
В статье будет рассмотрена возможность мониторинга база данных по средствам встроенной в Zabbix поддержке ODBC, c использованием автообнаружения объектов.
Для начала рассмотрим доступные для Zabbix методы мониторинга БД, которые использовались до поддержки ODBC.
Так как статья про мониторинг Oracle, то и будем смотреть в этом разрезе.
1. Использования скрипта zabora
В принципе спкрипт всем хорош, но главное, что меня не устраивало: скрипт лежит на каждой машине с БД, и при добавление запроса приходилось идти на эту машину и редактировать конфиг.
Поддерживает параметры запросов, то есть можно передавать параметр в ключ и на основе его делать запрос к БД.
То есть один и то же запрос может быть использован для сбора метрик разных объектов.
2. Orabbix или DBforBIX
Тоже хороший продукт, является демоном на java, создает несколько соединений и поддерживает автоматическое добавление новых запросов в конфиг без перезагрузки. Работает как Zabbix trapper, то есть сам с определенной периодичностью посылает данные в Zabbix сервер.
Недостатки:
— не поддерживает параметры, то есть на каждую метрику создается отдельный запрос.
Представьте у вас 10 tablespace'ов и вам нужно снимать с каждого 4 параметра — получается 40 запросов в файле. Интервал запроса получение метрики, так же выставляется в конфиге, что не очень удобно.
Попробовав все эти решения решил использовать поддержку ODBC в Zabbix, и вот почему:
- запрос к БД — стандартный ключ Zabbix, из этого следует, что мы настраиваем такие параметры как частота опроса в самом интерфейсе
- редактирование запросов в интерфейсе Zabbix
- позволяет использовать макросы
- самое главное позволяет автоматизировать процесс добавления новых объектов на мониторинг
Сначала опишу, что имеется в хозяйстве:
1. 6 баз данных Oracle — 1 БД — 1 сервер + 1 резервный сервер под БД итого: получается 12 серверов.
2. Сервера для каждой БД объединены в кластер — итого 6 кластеров
3. На каждом сервера установлен Zabbix agent для AIX
4. На каждом сервере по скрипту zabora
Конфигурация Zabbix мониторинга:
- Zabbix сервер на CentOS 6.5 + TokuDB — 20 000 элементов — 380 nps (новых значений в секунду)
- Специально для мониторинга БД, был поднят Zabbix Proxy, так как запросы могут выполнятся достаточно долго, то не хотелось бы из-них подвешивать процессы сбора данных основного Zabbix'a — тоже CentOS 6.5 + TokuDB
В этой статье я не буду касаться настройки TokuDB, так как планирую еще одну статью почему мы перешли с InnoDB на TokuDB, и что нам это дало.
Установка Oracle Instant Client
Сначала необходимо установить Oracle Instant Client на машину с Zabbix Proxy:
У нас используется Oracle 11g, поэтому скачиваем RMP пакеты соответствующей версии с сайта Oracle.
Нам необходимы:
- oracle-instantclient11.2-basic-11.2.0.4.0-1.x86_64.rpm — основные библиотеки
- oracle-instantclient11.2-jdbc-11.2.0.4.0-1.x86_64.rpm — драйвера для java, для нашей задачи не нужны, но в хозяйстве пригодиться :)
- oracle-instantclient11.2-sqlplus-11.2.0.4.0-1.x86_64.rpm — клиент SQLplus
- oracle-instantclient11.2-odbc-11.2.0.4.0-1.x86_64.rpm — библиотека для работы через ODBC
- можно еще до кучи: oracle-instantclient11.2-devel-11.2.0.4.0-1.x86_64.rpm :)
в той папке в которую скачали все эти файлы делаем:
# rpm -i oracle-*.rpm
Настройка SQLplus для доступа к БД Oracle.
