Для небольших компаний нередко применение всего двух-четырех серверов с виртуализацией, два Ethernet свитча порой даже с возможностью стекирования и Multi-chassis EtherChannel плюс СХД младшей серии — это вполне стандартная конфигурация инфраструктуры среднего бизнеса.
Таким предприятиям очень важно максимально задействовать все доступные технологии, чтобы максимально утилизировать своё оборудование и в этой статье пойдёт речь как этого добиться.
В большинстве современных серверов на борту как правило присутствует минимум два 1Gb интерфейса под данные и один 100Mb для менеджмента.
На СХД младшей серии NetApp FAS2240/FAS2220 на борту каждого контроллера помимо прочего присутствует 4х 1Gb порта.
Т.е. вполне логично использовать схему, где два свича в стеке используют Multi-chassis EtherChannel агрегируя линки идущие от каждого контроллера в каждый свитч для получения как отказоустойчивости так и утилизации пропускной способности всех этих линков. Такая-себе архитектура по образу и подобию FlexPod Express, но без модно-дорогой фичи vPC как у свитчей компании Cisco серии Nexus, в таком случае вместо интерлинков просто будет использован стек свичей. Да и вообще сервера и свитчи в такой схеме могут быть любого производителя. А если совсем всё туго с бюджетом, то можно использовать прямое включение в сервера, так если у сервера 2 порта на борту, можно будет подключить 4-ре сервера, а когда нужно будет добавить 5-й сервер, тут уж прийдётся покупать свитчи.
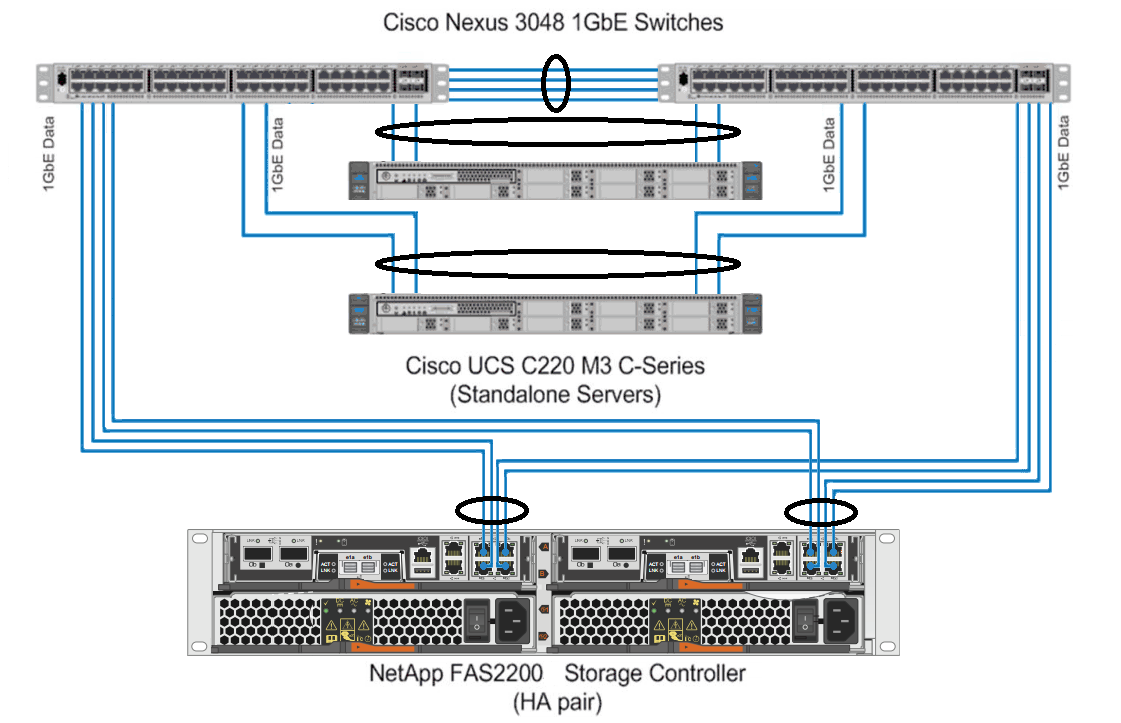
Схема подключения FlexPod Express.
Вот пример схемы, который будет описан в статье.
FAS 2240-4 HA — 2 контроллера по 4 1гбит линка
2 сервера с VMware ESXi, в каждом 4 выделенных сетевых порта по 1Гб для связи с хранилищем
2 гигабитных свитча в стеке с поддержкой Multi-chassis EtherChannel и LACP
Итак мы хотим задействовать всю доступную полосу пропускания и имеющиеся интерфейсы серверов и СХД. Т.е. сервер 1 работает преимущественно с ВМ расположенными на контроллере А, сервер 2 с ВМ на контроллере Б, у всех по 4 интерфейса, ВМ разбиты на 4 группы, все поделено равномерно и по честному.
Но балансировка нагрузки в сети «магическим образом» не может размазать эту нагрузку по всем линкам сама. Есть алгоритм который позволяет поочерёдно задействовать один из линков в агрегированном канале. Один из таких алгоритмов основывается на хеш суммах полученных из заголовков IP адресов источника и получателя, выбирая один линк. И этот нюанс играет важную роль в нашей схеме. Так как если хеш сумма для двух разных комбинаций IP источника и получателя будет совпадать, то для таких комбинаций будет задействован один и тот же физический линк. Другими словами важно понимать как работает алгоритм балансировки сетевого трафика и проследить, чтобы комбинации IP адресов были таковыми, чтобы получить отказоустойчивую схему инфраструктуры и задействовать все сетевые линки, опираясь при этом на лучшие практики от NetApp TR-3749, TR-3802 и TR-3839.
