Наверняка каждый, имеющий дело с электроникой и ПЛИС, знаком с сайтом opencores.org, где собрано множество полезных (и не очень) решений для электроники — десятки, может быть и сотни, реализаций процессоров и периферии — как оригинальных реализаций уже существующих устройств, так и новых разработок. В этой статье пойдёт речь о 32-битном микропроцессоре с оригинальной системой команд, созданном на основе платы «Марсоход2».
Наша команда в течение 10 лет занимается микроядром L4 и в какой-то момент пришло понимание, что само микроядро можно реализовать в виде блока процессора. Причём, если полноценное микроядро реализовать в «железе» весьма трудно, то можно хотя бы помочь программной части, переложив часть функций на железо. Сперва мы решили пойти по лёгкому и оптимальному пути — изучить существующие решения, выбрать подходящее идоработь напильником добавить возможности, полезные для микроядра. Работа заняла около месяца и былы изучены почти что все решения, найденные на opencores. Взятие за основу готового решения открывало неплохие возможости, в виде готовых компиляторов и различных библиотек. В какой-то момент нам перестали нравиться существующие решения — что-то оказалось сложным, что-то неоптимальным, что-то просто недоделанным, что-то, чего уж скрывать, имело не очень подходящую лицензию и условия использования. Набравшись смелости и скрипя зубами мы начали авантюру, решив разрабатывать процессор с самого начала.
С чего начинается микропроцессор? Спросите у системного программиста, и он ответит вам что это система команд. Несмотря на тотальную моду на RISC архитектуру, мы решили не привязывать длину инструкций к размеру машинного слова. Поэтому мы провели несколько экспериментов. Как ни странно, но очень удобным инструментом для проектирования системы команд оказался… Microsoft Excel. Прежде всего мы выделили несколько столбцов, использовав их для нумерации инструкций в трёх системах исчисления — десятичной, шестнадцетричной и двоичной. В итоге получилось 256 строк, по числу состояний, которые можно описать одним байтом. Затем мы попытались логически сгруппировать инструкции таким образом, чтобы схема их декодирования была максимально проста. Первый блок инструкций заняли однобайтовые инструкции — префиксы, модификаторы и простые инструкции. Следующий блок инструкций выглядит так:
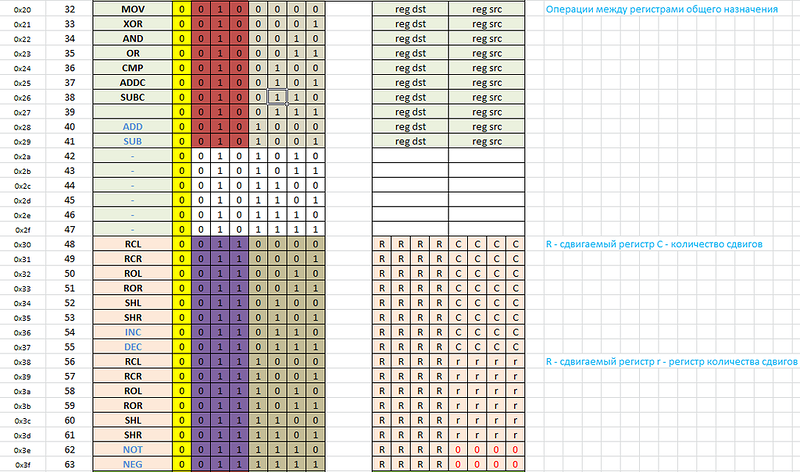
На следующем этапе пришлось определиться с количеством и типами регистров. Сколько регистров, по-вашему, будет оптимально для большинства задач? Ответы на этот вопрос могут сильно отличаться в зависимости от личности отвечающего — кому-то и 32-х нехватает, как есть и приверженцы безрегистровой архитектуры. Мы решили остановиться на 16-ти регистрах общего назначения. Это количество вполне комфортно для программирования на ассемблере, вполне удачно ложится на нашу архитектуру и несложно реализуются в HDL.