Для того чтобы клиент работал, необходимо в параметры окружение выставить необходимые переменные, для начала выставим их в своем профиле, прописав в файл
$HOME/.bash_profile:ORACLE_HOME=/usr/lib/oracle/11.2/client64 LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:$LD_LIBRARY_PATH TNS_ADMIN=$ORACLE_HOME/network/admin> PATH=$PATH:$ORACLE_HOME/bin:$HOME/bin export ORACLE_HOME export LD_LIBRARY_PATH export TNS_ADMIN export PATH
Перелогиниваемся и смотрим есть ли наши переменные в
# env
Обратим внимание на переменную
TNS_ADMIN=$ORACLE_HOME/network/adminЭтот путь необходимо создать, туда мы положим файл tnsnames.ora который используется библиотеками клиента для подключения к БД.
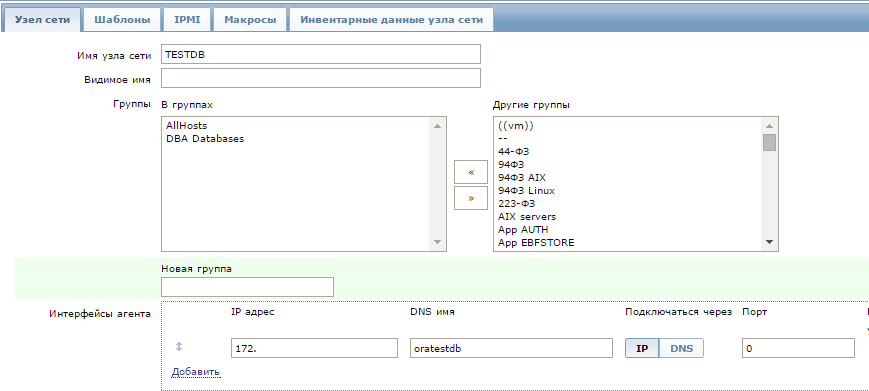
Создадим подключение к БД с именем TESTDB например.
#cat $ORACLE_HOME/network/admin/tnsnames.ora
TESTDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = oratestdb)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = testdb) ) )
Необходимо подставить нужные значения в HOST и SERVICE_NAME.
HOST — можно прописывать IP адрес или DNS имя (проверьте только, что оно ресолвится в IP)
Проверим настройку клиента, только предварительно создайте учетную запись zabbix в Oracle.
# sqlplus zabbix/zabbix@TESTDB
SQL*Plus: Release 11.2.0.4.0 Production on Sat May 24 10:47:09 2014 Copyright (c) 1982, 2013, Oracle. All rights reserved. Connected to:</code> Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL>
Видим, что клиент выдал приглашение, значит соединение прошло успешно, и совсем чтобы быть уверенными сделаем простенький запрос:
SQL> select banner from v$version where rownum=1;
BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production SQL>
Конфигурация ODBC.