Как правило, 2-4 сервера не нагружают 1Gb линки по пропускной способности, использование всех линков одновременно положительно сказывается на скорости взаимодействия узлов сети и на пропускной способности в пиковых нагрузках.
Далее (для упрощения) описаны манипуляции с одним контроллером, одним сервером и протоколом NFS.
Нам необходимо чтобы:
Фрагменты настройки СХД NetApp FAS:
Обратите внимание, параметр "lacp" в строке "ifgrp create lacp vif1 -b ip e0d e0b e0c e0a", соответствует Dynamic Multi-Mode в документации и обязан совпадать с настройками на свиче. TR-3802
Также не забудьте про правильные настройки flowcontrol как со стороны хранилища, так и свича. Если хранилище «отправляет» (flowcontrol send) контроля потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). И наоборот: если никто не отправляет, то никто и не должен быть настроен на принием. Побробнее про flowcontrol.
Напомню что два контроллера работают в отказоустойчивой паре и если «умирает» один контроллер, то он «переедит» (в терминах NetApp FailOver) на второй контроллер и на физическом контроллере будут работать два логических. Со стороны хоста очень важно настроить таймаут на случай такого переезда 90 секунд. Обратите внимение на запись partner vif1-53, она означает, что в случае FailOver при переезде на второй контроллер, вместе с ним переедут и настройки этого виртуального интерфейса. По этому не забывайте указать эту запись, иначе контроллер то переедит, а данные достыпны по старым адресам будут не доступны. Общая логика назначения партнёра для интерфейса такова:
И не забываем сделать аналогичные настройки VIF и VLAN на втором контроллере, чтобы было «на что» переезжать. На стороне свичей на портах от первого контроллера разрешаем хождение тех VLAN'ов, которые есть у соседа, чтобы была связность на случай переезда.
Также обратите внимение, что СХД NetApp FAS использует нумерацию интерфейсов для балансировки в VIF не в алфавитном порядке, а в порядке добавления.
Например, если VIF создан такой командой «ifgrp create lacp vif1 -b ip e0d e0b e0c e0a», то e0d будет 0-ым интерфейсом, e0b — 1, e0c — 2, e0a — 3.
К VMware ESXi подключены следующие датасторы
После настройки даём нагрузку от тестовых VM и проверяем загруженность по портам со стороны контроллера СХД:
Итак видно, что по интерфейсу e0a (столбец Pkts Out) трафик практически не отправляется.
Идём на сторону свитча (свитч усредняет данные за период в несколько минут, потому утилизация лишь 80%, а не почти 100%) и видим, что порт Ethernet 1/11 практически не принимает фреймы.
Видна нагрузка на приём (Rx) для контроллера в столбце «Rx Util» и загрузка на передачу (Tx) для сервера в столбце «Tx Util». При этом видно, что 2 датастора делят один линк контроллера.
При запуске генерации линейной записи на всех 4 VM и соответственно 4 NFS шарах балансировка трафика от СХД не зависит, поэтому картина ожидаемая.
Получается, что СХД при агрегации каналов с балансировкой по IP использует не все доступные линии, как должно быть по теории, а только 3 из 4-х. При этом все остальные участники (свитч и ESXi) балансируют правильно по всем 4-м линиям. Трафик 2-х датасторов от СХД до свитча идет в одном линке, а от свитча до ESXi уже по двум.
Аналогичную картину наблюдаем при работе по протоколу iSCSI. Один из 4-х линков СХД на исходящую связь практически не загружен (5-10 пакетов за 10 секунд). На втором контроллере и другом сервере ситуация аналогичная.
Почему это происходит? Да потому что хеш суммы двух IP пар совпадают, заставляя алгоритм выбирать один и тот же линк. Другими словами нужно просто подобрать другие IP.
Можно просто перебирать варианты IP. В написании программы подбора IP адресов большая трудность заключается в том, что алгоритм использует побитовые сдвиги над знаковым 32битным целым и операции сложения над ними же (переполнения отбрасываются). Поскольку скриптовые языки нынче слабо ориентированы на фиксированную битность чисел, то добиться нормального расчета на python не удалось. Поэтому была написана на C маленькая программа расчета по всему диапазону, а потом использовать результаты в переборе.
Начиная с версии Data ONTAP 7.3.2 для выбора пути используется не просто операция XOR над двумя IP адресами источника и получателя ((source_address XOR destination_address) % number_of_links). А более сложный алгоритм с побитовыми сдвигами под названием SuperFastHash представляющий более динамический, более сбалансированный способ распределения нагрузки и обеспечивает лучшую балансировку для большого количества клиентов. Результат получается почти тот же, но каждая TCP сессия ассоциируется только с одним интерфейсом.
Кстати говоря для быстрого получения результата очень удобно воспользоваться онлайн компилятором.
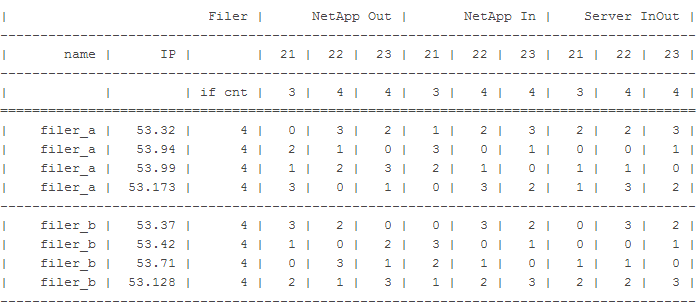
Ниже даны варианты выбора IP адресов СХД при условии наличия 3-х серверов (с IP адресами, заканчивающимися на 21, 22 и 23 и количеством интерфейсов к системе хранения 3, 4 и 4 соответственно).
