Comments 19
Есть еще одна библиотека — debug (npm debug). Ее очень удобно использовать как в процессе написания библиотек, так и для логирования. Она не имеет привычных уровней логирования, вместо этого вводятся id типа логов, кооторые можно гибко включать, используя wildcard.
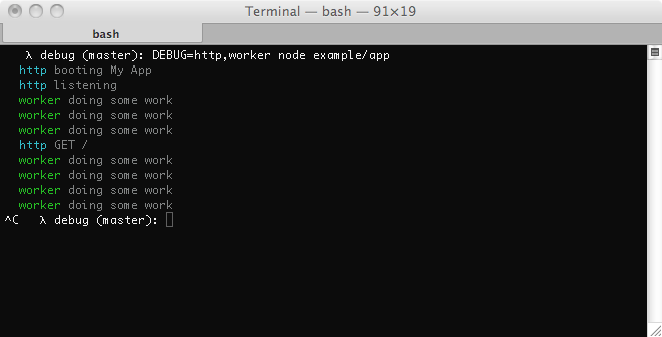
Рекомендую ;)
var debug = require('debug')('worker');
setInterval(function(){
debug('doing some work');
}, 1000);
$ DEBUG=http,worker node server.js
Рекомендую ;)
Несколько вопросов:
1. Есть ли разделение логов по датам, т.е. каждый день, час или месяц начинаем писать в новый файл?
2. Есть ли автоматическое удаление старых файлов (например, храним 100 последних)?
3. Поддерживается ли запись в лог из нескольких процессов (cluster)?
4. Реализована ли буферизация записи в лог на уровне таймеров (запись не чаще N мсек.) и на уровне объема буфера (например, пишем в память 128кб и сбрасываем это на диск в свободное время)?
1. Есть ли разделение логов по датам, т.е. каждый день, час или месяц начинаем писать в новый файл?
2. Есть ли автоматическое удаление старых файлов (например, храним 100 последних)?
3. Поддерживается ли запись в лог из нескольких процессов (cluster)?
4. Реализована ли буферизация записи в лог на уровне таймеров (запись не чаще N мсек.) и на уровне объема буфера (например, пишем в память 128кб и сбрасываем это на диск в свободное время)?
4. Это забота ядра, двойная буферизация будет лишней. Вряд ли какой-либо из логгеров делает fdatasync, чтобы что-то изменить.
Тем не менее, у класса stream.Writable в Node.js есть собственные буферы чтения и записи, и мы можем управлять их размерами. Более того, я проводил тесты для CentOS 6.5 (64 бит) и Win 7 (64 бит), в обоих случаях производительность записи в логи существенно поднималась, если увеличить буфер записи, выделенный по-умолчанию с 16 кб до 64 кб, а вот при большем увеличении, существенного увеличения производительности нет.
Автору библиотеки, btd: при создании файлового потока 1 строчку можно дописать и будет шустрее, см. пример тут.
Автору библиотеки, btd: при создании файлового потока 1 строчку можно дописать и будет шустрее, см. пример тут.
Про intel:
1. Да
2. Да
3. Нет
4. Нет
Если говорить как я делаю н-р logrotate
1. Да
2. Да
3. Не думаю что игра стоит свеч чтобы во время исполнения синхронизировать логи от нескольких процессов. Я лично пишу в разные файлы. Если нужно будет собрать я использую коллектор.
4. Идея понятна, но тут еть несколько моментов: 1. Нода работает в одном процессе, логи пишутся в нем же при краше процесса мы херим логи, 2. В intel используются стримы не думаю что это сложно реализовать на их уровне и просто скормить обработчику собстевенный.
1. Да
2. Да
3. Нет
4. Нет
Если говорить как я делаю н-р logrotate
1. Да
2. Да
3. Не думаю что игра стоит свеч чтобы во время исполнения синхронизировать логи от нескольких процессов. Я лично пишу в разные файлы. Если нужно будет собрать я использую коллектор.
4. Идея понятна, но тут еть несколько моментов: 1. Нода работает в одном процессе, логи пишутся в нем же при краше процесса мы херим логи, 2. В intel используются стримы не думаю что это сложно реализовать на их уровне и просто скормить обработчику собстевенный.
По пункту 3: два процесса могут писать в один файл, если оба открывают его с флагом «a». Тут только проблема будет в ротейте, создавать новые и удалять старые файлы должен Master процесс, а не Worker, и не несколько процессов сразу, ну и Worker должен открывать файл уже после того, как Master его создает. Вообще это удобно, представьте, что работает 16 или 32 воркера, это сколько же будет лог-файлов плодиться.
по поводу таймштампов в винстоне: github.com/flatiron/winston#console-transport
в settings просто указываем timestamp: true и дело в шляпе:
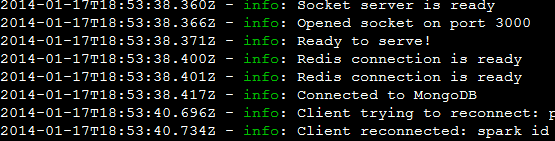
мне лично винстон очень нравится тем что я одновременно подключил 2 транспорта: в файл (в json формате) и в консоль (обычным текстом). хотя я много других и не пробовал.
в settings просто указываем timestamp: true и дело в шляпе:
мне лично винстон очень нравится тем что я одновременно подключил 2 транспорта: в файл (в json формате) и в консоль (обычным текстом). хотя я много других и не пробовал.
Соглашусь что для анализа производительности логи в таком виде трудно применимы :) Потому я и занимаюсь портированием Pinba на Node.js и надеюсь на днях написать об этом.
Sign up to leave a comment.
О логгировании в Node.js