Добрый день, уважаемые читатели.
Сегодня я расскажу вам о том, как можно построить простенькую систему анализа данных на Python. В этом мне помогут framework cubes и пакет cubesviewer.
Сubes представляет собой framework'ом для работы с многомерными данными с помощью Python. Кроме того он включает в себя OLAP HTTP-сервер для упрощенной разработки приложений отчетности и общего просмотра данных.
Сubesviewer представляет собой web-интерфейс для работы с вышеуказанным сервером.
Для начала надо установить библиотеки, необходимые для работы пакета:
Далее устанавливаем сам пакет cubes:
Как показала практика, лучше использовать версию (1.0alpha2) из текущего репозитория.
Если вы планируете работать под Windows необходимо в файле {PYTHON_DIR}\Lib\site-packages\dateutil\tz.py заменить 40 строку:
на
Затем, вне зависимости от платформы на которой вы работаете, нужно добавить следующий fix для корректной работы json-парсера. Вносить его надо в {PYTHON_DIR}\Lib\site-packages\cubes-1.0alpha-py2.7.egg\cubes\metadata.py начиная с 90 строки:
Для примера возьмем OLAP-куб, который идет в поставке с cubes. Он находится в папке examples/hello_world (ее можно взять с репозитория).
Наибольший интерес для нас представляют 2 файла:
Остановимся на них поподробнее. Начнем с файла slicer.ini, который может включать следующие разделы:
Итак разберем из нашего тестового файла видно, что сервер будет располагаться на локальной машине и будет работать по 5000 порту. В качестве хранилища будет использоваться локальная база SQLite под названием data.sqlite.
Подробнее о конфигурировании сервера можно прочитать в документации.
Также из файла видно, что описание модели нашего куба находиться в файле model.json, описание структуры которого мы сейчас и займемся.
Файл описания модели, это json-файл, который включает следующие логические разделы:
Для нас представляют интерес разделы cubes и dimensions, т.к. все остальные опциональны.
Элемент списка dimensions, содержит следующие метаданные:
Элемент списка cubes, содержит следующие метаданные:
Исходя из выше описанного, можно понять, что у нас в модели в будет 2 измерения (item, year). У измерения "item" 3 уровня измерений:
В качестве меры в нашем кубе будет выступать поле «amount», для которой выполняются функции суммы и подсчета кол-ва строк.
Подробнее о разметке модели куба можно почитать в документации
После того, как мы разобрались с настройками, надо создать нашу тестовую базу. Для того, чтобы это сделать, необходимо запустить скрипт prepare_data.py:
Теперь осталось только запустить наш тестовый сервер с кубом, который называется slicer:
После этого можно проверить работоспособность нашего куба. Для этого в строке браузера можно ввести:
localhost:5000/cube/irbd_balance/aggregate?drilldown=year
В ответ мы получим json-объект с результатом агрегации наших данных. Подробнее о формате ответа сервера можно почитать тут.
Когда мы настроили наш куб, можно приступить к установке сubesviewer. Для этого надо скопировать репозиторий себе на диск:
А потом просто переместить содержимое папки /src в нужный место.
Надо отметить, что сubesviewer является Django-приложением, поэтому для его работы необходим Django (не выше версии 1.4), а также пакеты requests и django-piston. Т.к. данная версия Django уже устарела, то выше я привел ссылку откуда можно взять сubesviewer для версии Django 1.6.
Установка ее немного отличается от оригинала тем, что в файл конфигурации сервера
После этого надо настроить приложение в файле {CUBESVIEWER_DIR}/web/cvapp/settings.py. Указав ему настройки БД, адрес OLAP сервера (переменная
Осталось внести небольшой fix в dajno-piston
Теперь можно синхронизировать наше приложение с БД. Для этого из {CUBESVIEWER_DIR}/web/cvapp нужно выполнить:
Осталось запустить локальный сервер Django
Теперь осталось зайти на указанный в
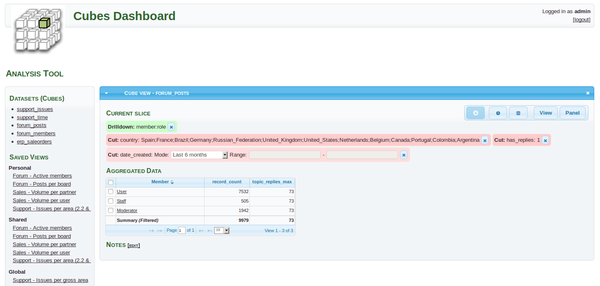
Для иллюстрации работы я взял самый простой пример. Надо отметить что для производственных проектов cubes можно развернуть например на apache или uswgi. Ну а подключить к нему сubesviewer с помощью этой статьи не составит труда.
Если тема будет интересна сообществу, то я раскрою ее в одной из будущих статей.
Сегодня я расскажу вам о том, как можно построить простенькую систему анализа данных на Python. В этом мне помогут framework cubes и пакет cubesviewer.
Сubes представляет собой framework'ом для работы с многомерными данными с помощью Python. Кроме того он включает в себя OLAP HTTP-сервер для упрощенной разработки приложений отчетности и общего просмотра данных.
Сubesviewer представляет собой web-интерфейс для работы с вышеуказанным сервером.
Установка и настройка cubes
Для начала надо установить библиотеки, необходимые для работы пакета:
pip install pytz python-dateutil jsonschema
pip install sqlalchemy flask
Далее устанавливаем сам пакет cubes:
pip install cubes
Как показала практика, лучше использовать версию (1.0alpha2) из текущего репозитория.