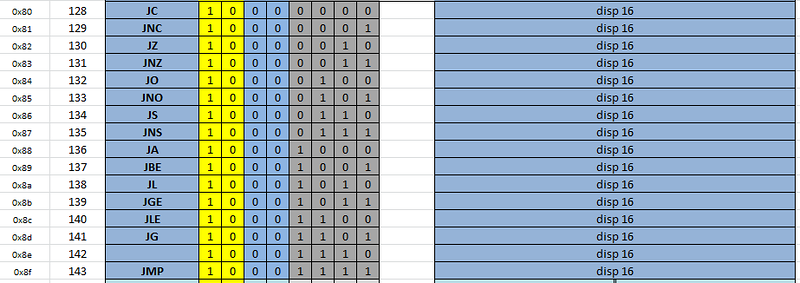
Определившись с регистрами, мы решили сделать полностью позиционно независимую систему команд — в архитектуре нет ни одной команды перехода по абсолютному адресу — все переходы осуществляются относительно текущей команды. Мы просто помешаны на компактности, поэтому все команды переходов имеют три формы — знаковые смещения размерностью 1, 2 и 3 байта. Например, ниже показаны переходы с 16-битным смещением:
Наконец, мы отказались от понятия аппаратного стека, в пользу организации стека «по соглашению». Для этого был введён специальный префикс NOTCH и следующая схема — если перед инструкцией условного или безусловного перехода стоит этот префикс, то в регистр R15 помещается адрес следующей инструкции, т.е. адрес возврата. Соответственно, инструкция RETURN выполняет переход по содержимому регистра R15. Таким образом при вложенных вызовах подпрограмм, забота о сохранении адреса возврата ложится на программиста или компилятор. На первый взгляд это кажется не очень удобным, оптимальным и привычным, но если задуматься, то получается несколько преимуществ — во первых, можно сэкономить несколько тактов не сохраняя этот регистр во внешней памяти в терминальных подпрограммах (т.е.подпрограммах, которые не вызывают других подпрограмм), во вторых, префикс NOTCH можно поставить перед инструкцией условного перехода, тем самым реализовав условные вызовы функций — пусть и небольшая, но тоже экономия. Что касается сложности программрования на ассемблере, то их прячут макрокоманды, являющиеся ассемблерными мнемониками более высокого уровня.
Позиционная независимость кода вносит ещё одну особенность — обращение к константным данным. Поскольку код может быть расположен по произвольному адресу, то и константные данные могут быть расположены произвольно вместе с кодом. Решение оказалось весьма простым — использование того же самого префикса NOTCH при загрузке в регистр константы, использует константу как смещение относительно исполняемой инструкции — таким образом решается проблема адресации данных в позиционно независимом коде.
После проектирования системы команд, которое в целом заняло около года, мы вооружились средой Qauartus и Icarus Verilog и… поняли что поспешили. Реализовать систему команд на языке Verilog оказалось чертовски сложным. Знающие люди посоветовали обкатать решения на программной модели, написав декодер и другие функциональные устройства на обычном Си. После реализации эмулятора несуществующего процессора и прогона на нём тестовых программ — дела пошли лучше. Ещё полгода понадобились на реализацию процессора на Верилоге. Тут следует сказать, что для новичка программирование ПЛИС может оказаться невероятно сложным, а многолетний опыт программирования на языках высого уровня может даже усложнить задачу. В таком случае на помощь приходят средства моделирования. На первом этапе чрезвычайно полезным оказался Icarus Verilog — бесплатный инструмент для моделирования схем, в комплекте с которым идёт GTKWave — программа для отображения сигналов. Используя эти инструменты можно увидеть что происходит с устройством в каждый момент времени. На каком-то этапе возможностей Icarus Verilog стало мало и мы воспользовались симулятором ModelSim компании MentorGraphis — это очень мощный коммерческий инструмент, урезанную версию которого можно бесплатно установить совместно со средой Altera Quartus.
