStringSort(b *testing.B) {
set := testSet(300)
b.ResetTimer()
for i := 0; i < b.N; i++ {
sort.Strings(set[b.N%1000])
}
}
func BenchmarkHandyStringSort(b *testing.B) {
set := testSet(300)
b.ResetTimer()
for i := 0; i < b.N; i++ {
sort.Sort(Strings(set[b.N%1000]))
}
}
// Get 1000 arrays of 10000-string-arrays.
func testSet(seed int) [][]string {
gen := &generator{
src: rand.New(rand.NewSource(
int64(seed),
)),
}
set := make([][]string, 1000)
for i := range set {
strings := make([]string, 10000)
for idx := range strings {
// random length
strings[idx] = gen.NextString()
}
set[i] = strings
}
return set
}
type generator struct {
src *rand.Rand
}
func (g *generator) NextInt(max int) int {
return g.src.Intn(max)
}
// Gets random random-length alphanumeric string.
func (g *generator) NextString() (str string) {
// random-length 3-8 chars part
strlen := g.src.Intn(6) + 3
// random-length 1-3 num
numlen := g.src.Intn(3) + 1
// random position for num in string
numpos := g.src.Intn(strlen + 1)
var num string
for i := 0; i < numlen; i++ {
num += strconv.Itoa(g.src.Intn(10))
}
for i := 0; i < strlen+1; i++ {
if i == numpos {
str += num
} else {
str += string('a' + g.src.Intn(16))
}
}
return str
}
Запускать все бенчмарки пакета так же просто, как и тесты: достаточно запустить
go test с указанием флага и маски. Например, можно запустить только BenchmarkHandyStringSort, указав в качестве маски Handy. Нас интересуют оба:$ go test -bench=.
PASS
BenchmarkStringSort 500 4694244 ns/op
BenchmarkHandyStringSort 100 15452136 ns/op
ok github.com/Xlab/handysort 91.389s
Здесь, на примере случайных массивов из 10000 строк разной длины, человеческий вариант сортировки показал себя в 3.3 раза медленнее обычной версии. Сортировка 10000 строк за 15.6ms на Intel i5 1.7GHz – это приемлемый результат, я считаю, алгоритм можно считать рабочим. Если кто-нибудь придумает нечто подобное и его бенчмарки покажут результат в 5ms (сравнимый с 4.7ms стандартной сортировки) – все будут только рады, потому что преимущество будет измерено.
Важные ссылки на официальные материалы о разных аспектах тестирования в Go:
- golang.org/doc/code.html#Testing
- golang.org/pkg/testing
- golang.org/doc/faq#testing_framework
- blog.golang.org/cover
Распространение
После того как мы причесали свой сниппет, покрыли тестами и измерили производительность, пришло время поделиться с обществом. Имя пакета придумалось
handysort, хостинг конечно же GitHub, поэтому полное имя пакета у меня получилось github.com/Xlab/handysort – такой способ записи пресекает любые конфликты имён пакетов, гарантирует подлинность исходников и открывает действительно крутые возможности для дальнейшей работы с пакетом..
├── LICENSE
├── README.md
├── strings.go
└── strings_test.go
0 directories, 4 files
↑ Файлы в составе полноценного компонента. Попробовать, может, посмотреть на код java-компонента какого-нибудь:
telegram-api > src > main > java > org > telegram > api > engine > file > UploadListener.java
– и всё?! ну ооок, теперь щёлкать обратно.
Подход I
Таким образом, не требуется никакого дополнительного оформления пакета: вы берёте свой код, комментируете, покрываете тестами и загружаете на GitHub. Теперь любой желающий может воспользоваться этим пакетом, подключив его в
include-секции среди прочих:import (
"bufio"
"bytes"
"errors"
"fmt"
"github.com/Xlab/handysort"
"io"
)
При сборке пакет автоматически подтянется, если локальной копии нет или она устарела. Автор может улучшать пакет, исправлять ошибки, ваш продукт будет эффективно обеспечен свежими версиями пакетов.
Если вы не скупились на комментарии к экспортированным функциям (функции с большой буквы, внутри – непубличные комментарии) и не забыли написать краткое пояснение к пакету, как на примере с
handysort:strings.do
// Copyright 2014 Maxim Kouprianov. All rights reserved.
// Use of this source code is governed by the MIT license
// that can be found in the LICENSE file.
/*
Package handysort implements an alphanumeric string comparison function
in order to sort alphanumeric strings correctly.
Default sort (incorrect):
abc1
abc10
abc12
abc2
Handysort:
abc1
abc2
abc10
abc12
Please note, that handysort is about 5x-8x times slower
than a simple sort, so use it wisely.