Доп настройки под windows
Если вы планируете работать под Windows необходимо в файле {PYTHON_DIR}\Lib\site-packages\dateutil\tz.py заменить 40 строку:
return myfunc(*args, **kwargs).encode()
на
return myfunc(*args, **kwargs)Затем, вне зависимости от платформы на которой вы работаете, нужно добавить следующий fix для корректной работы json-парсера. Вносить его надо в {PYTHON_DIR}\Lib\site-packages\cubes-1.0alpha-py2.7.egg\cubes\metadata.py начиная с 90 строки:
elif len(parts.scheme) == 1 and os.path.isdir(source):
# TODO: same hack as in _json_from_url
return read_model_metadata_bundle(source)
Описание настройки куба и процесс его разворачивания
Для примера возьмем OLAP-куб, который идет в поставке с cubes. Он находится в папке examples/hello_world (ее можно взять с репозитория).
Наибольший интерес для нас представляют 2 файла:
- slicer.ini — файл настроек http сервера нашего куба
- model.json — файл с описание модели куба
Остановимся на них поподробнее. Начнем с файла slicer.ini, который может включать следующие разделы:
[workspace]– конфигурация рабочего места[server]— параметры сервера (адрес, порт и тд.)[models]— список моделей для загрузки[datastore] или [store]– параметры хранилища данных[translations]— настройки локализации для модели.
Итак разберем из нашего тестового файла видно, что сервер будет располагаться на локальной машине и будет работать по 5000 порту. В качестве хранилища будет использоваться локальная база SQLite под названием data.sqlite.
Подробнее о конфигурировании сервера можно прочитать в документации.
Также из файла видно, что описание модели нашего куба находиться в файле model.json, описание структуры которого мы сейчас и займемся.
Файл описания модели, это json-файл, который включает следующие логические разделы:
name– имя моделиlabel– меткаdescription– описание моделиlocale– локаль для модели (если задана локализация)cubes– список метаданных кубовdimensions– список метаданных измеренийpublic_dimensions– список доступных измерений. По умолчанию все измерения доступны.
Для нас представляют интерес разделы cubes и dimensions, т.к. все остальные опциональны.
Элемент списка dimensions, содержит следующие метаданные:
| Ключ | Описание |
|---|---|
| name | идентификатор измерения |
| label | Имя измерения видное пользователю |
| description | описание измерения для пользователей |
| levels | Список уровней измерений |
| hierarchies | Список иерархий |
| default_hierarchy_name | Идентификатор иерархии |
Элемент списка cubes, содержит следующие метаданные:
| Ключ | Описание |
|---|---|
| name | идентификатор измерения |
| label | Имя измерения видное пользователю |
| description | описание измерения для пользователей |
| dimensions | список имен измерений заданных выше |
| measures | список мер |
| aggregates | список функций агрегации мер |
| mappings | задание разметки логических и физических атрибутов |
Исходя из выше описанного, можно понять, что у нас в модели в будет 2 измерения (item, year). У измерения "item" 3 уровня измерений:
- category. Отображаемое имя «Category», поля «category», «category_label»
- subcategory. Отображаемое имя «Sub-category», поля «subcategory», «subcategory_label»
- line_item. Отображаемое имя «Line Item», поле «line_item»
В качестве меры в нашем кубе будет выступать поле «amount», для которой выполняются функции суммы и подсчета кол-ва строк.
Подробнее о разметке модели куба можно почитать в документации
После того, как мы разобрались с настройками, надо создать нашу тестовую базу. Для того, чтобы это сделать, необходимо запустить скрипт prepare_data.py:
python prepare_data.py
Теперь осталось только запустить наш тестовый сервер с кубом, который называется slicer:
slicer serve slicer.ini
После этого можно проверить работоспособность нашего куба. Для этого в строке браузера можно ввести:
localhost:5000/cube/irbd_balance/aggregate?drilldown=year
В ответ мы получим json-объект с результатом агрегации наших данных. Подробнее о формате ответа сервера можно почитать тут.
Установка cubesviewer
Когда мы настроили наш куб, можно приступить к установке сubesviewer. Для этого надо скопировать репозиторий себе на диск:
git clone https://github.com/nonsleepr/cubesviewer.git
А потом просто переместить содержимое папки /src в нужный место.
Надо отметить, что сubesviewer является Django-приложением, поэтому для его работы необходим Django (не выше версии 1.4), а также пакеты requests и django-piston. Т.к. данная версия Django уже устарела, то выше я привел ссылку откуда можно взять сubesviewer для версии Django 1.6.
Установка ее немного отличается от оригинала тем, что в файл конфигурации сервера
slicer.ini в раздел [server] нужно добавить строку allow_cors_origin: localhost:8000После этого надо настроить приложение в файле {CUBESVIEWER_DIR}/web/cvapp/settings.py. Указав ему настройки БД, адрес OLAP сервера (переменная
CUBESVIEWER_CUBES_URL) и адрес просмоторщика (CUBESVIEWER_BACKEND_URL)Осталось внести небольшой fix в dajno-piston
Теперь можно синхронизировать наше приложение с БД. Для этого из {CUBESVIEWER_DIR}/web/cvapp нужно выполнить:
python manage.py syncdbОсталось запустить локальный сервер Django
python manage.py runserverТеперь осталось зайти на указанный в
CUBESVIEWER_BACKEND_URL адрес через браузер. И наслаждаться готовым результатом.Заключение
Для иллюстрации работы я взял самый простой пример. Надо отметить что для производственных проектов cubes можно развернуть например на apache или uswgi. Ну а подключить к нему сubesviewer с помощью этой статьи не составит труда.
Если тема будет интересна сообществу, то я раскрою ее в одной из будущих статей.
