SnapManager — это набор утилит компании NetApp позволяющих автоматизировать процессы снятия так называемых Application-Consistent Backup (ACB) и Crash-Consistent Snapshots (CCS) без остановки приложений, средствами СХД NetApp FAS серии, их архивации, резервного копирования, тестирования копий и архивов, клонирования, примапливания склонированных данных к другим хостам, восстановления и др. функциями через GUI интерфейс одним только лишь оператором приложения без привлечения специалистов по серверам, сети и СХД.
SnapManager for Oracle on Windows, Cloning Operation
Зачем вообще бэкапировать данные при помощи снапшотов и тем более средствами СХД? Дело в том, что большинство современных способов бэкапирования информации подразумевают длительность процесса, ресурсоёмкость: нагрузка на хост, загрузка каналов, занимание пространства и как следствие к деградации сервисов. Тоже касается и клонирования больших объемов информации для Dev/Test подразделений, увеличивая «временной разрыв» между актуальными данными и резервируемыми, это повышает вероятность того, что бэкап может оказаться «не восстановим». С применением «аппаратных» снапшотов компании NetApp, не влияющих на производительность и занимающий не положенные 100% резервной копии, а только лишь «разницу» (своего рода инкрементального бэкапа или лучше сказать обратного инкрементального бэкапа, на снятие и сборку которого не нужно тратить время), а также возможность передачи данных для резервирования и архивирования в виде снапшотов, позволяя более элегантно решать современные высокие требования бизнеса для подобных задач, уменьшая время передачи информации и нагрузку на хосты.
Утилита состоит из нескольких компонент: сервер, на выделенном хосте или виртуальной машине и агентов устанавливающихся на хостах с DB. Для полноценного функционирования SnapManager необходим функционал, который тоже лицензируются «поконтроллерно»: FlexClone, SnapRestore. Кроме установленных агентов SnapManager требуется установленный экземпляр утилиты SnapDrive (лицензии входят в комплект с SnapManager) на хосте внутри ОС с DB. SnapDrive помогает в создании CCS взаимодействуя с ОС, в то время как SMO взаимодействует с приложением, для создания ACB, таким образом дополняя друг-друга. Резница между ACB и CCS. Без купленных лицензиий SnapRestore и FlexClone, не будет доступен функционал соответственно моментального восстановления и средствами СХД моментального клонирования и катологизации.
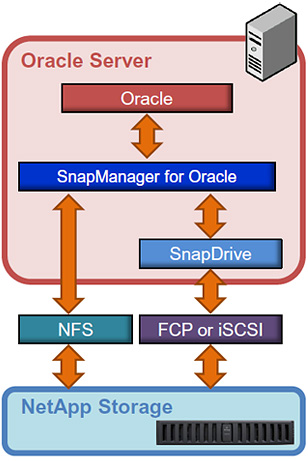
Интеграция SMO с Oracle
Лицензирование у SnapManager «поконтроллерное» в состав лицензии SnapManager входят и другие менеджеры для MS SQL, MS Exchange, MS Share Point, MS Hyper-V, VMWare vSphere, SAP, Lotus Domino и Citrix Xen Server.
SnapManager for MS SQL, Moving Operation
Пойдя по пути «оптимизации расходов», отказываясь от покупки лицензии SnapManager, нужно понимать, что управление потребуют дополнительных затрат времени и взаимодействия DBA с Server Admins, Сетевыми Администраторами и Админов СХД, для того, чтобы DBA получили вожделенную манипуляцию с DB. В то время как с SnapManager это можно выполнить нажатием пары кнопок в GUI интерфейсе, без привлечения разных специалистов и затрат времени.
Многие из выполняемых функций SnapManager можно выполнять при помощи бесплатной утилиты SnapCreator, также позволяющей интегрироваться с DB (а также большим количеством других приложений) приложениями для снятия консистентных снапшотов ACB средствами СХД. Но эта утилита не выполняет многих других удобных функций по управлению DB. Таких как клонирование DB, восстановление «in-Place», примапливание клона DB к другому хосту, автоматическое тестирование работоспособности и восстановления из архива и т.д.