О процессе отладки можно рассказывать долго. И вот в какой-то момент, когда ресурсы ПЛИС были заняты на целую треть, неожиданно появилось понимание, что полученный процессор уже можно использовать для каких-то проектов.

Для демонстрации возможностей процессора мы написали простейшую микропрограмму, которая при старте выводит следующее меню на экране удалённого терминала:
Если нажать клавишу 1 и если ваш терминал поддерживает передачу файлов по протоколу X-modem, то в устройство можно загрузить файл размером до 4 Кб. Это может быть текст или ANSI-картинка — в этом случае нажатие на клавишу 5 выведет текст или картинку на экран. Но стоило бы ради этого писать статью? Конечно нет, поэтому при нажатии в терминале на клавишу 2 управление передаётся коду, загруженному с помощью первого пункта меню. Если передать управление загруженному тексту или ansi-картинке, то через несколько шагов процессор наткнётся на несуществующую (ещё неопределённую команду) или обратится к несуществующей памяти. При этом произойдёт переход процессора в пошаговый режим — каждый код, принятый с терминала, вызовет выполнение одной инструкции процессора с выводом состояния шин на удалённый терминал.

Самое время нажать клавишу «Сброс». Мы назвали «сбросом» левую кнопку на плате Марсоход2.
Чтобы заставить устройство сделать что-нибудь осмысленное, вам понадобится Макро Ассемблер. В этот архив, помимо самого ассемблера и нескольких примеров, мы поместили исходный код микрокода процессора. Ниже показан пример простой пользовательской программы, которую можно с помощью ассемблера перевести в бинарный файл и загрузить в процессор.
Эта программа в цикле, до нажатия на любую клавишу в терминале, выводит в удалённый терминал информацию о количестве секунд с момента старта или сброса устройства. Чтобы проверить её в деле, понадобится сгенерированный файл usr_demo2.bin.
Небольшое пояснение к программе. Подпрограмма _get_sysclock возвращает количество импульсов кварцевого генератора с момента включения или сброса устройства. Пример дампа подпрограммы:
При выходе из подпрограммы _get_sysclock регистр R0 содержит младшие 32 бита, а регистр R1 старшие 32-бита результата.
Константа 0x05F5E100 это число импульсов тактового генератора за одну секунду.
Скачать свежую версию прошивки для платы Марсоход2 можно по этой ссылке.
Если вы не слышите новостей от нашего проекта, то знайте — мы работаем над переносом микроядра L4 в ПЛИС.
Спасибо за внимание.
Наша команда в течение 10 лет занимается микроядром L4 и в какой-то момент пришло понимание, что само микроядро можно реализовать в виде блока процессора. Причём, если полноценное микроядро реализовать в «железе» весьма трудно, то можно хотя бы помочь программной части, переложив часть функций на железо. Сперва мы решили пойти по лёгкому и оптимальному пути — изучить существующие решения, выбрать подходящее и
С чего начинается микропроцессор? Спросите у системного программиста, и он ответит вам что это система команд. Несмотря на тотальную моду на RISC архитектуру, мы решили не привязывать длину инструкций к размеру машинного слова. Поэтому мы провели несколько экспериментов. Как ни странно, но очень удобным инструментом для проектирования системы команд оказался… Microsoft Excel. Прежде всего мы выделили несколько столбцов, использовав их для нумерации инструкций в трёх системах исчисления — десятичной, шестнадцетричной и двоичной. В итоге получилось 256 строк, по числу состояний, которые можно описать одним байтом. Затем мы попытались логически сгруппировать инструкции таким образом, чтобы схема их декодирования была максимально проста. Первый блок инструкций заняли однобайтовые инструкции — префиксы, модификаторы и простые инструкции. Следующий блок инструкций выглядит так:
На следующем этапе пришлось определиться с количеством и типами регистров. Сколько регистров, по-вашему, будет оптимально для большинства задач? Ответы на этот вопрос могут сильно отличаться в зависимости от личности отвечающего — кому-то и 32-х нехватает, как есть и приверженцы безрегистровой архитектуры. Мы решили остановиться на 16-ти регистрах общего назначения. Это количество вполне комфортно для программирования на ассемблере, вполне удачно ложится на нашу архитектуру и несложно реализуются в HDL.