Расчет делался для двух сетей ХХ.YY.52.ZZ/24 и ХХ.YY.53.ZZ/24. Подбирались IP адреса для СХД, удовлетворяющие вышеописанным условиям.
При обмене трафиком между сервером c IP ХХ.YY.52.22 и алиасом СХД ХХ.YY.52.35 трафик:
от СХД до свитча (столбец NetApp Out, 22) пойдет по интерфейсу с номером 2 по нумерации СХД от свитча до СХД (столбец NetApp In, 22) пойдет по интерфейсу с номером 1 по нумерации свитча от свитча до сервера и от сервера до свитча (столбец Server InOut, 22) пойдет по порту 1 в нумерации сервера и свитча соответственно (не факт, что считают они одинаково)
Видно, что для каждого сервера трафик с разными алиасами на одном контроллере будет идти по разным интерфейсам. Аналогично трафик с разных серверов на один IP СХД пойдет по разным интерфейсам.

При написании использовались материалы Александра Гордиенко, Агрегация каналов и балансировка трафика по IP со стороны NetApp.
Обновленная версия статьи и алгоритма на С++.
Замечания по ошибкам в тексте прошу направлять в ЛС.
Таким предприятиям очень важно максимально задействовать все доступные технологии, чтобы максимально утилизировать своё оборудование и в этой статье пойдёт речь как этого добиться.
В большинстве современных серверов на борту как правило присутствует минимум два 1Gb интерфейса под данные и один 100Mb для менеджмента.
На СХД младшей серии NetApp FAS2240/FAS2220 на борту каждого контроллера помимо прочего присутствует 4х 1Gb порта.
Т.е. вполне логично использовать схему, где два свича в стеке используют Multi-chassis EtherChannel агрегируя линки идущие от каждого контроллера в каждый свитч для получения как отказоустойчивости так и утилизации пропускной способности всех этих линков. Такая-себе архитектура по образу и подобию FlexPod Express, но без модно-дорогой фичи vPC как у свитчей компании Cisco серии Nexus, в таком случае вместо интерлинков просто будет использован стек свичей. Да и вообще сервера и свитчи в такой схеме могут быть любого производителя. А если совсем всё туго с бюджетом, то можно использовать прямое включение в сервера, так если у сервера 2 порта на борту, можно будет подключить 4-ре сервера, а когда нужно будет добавить 5-й сервер, тут уж прийдётся покупать свитчи.
Схема подключения FlexPod Express.
Вот пример схемы, который будет описан в статье.
FAS 2240-4 HA — 2 контроллера по 4 1гбит линка
2 сервера с VMware ESXi, в каждом 4 выделенных сетевых порта по 1Гб для связи с хранилищем
2 гигабитных свитча в стеке с поддержкой Multi-chassis EtherChannel и LACP
Итак мы хотим задействовать всю доступную полосу пропускания и имеющиеся интерфейсы серверов и СХД. Т.е. сервер 1 работает преимущественно с ВМ расположенными на контроллере А, сервер 2 с ВМ на контроллере Б, у всех по 4 интерфейса, ВМ разбиты на 4 группы, все поделено равномерно и по честному.
Теоретическая часть
Но балансировка нагрузки в сети «магическим образом» не может размазать эту нагрузку по всем линкам сама. Есть алгоритм который позволяет поочерёдно задействовать один из линков в агрегированном канале. Один из таких алгоритмов основывается на хеш суммах полученных из заголовков IP адресов источника и получателя, выбирая один линк. И этот нюанс играет важную роль в нашей схеме. Так как если хеш сумма для двух разных комбинаций IP источника и получателя будет совпадать, то для таких комбинаций будет задействован один и тот же физический линк. Другими словами важно понимать как работает алгоритм балансировки сетевого трафика и проследить, чтобы комбинации IP адресов были таковыми, чтобы получить отказоустойчивую схему инфраструктуры и задействовать все сетевые линки, опираясь при этом на лучшие практики от NetApp TR-3749, TR-3802 и TR-3839.
Как правило, 2-4 сервера не нагружают 1Gb линки по пропускной способности, использование всех линков одновременно положительно сказывается на скорости взаимодействия узлов сети и на пропускной способности в пиковых нагрузках.
Описание
Далее (для упрощения) описаны манипуляции с одним контроллером, одним сервером и протоколом NFS.