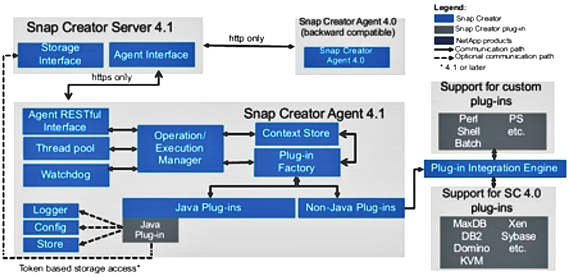
Схема взаимодействия компонент SnapCreator
Большинство недостающего функционала в SnapCreator можно компенсировать при помощи скриптинга, который сейчас доступен с PowerShell командлетами в: DataOntap Toolkit, SnapCreator, OnCommand Unified Manager (OCUM) и многих других полезных утилит. На что несомненно потребуется время, для отладки под бизнес процессы.
SMO интегрируется с 10GR2, 11g R1/R2, 12cR1 (12.1.0.1) с технологиями RAC, RMAN, ASM, Direct NFS. Всё ниже написанное можно, как правило, также отнести и для SnapManager for MS SQL (SMSQL) и SnapCreator.
SnapManager for Oracle on Linux, Backing-up Operation
SMO бэкапирует только следующие данные:
См. документ TR-3761 NetApp SnapManager 3.3.1 for Oracle, стр 12, таблица 1).
Redo Logs не бэкапируются, они могут бэкапироваться при помощи SnapMirror, смотри ниже.
Средствами SMO бэкап Archive Logs выполняется, логи не затираются и не восстанавливается. Для управления Redo Logs и Archive Logs применяется RMAN. Как SMO работает с Archive Logs.
Рекомендации по разбивке пространства на FlexVol'ы и LUN'ы для SMO, как правило совпадают с рекомендациями "Oracle DB on NetApp".
Первым делом необходимо выключить автоматические снапшоты на FlexVol'юмах, их теперь будет инициировать SMO Server. Обязательно необходимо отделять Temp Files на выделенный FlexVol. Не поддерживается RAW устройства с LVM. August 2011 | TR-3633 Best Practices for Oracle Databases on NetApp Storage, стр. 11
Некоторые однотипные файлы от разных DB можно группировать и хранить в одном FlexVol, другие разнотипные файлы нужно обязательно разделять:

Все эти требования по отделению Redo Logs, Archive Logs, Data Files и Temp Files вытекают из следующего:
На уровне создания снапшотов это называется Consistency Groups, что поддерживается DataOntap 7.2 или выше. Но это требуется только в случае ASM. В случае без ASM, Oracle сам справляется с консистентностью бэкапа базы, которая распределена по разным контроллерам (FlexVol'юмам).
В виду нашего случая с применением SAN, хочу обратить ваше внимание на следующие нюансы:
В случае использования Thin Provisioning и нескольких LUN'ов в одном FlexVol'юме, можно получить недостачу места для всех LUN'ов в этом FlexVol'юме и как следствие, отвалившиеся все LUN в нём. DataOntap переведет их в режим Offline, чтобы они не повредились. Для избежания этой ситуации рекомендуется использовать ОС RedHat Enterprise Linux 6.2 (или другие современные ОС) или выше с поддержкой Logical Block Provisioning как определено в стандарте SCSI SBC-3 (что часто называют SCSI Thin Provisioning), который «объясняет» ОС, что LUN на самом деле «тонкий» и место на нём «на самом деле закончилось», запрещая проводить операции записи. Таким образом, ОС должна перестать писать в такой LUN, а он сам не будет переведен в Offline и останется доступен только на чтение для ОС (другой вопрос как на это отреагирует приложение). Этот функционал также предоставляет возможность использования Space Reclamation. Таким образом современные ОС теперь более адекватно работают в режиме тонкого планирования с LUN'ами.
