
Защита собственного программного обеспечения от реверс инжиниринга достаточно старая проблема, в своё время терзавшая сердца многих shareware разработчиков и не только. Обычно для таких целей применяют протектор, но насколько бы ни был крутой протектор, всегда найдутся люди которые его распилят и взломают. Однако последнее время протекторы стали применять технологии видоизменения кода(мутацию и виртуализацию), которые позволяют из исходного алгоритма сделать кашу, внешне напоминающую 'чёрный ящик'. И действительно встречаются люди, уверенные в том, что виртуализация и мутация исполняемого кода современными коммерческими протекторами является некой панацеей. Понятное дело что любой безопасник скорее ухмыльнётся и не согласится с таким утверждением, ведь люди знающие горькую цену безопасности любые намёки на идеальную защиту скорее всего воспримут как миф и маркетинговую сказку. В этой статье я расскажу о собственном опыте и виденье исследования чёрного ящика коммерческих протекторов и возможных атаках на него. Надеюсь понимание недостатков таких технологий, поможет вам более разумно и эффективно применять их на практике или не применять вообще.
0x00. Разбор механизмов защиты кода
Для начала давайте определим технологии которые мы будем исследовать:
1. Мутирование — это метод обфускации кода, при котором исходный граф потока управления разбивается дополнительными вершинами, ветвлениями, дополняется мусорными инструкциями, циклами, не нарушая исходного алгоритма программы. Часто исходные инструкции мутируются в некоторое подмножество других инструкций выполняющих одну и ту же работу.
2. Виртуализация — это метод обфускации кода, при котором исходные инструкции алгоритма, транслируются в инструкции виртуальной машины, сгенерированной протектором. На место исходного алгоритма встраивается код, который во время выполнения передаёт промежуточные инструкции на вход в виртуальную машину, интерпретирующую их.
Оба способа усложняют как статический так и динамический анализ исполняемого кода и часто протекторы допускают комбинирование способов.
Далее в статье я буду рассматривать бесплатные демо-версии двух протекторов: VMProtect, Safengine, они позволяют мутировать, виртуализировать и комбинировать оба способа обфускации.
Для наложение технологий мутации и виртуализации кода протекторы предоставляют следующие способы:
1. На этапе разработки, через специальные маркеры (SDK)
Разработчик софта помечает в исходном коде фрагмент защищаемого кода специальными функциями из SDK протектора, затем после компиляции, на этапе установки протектора, данные участки будут обнаружены, вырезаны и обфусцированы.
int main ()
{
VMProtectMutate("Critical_code_mut");
... // critical code here
VMProtectEnd();
return 0;
}
2. На этапе протекции, через отладочные файлы
Непосредственно в процессе установки протектора, считываются отладочные файлы (pdb, map) и на их основе определяется карта обьектов приложения. Далее разработчик выбирает какие функции требуется защитить и как, после чего они целиком вырезаются из кода и обрабатываются.
Почему вырезается защищаемый код? Дело в том что при разбавлении кода, его размер значительно увеличивается, а следовательно уместить в исходном сегменте новые инструкции невозможно, поэтому и применяется вырезание кода в собственный участок памяти протектора.
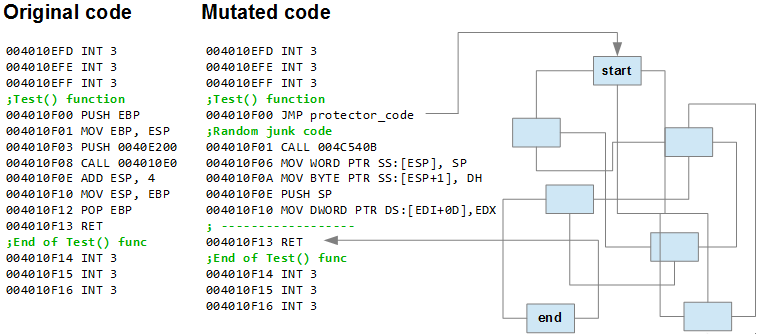
Упрощенная схема мутации исполняемого кода функции void Test() { printf(«Hello»); }
0x01. Преимущества и недостатки протекторов
Очевидным преимуществом мутации конечно же является невозможность визуального исследования алгоритма. Перед исследователем на первый взгляд лежит просто тарелка с горой спагетти, разобрать которую в ручную запредельно сложно, именно на это и делают ставки современные протекторы.