- 2 линка контроллера подключены в один свитч, 2 в другой
- на стороне свитча настроен multichassis LACP с балансировкой по IP
- на свитче для портов контроллера установлен Flowcontrol = on
- на контроллере для всех портов установлен Flowcontrol = send
- 4 линка по 1Гб на стороне контроллера объединены в один LACP с балансировкой по IP
- поверх VIF (ifgrp) создан VLAN и ему присвоен IP, дополнительно созданы 3 алиаса (адреса выданы последовательно)
- созданы 4 volume, в каждом volume создан qtree, volume экспортированы по NFS
- на сервере ESXi создан vSwitch с 4 интерфейсами с балансировкой по IP
- на этом vSwitch создан порт vmkernel в той же IP подсети и том же VLAN, в котором располагается основной IP и алиасы контроллера
- jumbo фреймы включены по всей цепочке (СХД, свитч, VLAN на свитче, vSwitch, порт vmkernel)
- в ESXi добавлены 4 NFS датастора, все с разных IP адресов (т.е. задействованы и основной IP и все алиасы контроллера)
- 4 VM vmware-io-analyzer.ova на разные NFS датасторы для проверки нагрузки на линки используя, к примеру, паттерн Max-throughput
Нам необходимо чтобы:
- один NFS экспорт был подключен ко всем хостам vmware ESXi по одинаковому IP адресу для того, чтобы vmware воспринимала его как один datastorage, а не как разные (для iSCSI такого требования нет, для каждого сервера можно указывать разные IP таргетов, IQN у них будет одинаковый)
- трафик (входящий и исходящий) от одного сервера к разным datastorage должен идти по разным линкам сервера и СХД
- трафик (входящий и исходящий) от разных серверов к одному datastorage должен идти по разным линкам СХД
Настройка
Фрагменты настройки СХД NetApp FAS:
Обратите внимание, параметр "lacp" в строке "ifgrp create lacp vif1 -b ip e0d e0b e0c e0a", соответствует Dynamic Multi-Mode в документации и обязан совпадать с настройками на свиче. TR-3802
Также не забудьте про правильные настройки flowcontrol как со стороны хранилища, так и свича. Если хранилище «отправляет» (flowcontrol send) контроля потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). И наоборот: если никто не отправляет, то никто и не должен быть настроен на принием. Побробнее про flowcontrol.
Пример настройки NetApp 7-Mode
san01a> rdfile /etc/rc
#Auto-generated by setup Thu may 22 13:26:59 GMT 2014
hostname san01a
ifgrp create lacp vif1 -b ip e0d e0b e0c e0a
vlan create vif1 53
ifconfig e0a flowcontrol send up
ifconfig e0b flowcontrol send up
ifconfig e0c flowcontrol send up
ifconfig e0d flowcontrol send up
ifconfig e0M `hostname`-e0M netmask 255.255.255.0 broadcast 10.10.10.255 flowcontrol full partner 10.10.40.11 mtusize 1500 trusted wins up
ifconfig e0P `hostname`-e0P netmask 255.255.252.0 broadcast 192.168.3.255 flowcontrol full up
ifconfig vif1-53 `hostname`-vif1-53 netmask 255.255.255.0 partner vif1-53 mtusize 9000 trusted -wins up
ifconfig vif1-53 alias 10.10.53.31 netmask 255.255.255.0 up
ifconfig vif1-53 alias 10.10.53.32 netmask 255.255.255.0 up
ifconfig vif1-53 alias 10.10.53.33 netmask 255.255.255.0 up
route add net default 10.10.10.3 1
routed on
options dns.domainname netapp.com
options dns.enable on
options nis.enable off
savecore
Отказоустойчивость для NFS
Напомню что два контроллера работают в отказоустойчивой паре и если «умирает» один контроллер, то он «переедит» (в терминах NetApp FailOver) на второй контроллер и на физическом контроллере будут работать два логических. Со стороны хоста очень важно настроить таймаут на случай такого переезда 90 секунд. Обратите внимение на запись partner vif1-53, она означает, что в случае FailOver при переезде на второй контроллер, вместе с ним переедут и настройки этого виртуального интерфейса. По этому не забывайте указать эту запись, иначе контроллер то переедит, а данные достыпны по старым адресам будут не доступны. Общая логика назначения партнёра для интерфейса такова:
- Если есть тим-интерфейс(ы) (VIF) с VLAN(ами), то настраиваем на каждом таком VLAN'е.
- Если есть VIF(ы), но уже без VLAN(ов), то настраиваем на каждом таком VIF интерфейсе.
- Если нет VIF, но есть VLAN(ы) на физическом интерфейсе, то настраиваем на каждом таком VLAN'е.
- Если нет ни VIF ни VLAN(ов) где бы то ни было, то на каждом физическом интерфейсе.
И не забываем сделать аналогичные настройки VIF и VLAN на втором контроллере, чтобы было «на что» переезжать. На стороне свичей на портах от первого контроллера разрешаем хождение тех VLAN'ов, которые есть у соседа, чтобы была связность на случай переезда.
Также обратите внимение, что СХД NetApp FAS использует нумерацию интерфейсов для балансировки в VIF не в алфавитном порядке, а в порядке добавления.
Например, если VIF создан такой командой «ifgrp create lacp vif1 -b ip e0d e0b e0c e0a», то e0d будет 0-ым интерфейсом, e0b — 1, e0c — 2, e0a — 3.