В случае использования снапшотов (а в SMO они будут использованы) и хранения нескольких LUN'ов в одном FlexVol'юме мы опять можем упереться в ситуацию с пространством, даже если LUN'ы «толстые». А именно: если снапшотам не хватает места в выделенном резерве, они начинают занимать пространство в активной файловой системе в ходе изменения LUN'а. Другими словами нужно правильно выделить свободное пространство под снапшоты для LUN'а(ов). Если его выделить меньше, то снешшоты от LUN'ов съедят пространство в снапшот-резерве, а потом из активной файловой системы и см. в предыдущем пункте, что произойдёт. Ситуация частично решается выделением эмпирически подобранного резерва под снапшоты, настройки удаления более старых снапшотов (snap autodelete) и автоматического увеличения FlexVol (volume autogrow). Но хочу обратить ваше внимание что высвобождение пространства произойдёт, уже после того, как LUN'(ы) уйдут в Offline, в содержащем их FlexVol, в котором собственно закончилось пространство. А наличие большого количества LUN'ов в одном FlexVol'юме увеличивает, так сказать, вероятность того, что в один прекрасный момент один из LUN'ов может взять и начать «расти» не по дням а по часам — не так как планировалось, съев всё пространство не только в резерве под снапшоты, но и в активной файловой системе FlexVol. От сюда и выплывает рекомендация: или иметь один LUN на один FlexVol, или хранить несколько LUN'ов в одном FlexVol'юме, но проследить, чтобы все эти LUN'ы были однотипные и росли «одинаково пропорционально». Второй пункт подразумевает обязательную настройку мониторинга OCUM (Бесплатная софтина, да и вообще полезная штука, мониторинг в любой ситуации не помешает) и следить за происходящим. OCUM может следить за всеми показателями ОС СХД DataOntap, какие только последняя, вообще, может предоставить. Ко всему прочему, OCUM может отправлять алерты на почту, которую соответственно нужно обязательно читать. Наглядно про снапшоты, LUN'ы и Fractional reserve и почему LUN 'ы обычно только растут можно посмотреть тут.
В случае SAN со снапшотами очень улучшает сутуацию поддержка ОС функций Space Reclamation см. предыдущий пункт. Space Reclamation, позволяет Thin LUN'ам уменьшаться на стороне СХД по мере удаления хостом данных на нём, решая "проблему постоянного роста Thin LUN'ов". Так как без Space Reclamation LUN'ы всегда только «ростут» в случае Thin LUN и даже для «толстых» LUN'ов отсутствие Space Reclamation выливается в «снапшоты-переростки», которые захватывают в себя никому не нужные уже давно удаленные блоки данных. По-сему Space Reclamation маст хэв.
Бэкапы созданные SMO могут быть каталогизированы в RMAN, такая настройка выполняется опционально. Это даёт возможность использования функций: блочного (смотри пример в приложение E) и Tablespace-in-time (смотри пример в приложение F) восстановления. При каталогизации бэкапов SMO в RMAN необходимо их располагать в DB, отличной от бэкапируемой. Для регистрации SMO бэкапов в RMAN, необходимо включить RMAN-enabled profiles. TR-3761 NetApp SnapManager 3.3.1 for Oracle, стр 11. Рекомендуется использовать что-то одно: или RMAN или SMO.
Бэкапирование Redo Logs и Archive Logs выполняются с помощью репликации SnapMmirror в синхронном, полу-синхронном или асинхронном режиме. Использование SnapMirror подразумевает применение снапшотов (без взаимодействия с SMO). Все остальные данные как правило реплицируются в асинхронном режиме. SnapMirror — лицензируется «поконтроллерно», на обе стороны — хранящий резервную копию (Secondary) и основной контроллер (Primary) NetApp FAS, содержащий данные, которые необходимо защищать. TR-3455 Database recovery using SnapMirror Async and Sync, Глава 12, стр 17.
Undo Tablespace нужно хранить вместе с Data Files для того, чтобы осуществлять их резервное копирование. Undo Tablespace нужно хранить на одном луне вместе с Data Files.
В чём разница между Archive, Redo и Undo Tablespace.
Для доступа к некоторым страницам может понадобится NetApp NOW ID. Если вы берете СХД NetApp на тест, ваш дистрибютор/интегратор поможет загрузить их.
*Qtree — Применение для репликации в системах NetApp FAS с ОС DataONTAp Cluster-Mode (Clustered ONTAP), более не требуется, так как SnapVault и SnapMirror QSM теперь умеют реплицировать и восстанавливать данные на уровне Volume.