Не менее важным является комбинирование различных техник антиотладки, антипатчинга, антихукинга, мутации и т.д. В совокупности всё это ведёт к усложнению процессов анализа, но не останавливает их.
Недостатков у таких технологий тоже хватает. Первый из которых, это потеря производительности, ведь мутируемый код увеличивается в сотни, а то и в тысячи раз. Не меньше это касается и виртуализации, обычно виртуальная машина намного тяжелее мутируемого кода. А если совместить оба подхода, то получается маниакально раздутый код. Причём накладные расходы не всегда оправдывают такую обфускацию, применение мутирующих технологий однобоко направлено на усложние восстановления оригинального графа выполнения программы.
Вот пример трассировки примитивнейшей функции:
void test()
{
printf("This is protected message #1\n");
printf("This is protected message #2\n");
}
До мутации:
Trace log
main 00405A2A CALL 004059F0 ESP=0018FEE0 main 004059F0 PUSH EBP ESP=0018FEDC main 004059F1 MOV EBP,ESP EBP=0018FEDC main 004059F3 SUB ESP,40 ESP=0018FE9C main 004059F6 PUSH EBX ESP=0018FE98 main 004059F7 PUSH ESI ESP=0018FE94 main 004059F8 PUSH EDI ESP=0018FE90 main 004059F9 PUSH OFFSET 0040ED10 ESP=0018FE8C main 004059FE CALL DWORD PTR DS:[<&MSVCR100D.printf>] EAX=00000012, ECX=84CB6CA9, EDX=7418F4B8 main 00405A04 ADD ESP,4 ESP=0018FE90 main 00405A07 PUSH OFFSET 0040ECF8 ESP=0018FE8C main 00405A0C CALL DWORD PTR DS:[<&MSVCR100D.printf>] EAX=00000014 main 00405A12 ADD ESP,4 ESP=0018FE90 main 00405A15 POP EDI ESP=0018FE94 main 00405A16 POP ESI ESP=0018FE98 main 00405A17 POP EBX ESP=0018FE9C main 00405A18 MOV ESP,EBP ESP=0018FEDC main 00405A1A POP EBP ESP=0018FEE0, EBP=0018FF30 main 00405A1B RETN ESP=0018FEE4
После мутации протектором Safengine:
Trace log
main 00405A2A CALL 004059F0 ESP=0018FEE0 main 004059F0 JMP 004C9C6A main 004C9C6A JMP 004C8391 main 004C8391 CALL 004C82D6 ESP=0018FEDC main 004C82D6 LEA ESP,[ESP+2] ESP=0018FEDE main 004C82DA LEA ESP,[ESP+2] ESP=0018FEE0 main 004C82DE PUSH EBP ESP=0018FEDC main 004C82DF NEG BP EBP=001800D0 main 004C82E2 JMP 004C812E main 004C812E MOV EBP,ESP EBP=0018FEDC main 004C8130 STC main 004C8131 SUB ESP,40 ESP=0018FE9C main 004C8134 CALL 004C8006 ESP=0018FE98 main 004C8006 JMP SHORT 004C7F96 main 004C7F96 LEA ESP,[ESP+4] ESP=0018FE9C main 004C7F9A PUSH EBX ESP=0018FE98 main 004C7F9B CALL 004C7F80 ESP=0018FE94 main 004C7F80 LEA ESP,[ESP+4] ESP=0018FE98 main 004C7F84 PUSH ESI ESP=0018FE94 main 004C7F85 JMP SHORT 004C7FB6 main 004C7FB6 PUSH EDI ESP=0018FE90 main 004C7FB7 PUSH 0040ED10 ESP=0018FE8C main 