Для синхронизации файлов проекта, ведения истории мы используем системы контроля версий, например, Git. Однако, когда у меня встал вопрос о контроле версий структуры базы MySQL — удовлетворяющего решения найти не удалось.
Замечу, во многих фреймворках и ORM существуют необходимые механизмы «из коробки» — миграции, версионность и т.д. А вот для нативной работы с MySQL — приходится все делать ручками. И пришла идея попытаться создать автоматическую систему для отслеживания изменений.
Хотелось менять структуру базы данных на development-сервере, автоматически обновлять ее на production-сервере, а также видеть историю всех изменений в Git, так как он уже использовался для контроля кода. И чтобы все бесплатно и просто!
Для этого необходимо получать информацию о всех запросах на изменение (CREATE, ALTER, DROP).
MySQL поддерживает 3 способа ведения логов — это логи ошибок (error log), логи всех запросов (general log) и логи медленных запросов (slow log).
Первый вариант я пока не использовала, но есть идеи (подробности ниже). Теперь про два остальных варианта.
Логи можно записывать либо в таблицы mysql, либо в файлы. Формат файлов логов достаточно неудобный и я решила использовать таблицы.
Внимание, так как речь идет о ВСЕХ mysql-логах данное решение стоит использовать только на dev-сервере без нагрузки на MySQL!
Важным моментом является определение базы данных, к которой идет запрос, так как в SQL-тексте самого запроса — этой информации может не быть.
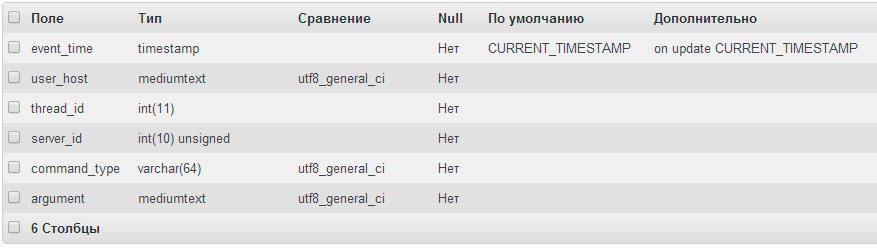
Оказалось, что general log пишет только номер потока сервера, и чтобы определить базу данных, пришлось бы искать запись для этого потока с указанием используемой БД. К тому же логи содержат информацию о подключении и отключении к серверу.
Структура mysql.general_log
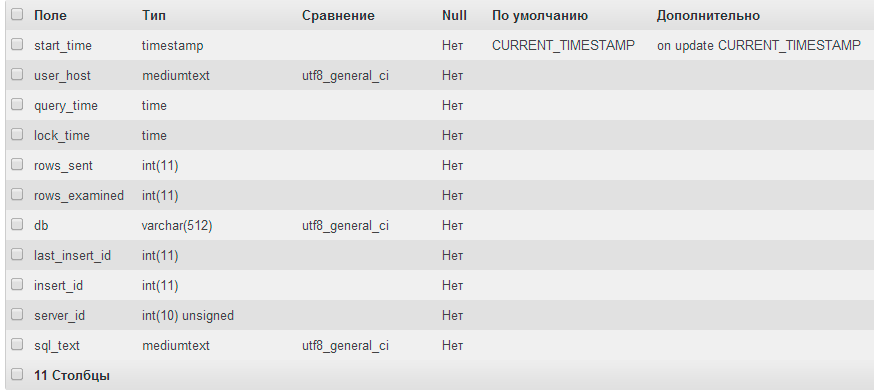
А вот в slow_log как раз таки нашлось все что нужно: во-первых, логи содержат только информацию о запросах, во-вторых, запоминается название базы данных, в контексте которой идут запросы.
Структура mysql.slow_log
Настроить slow log для записи всех запросов очень просто в my.cnf
log_slow_admin_statements нужно для записи ALTER запросов.