Пример настройки резолва, экспорта и Qtree для netApp 7-Mode
san01a> rdfile /etc/hosts
#Auto-generated by setup Thu may 22 13:26:59 GMT 2014
127.0.0.1 localhost localhost-stack
127.0.10.1 localhost-10 localhost-bsd
127.0.20.1 localhost-20 localhost-sk
10.10.40.10 san01a san01a-e0M
192.168.1.185 san01a san01a-e0P
10.10.53.30 san01a-vif1-53
san01a> exportfs
/vol/vol_filerA_nfsA -sec=sys,rw,nosuid
/vol/vol_filerA_nfsB -sec=sys,rw,nosuid
/vol/vol_filerA_nfsC -sec=sys,rw,nosuid
/vol/vol_filerA_nfsD -sec=sys,rw,nosuid
san01a> qtree status
Volume Tree Style Oplocks Status
-------- -------- ----- -------- ---------
rootvol unix enabled normal
vol_filerA_nfsA unix enabled normal
vol_filerA_nfsA qtree_filerA_nfsA unix enabled normal
vol_filerA_nfsB unix enabled normal
vol_filerA_nfsB qtree_filerA_nfsB unix enabled normal
vol_filerA_nfsC unix enabled normal
vol_filerA_nfsC qtree_filerA_nfsC unix enabled normal
vol_filerA_nfsD unix enabled normal
vol_filerA_nfsD qtree_filerA_nfsD unix enabled normal
К VMware ESXi подключены следующие датасторы
ds_filerA_nfsA 10.10.53.30:/vol/vol_filerA_nfsA/qtree_filerA_nfsA
ds_filerA_nfsB 10.10.53.31:/vol/vol_filerA_nfsB/qtree_filerA_nfsB
ds_filerA_nfsC 10.10.53.32:/vol/vol_filerA_nfsC/qtree_filerA_nfsC
ds_filerA_nfsD 10.10.53.33:/vol/vol_filerA_nfsD/qtree_filerA_nfsD
После настройки даём нагрузку от тестовых VM и проверяем загруженность по портам со стороны контроллера СХД:
Проверяем нагрузку на порты NetApp в 7-Mode
san01a> ifgrp stat vif1 10
Interface group(trunk) vif1
e0b e0a e0c e0d
Pkts In Pkts Out Pkts In Pkts Out Pkts In Pkts Out Pkts In Pkts Out
14225k 13673k 15542k 249k 13838k 11690k 15544k 7809k
46075 38052 90911 7 45882 37666 90812 37704
46953 37735 91581 4 46506 37613 91777 37625
46822 38016 91409 7 45498 37589 91670 37687
46906 38046 91514 6 45469 37591 91495 37588
46600 37737 91308 4 46554 37538 91514 37610
46792 37929 91371 7 45803 37532 91261 37508
46845 37831 91228 8 46307 37517 91450 37587
Итак видно, что по интерфейсу e0a (столбец Pkts Out) трафик практически не отправляется.
Подробный вывод по портам контроллера СХД
san01a> ifstat -a
-- interface e0a (3 hours, 30 minutes, 53 seconds) --
RECEIVE
Frames/second: 9147 | Bytes/second: 916k | Errors/minute: 0
Discards/minute: 0 | Total frames: 16347k | Total bytes: 73753m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 0
No buffers: 0 | Non-primary u/c: 0 | Tag drop: 0
Vlan tag drop: 0 | Vlan untag drop: 0 | Vlan forwards: 0
Vlan broadcasts: 0 | Vlan unicasts: 0 | CRC errors: 0
Runt frames: 0 | Fragment: 0 | Long frames: 0
Jabber: 0 | Alignment errors: 0 | Bus overruns: 0
Xon: 0 | Xoff: 0 | Jumbo: 8359k
TRANSMIT
Frames/second: 1 | Bytes/second: 87 | Errors/minute: 0
Discards/minute: 0 | Total frames: 249k | Total bytes: 7674m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 1006
Queue overflows: 0 | No buffers: 0 | Max collisions: 0
Single collision: 0 | Multi collisions: 0 | Late collisions: 0
Xon: 0 | Xoff: 0 | Jumbo: 239k
LINK_INFO
Current state: up | Up to downs: 2 | Speed: 1000m
Duplex: full | Flowcontrol: none
-- interface e0b (3 hours, 30 minutes, 53 seconds) --
RECEIVE
Frames/second: 4678 | Bytes/second: 467k | Errors/minute: 0
Discards/minute: 0 | Total frames: 14637k | Total bytes: 73533m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 0
No buffers: 0 | Non-primary u/c: 0 | Tag drop: 0
Vlan tag drop: 0 | Vlan untag drop: 0 | Vlan forwards: 0
Vlan broadcasts: 0 | Vlan unicasts: 0 | CRC errors: 0
Runt frames: 0 | Fragment: 0 | Long frames: 0
Jabber: 0 | Alignment errors: 0 | Bus overruns: 0
Xon: 0 | Xoff: 0 | Jumbo: 8352k
TRANSMIT
Frames/second: 3773 | Bytes/second: 123m | Errors/minute: 0
Discards/minute: 0 | Total frames: 14007k | Total bytes: 57209m
Total errors: 0 | Total discards: 1 | Multi/broadcast: 1531
Queue overflows: 1 | No buffers: 0 | Max collisions: 0
Single collision: 0 | Multi collisions: 0 | Late collisions: 0
Xon: 0 | Xoff: 0 | Jumbo: 2756k
LINK_INFO
Current state: up | Up to downs: 2 | Speed: 1000m
Duplex: full | Flowcontrol: none
-- interface e0c (3 hours, 30 minutes, 53 seconds) --
RECEIVE
Frames/second: 4630 | Bytes/second: 461k | Errors/minute: 0
Discards/minute: 0 | Total frames: 14243k | Total bytes: 69574m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 0
No buffers: 0 | Non-primary u/c: 0 | Tag drop: 0
Vlan tag drop: 0 | Vlan untag drop: 0 | Vlan forwards: 0
Vlan broadcasts: 0 | Vlan unicasts: 0 | CRC errors: 0
Runt frames: 0 | Fragment: 0 | Long frames: 0
Jabber: 0 | Alignment errors: 0 | Bus overruns: 0
Xon: 0 | Xoff: 0 | Jumbo: 7800k
TRANSMIT
Frames/second: 3756 | Bytes/second: 123m | Errors/minute: 0
Discards/minute: 0 | Total frames: 12022k | Total bytes: 189g
Total errors: 0 | Total discards: 0 | Multi/broadcast: 1003
Queue overflows: 0 | No buffers: 0 | Max collisions: 0
Single collision: 0 | Multi collisions: 0 | Late collisions: 0
Xon: 0 | Xoff: 0 | Jumbo: 6283k
LINK_INFO
Current state: up | Up to downs: 2 | Speed: 1000m
Duplex: full | Flowcontrol: none
-- interface e0d (3 hours, 30 minutes, 53 seconds) --
RECEIVE
Frames/second: 9127 | Bytes/second: 915k | Errors/minute: 0
Discards/minute: 0 | Total frames: 16349k | Total bytes: 73554m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 0
No buffers: 0 | Non-primary u/c: 0 | Tag drop: 0
Vlan tag drop: 0 | Vlan untag drop: 0 | Vlan forwards: 0
Vlan broadcasts: 0 | Vlan unicasts: 0 | CRC errors: 0
Runt frames: 0 | Fragment: 0 | Long frames: 0
Jabber: 0 | Alignment errors: 0 | Bus overruns: 0
Xon: 0 | Xoff: 0 | Jumbo: 8339k
TRANSMIT