004C7FBC CALL DWORD PTR DS:[40E19C] EAX=00000012, ECX=93D2AD8F, EDX=7418F4B8 main 004C7FC2 JMP SHORT 004C7FA0 main 004C7FA0 STC main 004C7FA1 JMP SHORT 004C7FDA main 004C7FDA ADD ESP,4 ESP=0018FE90 main 004C7FDD CALL 004C7FC4 ESP=0018FE8C main 004C7FC4 LEA ESP,[ESP+4] ESP=0018FE90 main 004C7FC8 PUSH 0040ECF8 ESP=0018FE8C main 004C7FCD CALL 004C7FE2 ESP=0018FE88 main 004C7FE2 MOV BYTE PTR SS:[ESP],CH main 004C7FE5 JMP SHORT 004C7FEB main 004C7FEB LEA ESP,[ESP+4] ESP=0018FE8C main 004C7FEF CALL DWORD PTR DS:[40E19C] EAX=00000014 main 004C7FF5 SETPE BH EBX=7EFD0100 main 004C7FF8 XCHG BL,BH EBX=7EFD0001 main 004C7FFA INC EBX EBX=7EFD0002 main 004C7FFB JMP SHORT 004C805A main 004C805A ADD ESP,4 ESP=0018FE90 main 004C805D POP EDI ESP=0018FE94 main 004C805E MOV ESI,4B536EDD ESI=4B536EDD main 004C8063 MOV SI,WORD PTR SS:[ESP] ESI=4B530000 main 004C8067 JMP SHORT 004C801E main 004C801E LEA EBX,[CDDFCA2F] EBX=CDDFCA2F main 004C8024 POP ESI ESP=0018FE98, ESI=00000000 main 004C8025 CALL 004C8008 ESP=0018FE94 main 004C8008 POP WORD PTR SS:[ESP] ESP=0018FE96 main 004C800C MOV BX,WORD PTR SS:[ESP+1] EBX=CDDF0000 main 004C8011 XCHG BYTE PTR SS:[ESP],BL EBX=CDDF004C main 004C8014 JMP SHORT 004C8040 main 004C8040 LEA ESP,[ESP+2] ESP=0018FE98 main 004C8044 POP EBX EBX=7EFDE000, ESP=0018FE9C main 004C8045 JMP SHORT 004C802A main 004C802A MOV ESP,EBP ESP=0018FEDC main 004C802C LEA EBP,[EDI+EAX] EBP=00000014 main 004C802F MOV BP,3200 EBP=00003200 main 004C8033 MOV EBP,CEF73787 EBP=CEF73787 main 004C8038 JMP 004C80ED main 004C80ED POP EBP ESP=0018FEE0, EBP=0018FF30 main 004C80EE RETN ESP=0018FEE4 -------- Logging stopped
В приведённом примере мутация кода выполнена на самом маленьком уровне сложности. Safengine позволяет увеличивать эту сложность до 254 раз, что в итоге может раздуть ваш код из 10 инструкций в набор мусора превышающий размер исходной программы в пару раз, что достаточно избыточно.
Так же к недостатком можно отнести случаи повреждения программы, которые к сожалению на моей памяти бывали. Одно дело если такие сбои возникнут в обычной программе, что приведёт к падению и совершенно другое если падение произойдёт в драйвере, что совершенно не приемлимо. Как известно протекторы могут обрабатывать различные исполняемые файлы (exe, dll, ocx, sys).
Маркетинговая политика тоже порой оставляет желать лучшего. Технический мусор в уши клиентам создающий иллюзию защищённости, не есть хорошо. Ведь разработчики протекторов не пишут в описаниях своих продуктов что эта технология хороша, но в ней есть вот такой-то такой-то изьян.