Итак, нам нужно постоянно забирать все запросы, выбирать из них запросы на изменение структуры БД и очищать все остальные.
Таблица mysql.slow_log не содержит ключевого поля, а также ее нельзя заблокировать (а значит частично удалять записи). Поэтому создадим таблицу, которая будет нас устраивать.
Структура change_structure_log

Для ротации логов небольшая процедура:
А ее можно добавить в планировщик MySQL:
Итак, у нас есть таблица со всеми запросами на изменение структуры. Теперь напишем небольшой скрипт для ее обработки. Я не буду использовать какой-то конкретный язык (лично я пишу на PHP, но из-за большого количества зависимостей в коде смысла выкладывать код нет).
Итак:
1. Проходим в цикле все записи таблицы change_structure_log.
2. Для sql_text регуляркой вытаскиваем имя БД, если оно есть, например
3. Если в запросе не указано название db — используем его из поля db.
4. Записываем в папку проекта с Git все записи соответствующих БД. Например, 20140508150500.sql.log. Для запросов без БД в начале пишем use $DB;
5. Удаляем все обработанные записи.
Итак, у нас в папке проекта появились новые файлы с запросами изменения БД, теперь мы можем закоммитить их в обычном режиме в нашем Git-клиенте.
Далее на production-сервере пишем скрипт, отслеживающий появление новых файлов и исполняем их в mysql. Так, при обновлении git-репозитария на production-сервере вместе с кодом, мы изменяем базу данных до состояния на dev-сервере.
Upd. Также (по подсказке DsideSPb) можно использовать хук для Git post-checkout, что позволит сделать итерацию по обновлению непрерывной и без внешних слушателей.
Сразу скажу, что данное решение достаточно примитивно и не поддерживает многих функций Git. Однако, основываясь на нем, мы можем делать и более крутые вещи: по изменению конкретных таблиц — например, автоматически изменять файлы нашей ORM.
Или автоматически создавать схемы Yaml — пользуясь любым MySQL-клиентом без дополнительных плагинов к нему.
Также возможно, например, отслеживать изменения данных в конкретных таблицах без изменения самой структуры БД (триггеров и т.д.), что может быть полезно для различных CMS.
P.S. Если мы хотим также узнавать о медленных запросах — мы можем интегрировать это в нашу систему, для этого нужно убрать фильтр из процедуры и в нашем скрипте делать запрос на медленные запросы и сохранять их.
Замечу, во многих фреймворках и ORM существуют необходимые механизмы «из коробки» — миграции, версионность и т.д. А вот для нативной работы с MySQL — приходится все делать ручками. И пришла идея попытаться создать автоматическую систему для отслеживания изменений.
Задача
Хотелось менять структуру базы данных на development-сервере, автоматически обновлять ее на production-сервере, а также видеть историю всех изменений в Git, так как он уже использовался для контроля кода. И чтобы все бесплатно и просто!
Для этого необходимо получать информацию о всех запросах на изменение (CREATE, ALTER, DROP).
Решение, начало
MySQL поддерживает 3 способа ведения логов — это логи ошибок (error log), логи всех запросов (general log) и логи медленных запросов (slow log).
Первый вариант я пока не использовала, но есть идеи (подробности ниже). Теперь про два остальных варианта.
Логи можно записывать либо в таблицы mysql, либо в файлы. Формат файлов логов достаточно неудобный и я решила использовать таблицы.
Внимание, так как речь идет о ВСЕХ mysql-логах данное решение стоит использовать только на dev-сервере без нагрузки на MySQL!
Важным моментом является определение базы данных, к которой идет запрос, так как в SQL-тексте самого запроса — этой информации может не быть.
CREATE TABLE /*DB_NAME.*/TABLE_NAME
Оказалось, что general log пишет только номер потока сервера, и чтобы определить базу данных, пришлось бы искать запись для этого потока с указанием используемой БД. К тому же логи содержат информацию о подключении и отключении к серверу.