Выражаю глубокую благодарность shane54, за помощь в консультировании по работе БД Оракл и конструктивную критику.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии
SnapManager for Oracle on Windows, Cloning Operation
Зачем вообще бэкапировать данные при помощи снапшотов и тем более средствами СХД? Дело в том, что большинство современных способов бэкапирования информации подразумевают длительность процесса, ресурсоёмкость: нагрузка на хост, загрузка каналов, занимание пространства и как следствие к деградации сервисов. Тоже касается и клонирования больших объемов информации для Dev/Test подразделений, увеличивая «временной разрыв» между актуальными данными и резервируемыми, это повышает вероятность того, что бэкап может оказаться «не восстановим». С применением «аппаратных» снапшотов компании NetApp, не влияющих на производительность и занимающий не положенные 100% резервной копии, а только лишь «разницу» (своего рода инкрементального бэкапа или лучше сказать обратного инкрементального бэкапа, на снятие и сборку которого не нужно тратить время), а также возможность передачи данных для резервирования и архивирования в виде снапшотов, позволяя более элегантно решать современные высокие требования бизнеса для подобных задач, уменьшая время передачи информации и нагрузку на хосты.
Компоненты SMO
Утилита состоит из нескольких компонент: сервер, на выделенном хосте или виртуальной машине и агентов устанавливающихся на хостах с DB. Для полноценного функционирования SnapManager необходим функционал, который тоже лицензируются «поконтроллерно»: FlexClone, SnapRestore. Кроме установленных агентов SnapManager требуется установленный экземпляр утилиты SnapDrive (лицензии входят в комплект с SnapManager) на хосте внутри ОС с DB. SnapDrive помогает в создании CCS взаимодействуя с ОС, в то время как SMO взаимодействует с приложением, для создания ACB, таким образом дополняя друг-друга. Резница между ACB и CCS. Без купленных лицензиий SnapRestore и FlexClone, не будет доступен функционал соответственно моментального восстановления и средствами СХД моментального клонирования и катологизации.
Интеграция SMO с Oracle
Лицензирование у SnapManager «поконтроллерное» в состав лицензии SnapManager входят и другие менеджеры для MS SQL, MS Exchange, MS Share Point, MS Hyper-V, VMWare vSphere, SAP, Lotus Domino и Citrix Xen Server.
SnapManager for MS SQL, Moving Operation
SnapCreator
Пойдя по пути «оптимизации расходов», отказываясь от покупки лицензии SnapManager, нужно понимать, что управление потребуют дополнительных затрат времени и взаимодействия DBA с Server Admins, Сетевыми Администраторами и Админов СХД, для того, чтобы DBA получили вожделенную манипуляцию с DB. В то время как с SnapManager это можно выполнить нажатием пары кнопок в GUI интерфейсе, без привлечения разных специалистов и затрат времени.
Многие из выполняемых функций SnapManager можно выполнять при помощи бесплатной утилиты SnapCreator, также позволяющей интегрироваться с DB (а также большим количеством других приложений) приложениями для снятия консистентных снапшотов ACB средствами СХД. Но эта утилита не выполняет многих других удобных функций по управлению DB. Таких как клонирование DB, восстановление «in-Place», примапливание клона DB к другому хосту, автоматическое тестирование работоспособности и восстановления из архива и т.д.
Схема взаимодействия компонент SnapCreator
Scripting
Большинство недостающего функционала в SnapCreator можно компенсировать при помощи скриптинга, который сейчас доступен с PowerShell командлетами в: DataOntap Toolkit, SnapCreator, OnCommand Unified Manager (OCUM) и многих других полезных утилит. На что несомненно потребуется время, для отладки под бизнес процессы.
Краткий ликбез по идеологии NetApp
Интеграция
SMO интегрируется с 10GR2, 11g R1/R2, 12cR1 (12.1.0.1) с технологиями RAC, RMAN, ASM, Direct NFS. Всё ниже написанное можно, как правило, также отнести и для SnapManager for MS SQL (SMSQL) и SnapCreator.
SnapManager for Oracle on Linux, Backing-up Operation
1) Что бэкапирует SMO:
SMO бэкапирует только следующие данные:
- Data Files
- Control files
- Archive Redo logs (Archive Logs)
См. документ TR-3761 NetApp SnapManager 3.3.1 for Oracle, стр 12, таблица 1).