0x02. Проблема неполноты защиты кода
Наконец перейдём к вопросу, что же мешает разработчикам протекторов написать еще более сложную и стойкую защиту? Ответ достаточно прост — неполнота информации. Получая на вход бинарный файл, даже при наличии отладочной информации существует ряд ограничений, нарушение которых приведёт к неуниверсальности протектора, либо повреждению защищаемого приложения. Для примера таких ограничений взглянем на структуру обычного PE приложения:
Raw Virtual Name ------------------------------------ 00000000 00400000 PE header 00000200 00401000 Code sector 00000400 00402000 Data sector 00000600 00403000 Resources sector
Код и данные в приложении помещаются в различные секции, но между ними есть чёткие связи. Таким образом несколько различных функций могут ссылаться на один и тот же блок данных, а данные могут ссылаться на другие данные и функции. Причем не всегда эта связь является явной. Исходя из этого, протекторы не могут свободно манипулировать структурой исполняемого файла: передвигать данные, расширять, перемещать функции в исходном сегменте и т.д. Хотя когда-то я предпринимал попытки расширения секций исполняемого файла, но это частный случай не являющийся универсальным. Поэтому протекторы укладывают свои данные следующим образом:
Raw Virtual Name ------------------------------------ 00000000 00400000 PE header 00000200 00401000 Code sector 00000400 00402000 Data sector 00000600 00403000 Protector sector 00000800 00404000 Resources sector
Исходное местоположение кода и данных не меняется, хотя перемещение некоторых других секторов возможно(ресурсы, релокации, ...). Защищаемый код вырезается и на его место помещается мусорные инструкции, чаще всего эти инструкции являются частью мутированного графа исполнения. Мутированный граф и виртуальная машина помещаются в сектор протектора.
Так же в связи с увеличением вычислительной нагрузки, протекторы не могут мутировать весь код приложения. Поэтому выбор защищаемых участков кода ложится на плечи программисту. Но программист не всегда может применить это наложение разумно. Например накрыв какой-то алгоритм шифрования мутацией, программист забудет накрыть мутацией все вызовы этого шифра, найдя которые исследователь сможет заполучить входные данные этого алгоритма и на их основе строить предположения по устройству шифра и возможно даже классифицировать или воспроизвести его.
Всё это приводит к утечке информации из мутированого\виртуализированного кода и позволяет выполнять атаки на него. Зная примерное местоположение данных или каких-то функций мы можем отслеживать обращение к ним из чёрного ящика, тем самым вместо распутывания клубка, мы составляем фантомную модель алгоритма. Конечно такой подход далеко не претендует на то чтобы дать нам полною картину алгоритма программы, однако в некоторых случаях этого вполне достаточно.
0x03. Рыбачим в чёрном ящике
Типичным средством исследования чёрного ящика, является трассировщик. Однако трасса обфусцированного кода на 80-99% состоит из мусора, поэтому нам нужно как-то из этого мусора получить только полезную информацию. Этот процесс чем-то напоминает рыбалку. Представим что трасса это озеро, трассировщик удочка, а условия трассировки эта наживка. Используя вышеописанные недостатки протекторов, мы можем подобрать правильную наживку и словить правильную информацию. Взглянем как же это выглядит на практике.
Предположим у нас есть следующая программа:
void array_fill(unsigned char *buf, size_t size)
{
for (int i = 0; i < size; i++) {
buf[i] = i;
if (i > 0) {
buf[i] ^= buf[i - 1];
}
}
}
int main()
{
unsigned char buf[10];
array_fill(buf, sizeof(buf));
return 0;
}
Пусть на функцию array_fill() будет наложена и мутация и виртуализация. Давайте оттрассируем вызов функции array_fill():
Исходное кол-во шагов: 230
Кол-во шагов после обфускации VMProtect: 83924
Кол-во шагов после обфускации Safengine: 250382
Как видно по цифрам разобрать трассу вручную просто нереально. Поэтому воспользуемся методом рыбалки.