Официальные пакеты Zabbix Server и Zabbix Proxy в СentoOS скомпилированы с поддержкой unixODBC, поэтому после их установки у вас должен быть установленный пакет unixODBC, проверяем:
# yum info *ODBC
Вывод должен содержать следующие пакеты:
unixODBC и oracle-instantclient11.2-odbc.Правим файлы:
# cat /etc/odbcinst.ini
[OracleDriver] Description=Oracle ODBC driver for Oracle 11g Driver=/usr/lib/oracle/11.2/client64/lib/libsqora.so.11.1
И сразу делаем такую проверку:
# ldd /usr/lib/oracle/11.2/client64/lib/libsqora.so.11.1
ldd: warning: you do not have execution permission for `/usr/lib/oracle/11.2/client64/lib/libsqora.so.11.1` linux-vdso.so.1 => (0x00007fff1a58f000) libdl.so.2 => /lib64/libdl.so.2 (0x00007f89d6d4d000) libm.so.6 => /lib64/libm.so.6 (0x00007f89d6ac8000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f89d68ab000) libnsl.so.1 => /lib64/libnsl.so.1 (0x00007f89d6692000) libclntsh.so.11.1 => /usr/lib/oracle/11.2/client64/lib/libclntsh.so.11.1 (0x00007f89d3d22000) libodbcinst.so.1 => /lib64/libodbcinst.so.1 (0x00007f89d3b11000) libc.so.6 => /lib64/libc.so.6 (0x00007f89d377d000) /lib64/ld-linux-x86-64.so.2 (0x00007f89d711c000) libnnz11.so => /usr/lib/oracle/11.2/client64/lib/libnnz11.so (0x00007f89d33af000) libaio.so.1 => /lib64/libaio.so.1 (0x00007f89d31ae000) libltdl.so.7 => /usr/lib64/libltdl.so.7 (0x00007f89d2fa5000)
C большой долей вероятностью, вы получите
libodbcinst.so.1 => not found, поэтому нужно сделать сим-линк:# ls -lah /lib64 | grep odbc
lrwxrwxrwx. 1 root root 31 May 18 00:45 libodbcinst.so.1 -> /usr/lib64/libodbcinst.so.2.0.0 lrwxrwxrwx. 1 root root 16 May 20 11:41 libodbcinst.so.2 -> libodbcinst.so.1
Дальше редактируем файл:
# cat /etc/odbc.ini
[ORA_TESTDB] Driver= OracleDriver DSN= TESTDB ServerName= TESTDB UserID= zabbix Password= zabbix
После этого у нас должно получится подключится к БД Oracle через клиент ODBC (всегда используйте параметр -v, если будет ошибка подключения, скажет детально в чем проблема):
# isql -v ORA_TESTDB
+---------------------------------------+ | Connected! | | | | sql-statement | | help [tablename] | | quit | | +---------------------------------------+ SQL>
Так же для очистки совести, что у нас все работает, делаем запрос:
SQL> select banner from v$version where rownum=1; +---------------------------------------------------------------------------------+ | BANNER | +---------------------------------------------------------------------------------+ | Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production | +---------------------------------------------------------------------------------+ SQLRowCount returns -1 1 rows fetched SQL>
Поздравляю, Вы настроили ODBC.
Теперь нам необходимо добиться, чтобы Zabbix Proxy так же мог делать запросы через ODBC.
Для этого необходимо, чтобы в окружение процесса zabbix_proxy были доступны переменные, указанные выше, для это добавим в файл:
# cat /etc/init.d/functions
# Set up a default search path. PATH="/sbin:/usr/sbin:/bin:/usr/bin" ORACLE_HOME=/usr/lib/oracle/11.2/client64 LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:$LD_LIBRARY_PATH TNS_ADMIN=$ORACLE_HOME/network/admin</code> PATH=$PATH:$ORACLE_HOME/bin:$HOME/bin</code> export ORACLE_HOME export LD_LIBRARY_PATH export TNS_ADMIN export PATH
После этого обязательно перезапускаем zabbix_proxy:
# service zabbix-proxy restart
Теперь мы сразу перейдем к настройке правил автообнаружения в терминологии Zabbix — это low level discovery rule.
Что такое LLD?
В принципе это любой элемент в Zabbix который может вернуть данные в JSON формате.
Так встроенный мониторинг баз данных в Zabbix всегда возвращает только 1 колонку и 1 строку. Почему-то в команде Zabbix до сиз пор не напишут для БД генератор LLD.
Кому нужна эта фича, просьба проголосовать.
Придется написать скрипт который будет выдавать нам список объектов в JSON формате.