Определившись с регистрами, мы решили сделать полностью позиционно независимую систему команд — в архитектуре нет ни одной команды перехода по абсолютному адресу — все переходы осуществляются относительно текущей команды. Мы просто помешаны на компактности, поэтому все команды переходов имеют три формы — знаковые смещения размерностью 1, 2 и 3 байта. Например, ниже показаны переходы с 16-битным смещением:
Наконец, мы отказались от понятия аппаратного стека, в пользу организации стека «по соглашению». Для этого был введён специальный префикс NOTCH и следующая схема — если перед инструкцией условного или безусловного перехода стоит этот префикс, то в регистр R15 помещается адрес следующей инструкции, т.е. адрес возврата. Соответственно, инструкция RETURN выполняет переход по содержимому регистра R15. Таким образом при вложенных вызовах подпрограмм, забота о сохранении адреса возврата ложится на программиста или компилятор. На первый взгляд это кажется не очень удобным, оптимальным и привычным, но если задуматься, то получается несколько преимуществ — во первых, можно сэкономить несколько тактов не сохраняя этот регистр во внешней памяти в терминальных подпрограммах (т.е.подпрограммах, которые не вызывают других подпрограмм), во вторых, префикс NOTCH можно поставить перед инструкцией условного перехода, тем самым реализовав условные вызовы функций — пусть и небольшая, но тоже экономия. Что касается сложности программрования на ассемблере, то их прячут макрокоманды, являющиеся ассемблерными мнемониками более высокого уровня.
Позиционная независимость кода вносит ещё одну особенность — обращение к константным данным. Поскольку код может быть расположен по произвольному адресу, то и константные данные могут быть расположены произвольно вместе с кодом. Решение оказалось весьма простым — использование того же самого префикса NOTCH при загрузке в регистр константы, использует константу как смещение относительно исполняемой инструкции — таким образом решается проблема адресации данных в позиционно независимом коде.
После проектирования системы команд, которое в целом заняло около года, мы вооружились средой Qauartus и Icarus Verilog и… поняли что поспешили. Реализовать систему команд на языке Verilog оказалось чертовски сложным. Знающие люди посоветовали обкатать решения на программной модели, написав декодер и другие функциональные устройства на обычном Си. После реализации эмулятора несуществующего процессора и прогона на нём тестовых программ — дела пошли лучше. Ещё полгода понадобились на реализацию процессора на Верилоге. Тут следует сказать, что для новичка программирование ПЛИС может оказаться невероятно сложным, а многолетний опыт программирования на языках высого уровня может даже усложнить задачу. В таком случае на помощь приходят средства моделирования. На первом этапе чрезвычайно полезным оказался Icarus Verilog — бесплатный инструмент для моделирования схем, в комплекте с которым идёт GTKWave — программа для отображения сигналов. Используя эти инструменты можно увидеть что происходит с устройством в каждый момент времени. На каком-то этапе возможностей Icarus Verilog стало мало и мы воспользовались симулятором ModelSim компании MentorGraphis — это очень мощный коммерческий инструмент, урезанную версию которого можно бесплатно установить совместно со средой Altera Quartus.
О процессе отладки можно рассказывать долго. И вот в какой-то момент, когда ресурсы ПЛИС были заняты на целую треть, неожиданно появилось понимание, что полученный процессор уже можно использовать для каких-то проектов.