Представим что мы ничего не знаем о функции array_fill(). Исследовав main() мы можем точно сказать что её подвызов принимает на входе адрес буфера и его размер, после чего согласно какому-то алгоритму буфер заполняется информацией. Поэтому мы зададим нашему трассировщику правило, по которому мы будем логировать только обращения на чтение\запись к передаваемому в функцию буферу. Результат для всех трёх вариантов приложений будет один и тот же:
Trace log
main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7700, ECX=0018FF34 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7701, ECX=0018FF35 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF34 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF35 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7701, ECX=0018FF35 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7702, ECX=0018FF36 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF35 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF36 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7703, ECX=0018FF36 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7703, ECX=0018FF37 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF36 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF37 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7700, ECX=0018FF37 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7704, ECX=0018FF38 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF37 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF38 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7704, ECX=0018FF38 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7705, ECX=0018FF39 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF38 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF39 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7701, ECX=0018FF39 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7706, ECX=0018FF3A main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF39 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3A main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7707, ECX=0018FF3A main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7707, ECX=0018FF3B main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3A main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3B main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7700, ECX=0018FF3B main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7708, ECX=0018FF3C main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3B main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3C main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7708, ECX=0018FF3C main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7709, ECX=0018FF3D main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3C main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF3D
Как видно независимо от степени мутации кода и кол-ва мусора, мы смогли получить чистую трассу описывающую все обращения к буферу. Но сможем ли мы восстановить по ней исходный алгоритм? Давайте попробуем.
И так если всмотреться в трассу становится виден цикл (это видно по повторяющимся обращениям к коду по адресу 004B7898):
; 1 step main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7700, ECX=0018FF34 ; 2 step main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7701, ECX=0018FF35 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF34 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF35 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7701, ECX=0018FF35 ; 3 step main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7702, ECX=0018FF36 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF35 main 004B7A8E MOV AL,BYTE PTR DS:[ECX] EAX=004B7A89, ECX=0018FF36 main 004B7898 MOV BYTE PTR DS:[ECX],AL EAX=004B7703, ECX=0018FF36 ...
и таких шагов всего 10, что соответствует размеру нашего буфера. Далее всё достаточно просто, зная какие значения берутся и какие кладутся назад, наш алгоритм работы лежит у нас практически на ладони. Единственное что тут нужно угадать, это применение операции XOR, но в данном случае это абсолютно не сложно.
Конечно данный пример является искусственным, на практике же приходится сталкиваться с более сложными алгоритмами с вложенными вызовами и неявной логикой, получение информации о которых может оказаться в десятки раз сложнее. В таких ситуациях применяются более сложные трассировщики, деобфускаторы, DBI и т.д. Тем не менее всё сводится к выдиранию информации трассировщиками и её анализу. Зная адреса к которым алгоритм может обратиться, мы собираем достаточно полезной информации о нём.
0x04. Анализ вложенных вызовов
Не менее важной информацией которую можно вытянуть из чёрного ящика, является информация о вложенных вызовах. Это могут быть вызовы WinAPI, библиотечные функции, функции самого приложения. Такая информация помогла бы нам более детально изучить внутреннее устройство и зависимости защищённого алгоритма.
В простейшем случае для анализа вложенных вызовов, мы можем воспользоваться известной информацией о структуре исполняемого файла. То есть зная в каком сегменте расположен мутированный код, можно отследить все выходы из данного сегмента, которые будут соответствовать вызовам внешних функций. И это действительно будет работать для библиотечных функций, но проблемы могут возникнуть для вызова собственных функций программы. Как я говорил где-то выше, вырезая защищаемый код, на его место протектор может положить часть собственного кода (мутированный граф, кусок виртуальной машины). Таким образом если выполнение кода выходит из секции протектора в секцию кода приложения, нет никакой гарантии что это именно вызов вложенной функции, а не выполнение части мутированного графа.