Redo Logs не бэкапируются, они могут бэкапироваться при помощи SnapMirror, смотри ниже.
1.1) Как бэкапируются, затираются и восстанавливаются Archive Logs:
Средствами SMO бэкап Archive Logs выполняется, логи не затираются и не восстанавливается. Для управления Redo Logs и Archive Logs применяется RMAN. Как SMO работает с Archive Logs.
2) Рекомендации по подготовке:
Рекомендации по разбивке пространства на FlexVol'ы и LUN'ы для SMO, как правило совпадают с рекомендациями "Oracle DB on NetApp".
Первым делом необходимо выключить автоматические снапшоты на FlexVol'юмах, их теперь будет инициировать SMO Server. Обязательно необходимо отделять Temp Files на выделенный FlexVol. Не поддерживается RAW устройства с LVM. August 2011 | TR-3633 Best Practices for Oracle Databases on NetApp Storage, стр. 11
Некоторые однотипные файлы от разных DB можно группировать и хранить в одном FlexVol, другие разнотипные файлы нужно обязательно разделять:
- Каждый лун желательно ложить в отдельный Qtree*. Это удобно в случае репликации SnapMirror QSM, SnapVault или NDMPCopy, так архивируются данные оперируя Qtree* и что важно, восстанавливаются всегда в Qtree*. По-этому данные забэкапленные не из Qtree* (non-qtree данные) всегда могут быть восстановлены только в Qtree*. Таким образом удобно всегда хранить данные в Qtree*, чтобы в случае восстановления не перенастраивать доступ к данным из нового места. Подробнее
- Располагая каждый LUN в отдельный Qtree* можно назначать квоты на её размер, генерируя алерты не на весь FlexVol, а на отдельный Qtree*, при достижении определённого порога её заполненности. Это удобно для отслеживания состояния LUN по email без использования каких-либо дополнительных утилит.
- Temp Files обязательно нужно отделять от всех остальных данных, так как они очень сильно меняются в ходе эксплуатации DB и соответственно снапшоты снятые с таких данных, занимают на СХД ценное пространство.
- Снапшоты на Temp Files должны быть выключены
- Temp Files от всех DB можно складывать в один FlexVol.
- Файлы DB Archive Logs, Redo Logs и собственно Data в случае с SAN каждый тип нужно держать на выделенном LUN 'е. Не стоит смешивать в одном луне файлы DB разных типов, к примеру, не стоит на одном луне держать файлы Archive Logs и Redo Log.
- LUN'ы содержащие файлы Archive Logs, Redo Log и собственно Data, каждый необходимо держать на выделенном FlexVol'юме. Т.е. для таких LUN'ов действует правило: один FlexVol — один LUN (и не забываем про Qtree*).
- Если, к примеру DB генерирует два файла Archive Logs и каждый из них лежит на отдельном LUN'е, то такие LUN'ы, в качестве исключения из правила, можно хранить в одном FlexVol'юме, т.е. иметь на один FlexVol'юм несколько LUN'ов. Тo же касается и других файлов DB, в том числе Data Files и Redo Logs.
- Копию Control Files от каждой DB желательно хранить вместе с соответствующими Redo Logs.
- Redo Logs от всех инстансов нужно отделять в отдельный FlexVol'юм.
- Archive Logs от всех инстансов DB нужно отделять в отдельный FlexVol'юм.
- Файлы Oracle Cluster Registry (OCR) или Voting Disk Files от всех инстансов можно складывать в один FlexVol'юм, каждый в отдельную Qtree* на этом FlexVol'юме. Oracle настойчиво рекомендует хранение OCR и Voting Disks на дисковых группах, которые не хранят database files.
- Undo Tablespace нужно хранить вместе с Data Files.
Все эти требования по отделению Redo Logs, Archive Logs, Data Files и Temp Files вытекают из следующего:
- Temp Files не нужны для бэкапирования и восстановлени, но из-за того что они сильно изменяются в случае применения к ним снапшотов, будут нещадно поедать пространство на СХД, занимая его бесполезными данными.
- Если хранить те же Temp Files вместе с другими типами файлов DB, которые будут бэкапироваться снапшотами, они поедают пространство (см. предыдущий пункт) и как следствие съев всё пространство могут привести к ситуации с уходом LUN'ов (в этом FlexVol'юме котором закончилось пространство) в Offline.