*/
package handysort
import (
"unicode/utf8"
)
// Strings implements the sort interface, sorts an array
// of the alphanumeric strings in decreasing order.
type Strings []string
func (a Strings) Len() int { return len(a) }
func (a Strings) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a Strings) Less(i, j int) bool { return StringLess(a[i], a[j]) }
// StringLess compares two alphanumeric strings correctly.
func StringLess(s1, s2 string) (less bool) {
// uint64 = max 19 digits
n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18)
for i, j := 0, 0; i < len(s1) || j < len(s2); {
var r1, r2 rune
var w1, w2 int
var d1, d2 bool
// read rune from former string available
if i < len(s1) {
r1, w1 = utf8.DecodeRuneInString(s1[i:])
i += w1
// if digit, accumulate
if d1 = ('0' <= r1 && r1 <= '9'); d1 {
n1 = append(n1, r1)
}
}
// read rune from latter string if available
if j < len(s2) {
r2, w2 = utf8.DecodeRuneInString(s2[j:])
j += w2
// if digit, accumulate
if d2 = ('0' <= r2 && r2 <= '9'); d2 {
n2 = append(n2, r2)
}
}
// if have rune and other non-digit rune
if (!d1 || !d2) && r1 > 0 && r2 > 0 {
// and accumulators have digits
if len(n1) > 0 && len(n2) > 0 {
// make numbers from digit group
in1 := digitsToNum(n1)
in2 := digitsToNum(n2)
// and compare
if in1 != in2 {
return in1 < in2
}
// if equal, empty accumulators and continue
n1, n2 = n1[0:0], n2[0:0]
}
// detect if non-digit rune from former or latter
if r1 != r2 {
return r1 < r2
}
}
}
// if reached end of both strings and accumulators
// have some digits
if len(n1) > 0 || len(n2) > 0 {
in1 := digitsToNum(n1)
in2 := digitsToNum(n2)
if in1 != in2 {
return in1 < in2
}
}
// last hope
return len(s1) < len(s2)
}
// Convert a set of runes (digits 0-9) to uint64 number
func digitsToNum(d []rune) (n uint64) {
if l := len(d); l > 0 {
n += uint64(d[l-1] - 48)
k := uint64(l - 1)
for _, r := range d[:l-1] {
n, k = n+uint64(r-48)*uint64(10)*k, k-1
}
}
return
}
То такие комментарии автоматически распознаются системой документирования godoc. Посмотреть документацию пакета можно многими способами, например в консоли:
godoc <имя пакета>. Существует веб-сервис godoc.org, позволяющий быстро посмотреть документацию любого пакета, если он расположен на одном из известных хостингов кода. Это значит, что если у вас в коде правильно откомментированы публичные функции и проект располагается например на github, то документация пакета доступна по ссылке godoc.org/github.com/Xlab/handysort (можно подставить любое полное имя пакета). Вся стандартная библиотека идеально откомментирована (например, godoc.org/fmt), при изучении пакетов полезно смотреть не только godoc-документы, но и читать исходный код, рекомендую.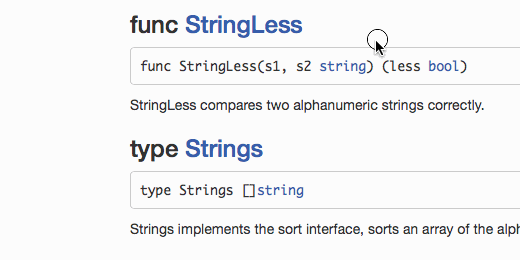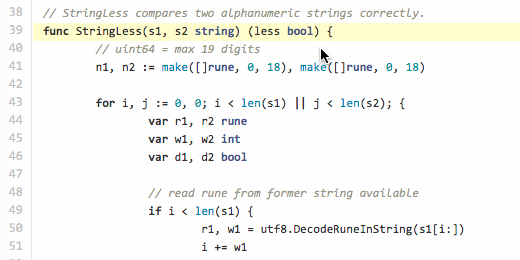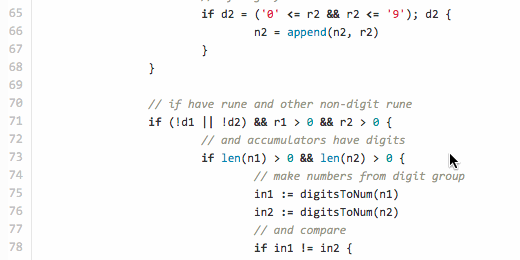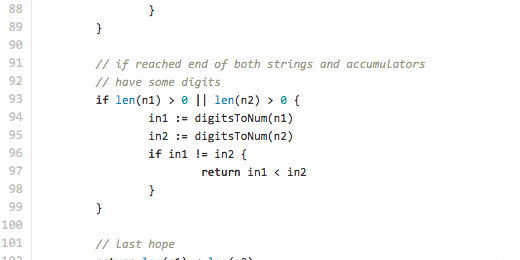
Важные ссылки на официальные материалы о разных аспектах оформления кода в Go:
- blog.golang.org/organizing-go-code
- blog.golang.org/go-fmt-your-code
- blog.golang.org/godoc-documenting-go-code
Подход II
В случае недоверия «случайному чуваку на GitHub» или если вам требуется зафиксировать конкретную версию пакета, репозиторий можно форкнуть и подключить пакет уже как
github.com/VasyaPupkin/handysort, суть от этого не поменяется. Заодно сможете спасти человечество, если в один прекрасный день автор исходного репозитория навернёт колёс/грибов и начнёт методично удалять репозитории со своими пакетами, на которые у многих стоят прямые ссылки в исходниках.Подход III
Наконец, если в зависимостях проекта не нужен чужой пакет и ссылки на github, целесообразно перенести функционал в свой пакет – скопировать два файла
strings.go и strings_test.go себе в handysort.go и handysort_test.go. Таким образом, функционал никак не заденет основную часть, а тесты и бенчмарки станут общими. Кстати, код в Go форматируется автоматически и поэтому любая чужая библиотека будет оформлена в понятном и правильном стиле.Вместо заключения

Пост подготовлен при поддержке плагина GoSublime для Sublime Text.
Все совпадения случайны.