Решение этой проблемы опять достаточно вероятностное. Во-первых нам потребуется гибкий трассировщик, например можно воспользоваться фреймворком Intel Pin, в прошлый раз я использовал трассировщик встроенный в OllyDbg. Во-вторых нужно создать грамотные трассировочные правила, которые позволят нам логировать только вложенные вызовы, исключая мусор, расположенный в секции кода. Если мы хотим определить вызов библиотечной функции то нам достаточно создать правило, которое будет фиксировать передачу управления за пределы участка памяти принадлежащему исследуемому модулю. В большинстве случаев это будет передача управления в какую-то библиотеку, хотя в некоторых нестандартных ситуациях передача управления может быть выполнена в некоторый базонезависимый код протектора. Но такие частные случаи мы рассматривать не будем. Однако что же делать с вложенными вызовами в самой программе?
Как вариант можно определять вложенные функции по сигнатуре пролога. Компиляторы обычно придают функциям достаточно шаблонный вид, за что и можно зацепится.

Шаблонный пролог функции
То есть при возврате управления из обфусцируемого кода (секции протектора), в секцию кода приложения мы можем проверять наличие инструкций Int3, Retn расположенных до предполагаемого пролога и так же сверять пролог с заранее подготовленными сигнатурами. Это поможет не всегда, так как компилятор может напихать чего угодно в код, особенно после оптимизации, но это больше чем ничего.
Так же я заметил один маленький недостаток в обфускации протектором Safengine, который может присутствовать и в других протекторах, но которого нет в VMProtect. Недостаток заключается в том, что если протектор мутирует какую-то функцию и в ней есть вызов другой мутируемой функции, то вложенная функция вызывается не в мутируемом коде, а через переходник (инструкцию jmp) который расположен по её оригинальному адресу. Это так же является утечкой информации из мутированного кода и может быть использовано для создания правила трассировщика. Хотя в VMProtect например вложенная мутируемая функция будет вызываться сразу в сегменте протектора, не позволяя нам таким образом определять вложенный вызов. Возможно этот недостаток существует только в демо версии Safengine.
Я уже не стал засорять статью исходниками трассировщика на Intel Pin, но если статья вам понравится, то можно и про трассировщик написать отдельной статьёй.
0x05. Восстановление графа выполнения
Мы всё ходили вокруг да около, пытались всячески избегать полного анализа мутированного кода, однако деобфускация и девиртуализация далеко не миф. Просто на деле такие технологии достаточно сложны и не пишутся на коленке. Я думаю специалисты из университетов и антивирусных лабораторий вовсю уже освоили данное направление и имеют богатый набор средств для их реализации. К сожалению я не сильно знаком с практикой применения таких технологий и сказать про них мне особо нечего, кроме того что они есть и что это круто :)
Если у вас есть какие-то знания и опыт в данном вопросе буду признателен если подкинете пару ссылочек в комментариях.
0x06. Заключение
Как видите чёрный ящик на деле оказывается не таким уж чёрным. По собранным крупицам информации, мы можем частично восстанавливать логику защищенного алгоритма и порой в достаточном обьёме.
А вообще я считаю лучше всего раскрыть потенциал применения технологий виртуализации и мутации могут только специализированные компиляторы. Ведь компилятор в отличии от протектора, обладает практически полной информацией о защищаемом коде и может спокойно манипулировать расположением и внешним видом защищаемого кода. Если реализовать какой-то набор подсказок для компилятора, то можно помочь программисту самостоятельно выбирать степень сложности обфускации для определённых функций и методов, что обеспечит более эффективное распределение защиты и следовательно нагрузки.
Напоследок, желающим проверить свои навыки реверса обфусцированного кода, предлагаю решить данный crackme.
Спасибо за внимание.