- В случае с применением SnapMirror VSM репликации используются снапшоты, а если мы имеем «смешанные в одну кучу» данные от DB, то смотри два предыдущих пункта про Temp Files. Плюс ко всему прочему на удалённую систему будут постоянно отсылаться никому не нужные данные, загружая канал связи.
- В случае с применением SnapMirror QSM или SnapVault репликации, вопрос с загрузкой канала связи можно обойти разместив данные в одном FlexVol'юме, данные которого необходимо реплицировать, в отдельный(ные) Qtree* и реплицировать только их, не нагружая канал связи, но вопрос со снапшотами всё-равно не обойти (см. первые два пункта), так как снапшоты снимаются на весь FlexVol'юм «целиком».
- С другой стороны «логика один LUN — один FlexVol'юм» исходит из возможной необходимости восстанавливать не все DB, а только одну или несколько. Для восстановления можно применять функционал SnapRestore с одним из подходов: SFSR или VBSR. VBSR более быстрый, так как не требует прохождения по структуре WAFL, так как VBSR работает на блочном уровне с FlexVol'юмами восстановятся все данные внутри него. Таким образом при хранении в одном FlexVol'юме нескольких DB или их частей, можно «нечаянно» заодно восстановить более старую версию (части) другой DB. Чтобы этого не происходило, в связи с чем имеем рекомендацию: один FlexVol'юм — один LUN, для всех данных которые возможно потребуется восстанавливать.
- В случае использования файлового доступа, такого как NFS или Direct NFS, вместо блочного доступа, суть всего вышесказанного относительно разделения файлов DB по разным FlexVol'юмам сохраняется, с той только разницей, что экспорт NFS выполняется на уровне Qtree* или Volume вместо LUN. А также возможностью более гранулярного восстановления файлов DB с применением SFSR.
2.1) Можно ли чтобы одна база жила на нескольких контроллерах (FlexVol'юмах) при использовании SnapManager?
На уровне создания снапшотов это называется Consistency Groups, что поддерживается DataOntap 7.2 или выше. Но это требуется только в случае ASM. В случае без ASM, Oracle сам справляется с консистентностью бэкапа базы, которая распределена по разным контроллерам (FlexVol'юмам).
В виду нашего случая с применением SAN, хочу обратить ваше внимание на следующие нюансы:
2.2) Thin Provisioning:
В случае использования Thin Provisioning и нескольких LUN'ов в одном FlexVol'юме, можно получить недостачу места для всех LUN'ов в этом FlexVol'юме и как следствие, отвалившиеся все LUN в нём. DataOntap переведет их в режим Offline, чтобы они не повредились. Для избежания этой ситуации рекомендуется использовать ОС RedHat Enterprise Linux 6.2 (или другие современные ОС) или выше с поддержкой Logical Block Provisioning как определено в стандарте SCSI SBC-3 (что часто называют SCSI Thin Provisioning), который «объясняет» ОС, что LUN на самом деле «тонкий» и место на нём «на самом деле закончилось», запрещая проводить операции записи. Таким образом, ОС должна перестать писать в такой LUN, а он сам не будет переведен в Offline и останется доступен только на чтение для ОС (другой вопрос как на это отреагирует приложение). Этот функционал также предоставляет возможность использования Space Reclamation. Таким образом современные ОС теперь более адекватно работают в режиме тонкого планирования с LUN'ами.