Frames/second: 3748 | Bytes/second: 123m | Errors/minute: 0
Discards/minute: 0 | Total frames: 8140k | Total bytes: 62385m
Total errors: 0 | Total discards: 0 | Multi/broadcast: 1213
Queue overflows: 0 | No buffers: 0 | Max collisions: 0
Single collision: 0 | Multi collisions: 0 | Late collisions: 0
Xon: 0 | Xoff: 0 | Jumbo: 2413k
LINK_INFO
Current state: up | Up to downs: 2 | Speed: 1000m
Duplex: full | Flowcontrol: none
Свитч
Идём на сторону свитча (свитч усредняет данные за период в несколько минут, потому утилизация лишь 80%, а не почти 100%) и видим, что порт Ethernet 1/11 практически не принимает фреймы.
Пример настройки двух Cisco Catalyst 3850 в стеке через 1GBE порты
Обратите внимание на "mode active" (LACP) в настройке интерфейса строки channel-group 1 mode active. Mode active (LACP) соответствует Dynamic Multi-Mode у NetApp. Подробнее смотри TR-3802.
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
system mtu 9198
!
spanning-tree mode rapid-pvst
!
interface Port-channel1
description N1A-1G-e0a-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
!
interface Port-channel2
description N1B-1G-e0a-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
!
interface GigabitEthernet1/0/1
description NetApp-A-e0a
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 1 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet2/0/1
description NetApp-A-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 1 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet1/0/2
description NetApp-B-e0a
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 2 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet2/0/2
description NetApp-B-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 2 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
Пример настройки двух Cisco Catalyst 6509 в стеке через 1GBE порты
Обратите внимание на "mode active" (LACP) в настройке интерфейса строки channel-group 1 mode active. Mode active (LACP) соответствует Dynamic Multi-Mode у NetApp. Подробнее смотри TR-3802.
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
Пример для Cisco IOS Release 12.2(33)SXI and later releases
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
Пример для Cisco IOS Release 12.2(33)SXI and later releases
! For Cisco IOS Release 12.2(33)SXI and later releases
system mtu 9198
!
spanning-tree mode rapid-pvst
!
interface Port-channel1
description N1A-1G-e0a-e0b
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
end
!
interface Port-channel2
description N1B-1G-e0a-e0b
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
end
!
interface GigabitEthernet1/0/1
description NetApp-A-e0a
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 1 mode active
spanning-tree guard loop
spanning-tree portfast edge trunk
end
!
interface GigabitEthernet2/0/1
description NetApp-A-e0b
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 1 mode active
spanning-tree guard loop
spanning-tree portfast edge trunk
end
!
interface GigabitEthernet1/0/2
description NetApp-B-e0a
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 2 mode active
spanning-tree guard loop
spanning-tree portfast edge trunk
end
!
interface GigabitEthernet2/0/2
description NetApp-B-e0b
switchport
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 2 mode active
spanning-tree guard loop
spanning-tree portfast edge trunk
end
Пример настройки двух Cisco Catalyst 3750 в стеке через 1GBE порты
Обратите внимание на "mode active" (LACP) в настройке интерфейса строки channel-group 11 mode active. Mode active (LACP) соответствует Dynamic Multi-Mode у NetApp. Подробнее смотри TR-3802.
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
Также обратите внимание на "flowcontrol receive on", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «отправляет» (flowcontrol send) сообщения о контроле потока, то «с другой стороны» свич обязан быть настроен на «приём» управления потоком (flowcontrol receive on). Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP или проприетарный Rapid‐PVST+ и установить порты свитча подключённых к конечным узлам, в состояние spanning-tree portfast.
Системы NetApp FAS поддерживают CDP, его можно включить или оставить выключенным.
system mtu 9198
!
spanning-tree mode rapid-pvst
!
interface Port-channel11
description NetApp-A-e0a-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface Port-channel12
description NetApp-B-e0a-e0b
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet1/0/1
description NetApp-A-e0a
switchport trunk encapsulation dot1q
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 11 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet2/0/1
description NetApp-A-e0b
switchport trunk encapsulation dot1q
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 11 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet1/0/2
description NetApp-B-e0a
switchport trunk encapsulation dot1q
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 12 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
!
interface GigabitEthernet2/0/2
description NetApp-B-e0b
switchport trunk encapsulation dot1q
switchport trunk native vlan 1
switchport trunk allowed vlan 53
switchport mode trunk
flowcontrol receive on
cdp enable
channel-group 12 mode active
spanning-tree guard loop
spanning-tree portfast trunk feature
Пример настройки двух Cisco Small Business SG500 в стеке через 10GBE порты
Обратите внимание на "mode active" (LACP) в настройке интерфейса строки channel-group 1 mode active. Mode active (LACP) соответствует Dynamic Multi-Mode у NetApp. Подробнее смотри TR-3802.