Для демонстрации возможностей процессора мы написали простейшую микропрограмму, которая при старте выводит следующее меню на экране удалённого терминала:
┌────────────────────────> Welcome to Everest core <───────────────────────────┐ │ 1 - Load binary file via X-modem protocol │ │ 2 - Run previously loaded binary file │ │ 3 - Show RAM (0x100000-0x100140) │ │ 4 - Test of message registers │ │ 5 - Show previously loaded ANSI picture │ │ 6 - Show built-in ANSI pic #1 │ │ 7 - Show built-in ANSI pic #2 │ └──────────────────────────────────────────────────────────────────────────────┘
Если нажать клавишу 1 и если ваш терминал поддерживает передачу файлов по протоколу X-modem, то в устройство можно загрузить файл размером до 4 Кб. Это может быть текст или ANSI-картинка — в этом случае нажатие на клавишу 5 выведет текст или картинку на экран. Но стоило бы ради этого писать статью? Конечно нет, поэтому при нажатии в терминале на клавишу 2 управление передаётся коду, загруженному с помощью первого пункта меню. Если передать управление загруженному тексту или ansi-картинке, то через несколько шагов процессор наткнётся на несуществующую (ещё неопределённую команду) или обратится к несуществующей памяти. При этом произойдёт переход процессора в пошаговый режим — каждый код, принятый с терминала, вызовет выполнение одной инструкции процессора с выводом состояния шин на удалённый терминал.
Самое время нажать клавишу «Сброс». Мы назвали «сбросом» левую кнопку на плате Марсоход2.
Чтобы заставить устройство сделать что-нибудь осмысленное, вам понадобится Макро Ассемблер. В этот архив, помимо самого ассемблера и нескольких примеров, мы поместили исходный код микрокода процессора. Ниже показан пример простой пользовательской программы, которую можно с помощью ассемблера перевести в бинарный файл и загрузить в процессор.
function user_main
load r14, 0x2000
push r15
loop:
call _get_sysclock
load r2, 0x05F5E100
call _div64
call _print_dec
lea r1, $shw_str
call _puts
call _uart_status
rcr r0, 2 ; Бит RCV_RDY в перенос
jc done ; Выход из цикла если была нажата клавиша
load r0, 0x01000000
call _delay
jmp loop
done:
pop r15
return
end
include tty.asm
include delay.asm
include mul.asm
include div.asm
include print_dec.asm
include sysclock.asm
$shw_str db ' seconds since boot',13,10,0
Эта программа в цикле, до нажатия на любую клавишу в терминале, выводит в удалённый терминал информацию о количестве секунд с момента старта или сброса устройства. Чтобы проверить её в деле, понадобится сгенерированный файл usr_demo2.bin.
Небольшое пояснение к программе. Подпрограмма _get_sysclock возвращает количество импульсов кварцевого генератора с момента включения или сброса устройства. Пример дампа подпрограммы:
; ------------------- _get_sysclock ------------------
0198: 37 e3 ; DEC R14, 4
019a: 60 e3 ; MOV (R14), R3
019c: e3 ff fe ff f8 ; LOAD R3, 0xfffefff8
01a1: 68 03 ; MOV R0, (R3)
01a3: 36 33 ; INC R3, 4
01a5: 68 13 ; MOV R1, (R3)
01a7: 68 3e ; MOV R3, (R14)
01a9: 36 e3 ; INC R14, 4
01ab: 05 ; RETURN
При выходе из подпрограммы _get_sysclock регистр R0 содержит младшие 32 бита, а регистр R1 старшие 32-бита результата.
Константа 0x05F5E100 это число импульсов тактового генератора за одну секунду.
Скачать свежую версию прошивки для платы Марсоход2 можно по этой ссылке.
Если вы не слышите новостей от нашего проекта, то знайте — мы работаем над переносом микроядра L4 в ПЛИС.
Спасибо за внимание.