Шаблон и скрипт можно взять на GitHub
Скрипт написан на php, поэтому любителям bash прошу отвернуться в сторону :)
Комментировать сам скрипт не буду, думаю по коду все понятно, скажу только, что его нужно положить в папку которая задана в конфиге zabbix_proxy.conf (или zabbix_server.conf):
ExternalScripts=/usr/lib/zabbix/externalscripts
Скрипт oracle.odbc.discovery
#!/usr/bin/php <?php if(!isset($argv[1]) && !isset($argv[2])) exit("ZBX_NOTSUPPORTED"); $connected_dsn = odbc_connect($argv[1],"",""); if(!$connected_dsn) exit('SQL connection erorr | ZBX_NOTSUPPORTED'); switch ($argv[2]) { case "tablespaces": $result=odbc_exec($connected_dsn,"SELECT tablespace_name FROM dba_tablespaces;"); $tablespaces = array("data"=>array()); while(odbc_fetch_row($result)){ $tablespaces['data'][]=array('{#TBSNAME}'=>odbc_result($result,1)); } echo json_encode($tablespaces); break; case "jobs": $result=odbc_exec($connected_dsn,"SELECT job_name, owner FROM dba_scheduler_jobs WHERE state != 'DISABLED';"); $jobs = array("data"=>array()); while(odbc_fetch_row($result)){ $jobs['data'][]=array( '{#JOBNAME}'=>odbc_result($result,1), '{#JOBOWNER}'=>odbc_result($result,2)); } echo json_encode($jobs); break; } exit(); ?>
Скрипту передаются два параметра:
1. DSN — который вы указали в файле /etc/odbc.ini в квадратных скобках, в случае примера это ORA_TESTDB
2. тип объектов, список которых нужно вернуть: tablespaces или jobs
В случае jobs, скрипт вернет так же и {#JOBOWNER}, то есть владельца job'a.
Добавьте права на выполнения на скрипт и попробуйте его запустить:
# /usr/lib/zabbix/externalscripts/oracle.odbc.discovery ORA_TESTDB tablespaces, скрипт вернет примерно вот такой массив:{ "data": [ { "{#TBSNAME}": "SYSTEM" }, { "{#TBSNAME}": "SYSAUX" }, { "{#TBSNAME}": "UNDOTBS1" }, { "{#TBSNAME}": "TEMP" }, { "{#TBSNAME}": "USERS" } ] }
# /usr/lib/zabbix/externalscripts/oracle.odbc.discovery ORA_TESTDB jobs
{ "data": [ { "{#JOBNAME}": "PURGE_LOG", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "ORA$AUTOTASK_CLEAN", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "DRA_REEVALUATE_OPEN_FAILURES", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "BSLN_MAINTAIN_STATS_JOB", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "RSE$CLEAN_RECOVERABLE_SCRIPT", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "SM$CLEAN_AUTO_SPLIT_MERGE", "{#JOBOWNER}": "SYS" }, { "{#JOBNAME}": "RLM$EVTCLEANUP", "{#JOBOWNER}": "EXFSYS" }, { "{#JOBNAME}": "RLM$SCHDNEGACTION", "{#JOBOWNER}": "EXFSYS" } ] }
Наконец-то переходим к добавлению мониторинга БД Oracle в Zabbix.
Для начала пару слов о шаблоне:
1. общие ключи мониторинга Oracle взяты из скрипта zabora
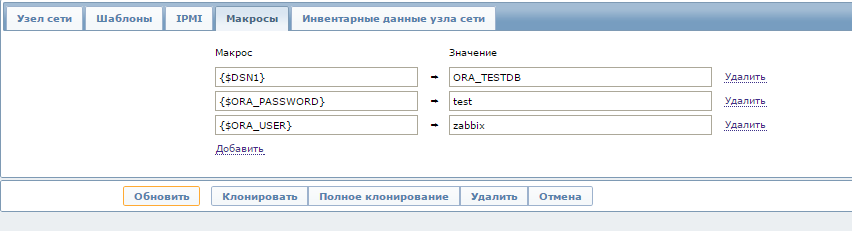
2. чтобы шаблона заработал необходимо во вкладе Макросы самого хоста, добавить 3 пользовательских макроса:
— {$DSN1} — DSN который прописан в квадратных скобках файла /etc/odbc.ini (в примере ORA_TESTDB)
— {$ORA_USER} — пользователь с правами которого будет подключение к БД Oracle
— {$ORA_PASSWORD } — пароль для подключения к БД Oracle
Итак список правил LLD:

Чтобы правила отработали в первый раз, выставите в самих правила интервал, предположим 300 секунд, и через 5 минут у вас в элементах данных должны создаться новые.