Также обратите внимание на "flowcontrol off", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «не отправляет и не принимает» команды (flowcontrol off) контроля потока, то «с другой стороны» свич тоже должен «не принимать и не отправлять» их. Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP и установить порты свитча подключённых к конечным узлам в состояние spanning-tree portfast.
Также обратите внимание на "flowcontrol off", установка этого параметра может варьироваться и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «не отправляет и не принимает» команды (flowcontrol off) контроля потока, то «с другой стороны» свич тоже должен «не принимать и не отправлять» их. Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP и установить порты свитча подключённых к конечным узлам в состояние spanning-tree portfast.
interface Port-channel1
description N1A-10G-e1a-e1b
spanning-tree ddportfast
switchport trunk allowed vlan add 53
macro description host
!next command is internal.
macro auto smartport dynamic_type host
flowcontrol off
!
interface Port-channel2
description N1B-10G-e1a-e1b
spanning-tree ddportfast
switchport trunk allowed vlan add 53
macro description host
!next command is internal.
macro auto smartport dynamic_type host
flowcontrol off
!
port jumbo-frame
!
interface tengigabitethernet1/1/1
description NetApp-A-e1a
channel-group 1 mode active
flowcontrol off
!
interface tengigabitethernet2/1/1
description NetApp-A-e1b
channel-group 1 mode active
flowcontrol off
!
interface tengigabitethernet1/1/2
description NetApp-B-e1a
channel-group 2 mode active
flowcontrol off
!
interface tengigabitethernet2/1/2
description NetApp-B-e1b
channel-group 2 mode active
flowcontrol off
Пример настройки HP 6120XG в блейд шасси HP c7000 через 10GBE порты
Обратите внимание, если flowcontrol, в конфигурации, нигде не фигурирует, значит он в состоянии "flowcontrol auto", и если на портах хранилища, которые подключены к коммутатору, flowcontol выключен, то на свиче на соответствующих портах, он будет в состоянии «off». Установка параметра flowcontrol может варьироваться, и зависит от нескольких параметров: скорости порта и типа коммутатора. Если хранилище «не отправляет и не принимает» команды (flowcontrol off) контроля потока, то «с другой стороны» свич тоже должен «не принимать и не отправлять» их. Побробнее про flowcontrol.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP и установить порты свитча подключённых к конечным узлам в состояние spanning-tree portfast.
И не забываем про рекомендации по настройке Spanning-Tree, где желательно включить RSTP и установить порты свитча подключённых к конечным узлам в состояние spanning-tree portfast.
# HP 6120XG from HP c7000 10Gb/s
trunk 17-18 Trk1 LACP
trunk 19-20 Trk2 LACP
vlan 201
name "N1AB-10G-e1a-e1b-201"
ip address 192.168.201.222 255.255.255.0
tagged Trk1-Trk2
jumbo
exit
vlan 202
name "N1AB-10G-e1a-e1b-202"
tagged Trk1-Trk2
no ip address
jumbo
exit
spanning-tree force-version rstp-operation
Status and Counters - Port Utilization
Rx Tx
Port Mode | ------------------------- | -------------------------
| Kbits/sec Pkts/sec Util | Kbits/sec Pkts/sec Util
------- --------- + ---------- --------- ---- + ---------- ---------- ---
контроллер
1/11-Trk10 1000FDx| 5000 0 00.50 | 23088 7591 02.30
1/12-Trk10 1000FDx| 814232 12453 81.42 | 19576 3979 01.95
2/11-Trk10 1000FDx| 810920 12276 81.09 | 20528 3938 02.05
2/12-Trk10 1000FDx| 811232 12280 81.12 | 23024 7596 02.30
сервер
1/17-Trk22 1000FDx| 23000 7594 02.30 | 810848 12275 81.08
1/18-Trk22 1000FDx| 23072 7592 02.30 | 410320 6242 41.03
2/17-Trk22 1000FDx| 19504 3982 01.95 | 408952 6235 40.89
2/18-Trk22 1000FDx| 20544 3940 02.05 | 811184 12281 81.11
Видна нагрузка на приём (Rx) для контроллера в столбце «Rx Util» и загрузка на передачу (Tx) для сервера в столбце «Tx Util». При этом видно, что 2 датастора делят один линк контроллера.
При запуске генерации линейной записи на всех 4 VM и соответственно 4 NFS шарах балансировка трафика от СХД не зависит, поэтому картина ожидаемая.
Подбор IP
Получается, что СХД при агрегации каналов с балансировкой по IP использует не все доступные линии, как должно быть по теории, а только 3 из 4-х. При этом все остальные участники (свитч и ESXi) балансируют правильно по всем 4-м линиям. Трафик 2-х датасторов от СХД до свитча идет в одном линке, а от свитча до ESXi уже по двум.
Аналогичную картину наблюдаем при работе по протоколу iSCSI. Один из 4-х линков СХД на исходящую связь практически не загружен (5-10 пакетов за 10 секунд). На втором контроллере и другом сервере ситуация аналогичная.
Почему это происходит? Да потому что хеш суммы двух IP пар совпадают, заставляя алгоритм выбирать один и тот же линк. Другими словами нужно просто подобрать другие IP.