Структура mysql.general_log
А вот в slow_log как раз таки нашлось все что нужно: во-первых, логи содержат только информацию о запросах, во-вторых, запоминается название базы данных, в контексте которой идут запросы.
Структура mysql.slow_log
Настроить slow log для записи всех запросов очень просто в my.cnf
log-output=TABLEslow_query_log = 1long_query_time = 0log_slow_admin_statements = 1log_slow_admin_statements нужно для записи ALTER запросов.
Обработка логов
Итак, нам нужно постоянно забирать все запросы, выбирать из них запросы на изменение структуры БД и очищать все остальные.
Таблица mysql.slow_log не содержит ключевого поля, а также ее нельзя заблокировать (а значит частично удалять записи). Поэтому создадим таблицу, которая будет нас устраивать.
Структура change_structure_log
Для ротации логов небольшая процедура:
USE mysql;
DELIMITER $$
CREATE PROCEDURE `change_structure_log_rotate`()
BEGIN
-- Definition start
drop table if exists slow_log_copy;
CREATE TABLE slow_log_copy LIKE slow_log;
RENAME TABLE slow_log TO slow_log_old, slow_log_copy TO slow_log;
insert into change_structure_log (start_time,query_time,sql_text, db) select start_time, query_time, sql_text,db from slow_log_old where sql_text like "ALTER%" OR sql_text like "CREATE%" OR sql_text like "DROP%";
drop table slow_log_old;
-- Definition end
END
$$
А ее можно добавить в планировщик MySQL:
CREATE EVENT `event_archive_mailqueue`
ON SCHEDULE EVERY 5 MINUTE STARTS CURRENT_TIMESTAMP
ON COMPLETION NOT PRESERVE
ENABLE
COMMENT '' DO
call change_structure_log_rotate();
Итак, у нас есть таблица со всеми запросами на изменение структуры. Теперь напишем небольшой скрипт для ее обработки. Я не буду использовать какой-то конкретный язык (лично я пишу на PHP, но из-за большого количества зависимостей в коде смысла выкладывать код нет).
Итак:
1. Проходим в цикле все записи таблицы change_structure_log.
2. Для sql_text регуляркой вытаскиваем имя БД, если оно есть, например
^ALTER\s+TABLE\s+(?:(?:ONLINE|OFFLINE)\s+)?(?:(?:IGNORE)\s+)?(?:([^\s\.]+)\.\s*)?([^\s\.]+)3. Если в запросе не указано название db — используем его из поля db.
4. Записываем в папку проекта с Git все записи соответствующих БД. Например, 20140508150500.sql.log. Для запросов без БД в начале пишем use $DB;
5. Удаляем все обработанные записи.
Итак, у нас в папке проекта появились новые файлы с запросами изменения БД, теперь мы можем закоммитить их в обычном режиме в нашем Git-клиенте.
Далее на production-сервере пишем скрипт, отслеживающий появление новых файлов и исполняем их в mysql. Так, при обновлении git-репозитария на production-сервере вместе с кодом, мы изменяем базу данных до состояния на dev-сервере.
Upd. Также (по подсказке DsideSPb) можно использовать хук для Git post-checkout, что позволит сделать итерацию по обновлению непрерывной и без внешних слушателей.
Сразу скажу, что данное решение достаточно примитивно и не поддерживает многих функций Git. Однако, основываясь на нем, мы можем делать и более крутые вещи: по изменению конкретных таблиц — например, автоматически изменять файлы нашей ORM.
Или автоматически создавать схемы Yaml — пользуясь любым MySQL-клиентом без дополнительных плагинов к нему.
Также возможно, например, отслеживать изменения данных в конкретных таблицах без изменения самой структуры БД (триггеров и т.д.), что может быть полезно для различных CMS.
P.S. Если мы хотим также узнавать о медленных запросах — мы можем интегрировать это в нашу систему, для этого нужно убрать фильтр из процедуры и в нашем скрипте делать запрос на медленные запросы и сохранять их.