Рассмотри сами правила и начнем с Tablespaces.

В принципе здесь все понятно, хочу обратить внимание на поле «Фильтр».
С помощью этого поля можно производить фильтрацию списка который возвращает нам сам элемент, в нашем примере нам не нужно добавлять на мониторинг системные tablespaces. Фильтрация происходит на основе правила regexp. Как видно на картинки поле {#TBSNAME} должно соответствовать правилу regexp Oracle System Excluded Tablespaces. Общие правила regexp описываются в
Администрирование > Общие > Регулярные выражения и вызываются в фильтре через символ @.
Аналогично все и для job'ов:

Переходим к прототипам данных

Сам прототип

Картинка говорит сама за себя, но хочу обратить на один нюанс, а именно на поле «Единица измерения», по умолчанию в Zabbix используется 10-тичная система исчисления, что и следовало ожидать, поэтому все приставки Кило, Мега, Гига и т.д. это деление на 1000, что с точки зрения исчисления объема данных не совсем корректно, поэтому чтобы вы получали во вкладке «Последние данные» адекватные значения в Zabbix используется «специальные» единицы измерения: B и Bps — байт и байт в секунду (подробнее).
Но есть забавный момент (баг), в последних данных приставки K(ilo), M(ega), G(iga) переводятся в K, М, Г, а вот сама единица нет, поэтому в случае с гигабайтами у Ваc будет ГB.
Прототипы триггеров для tablespaces:

Диапазоны следующие:
- при размере меньше 3ТБ ограничение в процентах
- от 3ТБ до 10ТБ в гигабайтах
- от 10ТБ в гигабайтах
Обратить внимание, что значения в условиях используется в байтах, а также обратить на порядок и используемых значений.
На первый взгляд может показаться лишним условие «Максимальный размер > 0»
Но это сделано для того чтобы приходило более информативное письмо для DBA.
В действиях вы указываете:
1. {ITEM.NAME1} ({HOSTNAME1}:{TRIGGER.KEY1}): {ITEM.VALUE1} 2. {ITEM.NAME2} ({HOSTNAME1}:{TRIGGER.KEY2}): {ITEM.VALUE2} 3. {ITEM.NAME3} ({HOSTNAME1}:{TRIGGER.KEY3}): {ITEM.VALUE3}
В действие мы не можем получить значения ключа который был создан автоматически, не то чтобы мы не можем его получить просто мы не знаем его название, для это там нужно вычленить из ключа название tablespace, но таких функций Zabbix нет.
При таких настройках действия, Вам будет приходить нечто подобное:
1. Текущий размер tablespace BG_Z_LOB_TBS (ODB.odbc.select[tbs_size_BG_Z_LOB_TBS,ORA_ODB]): 2 GB 2. Осталось свободного места в процентах в tablespace BG_Z_LOB_TBS (ODB.odbc.select[tbs_used_percent_BG_Z_LOB_TBS,ORA_ODB]): 99 % 3. Максимально возможный размер tablespace BG_Z_LOB_TBS (ODB.odbc.select[tbs_maxsize_BG_Z_LOB_TBS,ORA_ODB]): 32 GB
Прототипы данных для job'ов:

Прототипы триггеров для job'ов:

Триггеры срабатывают если:
- время выполнения job'a более 720 минут
- если job завершился со статусом не равным «SUCCEEDED»
Приятных Вам обнаружений в БД Oracle :)