Можно просто перебирать варианты IP. В написании программы подбора IP адресов большая трудность заключается в том, что алгоритм использует побитовые сдвиги над знаковым 32битным целым и операции сложения над ними же (переполнения отбрасываются). Поскольку скриптовые языки нынче слабо ориентированы на фиксированную битность чисел, то добиться нормального расчета на python не удалось. Поэтому была написана на C маленькая программа расчета по всему диапазону, а потом использовать результаты в переборе.
Алгоритм SuperFastHash
Начиная с версии Data ONTAP 7.3.2 для выбора пути используется не просто операция XOR над двумя IP адресами источника и получателя ((source_address XOR destination_address) % number_of_links). А более сложный алгоритм с побитовыми сдвигами под названием SuperFastHash представляющий более динамический, более сбалансированный способ распределения нагрузки и обеспечивает лучшую балансировку для большого количества клиентов. Результат получается почти тот же, но каждая TCP сессия ассоциируется только с одним интерфейсом.
Coded by Alexander Gordienko
#include <stdio.h>
int debug = 0;
void f_shiftL(int *r, int step, int i, int offset) {
r[step] = r[i] << offset;
if (debug > 0) {
printf("\nStep %i Left Shift %i %i\n", step, i, offset);
printf("\t%i << %i\n", r[i], offset);
printf("\t%i\n", r[step]);
}
}
void f_shiftR(int *r, int step, int i, int offset) {
r[step] = r[i] >> offset;
if (debug > 0) {
printf("\nStep %i Right Shift %i %i\n", step, i, offset);
printf("\t%i\n", r[i]);
printf("\t%i\n", r[step]);
}
}
void f_xor(int *r, int step, int i, int j) {
r[step] = r[i] ^ r[j];
if (debug > 0) {
printf("\nStep %i XOR %i %i\n", step, i, j);
printf("\t%i\n", r[i]);
printf("\t%i\n", r[j]);
printf("\t%i\n", r[step]);
}
}
void f_sum(int *r, int step, int i, int j) {
r[step] = r[i] + r[j];
if (debug > 0) {
printf("\nStep %i ADD %i %i\n", step, i, j);
printf("\t%i\n", r[i]);
printf("\t%i\n", r[j]);
printf("\t%i\n", r[step]);
}
}
int balance_ip_netapp (int net, int src, int dst, int link_cnt) {
int res[30];
res[0] = net*256 + src;
res[1] = net*256 + dst;
//printf ("a = %i.%i (%i)\n", net, src, res[0]);
//printf ("b = %i.%i (%i)\n", net, dst, res[1]);
f_shiftL(res, 2, 1,11);
f_xor (res, 3, 0, 2);
f_shiftL(res, 4, 0,16);
f_xor (res, 5, 3, 4);
f_shiftR(res, 6, 5,11);
f_sum (res, 7, 5, 6);
f_shiftL(res,15, 7, 3);
f_xor (res,16, 7,15);
f_shiftR(res,17,16, 5);
f_sum (res,18,16,17);
f_shiftL(res,19,18, 4);
f_xor (res,20,18,19);
f_shiftR(res,21,20,17);
f_sum (res,22,20,21);
f_shiftL(res,23,22,25);
f_xor (res,24,22,23);
f_shiftR(res,25,24, 6);
f_sum (res,26,24,25);
res[27] = res[26] % link_cnt;
if (res[27] < 0) {
res[27] = res[27] + link_cnt;
}
printf ("%i.%i -> %i, %i\n", net, src, dst, res[27]);
return 0;
}
int main() {
int src, dst, interface;
//Задаём количество сетевых интерфейсов
interface = 4;
printf ("IP Octet3.IP Octet4 Source -> IP Octet4 Destination, Interface\n");
//Начинаем перебор destination для четверного октета IP адреса (в примере с 21 до 23)
for (src=21; src<=23; src++) {
//Начинаем перебор source для четверного октета IP адреса (в примере с 30 до 250)
for (dst=30; dst<=250; dst++) {
//Задаём третий октет IP адреса (в примере 52 и 53)
balance_ip_netapp(52, dst, src, interface );
balance_ip_netapp(53, dst, src, interface );
}
}
}
Кстати говоря для быстрого получения результата очень удобно воспользоваться онлайн компилятором.
Ниже даны варианты выбора IP адресов СХД при условии наличия 3-х серверов (с IP адресами, заканчивающимися на 21, 22 и 23 и количеством интерфейсов к системе хранения 3, 4 и 4 соответственно).
Расчет делался для двух сетей ХХ.YY.52.ZZ/24 и ХХ.YY.53.ZZ/24. Подбирались IP адреса для СХД, удовлетворяющие вышеописанным условиям.
Как пользоваться табличкой
При обмене трафиком между сервером c IP ХХ.YY.52.22 и алиасом СХД ХХ.YY.52.35 трафик:
от СХД до свитча (столбец NetApp Out, 22) пойдет по интерфейсу с номером 2 по нумерации СХД от свитча до СХД (столбец NetApp In, 22) пойдет по интерфейсу с номером 1 по нумерации свитча от свитча до сервера и от сервера до свитча (столбец Server InOut, 22) пойдет по порту 1 в нумерации сервера и свитча соответственно (не факт, что считают они одинаково)
Видно, что для каждого сервера трафик с разными алиасами на одном контроллере будет идти по разным интерфейсам. Аналогично трафик с разных серверов на один IP СХД пойдет по разным интерфейсам.
При написании использовались материалы Александра Гордиенко, Агрегация каналов и балансировка трафика по IP со стороны NetApp.
Обновленная версия статьи и алгоритма на С++.
Замечания по ошибкам в тексте прошу направлять в ЛС.