2.3) SAN & SnapShots:
В случае использования снапшотов (а в SMO они будут использованы) и хранения нескольких LUN'ов в одном FlexVol'юме мы опять можем упереться в ситуацию с пространством, даже если LUN'ы «толстые». А именно: если снапшотам не хватает места в выделенном резерве, они начинают занимать пространство в активной файловой системе в ходе изменения LUN'а. Другими словами нужно правильно выделить свободное пространство под снапшоты для LUN'а(ов). Если его выделить меньше, то снешшоты от LUN'ов съедят пространство в снапшот-резерве, а потом из активной файловой системы и см. в предыдущем пункте, что произойдёт. Ситуация частично решается выделением эмпирически подобранного резерва под снапшоты, настройки удаления более старых снапшотов (snap autodelete) и автоматического увеличения FlexVol (volume autogrow). Но хочу обратить ваше внимание что высвобождение пространства произойдёт, уже после того, как LUN'(ы) уйдут в Offline, в содержащем их FlexVol, в котором собственно закончилось пространство. А наличие большого количества LUN'ов в одном FlexVol'юме увеличивает, так сказать, вероятность того, что в один прекрасный момент один из LUN'ов может взять и начать «расти» не по дням а по часам — не так как планировалось, съев всё пространство не только в резерве под снапшоты, но и в активной файловой системе FlexVol. От сюда и выплывает рекомендация: или иметь один LUN на один FlexVol, или хранить несколько LUN'ов в одном FlexVol'юме, но проследить, чтобы все эти LUN'ы были однотипные и росли «одинаково пропорционально». Второй пункт подразумевает обязательную настройку мониторинга OCUM (Бесплатная софтина, да и вообще полезная штука, мониторинг в любой ситуации не помешает) и следить за происходящим. OCUM может следить за всеми показателями ОС СХД DataOntap, какие только последняя, вообще, может предоставить. Ко всему прочему, OCUM может отправлять алерты на почту, которую соответственно нужно обязательно читать. Наглядно про снапшоты, LUN'ы и Fractional reserve и почему LUN 'ы обычно только растут можно посмотреть тут.
2.4) Space Reclamation:
В случае SAN со снапшотами очень улучшает сутуацию поддержка ОС функций Space Reclamation см. предыдущий пункт. Space Reclamation, позволяет Thin LUN'ам уменьшаться на стороне СХД по мере удаления хостом данных на нём, решая "проблему постоянного роста Thin LUN'ов". Так как без Space Reclamation LUN'ы всегда только «ростут» в случае Thin LUN и даже для «толстых» LUN'ов отсутствие Space Reclamation выливается в «снапшоты-переростки», которые захватывают в себя никому не нужные уже давно удаленные блоки данных. По-сему Space Reclamation маст хэв.
3) Отображаются ли бэкапы в RMAN?
Бэкапы созданные SMO могут быть каталогизированы в RMAN, такая настройка выполняется опционально. Это даёт возможность использования функций: блочного (смотри пример в приложение E) и Tablespace-in-time (смотри пример в приложение F) восстановления. При каталогизации бэкапов SMO в RMAN необходимо их располагать в DB, отличной от бэкапируемой. Для регистрации SMO бэкапов в RMAN, необходимо включить RMAN-enabled profiles. TR-3761 NetApp SnapManager 3.3.1 for Oracle, стр 11. Рекомендуется использовать что-то одно: или RMAN или SMO.
4) Планируется ли бэкапирование Redo Logs при помощи SMO в будущем?
Бэкапирование Redo Logs и Archive Logs выполняются с помощью репликации SnapMmirror в синхронном, полу-синхронном или асинхронном режиме. Использование SnapMirror подразумевает применение снапшотов (без взаимодействия с SMO). Все остальные данные как правило реплицируются в асинхронном режиме. SnapMirror — лицензируется «поконтроллерно», на обе стороны — хранящий резервную копию (Secondary) и основной контроллер (Primary) NetApp FAS, содержащий данные, которые необходимо защищать. TR-3455 Database recovery using SnapMirror Async and Sync, Глава 12, стр 17.
5) Можно ли Undo Tablespace и Temp Files держать вместе?
Undo Tablespace нужно хранить вместе с Data Files для того, чтобы осуществлять их резервное копирование. Undo Tablespace нужно хранить на одном луне вместе с Data Files.
В чём разница между Archive, Redo и Undo Tablespace.
Для доступа к некоторым страницам может понадобится NetApp NOW ID. Если вы берете СХД NetApp на тест, ваш дистрибютор/интегратор поможет загрузить их.
*Qtree — Применение для репликации в системах NetApp FAS с ОС DataONTAp Cluster-Mode (Clustered ONTAP), более не требуется, так как SnapVault и SnapMirror QSM теперь умеют реплицировать и восстанавливать данные на уровне Volume.
Выражаю глубокую благодарность shane54, за помощь в консультировании по работе БД Оракл и конструктивную критику.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии
